インターネットで調べて実装しているのでまだ理解し切れていない部分もあります。
虚偽・暴論等が記事内にありましたらご指摘願います。
はじめに
今回は、2018年の時点で2番目に優秀というApe-Xという強化学習アルゴリズムを実装してみました。
Ape-Xとは
Ape-Xは2018に発表された強化学習アルゴリズムで、R2D2に次いで2番目に優秀とされている強化学習アルゴリズムです
論文はこちら
構造的には、
・Double Deep Q Network
・multi-step bootstrap target
・Dueling Network
・Prioritized Experience Replay
・分散学習
no
4つを組み合わせたアルゴリズムです。順番に説明していきます
Double Deep Q Network (DDQN)
DDQNについてはこのサイトがわかりやすいと思います
DQNはネットワークが一つのために自分を過大評価してしまうという欠点がありました。DDQNはその改善版で、DQNと違ってQネットワークを二つ使っています。
価値計算用ネットワークと行動決定用ネットワークの二つです。実際に式を見てみましょう。
DQNのQ値の式(求めるべき値の式)は、
Q(S_{t},A_{t})=R_{t+1}+\gamma max_{a}(Q(S_{t+1},a))
変数の説明
$\gamma max_{a}(Q(S_{t},a))$:状況$S_{t}$でのQ値の最大値に割引率$\gamma$をかけたもの
なのに対して、DDQNでは
Q(S_{t},A_{t})=R_{t+1}+\gamma Q_{target}(S_{t},argmax_{a}Q(S_{t+1},a))
という式を使用します。右辺の二つ目の項が変わっていますね。新しいQネットワーク$Q_{target}$が出現していると思います。これが価値計算用ネットワークです(逆にいえば$Q$が行動決定用です)。
まず行動決定用ネットワークを使って$S_{t+1}$に対する行動を決定し、その結果得られるであろう報酬を価値計算用ネットワークを使って予測する、という流れです。
まだわからない!という人へ
例えば、自分のサッカーの試合を振り返っている時、自分で振り返ろうとするとどうしてもその人の主観が入り込み、その試合中の行動を過大評価・過小評価してしまう恐れがありますよね。それを防ぐために「第三者」を用意して、その人に評価してもらうことで主観を取り除こう、というのがDDQNの考え方です。 (また、その「第三者」はここでは「過去の自分」になります)multi-step bootstrap target
これは、いくつかの連続した経験を考慮して学習するアルゴリズムです。
これも式で比較してみましょう。
先ほども述べましたが、DQNでは、
Q(S_{t},A_{t})=R_{t+1}+\gamma max_{a}(Q(S_{t+1},a))
という式を使っているのに対し、(nステップ考慮する)multi-step bootstrap target では
Q(S_{t},A_{t})=R_{t+1}+\gamma R_{t+2}+...+\gamma^{n-1}R_{t+n-1}+\gamma^{n} max_{a}(Q(S_{t+n},a))
という式を使います。(Ape-Xの論文ではn=3で行っています)
Double Deep Q Network、multi-step bootstrap target の式を組み合わせると、
Q(S_{t},A_{t})=R_{t+1}+\gamma R_{t+2}+...+\gamma^{n-1}R_{t+n-1}+\gamma^{n} Q_{target}(S_{t+n},argmax_{a}Q(S_{t+n},a))
このような式になり、これがApe-Xで使う目標の値を求める式になります。
Dueling Network
Queling Networkについてはこのサイトを参考にしています
Dueling Network は他のDQNやDDQNのような、「状態から直接行動を決定する」のではなく、「その状態がどのようなものかを識別し、それを考慮しながら行動を決定する」という考え方のアルゴリズムです。
具体的に、下の図のようなネットワークになります。
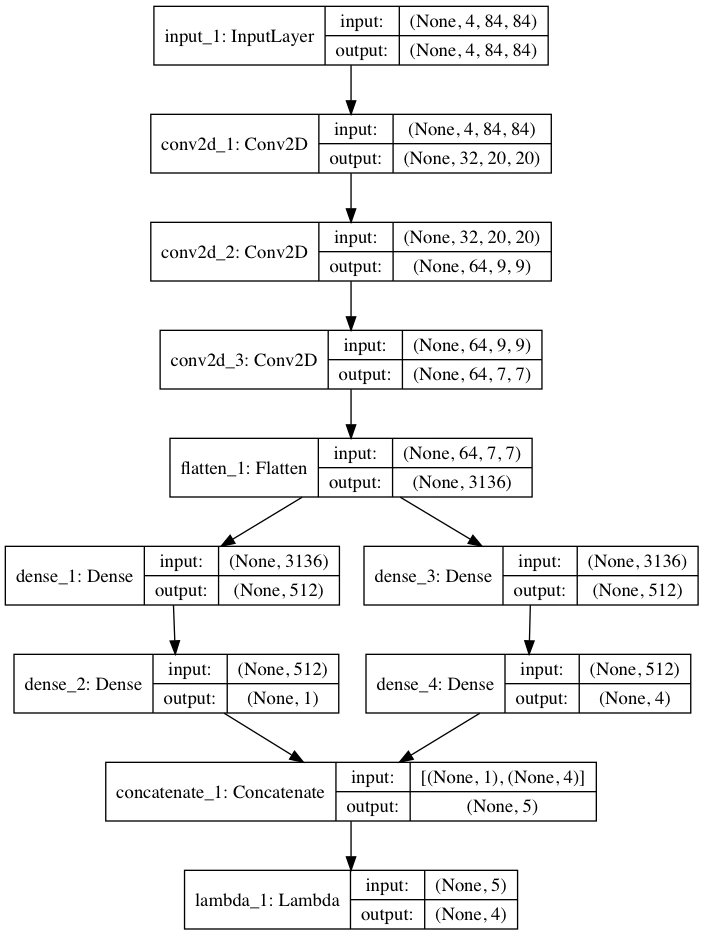
まず、状況$S_t$を受け取り、ある程度予測してから状態価値関数(状態を数値化)の層(左)と、Advantage(一時的な行動決定)の層(右)に別れ、それぞれ予測を行ってから最後に足し合わせています。
Prioritized Experience Replay
これの日本語名は「優先順位付き経験再生」です。つまり、ある経験(状態、行動、その結果得られた報酬など)に優先順位をつけ、優先順位が高いものをよく学習するということです。
Ape-Xにおける優先順位はTD誤差によって決定します。具体的には、
P_{i}=|\delta_{i}|
このように定義されます。
TD誤差とは
TD誤差とは、簡単にいうと「目標値」と「予測値」の誤差を表し、一般的に$\delta$で表されます。分散学習
Ape-Xでは、学習をLeanerとActor、そしてMemoryの3つに分け、それぞれ並列して学習を行います(下図)。
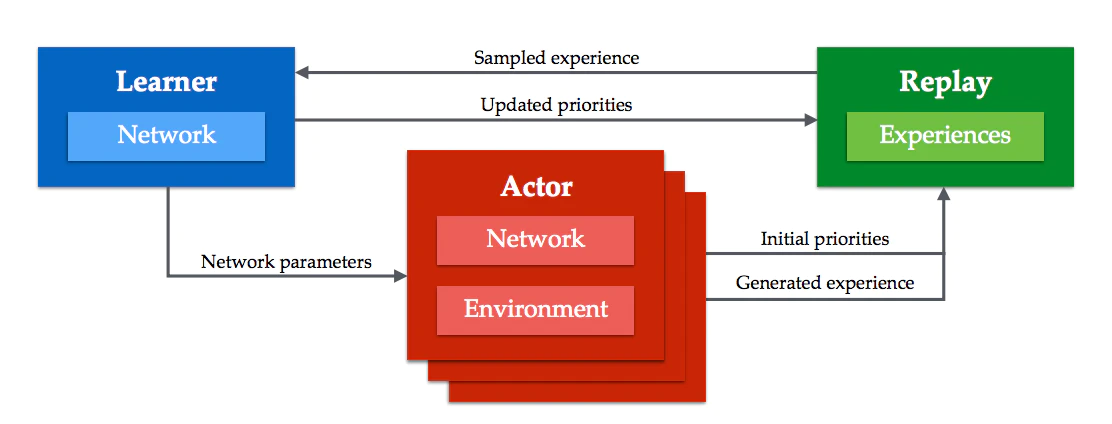
Actor:行動専門。Leanerから随時ネットワークを取得し、そのネットワークを使用して多くの経験を積み、それを優先順位をつけてMemoryに送信
Memory:Actorから経験を受け取り、必要があればLeanerに提供する
Leaner:学習専門。Memoryからサンプルを受け取り、それをもとに学習を行う。学習時、サンプル中の経験の優先順位を更新してMemoryを更新する。
この中のActorが分散学習を行っています。Actorの数を増やし、より多くの経験を発生させよう、ということです。
実装
実装上のポイント
ε固定
通常、ε-greedyにおけるεは1から少しづつ小さくしていますが、今回はこれをActorごとに固定しています。
また、$Actor_i$のεは次の式で求めることができます。
\varepsilon_i=\varepsilon^{1+\frac{i}{N-1}\alpha}
(NはActorの数、0_indexed)
論文では、$\varepsilon$=0.4,$\alpha$=7としています。
マルチプロセス
マルチプロセスにはPythonのmultiprocessing というモジュールを使います
また、プロセス間の通信には以下のものを使います
・exp_queue(Actor→Memory 経験送信用)(multiprocessing.Queue)
・param_queue(Leaner→Actor Leanerのネットワークの重みの共有)(multiprocessing.Queue)
・actor_working(Actorの稼働状況)(multiprocessing.Value)
Memory
今回は、 Memory を Leaner の中に入れ、学習前に適宜 exp_queue から新しい経験を確認し、新しい情報があればMemoryに格納します。
また、優先順位はこのサイトの SumTree というものを使って実装します(簡単に説明するとSumTreeは二分木を使って優先順位付きのサンプリングを行います)
実装
基本的に詳細はコメントに載せているのでここでは流れだけを説明します
Memory
Memoryのコードはそんなに長くはないので全文載せます。
class Memory:#経験を優先順位をつけて保存しておく
def __init__(self,
capacity):
self.capacity=capacity
self.data=SumTree(self.capacity)
def length(self):
return self.data.write
def sample(self,num_samples):
data_length=self.data.total()
sampling_interbal=data_length/num_samples
batch=[] #返すやつ
for i in range(num_samples):
l=sampling_interbal*i
r=sampling_interbal*(i+1)
p=random.uniform(l,r)
(idx,p_sample,data)=self.data.get(p)
# idx:使っている二分木上でのインデックス(優先度を更新するときに使う)
# p_sample:そのデータの優先度(実際には使ってない)
# data:データ
batch.append([idx,p_sample,data])
return batch
def add(self,p,data): #p:優先順位(TD誤差)
self.data.add(p,data)
def update_p(self,idx,p): #優先順位の更新
self.data.update(idx,p)
add:Memoryにデータを優先順位とともに追加
update_p:指定されたデータの優先順位を更新
sample:サンプルを取得
length:データの大きさ(ただこの値はループするので信用できるのは1周目のみ)
Leaner
Leaner・Actorは長いので関数単位で
init
変数の初期化を行います
def __init__(self,
env, #トレーニング環境
exp_queue, #Memory
param_queue, #Actorへの提供用
num_actions, #行動の種類数
exp_memory_size, #Memoryの上限(MemoryもLeanerで管理する)
train_batch_size, #学習するときのバッチサイズ
actor_working, #Actorが動いているかどうか
save_name, #保存名
myenv=False, #クラスか名前か
gamma=0.99, #割引率
update_target_interbal=100, #価値計算用のネットワークの更新頻度
load_model_path=None,
window_length=3 #考慮に入れるフレーム数
):
#引数の変数を受け取る
self.exp_queue=exp_queue
self.param_queue=param_queue
self.exp_memory_size=exp_memory_size
self.train_batch_size=train_batch_size
self.window_length=window_length
self.gamma=gamma
self.save_name=save_name
self.update_target_interbal=update_target_interbal
self.actor_working=actor_working
if myenv:
self.env=env()
else:
self.env=gym.make(env)
self.num_actions=num_actions
#ネットワーク定義
self.main_Q=self.build_network() #行動決定用のQネットワーク
self.target_Q=self.build_network() #価値計算用のQネットワーク
if load_model_path!=None:
self.main_Q=load_model(load_model_path)
self.target_Q.set_weights(self.main_Q.get_weights())
#メモリ作成
self.memory=Memory(self.exp_memory_size)
#最初の重みをQueueに入れておく
while not param_queue.full():
param_queue.put([self.main_Q.get_weights(),self.target_Q.get_weights()])
# print(param_queue.full())
return
最初の塊は受け取った引数を保存してるだけです
次の塊は、行動決定、価値計算用ネットワークを定義して、二つの重みを揃える動作をしています(build_network関数は次で定義します)
その次はMemory定義、
最後はActor用に param_queue を満杯にしています
build_network
ネットワークの構築を行います
def build_network(self):
#ネットワーク構築
l_input=Input((1,)+self.env.observation_space.shape,name="Input_Leaner")
fltn=Flatten()(l_input)
dense=Dense(units=256,activation="relu")(fltn)
dense=Dense(units=256,activation="relu")(dense)
dense=Dense(units=256,activation="relu")(dense)
v=Dense(units=256,activation="relu")(dense)
v=Dense(units=1,activation="linear")(v)
adv=Dense(units=256,activation="relu")(dense)
adv=Dense(units=self.num_actions,activation="linear")(adv)
y=concatenate([v,adv])
l_output = Lambda(lambda a: K.expand_dims(a[:, 0], -1) + (a[:, 1:] - K.stop_gradient(K.mean(a[:,1:],keepdims=True))), output_shape=(self.num_actions,))(y)
model=Model(inputs=l_input,outputs=l_output)
model.compile(optimizer="Adam",
loss="mse",
metrics=["accuracy"])
return model
最初の塊はネットワーク構築、次の塊はモデルのコンパイルをしています
ネットワーク構築にラムダ式がありますが、あまり理解できていないので説明ができません...ごめんなさい
make_sample
Memoryからサンプルを作成しています
def make_batch(self):
train_batch=self.memory.sample(self.train_batch_size)
train_batch=np.array(train_batch)
batch=train_batch[:,2] #データだけ取り出す
#このままだと
#[[a_1,b_1,c_1],[a_2,b_2,c_2]...[a_n,b_n,c_n]]
#となっているから、これを
#[[a_1,a_2,...,a_n],[b_1,b_2,...,b_n],[c_1,c_2,...,c_n]]
#にする
#(こうすると推論のときに一気にできるので高速に処理ができる)
rewards_batch=[] #Reward[t]
state_batch=[] #State[t]
state_n_batch=[] #State[t+n]
action_batch=[] #Action[n]
for i in batch:
rewards_batch.append(i[0])
state_batch.append(i[1][0])
state_n_batch.append(i[2][0])
action_batch.append(i[3])
rewards_batch=np.array(rewards_batch)
state_batch=np.array(state_batch)
state_n_batch=np.array(state_n_batch)
action_batch=np.array(action_batch)
#教師データ作成
batch_size=len(state_batch)
y=self.main_Q.predict(state_batch,batch_size=batch_size)
#予め推論をしておく
main_predict=self.main_Q.predict(state_n_batch,batch_size=batch_size)
target_predict=self.target_Q.predict(state_n_batch,batch_size=batch_size)
for i in range(batch_size):
action=np.argmax(main_predict[i]) #mainQを使って行動選択
q=target_predict[i][action] #targetQでQ値を出す
target=rewards_batch[i]+(self.gamma**self.window_length)*q #Q(State(t),Action(t)) として出すべき値(目標の値)
td_error=y[i][action_batch[i]]-target #TD誤差を計算
self.memory.update_p(train_batch[i][0],abs(td_error)) #その繊維の優先度を更新
y[i][action_batch[i]]=target #教師データに目標の値を代入
return state_batch,y
まず一つ目の塊はMemoryから必要な分だけデータを取り出しています
そして二つ目の塊でそのデータをフォーマット、三つ目でそれをnp配列にしています
4つ目では、できた配列のうち、$State_{t+n}$に該当するものの配列を$Q$、$Q_{target}$にいれて推論をさせています。コメントにもありますが、こうしているのは、一つ一つ推論させるより一気に推論させた方が圧倒的に速いからです(3倍以上早くなります)
そして最後の塊でApe-Xの式に基づいて、教師用データの作成を行なっています
run
Leanerで実際に学習を行います
def run(self):
t=0 #トータル試行回数
while self.memory.length()<self.train_batch_size:
print("Leaner is waiting for enough experience to train")
while not self.exp_queue.empty(): #exp_queueにある経験情報を全てMemoryに追加
batch=self.exp_queue.get()
self.memory.add(batch[4],batch)
time.sleep(5)
print("Leaner starts")
try:
while True:
#Actorが一つも動いていなければ終了
working=False
for i in self.actor_working:
if i:
working=True
break
if not working:
break
#exp_queueから経験を取得・Memoryに入れる
while not self.exp_queue.empty():
batch=self.exp_queue.get()
self.memory.add(batch[4],batch)
#サンプル作成
X,y=self.make_batch()
X=np.array(X)
y=np.array(y)
if t%self.update_target_interbal==0: #価値計算用ネットワークを更新
self.target_Q.set_weights(self.main_Q.get_weights())
#行動決定用は学習・重みを更新
self.main_Q.fit(X,y,epochs=1,verbose=0)
#Queueが満杯になるまで入れる
while not self.param_queue.full():
self.param_queue.put([self.main_Q.get_weights(),self.target_Q.get_weights()])
t+=1
except KeyboardInterrupt:
self.main_Q.save(self.save_name)
print("model has been saved with name'"+self.save_name+"'")
print("Learning was stopped by user")
return
self.main_Q.save(self.save_name)
print("model has been saved with name '"+self.save_name+"'")
print("Leaner finished")
return
最初はMemoryに経験が必要数集まるまで待機。たまったら本格的に始動。学習ループ開始
まずActorが動いているか確認。一つも動いていなければ終了
そして、 exp_queue にたまっている経験を格納した後、学習に入ります。
get_sample でサンプルを取得、必要があれば価値計算用ネットワークの重みを更新して行動決定用ネットワークは学習。
学習が終わるとその時点での重みを param_queue に格納します。
(最後はCtrl+Cの実装です)
Actor
init
def __init__(self,
env, #Gymのenv
exp_queue, #Memory用のmp.Queue
param_queue, #Leaner用のmp.Queue
nb_steps, #学習回数
warmup_steps, #ランダムに行動する回数
num_actions, #行動の種類数
id_, #識別用ID
num_actors, #Actorの総数
actor_working, #どのActorが動いていてどのActorが動いていないか
myenv=False, #これをTrueにするとenvにクラス名を渡せる
gamma=0.99, #割引率
max_epsilon=0.4,
alpha=7,
update_param_interbal=100, #何回試行したらパラメータを更新するか
visualize=False,
window_length=3 #考慮に入れるフレーム数
):
if(myenv):
self.env=env()
else:
self.env=gym.make(env)
#各種変数の定義、代入
self.num_actions=num_actions
self.exp_queue=exp_queue
self.param_queue=param_queue
self.id=id_
self.gamma=gamma
self.window_length=window_length
self.update_param_interbal=update_param_interbal
self.visualize=visualize
self.nb_steps=nb_steps
self.actor_working=actor_working
self.warmup_steps=warmup_steps
if self.warmup_steps>self.nb_steps:
raise ValueError("warmup_steps must be lower than nb_steps.")
#εの計算
if num_actors <= 1:
self.epsilon = max_epsilon ** (1 + alpha)
else:
self.epsilon = max_epsilon ** (1 + id_/(num_actors-1)*alpha)
self.main_Q=self.build_network() #行動決定用ネットワーク
self.target_Q=self.build_network() #価値計算用ネットワーク(TD誤差の計算のためだけに使う)
#初期のLeanerの重みを取得
while self.param_queue.empty():
time.sleep(2)
param=self.param_queue.get()
self.main_Q.set_weights(param[0])
self.target_Q.set_weights(param[1])
やっていることはLeaner.run()とほぼ同じなので説明は割愛
built_network
これもLeanerとほとんど同じです。
ただ、Actorの方は学習はしないのでコンパイルはしません。
send_batch
受け取ったデータを加工して exp_queue に送信します
def send_batch(self,batch):
#この部分はApe-XのTD誤差の式を理解していないとわかりにくい
#一応対応する変数の名前は書いておく
length=len(batch)
#累計報酬
batch_rewards=0
for i in range(length):
batch_rewards+=(self.gamma**i)*batch[i][3]
#State[t]
batch_state=np.array([[batch[0][0]]])
#State[t+n]
batch_state_n=np.array([[batch[length-1][1]]])
#Action[t]
batch_action=batch[0][2]
#TD誤差の計算
action=np.argmax(self.main_Q.predict(batch_state_n)[0])
q=(self.gamma**length)*self.target_Q.predict(batch_state_n)[0][action]
td_error=batch_rewards+q+self.main_Q.predict(batch_state)[0][batch_action]
#exp_queue に送る内容の作成
send=[batch_rewards,batch_state,batch_state_n,batch_action,abs(td_error)]
#送信
self.exp_queue.put(send)
ここでApe-Xの式をもう一度確認します
Q(S_{t},A_{t})=R_{t+1}+\gamma R_{t+2}+...+\gamma^{n-1}R_{t+n-1}+\gamma^{n} Q_{target}(S_{t},argmax_{a}Q(S_t,a))
これに使われている変数は
・$S_t$
・$A_t$
・$R_{t+1},R_{t+2},...,R_{t+n-1}$
・$S_{t+n}$
・$\gamma$
です。このうち、$\gamma$はLeanerにもあるので、残りの4つをデータとして送ります。
その際、報酬は割引率も加味して累積報酬としておきます。
run
def run(self):
batch=[] #Memoryに渡す前に経験をある程度蓄積させるためのバッファ
t=0 #トータル試行回数
epoch=0
self.actor_working[self.id]=True
print("Actor{} starts".format(self.id))
try:
while True:
state=self.env.reset()
done=False
epoch_reward=0
step=0
while not done and t<self.nb_steps:
#行動を決定
action=self.main_Q.predict(np.array([[state]]))
action=np.argmax(action[0])
if t<self.warmup_steps or (self.epsilon>=random.random() and (not self.visualize)):
action=random.randrange(0,self.num_actions)
old_state=state
state,reward,done,info=self.env.step(action) #実際に行動
epoch_reward+=reward
if not self.visualize: #描画用でないのなら経験を送る
mini_batch=[old_state,state,action,reward] #ミニバッチを作成
batch.append([mini_batch]) #バッファに新しく格納
remove_list=[] #溜め切ってデータを送信し終えたデータ(後で削除する)
for i in range(len(batch)):
batch[i].append(mini_batch)
if(len(batch[i])>=self.window_length):
self.send_batch(batch[i]) #経験の送信
#不要なので後で捨てておく
remove_list.append(i)
elif done:# これ以上連続した新しい経験は発生しないのでバッファの中身を全部送る
self.send_batch(batch[i]) #経験の送信
#不要なので後で捨てておく
remove_list.append(i)
#前から削除するとバグりそうので後ろから削除
remove_list.sort()
remove_list.reverse()
for i in remove_list:
batch.pop(i)
else: #visualize=Trueなら描画だけ行う
self.env.render()
time.sleep(1/30)
if t%self.update_param_interbal==0: #Qネットワークの重みを更新
failed=0
while self.param_queue.empty():
if failed>20: #確実にLeanerが落ちているので終了
print("Actor{} ended.".format(self.id))
self.actor_working[self.id]=False
return
print("Actor{} failed to get new param.".format(self.id))
failed+=1
time.sleep(5)
#重みの取得
param=self.param_queue.get()
self.main_Q.set_weights(param[0])
self.target_Q.set_weights(param[1])
t+=1
step+=1
if done:
break
if t>=self.nb_steps:
break
epoch+=1
print("Actor{} episode:{} nb_step:{}({}) reward:{} step:{}".format(self.id,epoch,t,self.nb_steps,epoch_reward,step))
except KeyboardInterrupt:
print("Actor{} ended".format(self.id))
self.actor_working[self.id]=False
return
print("Actor{} ended.".format(self.id))
self.actor_working[self.id]=False
return
Actorは、Leanerとは違って終了条件が指定された回数行動することになっています。
流れとしては、
1.行動を決定、実際に行動して報酬を受け取る
2.状況・行動・結果・報酬を溜める
3.一定量たまったらそれらをMemoryに送信
4.必要があればLeanerから最新の重みを取得
最後の8行はCtrl+Cの実装です
main関数
import multiprocessing as mp
from Actor import Actor
from Leaner import Leaner
import time
from keras.models import load_model
import ctypes
def A(exp_queue,param_queue,nb_steps,warmup_steps,num_actions,id,num_actors,actor_working):
if id==0:
actor=Actor("CartPole-v0",exp_queue,param_queue,nb_steps,warmup_steps,num_actions,id,num_actors,actor_working,max_epsilon=0.7)
else:
actor=Actor("CartPole-v0",exp_queue,param_queue,nb_steps,warmup_steps,num_actions,id,num_actors,actor_working,max_epsilon=0.7)
actor.run()
return
def L(exp_queue,param_queue,num_actions,memory_size,train_batch_size,actor_working,save_name):
leaner=Leaner("CartPole-v0",exp_queue,param_queue,num_actions,memory_size,train_batch_size,actor_working,save_name)
leaner.run()
return
if __name__=="__main__":
num_actors=3 #Actorの数
num_actions=2 #行動の種類数
nb_steps=10000 #試行回数
warmup_steps=200 #ランダムに行動する回数
memory_size=100000 #Memoryの上限
train_batch_size=32 #Leanerが一回に使用するデータの数
save_name="CartPole.h5" #ファイルをセーブする時の名前
#プロセス間通信用
exp_queue=mp.Queue(5000)
param_queue=mp.Queue(int(num_actors))
actor_working=mp.Value(ctypes.c_uint*num_actors)
for i in range(num_actors):
actor_working[i]=False
#並列処理(Leaner)
ps=[]
ps.append(mp.Process(target=L, args=(exp_queue,param_queue,num_actions,memory_size,train_batch_size,actor_working,save_name)))![Something went wrong]()
ps[0].start()
try:
#並列処理(Actor)
for i in range(num_actors):
ps.append(mp.Process(target=A, args=(exp_queue,param_queue,nb_steps,warmup_steps,num_actions,i,num_actors,actor_working)))
ps[i+1].start()
time.sleep(1)
for p in ps:
print(p)
p.join()
except KeyboardInterrupt:
print("end")
メイン関数です。
multiprocessingというモジュールを使ってActor、Leanerを並列で動かしています。
実行結果
実行した結果です(マウスが映り込んでますが...)

...うまく学習できてないですね。
何が問題なんだろう。分かる方がいらっしゃれば教えていただけると幸いです
ソースコードはgithubに公開しています