物体検出とは
物体検出(Object Detection)とは、画像やビデオ内の複数の物体を特定し、それぞれの物体の位置をバウンディングボックス(矩形領域)で示す技術です。物体検出は、画像分類の進化形であり、単に画像内に物体が存在するかどうかを判別するだけでなく、その物体がどこに位置しているかも特定します。
応用分野
物体検出は多くの分野で応用されています。以下はその例です。
・自動運転: 車両や歩行者、標識などをリアルタイムで検出し、安全な運転をサポートします。
・監視カメラ: 異常行動の検出や特定人物の追跡を行います。
・医療画像解析: レントゲンやMRI画像から腫瘍や病変を検出します。
・産業用ロボティクス: 工場の生産ラインで不良品を検出したり、物体のピッキングを行います。
物体検出の歴史
物体検出は、初期のテンプレートマッチングやエッジベースの手法から始まり、特徴ベースの手法、そして深層学習によるアプローチへと進化してきた。特に、深層学習の登場以降、物体検出の精度と速度は飛躍的に向上している。最新の手法は、複数のスケールでの物体検出、エンドツーエンドの学習、リアルタイム処理を実現し、広範な応用が可能となっている。物体検出技術の発展には、いくつかの重要な段階があり、以下に、物体検出の歴史を概観する。
初期の物体検出(1990年代前半)
- テンプレートマッチング
・概要: 画像内の物体を既知のテンプレートと比較することで検出する手法。
・利点: 単純で実装が容易。
・欠点: テンプレートが回転、スケーリング、ノイズに対して脆弱。 - エッジベースの手法
・概要: エッジ検出器(Cannyエッジ検出器など)を使用して画像内の物体を検出。
・利点: 形状情報を利用するため、テンプレートマッチングよりも柔軟。
・欠点: 複雑な背景やノイズに対して脆弱。
特徴ベースの物体検出(1990年代後半から2000年代前半)
- Haar-like特徴とカスケード分類器(2001年)
Viola-Jones検出器:
・概要: Haar-like特徴とアダブースト(AdaBoost)を使用した高速かつリアルタイムな顔検出アルゴリズム。
・利点: リアルタイム処理が可能で、顔検出において非常に成功。
・欠点: 特定の物体(特に顔)に特化しており、他の物体検出には限界がある。 - HOG(Histogram of Oriented Gradients)特徴とSVM(Support Vector Machine)(2005年)
Dalal-Triggs検出器:
・概要: HOG特徴量とSVMを使用して歩行者検出を行う手法。
・利点: 歩行者検出の精度が高く、他の物体検出にも応用可能。
・欠点: 計算コストが高く、リアルタイム処理が難しい。
深層学習の登場と革命(2010年代)
- R-CNN(Regions with Convolutional Neural Networks)(2014年)
・概要: 画像から選択した候補領域(region proposals)をCNNに通して物体を検出。
・利点: 高精度で多様な物体を検出可能。
・欠点: 計算コストが非常に高く、推論速度が遅い。 - Fast R-CNN(2015年)
・概要: R-CNNの改良版で、ROIプーリングを導入し、同一のCNNを共有して計算を高速化。
・利点: 高速かつ高精度。
・欠点: 依然としてregion proposalの生成に時間がかかる。 - Faster R-CNN(2015年)
・概要: Region Proposal Network(RPN)を導入し、region proposalの生成をCNN内部で行う。
・利点: 大幅な高速化を実現し、エンドツーエンドで学習可能。
・欠点: リアルタイム処理にはまだ不十分。 - YOLO(You Only Look Once)(2015年)
・概要: 画像をグリッドに分割し、各グリッドセルで物体のバウンディングボックスとクラスを予測するエンドツーエンドのアプローチ。
・利点: 非常に高速でリアルタイム処理が可能。
・欠点: 小さな物体の検出精度が低い。 - SSD(Single Shot MultiBox Detector)(2016年)
・概要: 複数の異なる解像度の特徴マップを使用して物体を検出。
・利点: 高速かつ高精度で、YOLOと同様にエンドツーエンドで学習可能。
・欠点: 非常に小さな物体の検出には限界がある。
現代の物体検出(2015年以降)
- YOLOv8、YOLOv9、YOLOv10、YOLOv11、YOLOv12(2015年以降)
・概要: YOLOアーキテクチャの改良版。バックボーンネットワークの改善、複数スケールの特徴融合、その他の最適化技術を導入。
・利点: 高精度と高速性を両立。
・欠点: 非常に複雑なシーンや多数の物体がある場合には限界がある。 - EfficientDet(2019年)
・概要: EfficientNetをベースとしたスケーラブルな物体検出アーキテクチャ。
・利点: モデルサイズと計算量を効率的に調整可能。
・欠点: YOLOシリーズと比較して導入が複雑。 - Transformerベースのモデル(DETRなど)(2020年以降)
・概要: Attention機構を利用して物体検出を行う新しいアプローチ。
・利点: 非常に高い柔軟性と精度。
・欠点: 訓練に大量のデータと計算資源を必要とする。
物体検出の主なステップ
- 物体の検出: 画像全体をスキャンし、物体が存在する可能性のある領域(バウンディングボックス)を特定する。
- クラス分類: 各バウンディングボックス内の物体を特定のクラス(カテゴリ)に分類する。
- 位置の特定: 各物体のバウンディングボックスの座標(左上隅と右下隅の座標)を計算する。
バウンディングボックスとは
バウンディングボックス(Bounding Box)とは、画像やビデオ内の物体を囲む矩形のことです。物体検出において、バウンディングボックスは物体の位置とサイズを特定するために使用されます。
バウンディングボックスの表現方法
バウンディングボックスは通常、以下の情報で表現されます。
・左上隅の座標(x1, y1): 矩形の左上の点の位置。
・右下隅の座標(x2, y2): 矩形の右下の点の位置。
・幅と高さ(width, height): 矩形の幅と高さ。
例えば、画像のサイズが1000x1000ピクセルで、バウンディングボックスの左上隅が(100, 200)、右下隅が(400, 600)の場合、このバウンディングボックスは横幅300ピクセル、高さ400ピクセルの矩形になります。
YOLOとは
YOLO(You Only Look Once)は、物体検出(Object Detection)のための深層学習アルゴリズムです。物体検出は、画像やビデオ内の物体の位置とクラスを特定するタスクです。YOLOは、1つの畳み込みニューラルネットワーク(CNN)を使って、画像全体を一度に処理し、物体の位置とクラスを同時に推定します。
YOLOのアルゴリズムの特徴
YOLO (You Only Look Once) アルゴリズムは、リアルタイムでの物体検出を可能にするために設計されたディープラーニングベースの手法です。YOLOは、従来の物体検出手法に比べて高速かつ正確な検出を実現します。ここでは、YOLOの基本的な仕組みとCNN(畳み込みニューラルネットワーク)を交えて説明します。
YOLOの基本的な仕組み
1.単一ステージ検出:
YOLOは画像を入力として受け取り、単一のニューラルネットワークパスで物体の位置とクラスを予測します。これにより、複数の段階を経る従来の検出手法(例えばR-CNNシリーズ)に比べて高速です。
2.グリッド分割:
入力画像をSxSのグリッドに分割します。各グリッドセルは、そのセル内に中心がある物体を検出する責任があります。
3.バウンディングボックスとクラスの予測:
各グリッドセルは固定数(B個)のバウンディングボックスを予測します。各バウンディングボックスは次の情報を含みます:
・バウンディングボックスの中心座標 (x, y)
・バウンディングボックスの幅と高さ (w, h)
・バウンディングボックス内の物体のクラスの確率
4.非最大抑制(NMS):
重複するバウンディングボックスを除去し、最も高い信頼度を持つボックスのみを残すためにNMSを使用します。
CNN(畳み込みニューラルネットワーク)との関係
YOLOのバックボーンは、CNNで構成されています。CNNは、特徴抽出と物体検出の両方において重要な役割を果たします。
1.特徴抽出:
入力画像は、一連の畳み込み層、バッチ正規化層、およびプーリング層を通過します。これにより、画像の空間的な特徴が抽出されます。これらの層は、エッジ、テクスチャ、形状などの低レベルおよび高レベルの特徴を学習します。
2.フルコネクション層:
畳み込み層の出力は、フルコネクション層に渡されます。これにより、抽出された特徴が結合され、物体の位置とクラスの予測が行われます。
予測層:
最終的な予測は、ネットワークの最終層で行われます。この層は、各グリッドセルごとにバウンディングボックスの座標、サイズ、およびクラスの確率を出力します。
YOLOシリーズの変遷
YOLO (You Only Look Once) シリーズは、物体検出のためのリアルタイムシステムとして、Joseph Redmonらによって開発された。実装には著者のJoseph Redmonが作成したC言語のライブラリDarknetが用いられ、以降のYOLOシリーズのほとんどで同様のライブラリが採用されている。各バージョンは前のバージョンの欠点を改善し、性能を向上させている。以下に、YOLOシリーズの主要なバージョンとその特徴を説明する。
■YOLOv1 (2015年)
論文: "You Only Look Once: Unified, Real-Time Object Detection"
著者:Joseph Redmonら
画像をグリッドに分割し、各グリッドセルがバウンディングボックスとクラス確率を予測。非常に高速で、リアルタイムの物体検出を可能に。他の物体検出アルゴリズムに比べて、精度が劣る場合がある。
■YOLOv2 (2016年)
論文: "YOLO9000: Better, Faster, Stronger"
著者:Joseph Redmonら
アーキテクチャの改良を行ない、Darknet-19バックボーンを導入。複数の解像度での訓練により、スケーラビリティ向上。アンカーボックスの使用により、検出精度が向上。COCOデータセット上でのmAP (mean Average Precision) が向上。最大9000種類の物体を検出可能に。
■YOLOv3 (2018年)
著者:Joseph Redmon、Ali Farhadi
論文: "YOLOv3: An Incremental Improvement"
Darknet-53バックボーンを導入。マルチスケール特徴抽出により異なるスケールで物体を検出。ロジスティック回帰を使用したクラス予測。COCOデータセット上での精度向上と、依然として高速な性能。
■YOLOv4 (2020年)
論文: "YOLOv4: Optimal Speed and Accuracy of Object Detection"
著者:Alexey Bochkovskiy
CSPDarknet53バックボーンを導入。データ拡張手法(Mosaic、CutMixなど)と正則化手法(DropBlockなど)の導入。より高速な学習と推論を可能にするための改良。精度とスピードの両立。
■YOLOv5 (2021年)
著者:Glenn Jocher(Ultralytics社)
Ultralyticsによる開発。PyTorch実装で、使いやすさが向上。バージョン間の明確な論文発表はなく、実装とコミュニティのフィードバックによる改善。トレーニングとデプロイメントが容易化。
■YOLOv6 (2022年)
著者:Meituan Technical Team
YOLOv4とYOLOv5の改良版として、Meituan社が開発。より高い精度とスピードを目指した改善。
■YOLOv7 (2022年)
著者:Alexey Bochkovskiy
より小型で効率的なモデルアーキテクチャの導入。精度と推論速度の向上。幅広いデバイスでの実装が容易に。
■YOLOv8 (2023年1月)
著者:Ultralytics社
さらなる精度と速度の最適化。より簡単なトレーニングとデプロイメントプロセスで現在広く利用されているモデル。
■YOLOv9(2024年2月)
著者:台湾、中央研究院情報科学研究所・国立台北理工大学の研究チーム所属のChien-Yao Wangら
プログラマブル勾配情報 (PGI) を実装する Ultralytics YOLOv5 コードベースでトレーニングされた実験モデル。
■YOLOv10(2024年5月)
著者:北京市、清華大学の研究者チーム所属のAo Wangら
NMS を使用しないトレーニングと効率性を重視した精度重視のアーキテクチャを特徴とし、最先端のパフォーマンスとレイテンシーを実現。
■YOLOv11(2024年9月30日)
著者:Ultralytics社
改良されたバックボーンとネックアーキテクチャを採用したことで、より少ないパラメータでより高い精度を実現。YOLO11mはYOLOv8mよりも22%少ないパラメータで、COCOデータセットにおいて高い平均精度(mAP)を達成し、精度を損なうことなく計算効率を向上。環境適応性が向上し、エッジデバイス、クラウドプラットフォーム、NVIDIA GPUをサポートするシステムなど、さまざまな環境にシームレスに展開可能。
サポート対象タスク: 物体検出、インスタンス分割、画像分類、姿勢推定、指向性物体検出(OBB)
■YOLOv12(2025年2月18日)
著者:Yunjie Tian(University at Buffalo)、Qixiang Ye
(University of Chinese Academy of Sciences)、David Doermann
(University at Buffalo)
従来のCNNベースから逸脱しつつ、同等の速度を実現する注目度中心のYOLOフレームワーク(attention-centric YOLO framework)である。別名、自己注意アプローチ(Self-Attention)とも言う。
論文名:「YOLOv12: 注目中心型リアルタイム物体検出器」
論文URL:https://arxiv.org/abs/2502.12524
※自己注意(Self-Attention)機構に関する参考記事
https://xtech.nikkei.com/atcl/nxt/mag/rob/18/00007/00006/
■Ultralytics YOLO26(2026年1月14日)
YOLO26はネイティブなエンドツーエンドモデルであり、非最大抑制 (NMS) を必要とせずに直接予測を生成します。この後処理ステップを排除することで、推論はより高速、軽量になり、実世界のシステムへのデプロイが容易になります。この画期的なアプローチは、清華大学のAo Wang氏によってYOLOv10で初めて開拓され、YOLO26でさらに進化しました。
https://docs.ultralytics.com/ja/models/yolo26/#overview
YOLOバージョンの性能比較
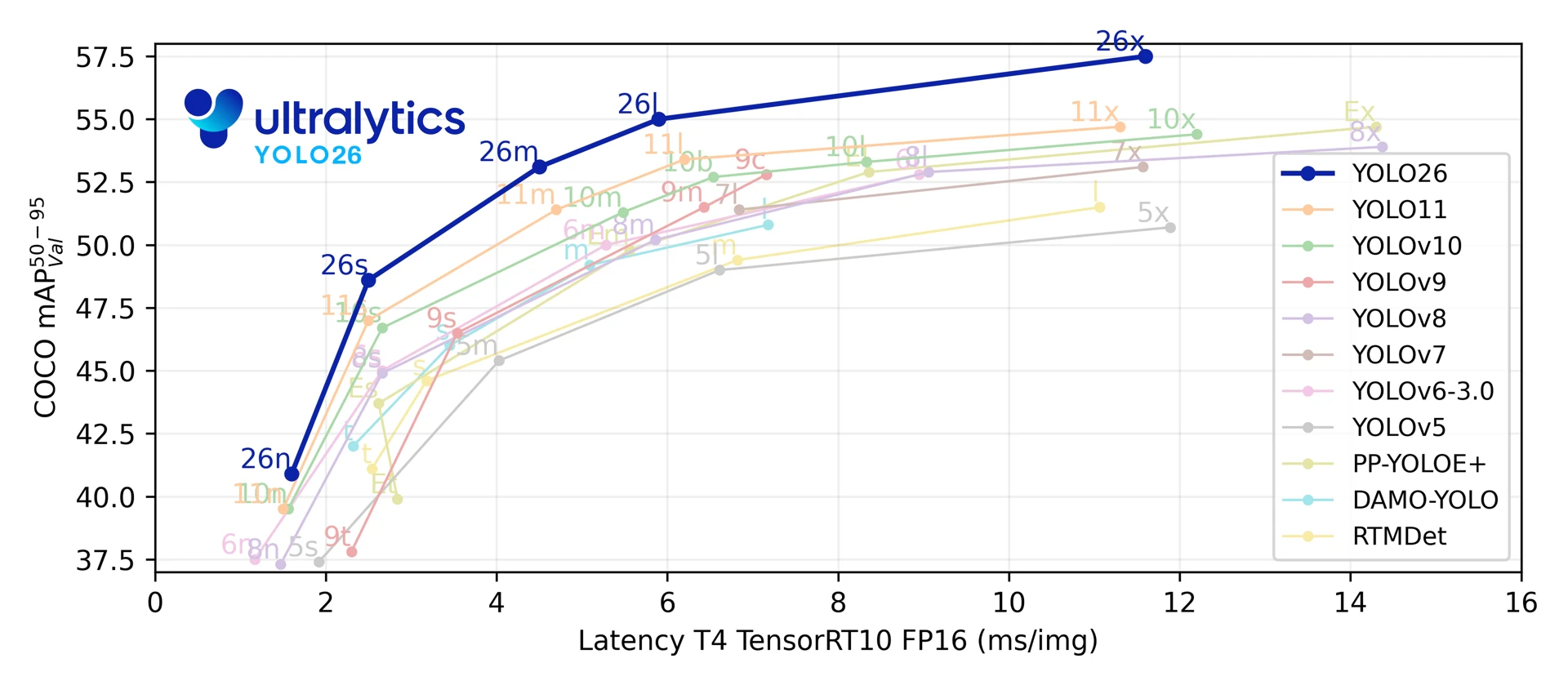
出典:https://docs.ultralytics.com/ja/models/
(2026年3月4日 Ultralytics社ドキュメント閲覧)
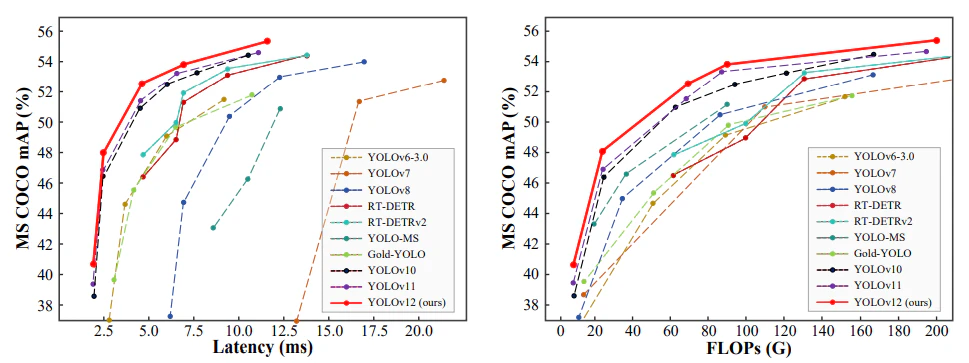
出典:https://arxiv.org/abs/2502.12524
(2025年5月14日 「YOLOv12: 注目中心型リアルタイム物体検出器」論文閲覧)
評価指標
物体検出で用いられる主な評価の指標について解説する。
基本の評価指標
・TP(True Positive):実際にポジティブで、正しくポジティブと予測できた数
・TN(True Negative):実際にネガティブで、正しくネガティブと予測できた数
・FP(False Positive):実際にはネガティブで、誤ってポジティブと予測してしまった数
・FN(False Negative):実際にはポジティブで、誤ってネガティブと予測してしまった数
・Accuracy(正解率):モデルが正し宇予測した割合。

・Precision(適合率):ポジティブと予測された中で、どれだけが本当のポジティブだったか。陽性反応的中度のこと。
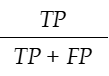
・Recall(再現率):実際にポジティブだった中で、どれだけをポジティブと予測できたか。真陽性率のこと。

・F値:適合率と再現率の調和平均。ポジティブとネガティブの割合が極端に異なっていても評価しやすいのが特徴。

Confusion Matrix(混同行列)
実際のクラスとモデルが予測したクラスの組み合わせを集計したもの。次の混合行列の様に、青塗りされた箇所にデータが集まっている分、正しく予測ができているということになる。

IoU(Intersection over Union)
IoUは物体検出アルゴリズムの性能を評価するための主要な指標の一つ。IoUは、予測されたバウンディングボックスと実際のバウンディングボックス(グラウンドトゥルース)の重なり具合を定量化するもの。領域の積を領域の和で割った指標。

IoUの解釈
・IoU = 0:予測ボックスとグラウンドトゥルースボックスが全く重ならない。
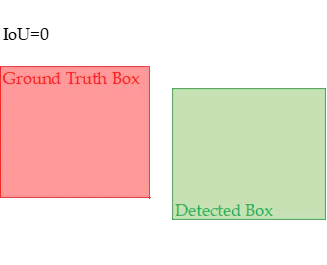
・0 < IoU < 1:予測ボックスとグラウンドトゥルースボックスが部分的に重なる。IoUが大きいほど、重なりが大きい。
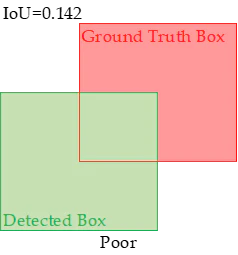
・IoU = 1:予測ボックスとグラウンドトゥルースボックスが完全に一致する。

IoUを用いた評価
物体検出アルゴリズムでは、一般的に特定のIoU閾値を設定して評価を行う。例えば、IoUが0.5以上であれば正解とみなすなどの基準を設ける。
・IoUを用いた評価指標の例
- Mean Average Precision (mAP): mAPは、複数のIoU閾値(例えば0.5, 0.75, 0.95など)における平均精度を計算したもので、物体検出モデルの総合的な性能を評価する指標。
- Precision and Recall: 特定のIoU閾値で正しく検出された物体の割合(適合率)と、実際に存在する物体をどれだけ検出できたか(再現率)を計算。
APとmAPの評価指標について
Mean Average Precision (mAP) は、物体検出アルゴリズムの性能を評価するための主要な指標の一つである。mAPは、精度と再現率のバランスを評価するために用いられ、特定のIoU(Intersection over Union)閾値での評価を基に計算される。以下では、mAPの計算方法とその解釈について詳しく説明する。
Precision-Recall Curve(適合率-再現率曲線)
適合率と再現率の関係を視覚的に示すために、Precision-Recall曲線が使用される。この曲線は、再現率を横軸に、適合率を縦軸にしてプロットされる。再現率が増加すると、適合率が減少する傾向となる。
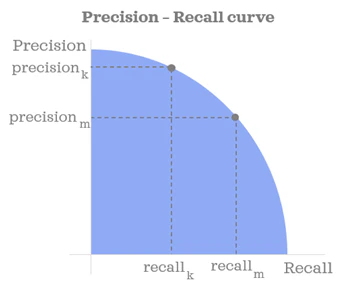
出典:https://levelup.gitconnected.com/precision-recall-curve-explained-fabfe58fb52e
(2025年5月15日閲覧 Thanks)
Average Precision (AP) の計算
APは、特定のクラスに対するPrecision-Recall曲線の下の領域(面積)を計算したものである。APは、異なる再現率値での適合率の平均を取ることで計算される。
1.再現率の閾値ごとの適合率を計算:再現率の各閾値に対して適合率を計算。
2.Precision-Recall曲線のプロット: 適合率と再現率の関係をプロットし、曲線を作成。
3.曲線の下の領域を計算: 曲線の下の領域を計算することで、APを求める。
※𝐴𝑃50や𝐴𝑃75などはmAPを計算する際のIoUの閾値を表している。
Mean Average Precision (mAP)
mAPは、全てのクラスに対するAPの平均である。つまり、各クラスのAPを計算し、それらの平均を取ることでmAPが得られる。(Nはクラスの数。)
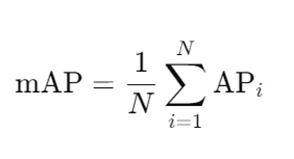
mAPの計算手順
1.各クラスのバウンディングボックスの評価:
・予測されたバウンディングボックスとグラウンドトゥルースバウンディングボックスのIoUを計算。
・IoUが指定した閾値以上であればTrue Positive(正例)、それ以外はFalse Positive(偽例)またはFalse Negative(漏れ)とする。
2.各クラスのAPを計算:
・各クラスのPrecision-Recall曲線をプロットし、その下の領域を計算。
3.mAPを計算:
・各クラスのAPの平均を取り、mAPを求める。