この記事はDistributed computing Advent Calendar8日目の記事です。
Hadoopをはじめとする大規模な計算リソースを効率よく使うにはリソーススケジューラが必要です。分散システムでのリソーススケジューラといえばYARNやMesosといったシステムが有名ですが、今回は分散システムでの効率のよいスケジューリングを定義したDominant Resource Fairnessという考え方とそのYARN上での実装についてまとめてみました。
"Fairness"の難しさ
分散システムに限らずリソーススケジューリングにおいて目標とされるもののひとつとして"Fairness"があります。曖昧な言葉ではありますが、効率のよいシステムでは限られたリソースを複数のユーザ、タスク間で共有してそれぞれの要求を満たしつつ、全体のスループットもあげていくことが求められます。このときにどのようにリソースを割り振れば"Fair"といえるような状況になるでしょうか。
例えばOSが各プロセスをスケジューリングするときは各プロセスが消費しているCPU時間が(それが重みづきであれ)均等になるようにスケジューリングされる場合が多いと思います。どのプロセスも等しくCPUが使えれば直感的にも"Fair"な感じがしますし、多くの場合上手くいきます。これはスケジューラがCPU時間という単一のリソースを均等に分配することを考えてスケジューリングするためシンプルなアルゴリズムでも上手くいくようです。
ではCPUだけでなく、そのプロセスが使うMemory, Disk, I/Oなどの複数のリソースの種類を考慮して"Fairness"を考える場合はどうすればよいでしょうか。各ユーザ、タスクによって必要なリソースは異なるため簡単には計算できなさそうです。例えば<CPU, Memory>がそれぞれトータルで<10core, 10GB>のシステムがあったとしてユーザAは<1core, 5GB>, ユーザBは<5core, 2GB>を要求するタスクを幾つか投げようとします。それぞれいくつのタスクを動かせばユーザAとユーザBのリソース利用は”Fair"になるでようか、core使用量が半々になるように? memory使用量が半々になるように?
このような問題を幾つかの好ましい性質を備えつつ実現したのがDominant Resource Fairnessというアルゴリズムです。
Dominant Resource Fairness(DRF)とは?
DRFの考え方自体はとてもシンプルです。
リソースの種類毎のシステムのtotal capacityを$R$ ($r_1$, $r_2$はCPUとかmemoryなどと考えてください)
R = <r_1, r_2,...,r_m>
ユーザ$i$に割り当てられたリソースを$U_i$
U_i = <u_{i, 1}, u_{i, 2}, ..., u_{i, m}>
としたときにユーザ$i$のDominant Shareを以下のように定義します。
s_i = max_j \{ u_{i, j} / r_{j} \}
つまりユーザ$i$の消費するリソースの中でそのリソースのシステム全体の対する割合が最も高いものの消費割合をDominant Shareとよびます。DRFではこの$s_i$が全ユーザで均等になるようにスケジューリングを行います。例えばシステム全体でCPU,Memoryがそれぞれ<9core, 18GB>用意されているとしてユーザAが$D_A=$<1core, 4GB>を$x$タスク, ユーザBが$D_B=$<3core, 1GB>を$y$タスクはしらせようとしています。(これらをDemand Vectorといいます)このときDRFによるスケジューリングは下記の最適化問題を解くことで得られます。
\begin{align}
&max(x, y) \\
&subject\ to \\
x + 3y &\leq 9\ (CPU\ constraint)\\
4x + y &\leq 18\ (Memory\ constraint)\\
\frac{2x}{9} &= \frac{y}{3} \ (Equalize\ dominant\ shares)\\
\end{align}
これを解くと$x=3, y=2$となり下記のようにスケジューリングされます。
 https://people.eecs.berkeley.edu/~alig/papers/drf.pdf
https://people.eecs.berkeley.edu/~alig/papers/drf.pdf
このアルゴリズム、とてもシンプルなのですが、論文で紹介されていたような他のアルゴリズム(Asset Fairness, CEEI)にはない好ましい性質があります。それが下記の4つです。
- Sharing Incentive
- Strategy-proofness
- Envy-freeness
- Pareto efficiency
Sharing Incentive
システムを別個のn個のシステムに分けるよりもひとつのシステムを共有した方が得するような性質を満たしているかどうかを示します。
例えば2人のユーザがいる$R= <30, 30>$となるシステムに対して$D_1 = <1, 3>$,$D_2=<1, 1>$を要求するとします。このとき例えば論文で比較されているAsset Fairnessというすべてのリソースの使用を考慮したアルゴリズムを使うと$U_1=<6,18>$,$U_2=<12,12>$となります。しかしユーザ2はどちらのリソースに対しても単純にシステムを2分割して利用できるはずの$<15, 15>$を利用できていないので、誰かとシステムを共有するくらいなら分割してしまった方がいいと考えるわけです。
このような状況に陥らないようにする性質がSharing Incentiveです。DRFはこれを満たします。
Strategy-proofness
だれかが本来必要なソース以上のリソースを偽って要求した場合、得をするとは限らないことを保証するのがStrategy-proofnessです。
例えばシステムのリソースが$R=<100,100>$のときに、ユーザ1が$D_1=<16,1>$, ユーザ2が$D_2=<1,2>$を要求したとします。この時例えばCEEIというミクロ経済学の均衡理論に基づいたアルゴリズムを使用するとユーザ1, ユーザ2への割当てタスクはそれぞれ$\frac{100}{31} \approx 3.2$と$\frac{1500}{31}\approx48.8$となります。ここでユーザ1が偽って$D_1=<16,8>$を要求するとCEEIはそれぞれ$\frac{25}{6}\approx4.2$と$\frac{100}{3}\approx33.3$となり純粋にユーザAへの割当が増えてしまいました。
DRFではこのように嘘つきが得をするようなことがないようになっています。
※ただしStrategy-proofnessに関しては元論文に書いてある前提が私も理解しきれていません。論文だとStrategy-proofnessは「はじめに要求したリソースを途中から増やしても割当が増えるわけではない」という意味に読めました。最初から嘘をついてリソース要求した場合にはそれに基づいてDRFを計算してしまいます。そもそもリソーススケジューラから見て最初から嘘をついて要求をしてきたユーザを見破るようなことはできない気がするので、このような前提になっているのかもしれません。
Envy-freeness
他人をうらやむことがない。論文の中では他のユーザに割り当てられたあらゆるリソースのシェアが自分のシェアよりも多い場合がない状態として定義されています。例えばリソース割り当てがそれぞれ$U_1 = <1, 4>$と$U_2 = <2, 6>$の場合ユーザ1はユーザ2の割り当てでDominant Shareを純増させることができるので、Envyに思うはずです。
Pareto efficiency
パレート最適という経済学の概念を指します。これは誰か他の人のリソースシェアを下げない限り自分のリソースシェアを上げることができないという状況が誰にとっても成り立っているような状況を指します。つまり、持てるリソースを効率的に使えていると考えることができます。
この他にも単調性というシステムリソース増やしたらみんなの割当も増えるとか、ユーザ減ったらみんなの割当増えるといった好ましい性質もあるみたいです。
では次に上記の性質の中で最も重要そう(且つ面白そうな)Pareto efficiencyについて考えてみます。
Progressive filling
まずDRFがアルゴリズムとしてどのように書き下されるか示しておきたいと思います。
 Algorithm1: DRF pseudo-code
Algorithm1: DRF pseudo-code
Dominant Shareが一番低いユーザのタスクをひとつずつ取り出していくだけですね。このアルゴリズムはDemand Vectorのscalingさえすればmin-max schedulingで用いられるProgressive fillingというアルゴリズムと同じアルゴリズムになります。Progressive fillingの大きな特徴は各ユーザのDominant Shareが固定の割合で増えていくことです。固定の割合でDominant Shareを徐々に増やしていきすべてのユーザで増やすことができなくなった、つまりシステムリソースを使い切った時点でスケジューリングを終了します。例えばユーザ$i$の要求するリソース$D_i$を下記のように定義します。
D_i = <d_{i,1}, d_{i, 2}, ..., d_{i, m}>
$r_k$をこのユーザのDominant ResourceとするとDominant Shareは
s_i = \frac{d_{i, k}}{r_k}
となります。$r_k$はシステム全体のリソースです。Algorithm1のユーザ$i$の要求リソースを下記のようにスケーリングします。
D_i^\prime = \frac{\epsilon}{s_i} D_i = \frac{\epsilon}{s_i} <d_{i,1}, d_{i, 2}, ..., d_{i, m}>
$\epsilon$は任意の定数です。この$D_i^\prime$を各イテレーションでの割当てとすると毎回Dominant Resourceは$\frac{\epsilon}{s_i}d_{i, k} = \epsilon r_k$の分だけ増えます。(ユーザ$i$の要求リソースが固定の場合Dominant Resourceのタイプは変わらないため)つまり、Dominant Shareは$(\epsilon r_k) / r_k = \epsilon$の一定の分だけ増えていくことになります。これは一般にすべてのユーザで成り立ちProgressive fillingの大きな特徴となります。
それではこのProgressive fillingで実装されたDRFのPareto efficiencyを考えてみます。まず必要な補題をひとつ考えておきます。
DRFでのリソーススケジューリングではすべてのユーザが少なくともひとつの飽和したリソースに割当てられている
今Progressive fillingでのDRFスケジューリングが完了したとします。**飽和したリソース(Saturated Resource)**というのはシステムのキャパシティ限界まで割当たってしまったリソースのことです。つまりすべてのユーザが少なくともこれ以上どうやっても増やせないリソースを要求しているということです。これを背理法で示してみます。つまりあるユーザ$i$はシステムのキャパシティに対してまだ余裕のあるリソースのみを要求しているとします。その場合にはこのユーザに対してリソースを割り当ててDominant Shareを増やすことができますが、これはProgressive fillingの前提と矛盾することになります。なぜならProgressive fillingは全ユーザのDominant Shareが増やせなくなった時点で終了するからです。これはProgressive fillingでのDRFスケジューリングが完了したということと矛盾します。つまりすべてのユーザはシステムキャパシティに対して飽和したリソースを少なくとも1つは要求していることになります。
この補題をもとにPareto efficiencyを示してみます。
DRFはPareto efficientである
Progressive fillingでのDRFスケジューリングが完了したとします。このときユーザ$i$はDominant Share, $s_i$を他のどのユーザのDominant Shareを減らすことなく増やすことができると仮定します。上記の補題からユーザ$i$は少なくともシステムキャパシティに対して飽和したリソース($r_k$)を少なくともひとつ要求しています。このとき以下の2パターンが考えられます。
- 他のどのユーザも$r_k$を要求していない -> $r_k$はすべてユーザ$i$が使っているのでこれ以上増やしようがない
- $r_k$を要求するユーザがいる -> ユーザ$i$の$r_k$割当てを増やすと、他のユーザ$j$の$r_k$への割当てを減らすことになる。
Progressive fillingの下では各ユーザへ割り当てられたリソースはそのユーザの要求リソースに比例した形になります。
U_i = \sigma D_i
つまりユーザ$j$への任意のリソース割当てを減らすことはかならずDominant Resourceへの割当ても減らすことを意味します。Dominant Resourceへの割当てが減ったユーザ$j$のDominant Shareは下がることになります。しかしこれはユーザ$i$が他のどのユーザのDominant Shareを減らすことなく自身のDominant Shareを増やすことができるという仮定に矛盾します。よって他のユーザのDominant Shareを減らすことなく自身のDominant Shareを増やすことはできません。これがPareto efficiencyの定義でした。
この他にもSharing incentiveやEnvy-freenessに証明も元論文にのっているので是非興味がありましたら見てみてください。
YARNにおけるDRF
ここまで長くなりましたが、このDRFがYARNではどのように実装されているか見てみます。YARNには組み込みでFifoScheduler, FairScheduler, CapacitySchedulerの3つがあります。このうちFairSchedulerとCapacitySchedulerは内部にキューを持っていてユーザ、部署など毎にリソース管理をすることができます。これらのキュー、タスク毎の割当てを決めるのがSchedulingPolicyで"fifo"/"fair"/"drf"がありますが、現状複数選べるようになっているのはFairSchedulerのみのようです。簡単にいうと
- "fifo": 早いもの順
- "fair": Memoryだけ考慮したmin-max scheduling
- "drf": Memory, CPUを考慮したdominant resource fair scheduling
デフォルトでは"fair"になっているので、DRFを使うにはfair-scheduler.xmlのキューエントリのschedulingPolicyを変更する必要があります。詳細は日本語でしたら[翻訳]Hadoop: Fair Schedulerを参照してください。
DRFの計算を担うのはDominantResourceFairnessPolicyというクラスでこのAPIをざっくり見てみると
public class DominantResourceFairnessPolicy extends SchedulingPolicy {
@Override
// Schedulableのソートを担う。Container Allocation用
public Comparator<Schedulable> getComparator();
@Override
// 与えられたSchedulableのシェアを計算。主に更新用
public void computeShares(Collection<? extends Schedulable> schedulables,
Resource totalResources);
}
Schedulableというのはスケジューリングの優先順位を考える対象で実体はキューあるいはYARNアプリケーションを指します。Comparator<Schedulable>はSchedulable同士の大小を比較、computeSharesはキューあるいはアプリケーションとクラスタ全体のリソースを受け取ってそれぞれのシェアをアップデートします。
リソース要求があって実際にコンテナを割り当てるのはFairScheduler#attemptSchedulingで行われます。
@VisibleForTesting
void attemptScheduling(FSSchedulerNode node) {
// ...
Resource assignment = queueMgr.getRootQueue().assignContainer(node);
// ...
}
キューはツリー上に定義されているのでここでルートキューに対してassignContainerを呼ぶことで子のキューに対して再帰的によばれていくようになっています。深さ優先で最もDominant Shareが小さいキューを探していきます。子がいるキュー(FSParentQueue)では
@Override
public Resource assignContainer(FSSchedulerNode node) {
Resource assigned = Resources.none();
// ...
// Hold the write lock when sorting childQueues
writeLock.lock();
try {
// 子キューをDRF policyに基いてソートする。このときDominant Shareが小さいものが先頭にくる
Collections.sort(childQueues, policy.getComparator());
} finally {
writeLock.unlock();
}
// 子キューに対して割当てを順番に試していく
readLock.lock();
try {
for (FSQueue child : childQueues) {
assigned = child.assignContainer(node);
if (!Resources.equals(assigned, Resources.none())) {
break;
}
}
} finally {
readLock.unlock();
}
return assigned;
}
葉となるキュー(FSLeafQueue)では
@Override
public Resource assignContainer(FSSchedulerNode node) {
Resource assigned = none();
// ...
// このキューにsubmitされたアプリケーション FSAppAttemptもSchedulable。
// fetchAppsWithDemandで内部的にソートされている
for (FSAppAttempt sched : fetchAppsWithDemand()) {
if (SchedulerAppUtils.isPlaceBlacklisted(sched, node, LOG)) {
continue;
}
assigned = sched.assignContainer(node);
if (!assigned.equals(none())) {
if (LOG.isDebugEnabled()) {
LOG.debug("Assigned container in queue:" + getName() + " " +
"container:" + assigned);
}
// 割当てが起こったらここでスケジューリングを終了
break;
}
}
return assigned;
}
というわけで全体像としては下記のようになります。
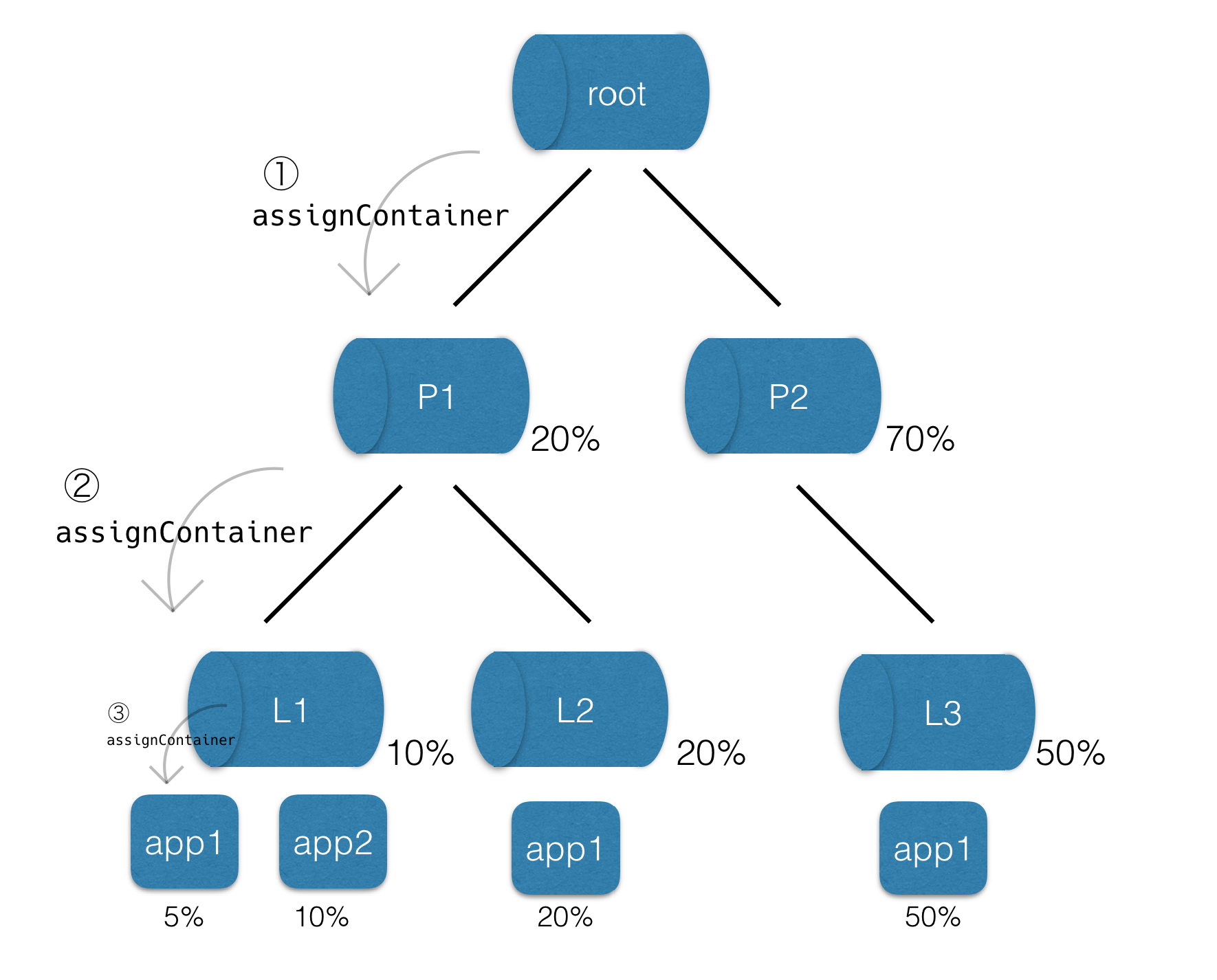
rootの子キューをDominant Shareでソートして一番小さいものを選ぶ、またそのキューに子がいたらソートして小さいものを選ぶ。Leafまでぶち当たったらその中のアプリケーションをソートして一番Dominant Shareが小さいアプリケーションにリソース(Container)を割り当てます。上の図で示されている数字は各キューのDominant Shareを表していますが、Dominant Shareは異なるリソースのシェア同士の比較をする可能性があるので必ずしも各階層で足して100%にはなりません。
最後にこのDRFに基いてソートしている部分を見てみます。このソートはDominantResourceFairnessComparatorが担っており、Comparatorinterfaceを実装しているのでTreeSetなどに組み込むことができるようになっています。核となるcompareメソッドは以下です。
@Override
public int compare(Schedulable s1, Schedulable s2) {
// ResourceWeightsはMemory, CPUそれぞれのリソースに重みを考慮したリソースです。
ResourceWeights sharesOfCluster1 = new ResourceWeights();
ResourceWeights sharesOfCluster2 = new ResourceWeights();
// それぞれのMinimumなリソース
ResourceWeights sharesOfMinShare1 = new ResourceWeights();
ResourceWeights sharesOfMinShare2 = new ResourceWeights();
// クラスタ全体に対するシェアでソートしたリソースタイプ。Dominant Shareとなるリソースがわかります
ResourceType[] resourceOrder1 = new ResourceType[NUM_RESOURCES];
ResourceType[] resourceOrder2 = new ResourceType[NUM_RESOURCES];
// シェアを計算する。詳細に関しては後述。
// Memory, CPUの重み付きシェアが降順にソートされsharesOfCluster*, resourceOrder*に入れられます。
calculateShares(s1.getResourceUsage(),
clusterCapacity, sharesOfCluster1, resourceOrder1, s1.getWeights());
// Miminum計算するときは重みをそれぞれ1にしています
calculateShares(s1.getResourceUsage(),
s1.getMinShare(), sharesOfMinShare1, null, ResourceWeights.NEUTRAL);
calculateShares(s2.getResourceUsage(),
clusterCapacity, sharesOfCluster2, resourceOrder2, s2.getWeights());
calculateShares(s2.getResourceUsage(),
s2.getMinShare(), sharesOfMinShare2, null, ResourceWeights.NEUTRAL);
// Dominant ShareがMinimumさえ満たしていない場合
boolean s1Needy = sharesOfMinShare1.getWeight(resourceOrder1[0]) < 1.0f;
boolean s2Needy = sharesOfMinShare2.getWeight(resourceOrder2[0]) < 1.0f;
int res = 0;
if (!s2Needy && !s1Needy) {
// それぞれの比較。詳細は後述。
res = compareShares(sharesOfCluster1, sharesOfCluster2,
resourceOrder1, resourceOrder2);
} else if (s1Needy && !s2Needy) {
// Minimumを満たしていないs1を先に
res = -1;
} else if (s2Needy && !s1Needy) {
// Minimumを満たしていないs2を先に
res = 1;
} else { // both are needy below min share
res = compareShares(sharesOfMinShare1, sharesOfMinShare2,
resourceOrder1, resourceOrder2);
}
if (res == 0) {
// Dominant Shareが同じ場合は早いもの勝ち
res = (int)(s1.getStartTime() - s2.getStartTime());
}
return res;
}
calculateSharesの実装は下記のようになっています。MemoryとCPUに関して重みを考慮したシェアを計算し、Dominant Shareが大きい順に並びかえています。
void calculateShares(Resource resource, Resource pool,
ResourceWeights shares, ResourceType[] resourceOrder, ResourceWeights weights) {
// Memoryの重み付きShare
shares.setWeight(MEMORY, (float)resource.getMemorySize() /
(pool.getMemorySize() * weights.getWeight(MEMORY)));
// CPUの重み付きShare
shares.setWeight(CPU, (float)resource.getVirtualCores() /
(pool.getVirtualCores() * weights.getWeight(CPU)));
// shareが大きいリソースタイプ順に並び替える
if (resourceOrder != null) {
if (shares.getWeight(MEMORY) > shares.getWeight(CPU)) {
resourceOrder[0] = MEMORY;
resourceOrder[1] = CPU;
} else {
resourceOrder[0] = CPU;
resourceOrder[1] = MEMORY;
}
}
}
そしてcompareするコードはこちら。それぞれのDominant Shareはわかったので、順番に比較するだけ。
private int compareShares(ResourceWeights shares1, ResourceWeights shares2,
ResourceType[] resourceOrder1, ResourceType[] resourceOrder2) {
for (int i = 0; i < resourceOrder1.length; i++) {
// Dominant Share同士を比較
int ret = (int)Math.signum(shares1.getWeight(resourceOrder1[i])
- shares2.getWeight(resourceOrder2[i]));
if (ret != 0) {
return ret;
}
}
return 0;
}
Dominant Shareが同じ場合には次にDominantなResourceのShareを比較します。これで最もDominant Shareが低いキュー、アプリケーションが得られるのでこいつにリソースを割り当ててあげます。DRF自体はリソースタイプがいくつあっても比較できる一般的なアルゴリズムですが、YARNのDominantResouceFairnessPolicyはMemory, CPUに関してベタに書いてありました。
まとめ
YARNのスケジューラ、詳細までは追えていなかったのですが、DRFという研究に基いて実装されていました。ちなみにDRFは同じリソーススケジューラであるMesosにも実装されているということをMesosソースコードリーディングで知りました。分散システムのリソース管理を勉強したい方にとってはとてもよい勉強会だと思います。