この記事はAmazon Web Service Advent Calendar 25日目の記事です。
Auto Scaling Groupsとは
Auto Scaling GroupsはAmazon EC2上で動く機能のひとつで、インスタンスの論理的なグループを定義して、そのグループの総インスタンス数を柔軟に変えることを可能にします。Auto Scaling Groupに対して必要なキャパシティを設定するだけで、Auto Scaling Groupが自動でインスタンスの作成、Bootstrap, Configuration, アプリケーションサービスの立ち上げまでを行ってくれます。この機能を使えばWeb Trafficのピークに合わせて必要な台数を自動で立ち上げていくといったことができるようになります。またコスト削減のため余剰リソースを自動で縮退させていくということも可能になります。
この記事ではTreasure Data内で利用している分散クエリエンジンPrestoを実際にAuto Scaling Groupsを使って運用してみてわかったtipsやハマりどころなどを紹介します。
Auto Scaling Groupsの使い方
詳細なStep by Stepはここでは割愛させていただきますが、Auto Scaling Groupを使うにあたって知っておかなければいけない用語と知識を簡単に紹介します。
- Launch Configuration : Auto Scaling Groupから立ち上げるEC2のインスタンスタイプやAMI、Security Groupsなどを設定する。
- Desired Capacity : そのAuto Scaling Groupで満たすべきインスタンス数。Auto Scaling Groupは自動でこの値を満たすようにインスタンスを増減させる。
- Cooldowns : Auto Scaling Groupで前回発生したイベントから次のイベントを処理するまでの間の時間。Cooldownsを用いると立て続けにイベントが発生した場合でも(e.g. アクセス数のスパイクが一定時間続く)、その度に次々とインスタンスを追加していくことを防ぐことができる。
- Lifecycle Hooks : Auto Scaling Groupから立ち上げられたインスタンスの状態をトリガーにしてアプリケーション側に処理を委譲する機能。後述するCodeDeployとの連携やGraceful Shutdownに用いる。
ここに加えてアプリケーションのデプロイにはAWS CodeDeployを用いました。なぜならLaunch Configurationのみだとアプリケーションのバージョン管理やパッケージの作成、保存などが難しかったからです。なおAuto Scaling GroupsとCodeDeployはCodeDeployのdeployment group作成時に簡単に連携させることができます。
$ aws deploy create-deployment-group \
--application-name SimpleDemoApp \
--auto-scaling-groups CodeDeployDemo-AS-Group \
--deployment-group-name SimpleDemoDG \
--deployment-config-name CodeDeployDefault.OneAtATime \
--service-role-arn service-role-arn
詳細はTutorialをご覧ください.
Prestoとは
PrestoはFacebookで開発された分散SQLエンジンです。現在はオープンソースソフトウェアとなっており、UberやNetflixなど巨大なサービスを支えるデータ分析のためのソフトウェアです。
 [Presto](https://prestodb.io/)
[Presto](https://prestodb.io/)
Prestoはデータを基本的にインメモリで処理するため同種類のHiveなどのソフトウェアとくらべて高速にデータを処理することができます。そのためHadoopなどと比べて比較的小中規模のデータに対してインタラクティブな分析を行いたいときに向いています。ただ0.186からSpill to Diskの機能が入りましたのでより大きなデータでもクエリを完了させることが今後できるようになるかもしれません。
ひとつのPrestoクラスタにはmaster nodeとしてのCoordinatorとslave nodeとしてのWorkerと呼ばれるコンポーネントがあります。クライアントは実行したいクエリをまずCoordinatorに投げます。Coordinatorは専用のHTTPのエンドポイントを提供しているので必要であればセッションパラメタなどとともにクエリを投げます。Coordinatorは受け取ったクエリからクエリの実行計画、最適化を行い各WorkerにクエリのFragmentとしてのTaskを配布します。各Workerは受け取ったTaskを並列に実行し、出力を他のWorkerに投げるなり、どこかのストレージ書くなりといったことをします。
詳細はPrestoのコンセプト参照のこと
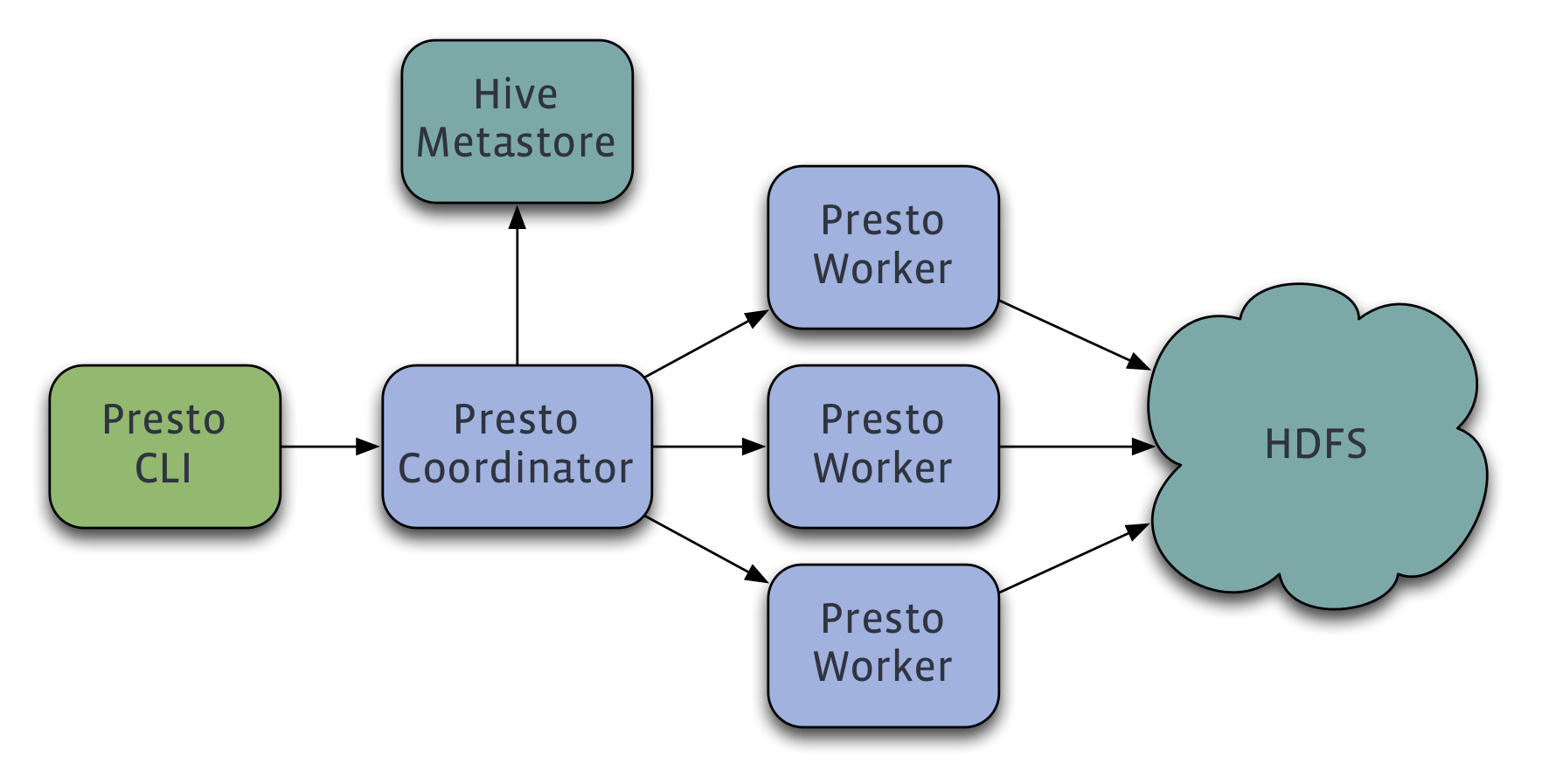
またPrestoはデータソースとして利用できるストレージへのアクセスをConnectorと呼ばれるプラグイン経由で行います。PrestoではこのConnectorと分散処理のレイヤーがきれいに分かれているため既に持っている既存のストレージのデータに対してPrestoを使って分析することができます。既にコミュニティから20以上のプラグインが提供されているので、既にここに必要なものがあれば自前で作る必要もありません。
Prestoクラスタの作成手順
このAuto Scaling Groupsを用いてPrestoクラスタを作る手順は下記のようになります。
- Auto Scaling Groupを作成する
- CoordinatorとWorker用のgroupは別で作成する。なぜならCoordinatorは水平スケーリングしないため
- CoordinatorのAuto Scaling GroupのMin Capacityを1にしておくと誤って削除することがない
- クラスタ内の通信レイテンシを抑えるためひとつのクラスタで一つのPlacement Groupを使うように指定しておく
- CodeDeployのdeployment groupを作成する
- Auto Scaling Groupと1対1で対応するように作成する
- つまりCoordinator用とWorker用のdeployment groupそれぞれ作る
- CodeDeploy用のパッケージを作成する。詳細はこちら参照
- Prestoの場合は必要なJARと
launcher.pyスクリプトをキックするhook scriptが最低必要 - 後述するようにGraceful Shutdownを実現するのであれば、lifecycle hookをトリガーするscriptなども必要
- インスタンス数の調整
-
aws autoscaling set-desired-capacityで行うことができる。CodeDeployは自動で最後の成功したrevisionをdeployしてくれるのでパッケージdeployのあとでこれをやっても構わない
- CodeDeploy経由でパッケージをdeployする
- Coordinator用のdeployment groupとWorker用のdeployment groupからそれぞれパッケージをdeployする (e.g.
aws deploy create-deployment)
これで一つのPrestoクラスタが完成します。各手順の詳細はAuto Scaling GroupsやCodeDeployのドキュメントを参照してください。
ここからはPrestoクラスタを運用する上でAuto Scaling Groupsを使ったときのPros & Consを述べていきたいと思います。
クラスタの作成/拡大が速い
何よりこれが最も大きな改善でした。後述するようにある特定のケースでは上手くいかないこともあるのですが、CodeDeployのdeployment groupの定義も、Auto Scaling GroupsのLaunch Configurationもテンプレート化できるのでクラスタの設定を簡単に複製させていくことができます。またクラスタに対するロードが上がったときでも
- Desired Capacityを設定する
- 待つ
だけで自動でクラスタのCapacityを大きくすることができます。
大量インスタンスの追加に失敗する
CodeDeployには一度に10個までのdeploymentしか実行できないという制約があります。このため一度に何十台も追加しようとする場合 (とりわけクラスタのbootstrap時に発生しますが) そういった場合に10個を超えたインスタンスはCodeDeployがdeployしてheatbeatを送ってくれないため、timeoutしてインスタンス立ち上げに失敗してしまう可能性が高まります。

この場合にはとれる方法は、
- 一度に10台を目安に追加する
- 各インスタンスのdeployを速くする
などが考えられます。一度に何十台も必要なのは多くの場合クラスタの初期作成時だけですが、何度も失敗するのはとても面倒でした。
Graceful ShutdownとLifecyle Hook
PrestoはOLAPシステムなので、その上で走るクエリも数秒で終わるものもあれば、数分から数時間かかるものもあります。またPrestoはクエリの実行に関してFault Tolerantでないので、1つのWorkerノードが落ちていたりすると失敗してしまいます。数時間かけて走らせたクエリがWorkerのShutdownで失敗しては悲しいのでGraceful ShutdownはPrestoのようなシステムでは重要になってきます。
Prestoでの通常のGraceful Shutdownのプロセスは下記のようになります。
- Workerの
/v1/stateにDELETEを送る - Workerは
SHUTTING_DOWN状態になる。このノードでタスクが動いている間この状態が維持される -
SHUTTING_DOWNが終わるとプロセスは停止する
これで晴れてインスタンスと停止することができます。Auto Scaling Groupsでこれを実現する場合にはどうすればよいでしょうか。
Auto Scaling GroupsにはLifecycle Hookという仕組みがあり、インスタンス立ち上げと停止時にあるアクションを待たせることができます。
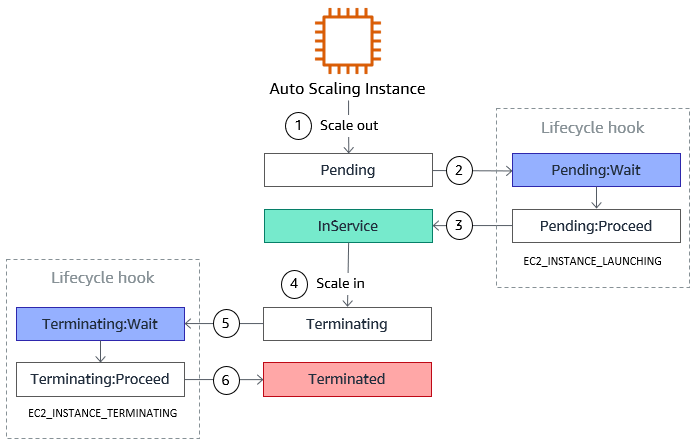
From Auto Scaling Lifecycle Hooks
Lifecycle Hookの登録を行っておくと、立ち上げ時と停止時にそれぞれ
Pending:WaitTerminating:Wait
という状態でインスタンスのbootstrapを待ちます。この間に必要な処理を行い、終わったらcomplete-lifecycle-actionコマンドを送り状態を
Pending:ProceedTerminating:Proceed
に進ませることができます。これをGraceful Shutdownに利用します。
-
put-lifecycle-hookでGraceful Shutdown用のLifecycle Hookを登録します。Shutdown用なので--lifecycle-transitionにautoscaling:EC2_INSTANCE_TERMINATINGを指定します。
$ aws autoscaling put-lifecycle-hook \
--lifecycle-hook-name presto-graceful-shutdown \
--auto-scaling-group-name my-asg \
--lifecycle-transition autoscaling:EC2_INSTANCE_TERMINATING
2.Auto Scaling Groups経由でインスタンスを停止させます。(e.g. Desired Capacityを減らす、terminate-instance-in-auto-scaling-groupコマンドを使う等)
3.先述のように/v1/stateに対してDELETEを送ります。タスクがある間Workerは待ち続けますが、この間、同時にrecord-lifecycle-action-heartbeatを送り続けます。これはAuto Scaling Groupsに「Workerがまだ生きているのでTerminating:Wait状態のまま待っといて」ということを指示します。
4.SHUTTIND_DOWNが完了してWorkerプロセスが死んだことを確認したら、complete-lifecycle-actionで「Terminating:Proceedに進んでいいよ」ということを指示します。これでAuto Scaling Groupsはこのインスタンス停止のためのプロセスを続行できるのです。
問題はこの一連のプロセスを実行する機能はPrestoにはないので、自前で作る必要があります。簡単なのはcronでWorkerプロセスの状態を見て、生きていればheartbeatを自インスタンスIDとともに送り続け、死んだらcompleteを送るというのがよいかと思います。
Capacity Metrics
Auto Scaling Groupsを使う最大のメリットはあるメトリクスの増減をトリガーにして自動でクラスタのキャパシティを調整できることです。シンプルなWebアプリケーションであれば、アクセス数などから必要キャパシティの見積もりを行うことができます。Prestoでは何をみればよいでしょうか。最後に幾つかPrestoクラスタのキャパシティを計るのに有用なメトリクスを考えてみたいと思います。
同時実行クエリ数
クエリが増えればそれだけ必要な台数も増えます。ただPrestoのようなOLAPシステムに流れるクエリの負荷というのはクエリごとにかなり大きな差があります。数百GBのテーブルフルスキャンしてJOINしたクエリと、小さなテーブルの1つのカラムのSELECTで終わるクエリでは全くクラスタに与える負荷は違います。もう少しクエリ毎の負荷を考えたメトリクスが必要そうです。
メモリ
クラスタ全体で利用できるメモリはWorkerの台数によって決まります。Prestoはオンメモリの分散SQLエンジンなので、すべてのクエリは基本的にメモリリソースを使います。Prestoには3種類のメモリプールがあり、各クエリはここから必要なメモリを割り当ててもらいます。
- General Pool: まずすべてのクエリがメモリを割り当てられるのがGeneral Memory Pool
- Reserved Pool: General Poolを使い切った場合に最もメモリを使っているクエリをReserved Poolに移して実行
- System Pool: Prestoのクエリエンジンが使うMemory Pool
そのため概ねGeneral Pool + Reserved PoolがPresto上で動くクエリのメモリ消費量となります。
Driver
DriverはPrestoでの最小の並列実行の単位でJVMのスレッド上で動きます。Driverはある入力を得て幾つかもOperatorを適用します。その出力はTaskに集められまた他のTaskのの入力となります。Driverは各クエリが実行するOperatorを集めたものなので、Driverが多いことはつまりCPUを多く使うクエリともいえます。
分散SQLの実行を大きく支えるリソースはメモリとCPUなので最終的には
- General Pool + Rerserved Poolの使用量
- Driver数
をキャパシティを計るターゲットとしてTarget Trackingから取れるようになると、本当のAuto Scalingが実現できることになります。
まとめ
分散SQLエンジンのCapacity PlanningやDeploymentはしばしば手間のかかる仕事となるので、せっかくAWS上でクラスタを運用しているのであれば効果の高いリソース(CodeDeployやAuto Scaling Groups)は今後も積極的に使っていきたいと思いました。
Treasure Dataではこのように分散SQLエンジンの足回りやCloudとのインテグレーションを支えてくれるエンジニアを絶賛募集しております!