はじめに
本記事では、物体検出アルゴリズムであるYOLOのAIモデル学習の方法について解説します。また、前回の記事で行なったデータセットのデータ拡張前後でモデルの精度を評価、比較します。
※前回のデータセットのデータ拡張についての記事はこちらです。
https://qiita.com/LatanKee/items/58c3d5db1a601c513146
本記事でモデル学習に利用したデータセットについては上記の記事の中で解説しています。
本記事で獲得できるスキル
・YOLOのモデル学習
・AIモデルの評価、比較
・データ拡張によるAIモデルの精度向上
※物体検出の基本知識とAIモデルの評価指標についてはこちらで解説しています。
https://qiita.com/LatanKee/items/91f1cbdfa9b0e80f4fe8
環境
・Windows 11 Home
・Google Colaboratory
※Colabは無料版でもモデル学習は可能ですが、時間が掛かり、スクリプト実行中にランタイムの接続が切断されます。筆者は100コンピューティング単位につき、1,179円のPay As You GoプランでT4を利用しています。(2025年5月28日現在)
YOLOのモデル学習の手順
1)YOLOv8 ライブラリのインストール
pip install ultralytics
2)データ拡張後のデータセットで学習実行(YOLOv8n 100エポック)
from ultralytics import YOLO
# 学習するモデル(軽量な yoloV8n を例に)
model = YOLO('yolov8n.pt') # 他に yolov8s.pt, yolov8m.pt, yolov8l.pt, yolov8x.pt も選択可
# 学習実行
model.train(
data='/content/drive/MyDrive/Traffic_Project/datasets/data.yaml',
epochs=100,
imgsz=640,
batch=16,
workers=2,
name='yolov8_traffic_signs',
project='/content/drive/MyDrive/Traffic_Project/datasets/Albumentations/runs',
verbose=True
)
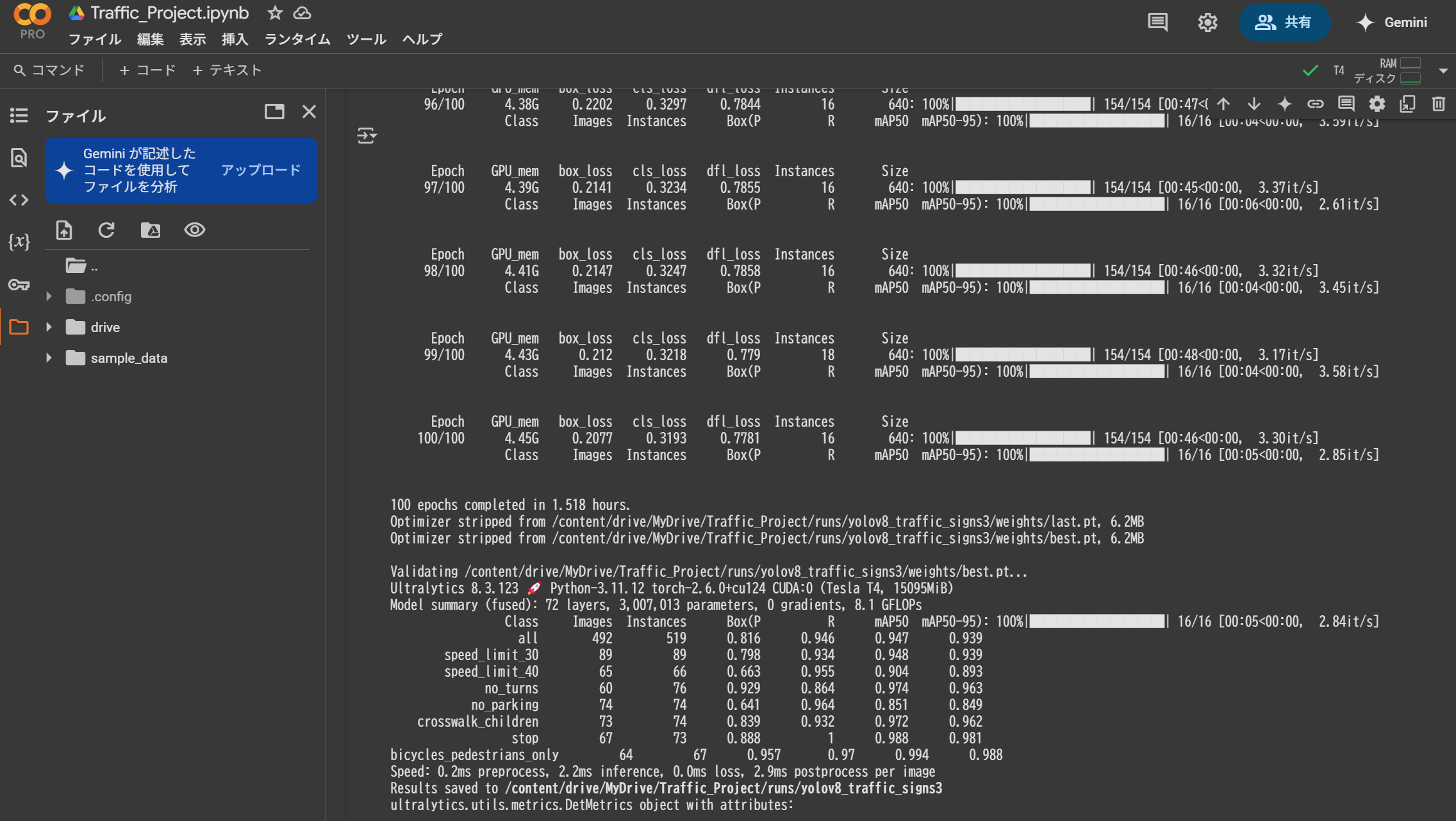
実行結果
データセット:2956枚の画像データ(Train2464+Valid492)
GPU:T4
学習時間:1.518時間/100エポック
以上でYOLOのモデル学習は終わりです。簡単ですね。
スクリプトの内、重要なのは下記の行の通り、projectオプションを設定することです。
project='/content/drive/MyDrive/Traffic_Project/runs',
このオプションを省くと、セッションが切断された時に、学習結果が消えてしまいます。私は何時間も掛けた学習結果を無にするという失敗を何度かしていますので、みなさんもご注意ください。
データ拡張前のオリジナルデータセットの作成
続いて、データセットのデータ拡張前と後でモデルの精度を比較します。
そのために、まずデータ拡張前のオリジナルデータセットを次の割合で分割します。
■データセットの割合
・train 80%
・valid 16%
・test 4%
1) GoogleDriveのマウント
from google.colab import drive
drive.mount('/content/drive')
2)オリジナルデータセットの分割
import os
import shutil
from sklearn.model_selection import train_test_split
# 拡張前のデータセットを対象
images_dir = '/content/drive/MyDrive/Traffic_Project/datasets/all_images'
labels_dir = '/content/drive/MyDrive/Traffic_Project/datasets/all_labels'
# 保存先:original_only 配下に train, valid, test
base_output_dir = '/content/drive/MyDrive/Traffic_Project/datasets/original_only'
train_img_dir = os.path.join(base_output_dir, 'train/images')
train_lbl_dir = os.path.join(base_output_dir, 'train/labels')
valid_img_dir = os.path.join(base_output_dir, 'valid/images')
valid_lbl_dir = os.path.join(base_output_dir, 'valid/labels')
test_img_dir = os.path.join(base_output_dir, 'test/images')
test_lbl_dir = os.path.join(base_output_dir, 'test/labels')
# ディレクトリ作成
for path in [train_img_dir, train_lbl_dir, valid_img_dir, valid_lbl_dir, test_img_dir, test_lbl_dir]:
os.makedirs(path, exist_ok=True)
# 画像ファイル一覧
image_files = [f for f in os.listdir(images_dir) if f.lower().endswith(('.jpg', '.jpeg', '.png'))]
# 分割 1段階目:80% train、20% 残り
train_files, remaining_files = train_test_split(image_files, test_size=0.2, random_state=42)
# 分割 2段階目:残りを valid: test = 80:20 → valid: 16%, test: 4%
valid_files, test_files = train_test_split(remaining_files, test_size=0.2, random_state=42)
# コピー関数
def copy_split_data(file_list, src_img_dir, src_lbl_dir, dst_img_dir, dst_lbl_dir):
for img_file in file_list:
lbl_file = os.path.splitext(img_file)[0] + '.txt'
shutil.copy2(os.path.join(src_img_dir, img_file), os.path.join(dst_img_dir, img_file))
lbl_path = os.path.join(src_lbl_dir, lbl_file)
if os.path.exists(lbl_path):
shutil.copy2(lbl_path, os.path.join(dst_lbl_dir, lbl_file))
# 分割実行
copy_split_data(train_files, images_dir, labels_dir, train_img_dir, train_lbl_dir)
copy_split_data(valid_files, images_dir, labels_dir, valid_img_dir, valid_lbl_dir)
copy_split_data(test_files, images_dir, labels_dir, test_img_dir, test_lbl_dir)
print("✅ データ拡張前の original_only 分割完了:")
print(f" - Train: {len(train_files)} 枚")
print(f" - Valid: {len(valid_files)} 枚")
print(f" - Test : {len(test_files)} 枚")
実行結果
✅ データ拡張前の original_only 分割完了:
- Train: 224 枚
- Valid: 44 枚
- Test : 12 枚
3)データ拡張前のオリジナルデータセットで学習実行(YOLOv8n 100エポック)
from ultralytics import YOLO
# 学習するモデル(軽量な yoloV8n を例に)
model = YOLO('yolov8n.pt') # 他に yolov8s.pt, yolov8m.pt, yolov8l.pt, yolov8x.pt も選択可
# 学習実行
model.train(
data='/content/drive/MyDrive/Traffic_Project/datasets/original_only/original_data.yaml',
epochs=100,
imgsz=640,
batch=16,
workers=2,
name='original_datasets_yolov8_traffic_signs',
project='/content/drive/MyDrive/Traffic_Project/datasets/original_only/runs',
verbose=True
)
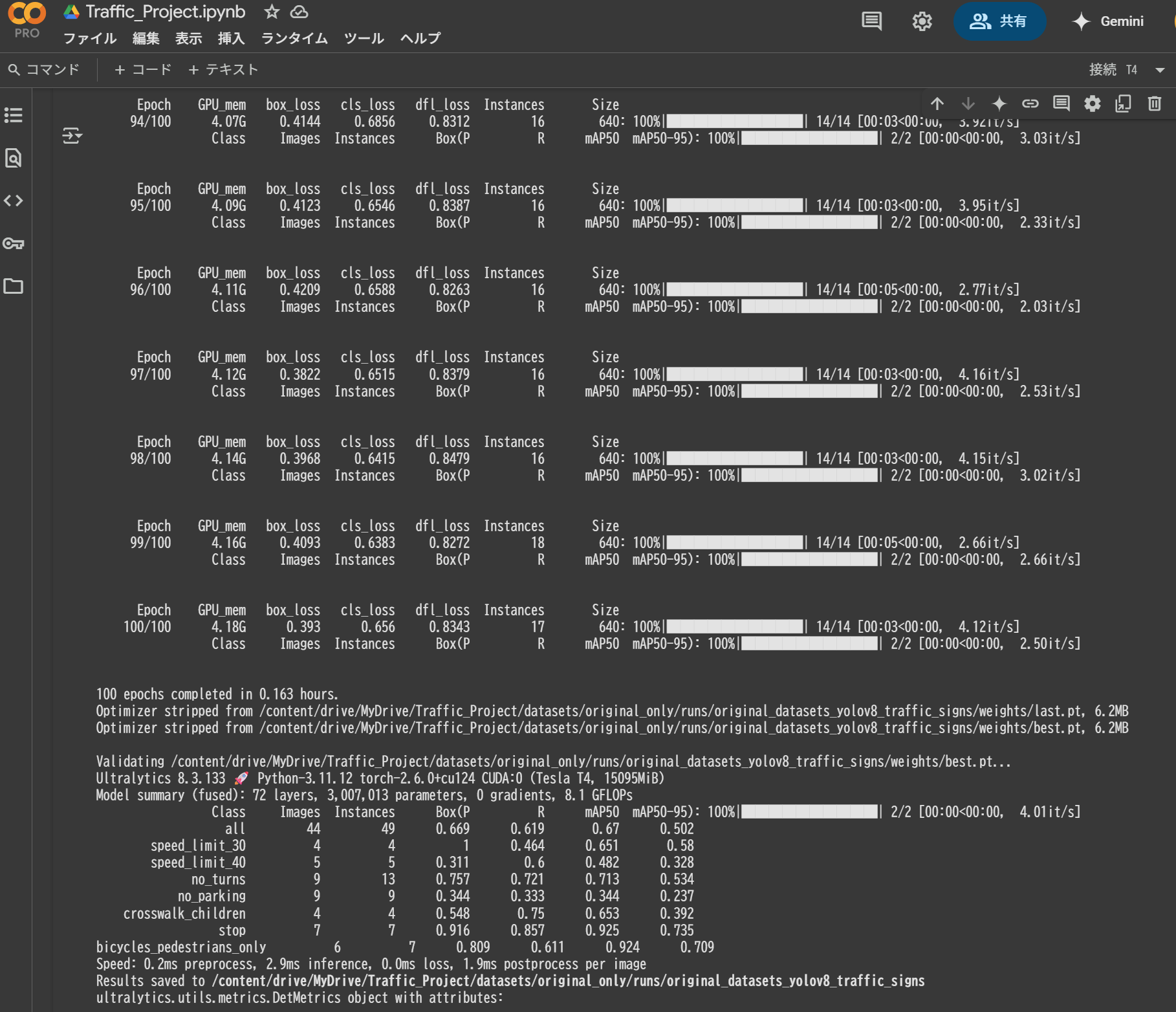
実行結果
データセット:268枚の画像データ(Train224+Valid44)
GPU:T4
学習時間:0.163時間/100エポック
データ拡張有無でモデルの精度を比較
では、早速モデルの精度を比較しましょう。
モデルの評価指標はモデルの学習の際にprojectのオプションで設定したrunsフォルダ(Google Drive)に格納されています。
例:
project='/content/drive/MyDrive/Traffic_Project/datasets/Albumentations/runs',
学習条件と概要
| 項目 | 拡張なし | 拡張あり |
|---|---|---|
| データセット | 268枚(Train 224 + Valid 44) | 2,956枚(Train 2,464 + Valid 492) |
| 使用GPU | T4 | T4 |
| 学習時間(100ep) | 0.163時間(約10分) | 1.518時間(約1時間30分) |
結論
結論、データセット拡張は学習性能・汎化性能を大幅に改善する効果が確認できました。精度曲線の傾向(特にmAPの伸び)は、データ数の影響が強いことを示唆しています。
データ拡張なし
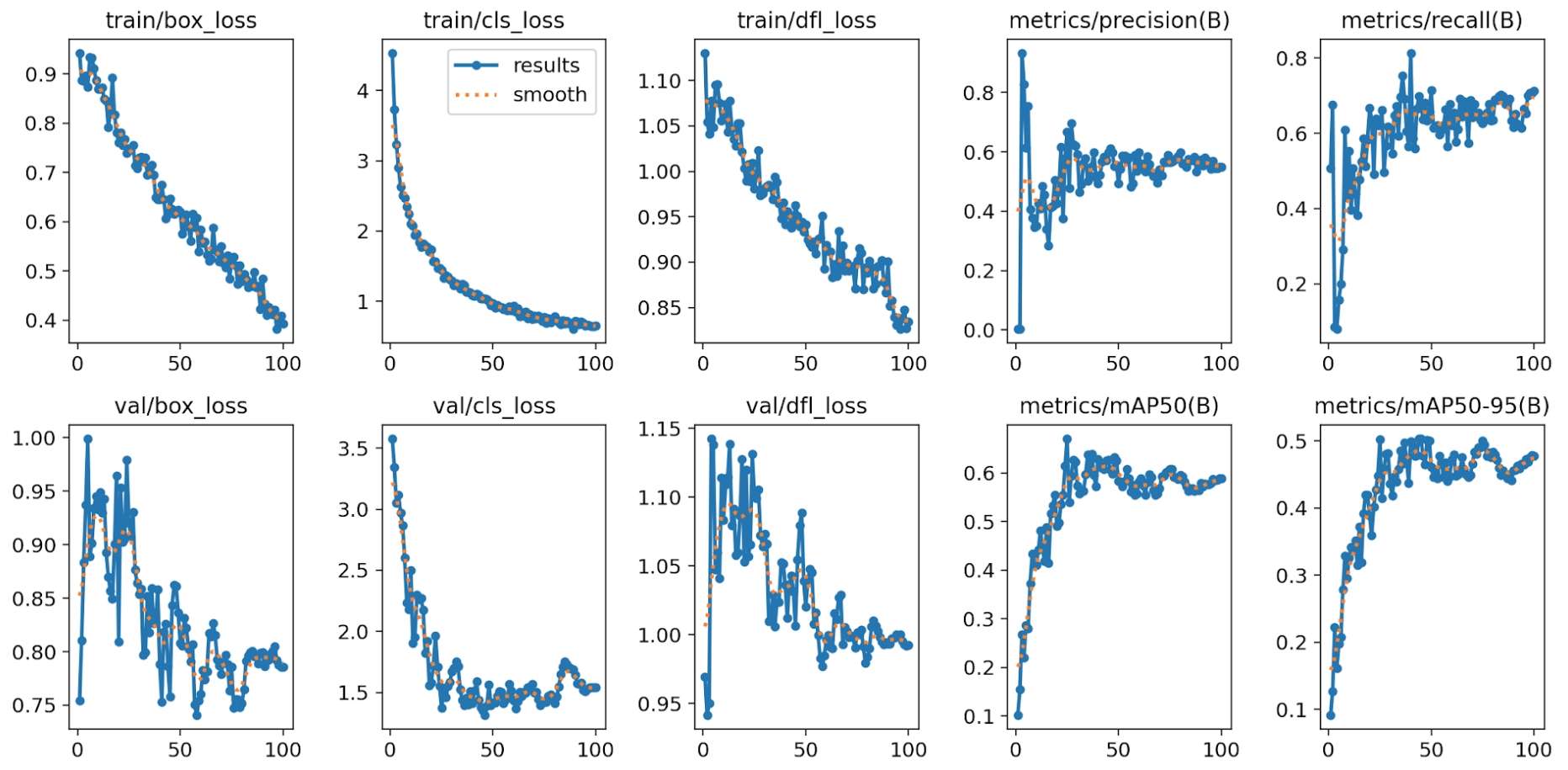
データ拡張あり
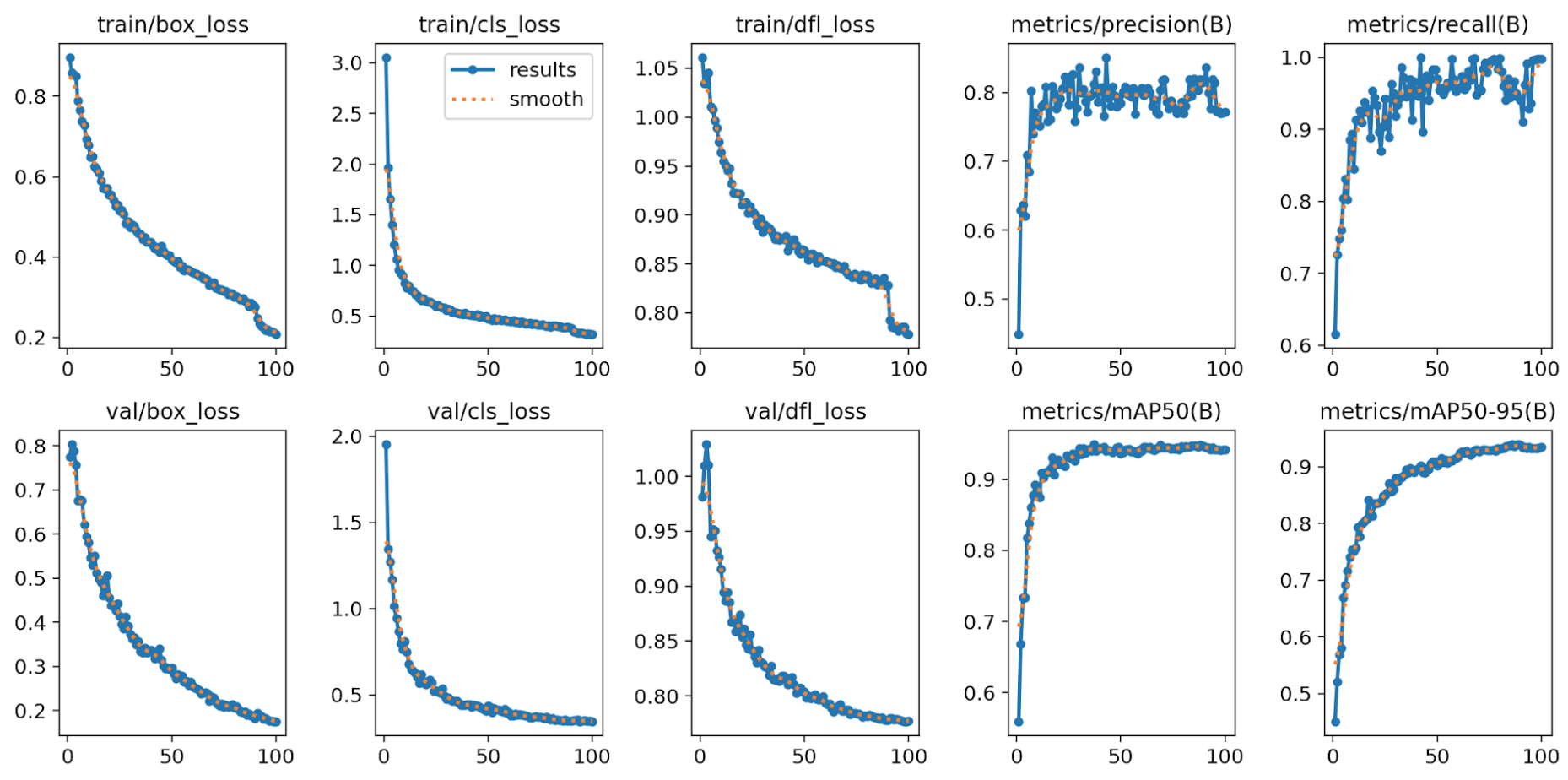
評価指標の比較
| 指標 | 拡張なし | 拡張あり | 改善度 |
|---|---|---|---|
| precision | ~0.4 | ~0.8 | 約2倍向上 |
| recall | ~0.6 | ~0.95 | 約1.6倍向上 |
| mAP50 | ~0.6 | ~0.95 | 約1.6倍向上 |
| mAP50-95 | ~0.45 | ~0.9 | 約2倍向上 |
詳細評価
・precision(適合率)
→ 拡張後は誤検出が大幅に減少し、精度が倍増。
・recall(再現率)
→ 見逃しがほとんどなくなり、ほぼ100%近くまで改善。
・mAP50 / mAP50-95
→ IoU 0.5だけでなく高いIoUしきい値でも安定した検出精度を確保。
・学習曲線
→ 拡張後の方がlossの収束が滑らかで、過学習の兆候が少ない。
総合比較結果
| 観点 | 結論 |
|---|---|
| 精度向上 | 拡張後モデルは全指標で優秀。データ拡張の効果は明確。 |
| 汎化性能 | 拡張後モデルは検証データで高精度を維持、汎化力が高い。 |
| 学習コスト | 拡張後は学習時間が約10倍だが、それに見合う性能向上あり。 |
| 適用推奨 | 実運用・実用化を目指すなら、拡張後モデルが推奨される。 |
おまけ:その他の評価指標
学習を行なった画像データ例
7つの交通標識
val_batch
val_batchでは
・モデルの重みは更新しない(学習しない)
・ただモデルの性能(loss, precision, recallなど)を評価する
データ拡張なし

データ拡張前では見逃しや誤検出があり、信頼度も低いです。
データ拡張あり

見逃しや誤検出も見当たりません。信頼度も非常に高く正確に推論できています。
各指標のイメージまとめ
| 用語 | イメージ説明 |
|---|---|
| 混同行列 | 予測結果と正解を比較した表 |
| confidence | AIの「これ正しいと思う!」度合い |
| precision | 予測の正確さ(間違い少なさ) |
| recall | 見逃しの少なさ |
| F1 | precision と recall をバランスよく評価する値 |
| F1カーブ | 信頼度を動かしたときの F1 のベスト位置を探すグラフ |
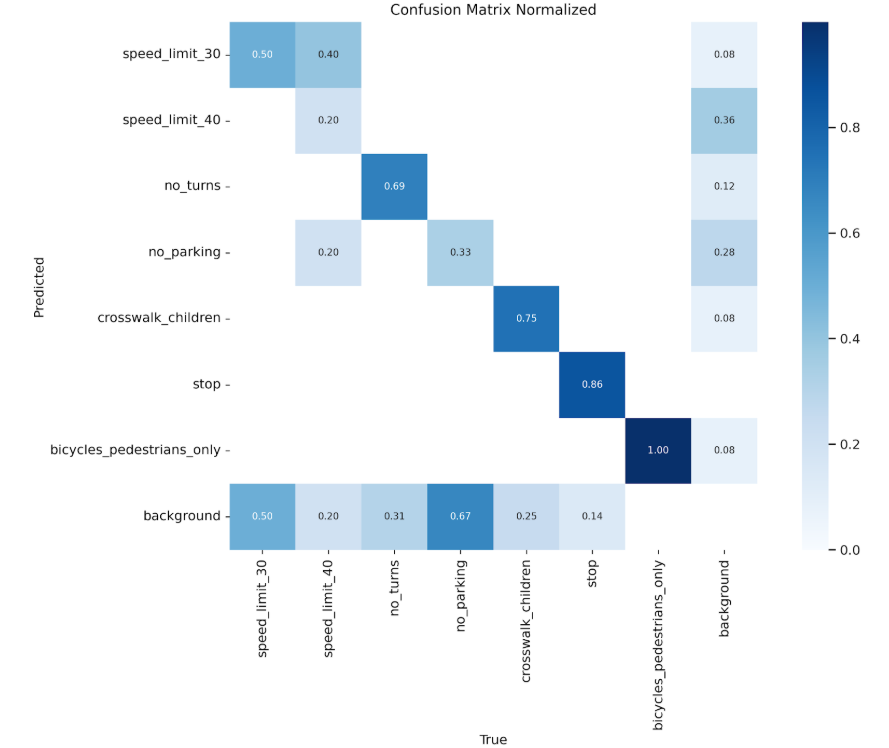
confusion_matrix_normalized(混同行列)
混同行列は、左上から右下への対角線が直線で色が濃い程、対角線に値が集中している程、正しく推論が成功していることになります。
データ拡張なし
データ拡張あり
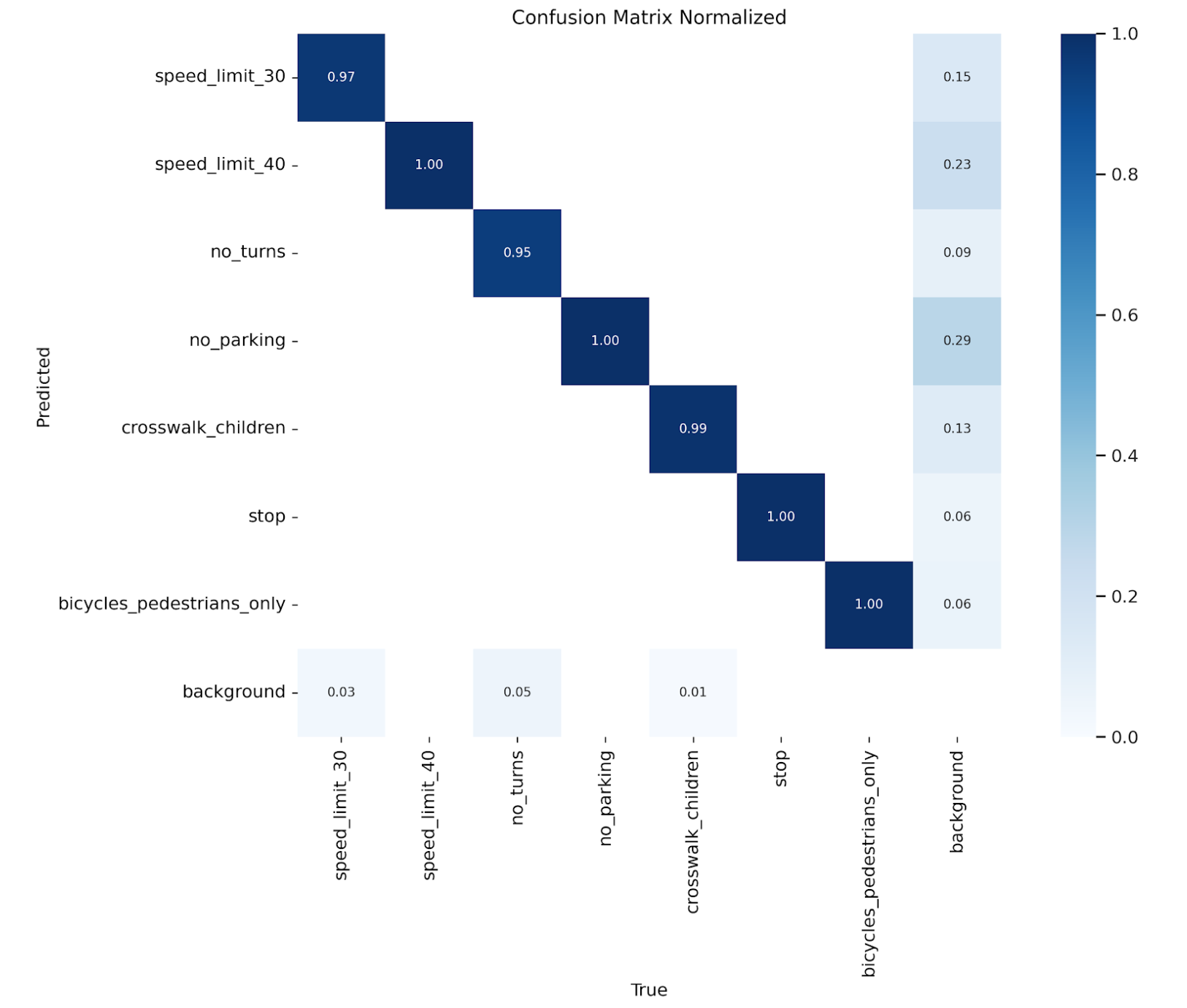
混同行列の評価比較
| クラス | 拡張なし(正解率) | 拡張あり(正解率) | 改善内容 |
|---|---|---|---|
| speed_limit_30 | 50% | 97% | 大幅改善、speed_limit_40との混同解消 |
| speed_limit_40 | 0% | 100% | 完全正解(以前はbackgroundに36%誤分類) |
| no_turns | 69% | 95% | 誤分類(background)大幅減少 |
| no_parking | 33% | 100% | 背景との混同67% → ほぼゼロ |
| crosswalk_children | 75% | 99% | 高精度に向上 |
| stop | 86% | 100% | 完全正解 |
| bicycles_pedestrians_only | 100% | 100% | 完璧を維持 |
| background | 他クラスから誤分類多数 | 誤分類率0.03–0.29 | 各クラスからの誤検出が大幅減少 |
✅ speed_limit 系の混同(30 ↔ 40)がほぼ消滅し、識別力が向上。
✅ no_parking の誤分類がゼロに改善。
✅ 全クラスで精度が向上し、backgroundとの誤分類率が激減。
✅ ほとんどのクラスで diagonal(正解マス)が 0.95–1.0 という完璧レベルに到達。
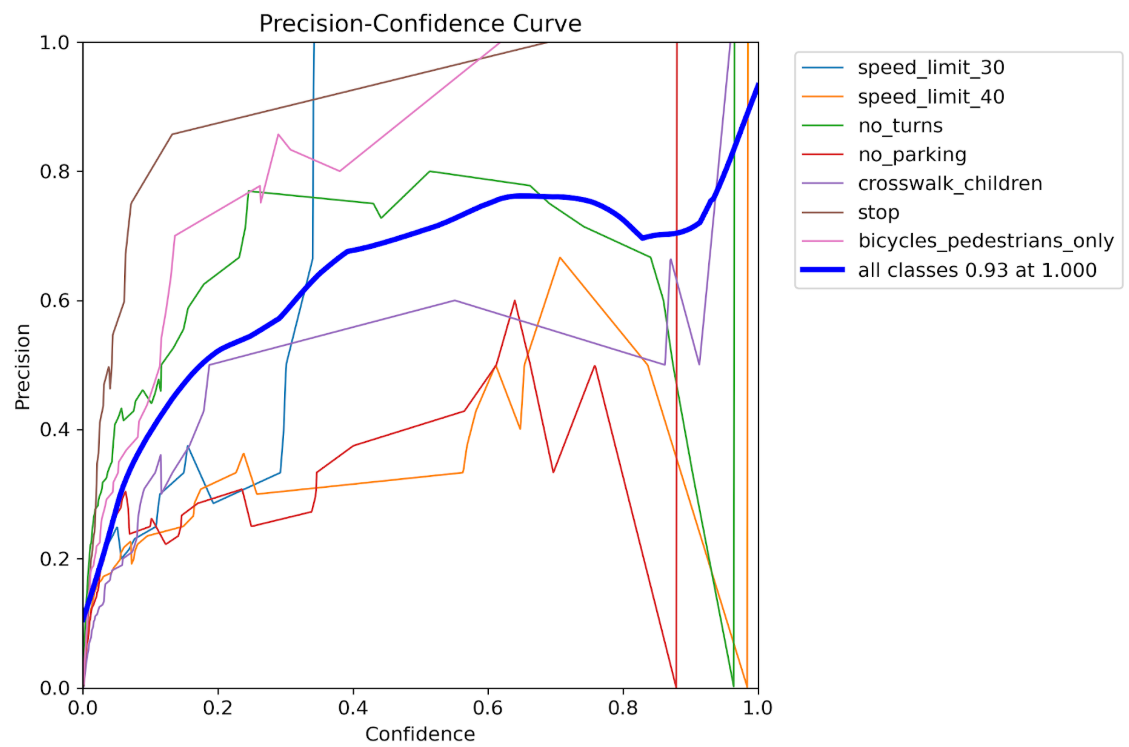
Pカーブ
precision=モデルが出した予測のうち、実際に正解だった割合
信頼度(confidence)を上げると精度(precision)は上がる一方、見逃し(recall低下)も増えます。
データ拡張なし
データ拡張あり
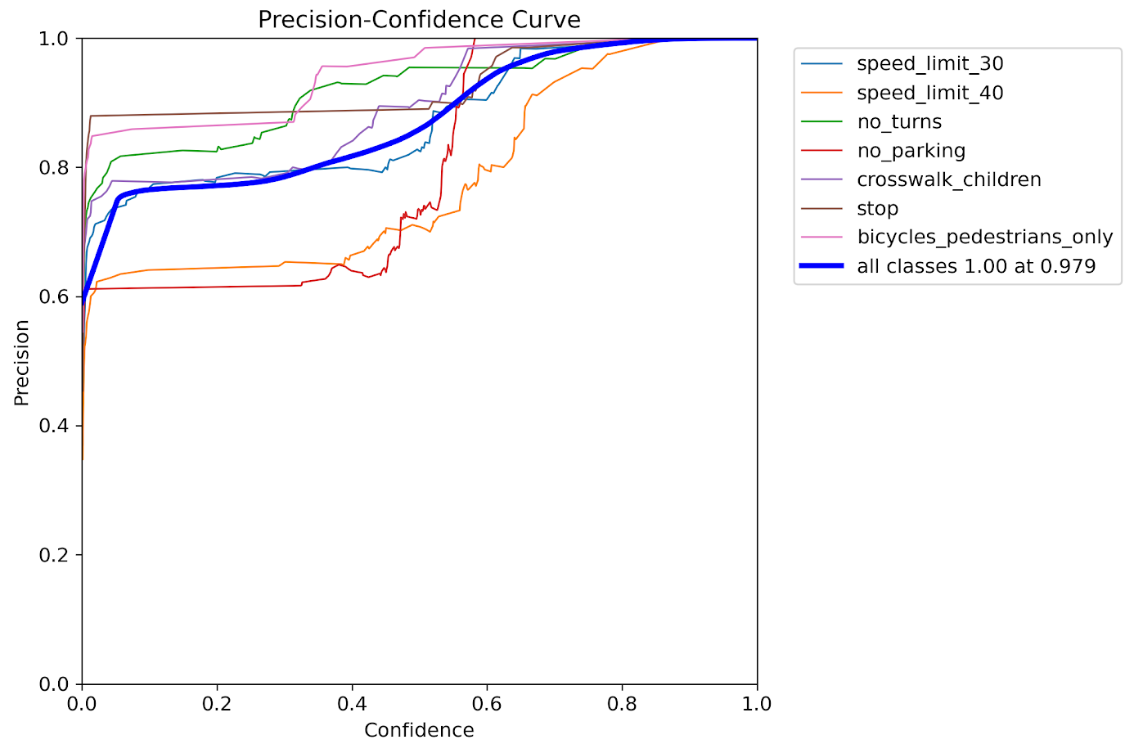
Pカーブの評価比較
| 指標 | 拡張なし | 拡張あり |
|---|---|---|
| 全クラス最大 precision | 0.93 @ 信頼度1.0 | 1.00 @ 信頼度0.98 |
| precision の安定性 | ガタガタでクラス間格差大 | 線が滑らかで高い水準に揃っている |
✅データ拡張後は、モデルが「これなら自信ある」と言った予測は、ほぼ100%正解になっている。
✅ precision の向上は、特に運用フェーズで false positive(誤検出)を減らしたいときに大事。
✅ ただし、注意点:
→ precision を優先すると recall(見逃し)が減るので、F1スコアとのバランスも見る必要がある。
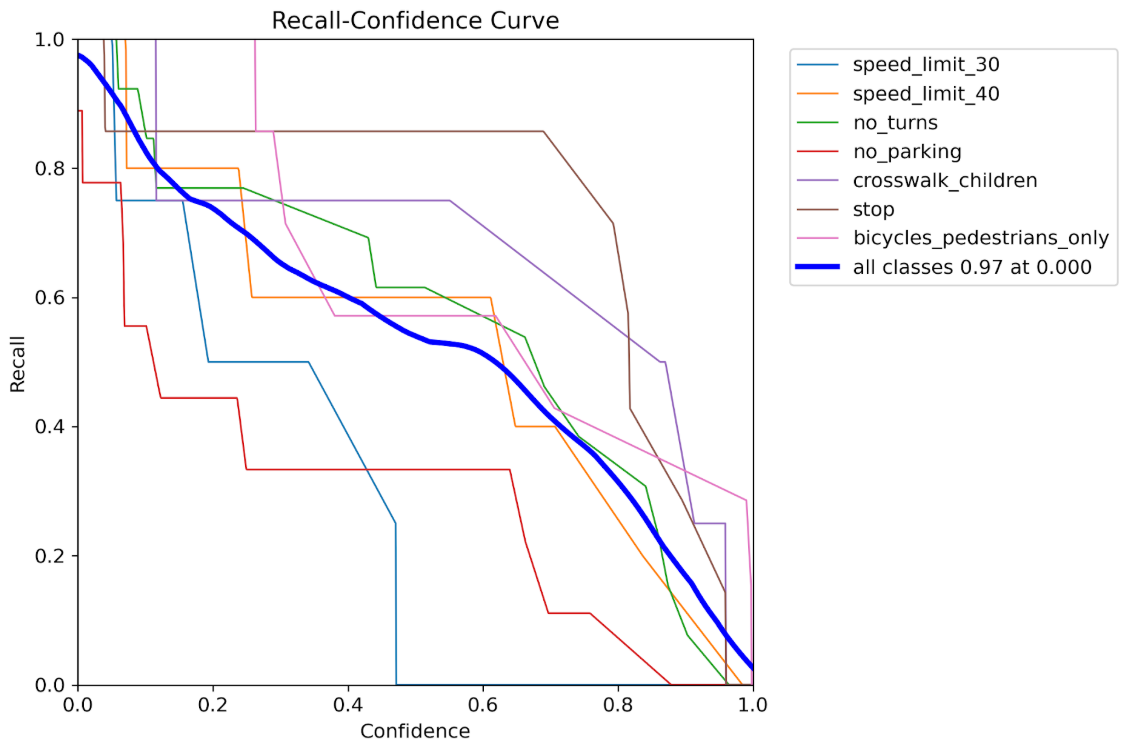
Rカーブ
Recall(再現率)=実際に正解だったもののうち、どれだけ検出できたか(見逃しが少ないか)
「信頼度を上げると、見逃し(recall)がどう変化するか」を見るグラフです。正解のうち何個をちゃんと見つけたか。見逃しが少ないほど高評価となります。
データ拡張なし
データ拡張あり
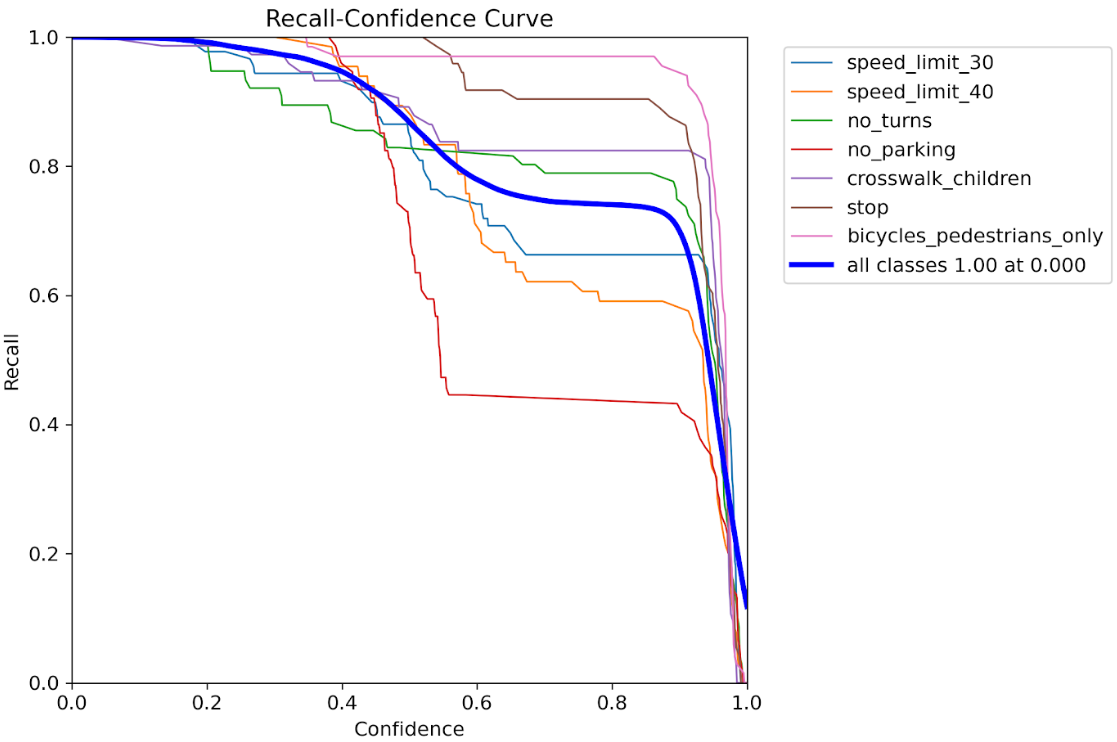
Rカーブの評価比較
| 項目 | データ拡張なし | データ拡張あり |
|---|---|---|
| 全体最大 recall | 約0.97 | 完全1.0 |
| 信頼度0での安定性 | クラス間でガタガタ、低めのクラスあり | 全クラスが高い水準で横並び、高安定 |
| 信頼度を上げたとき | 急激に落ちるクラスが多い | 緩やかに落ちる、stop・bicycles_pedestrians_onlyは特に強い |
✅ データ拡張後:
・全体の recall が最大1.0に到達、見逃しゼロ。
・クラス間のバラツキが小さくなり、安定感が大幅に向上。
・高信頼度でも比較的高い recall を維持するクラスが増加。
✅ 特に優秀なクラス(拡張後):
・bicycles_pedestrians_only、stop → 高confidenceでも高recallを維持。
・speed_limit_40、no_parking → 改善したが、まだ中間層。
PRカーブ
PRカーブ=モデルが「どれだけ正確に予測できたか(precision)」と、「どれだけ漏れなく拾えたか(recall)」のバランスを見るグラフ。
precision(正確さ)と recall(漏れの少なさ)のバランスを、クラスごと・全体で可視化したものです。
データ拡張なし

データ拡張あり

| クラス | 拡張なし mAP@0.5 | 拡張あり mAP@0.5 | 改善量 |
|---|---|---|---|
| speed_limit_30 | 0.651 | 0.948 | +0.297(約1.5倍改善) |
| speed_limit_40 | 0.482 | 0.904 | +0.422(約1.9倍改善) |
| no_turns | 0.713 | 0.974 | +0.261(約1.4倍改善) |
| no_parking | 0.344 | 0.851 | +0.507(約2.5倍改善) |
| crosswalk_children | 0.653 | 0.972 | +0.319(約1.5倍改善) |
| stop | 0.925 | 0.988 | +0.063(微改善、高水準維持) |
| bicycles_pedestrians_only | 0.924 | 0.994 | +0.070(微改善、高水準維持) |
| all classes (全体平均) | 0.670 | 0.947 | +0.277(約1.4倍改善) |
✅ 苦手クラス(speed_limit_40, no_parking)が特に大幅改善
✅ 得意クラス(stop, bicycles_pedestrians_only)はさらに微調整レベルの向上
✅ 全体mAPが 0.67 → 0.947 と大幅アップ(約41%改善)
F1カーブ
AIモデルを開発する際、「しきい値をどう決めるか?」という問題があります。
・高い信頼度のものだけ採用する?(→ precision 高め、でも見逃しが増える=recall 下がる)
・低い信頼度でも採用する?(→ recall 高め、でも間違いが増える=precision 下がる)
そこで出てくるのが F1スコアです。
これは precision と recall をバランスよくまとめた指標です。
F1カーブの簡単な読み方
・上に張り付いているクラス → そのクラスは高精度
・下でガタガタしているクラス → そのクラスはまだ検出が不安定
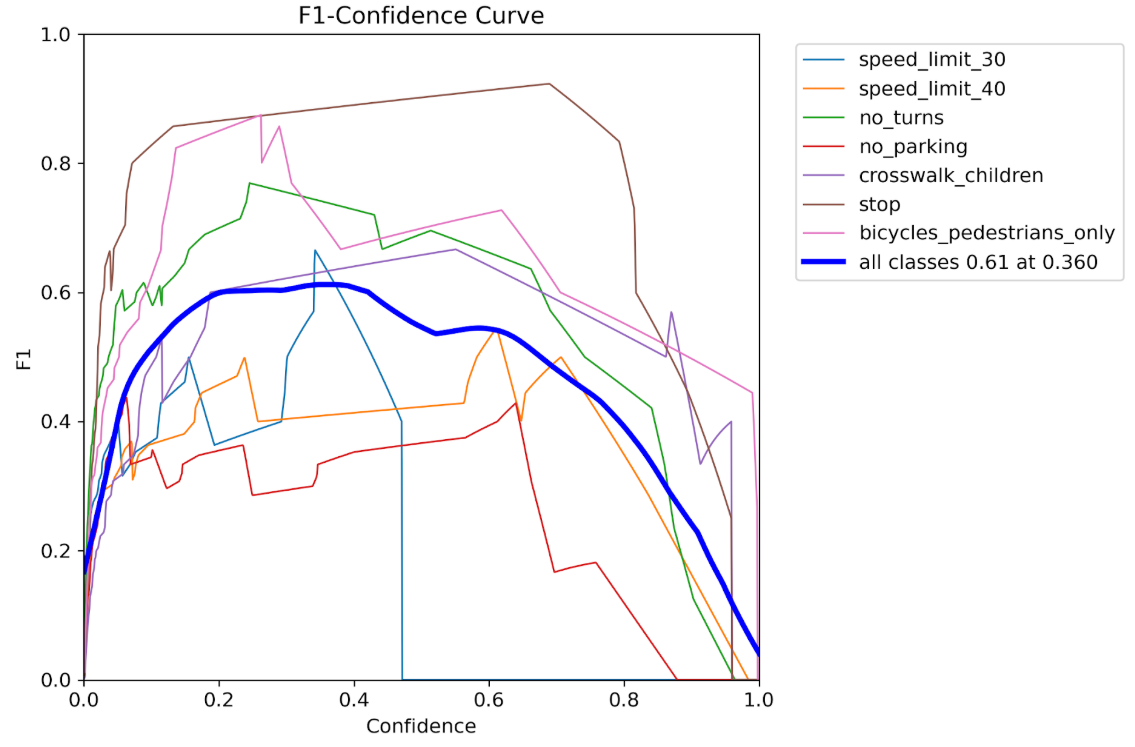
データ拡張なし
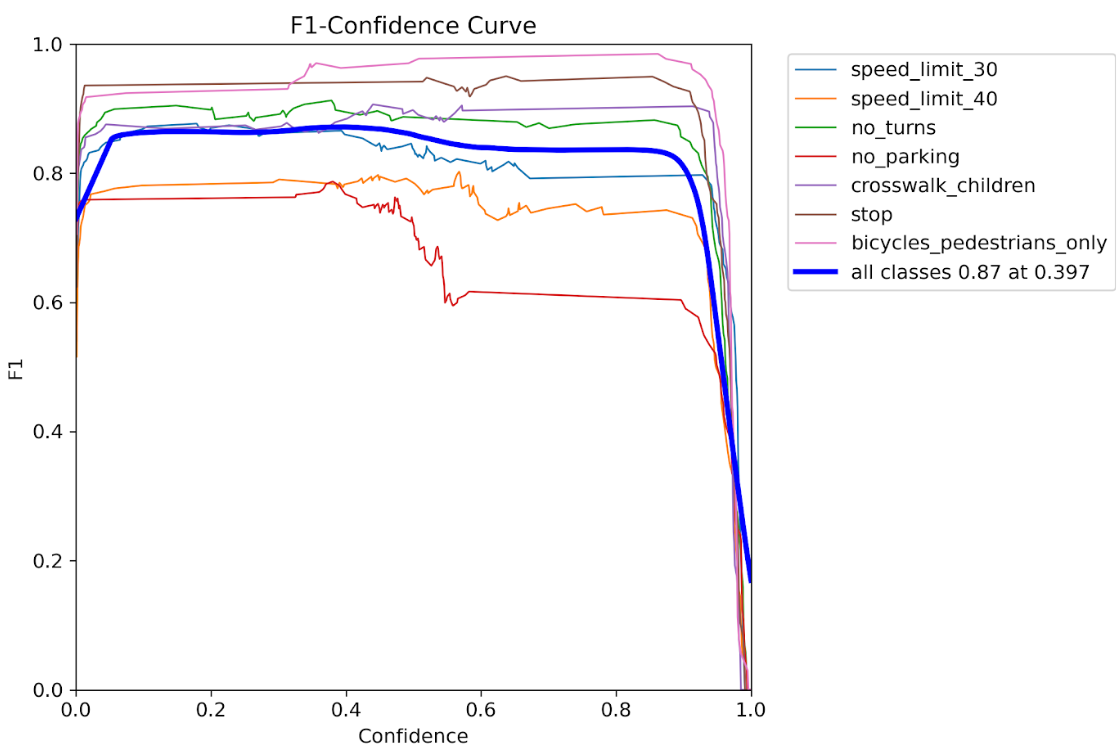
データ拡張あり
F1カーブの評価比較
| 指標 | 拡張なし | 拡張あり | 改善度 |
|---|---|---|---|
| 全クラス最大F1 | 0.61 @ 0.36 confidence | 0.87 @ 0.40 confidence | 約1.4倍向上 |
✅ 全体的に信頼度を 0.36 → 0.40 付近に置くと最良F1になる傾向
✅ 最大F1が 0.61 → 0.87 に大幅向上(+0.26、約43%改善)
✅ 苦手なクラスを特定し、データセットの増強をすることで、更にモデルの精度を向上させることも可能です。
おわりに
データ拡張によって段違いにモデルの精度が向上したことを確認できました。評価指標の見方も解説してみました![]() 検証については次回の記事で解説します。
検証については次回の記事で解説します。
シリーズ他記事
本記事はシリーズで構成されており、最終的に、YOLOカスタムモデルをRaspberry Piでデプロイする方法を解説します。シリーズでご覧いただくと、ゼロから画像認識技術を学ぶことができます。
[YOLOカスタムモデルをRaspberry Piでデプロイ①]LabelImgでアノテーションをする最も簡単な方法[Windows]
https://qiita.com/LatanKee/items/d87a729ab47f6ce605f7
[YOLOカスタムモデルをRaspberry Piでデプロイ②]データセットをデータ拡張(Albumentation)する方法[超簡単]
https://qiita.com/LatanKee/items/58c3d5db1a601c513146

(目指す最終イメージ)
次回
・モデルの検証
・Yoloのバージョン別比較
YOLOカスタムモデルをRaspberry Piでデプロイするフェーズに近付いてきました。
お楽しみに![]()