ジョブカン事業部アドベントカレンダー9日目の記事です!
ジョブカン事業部で開発を担当している @Larvesta636 と申します。
むし・ほのおタイプです🐛🔥
今回の記事では、Cursor と GitHub Copilot を利用してコードレビューを効率化する方法について紹介します。
TL;DR
- Cursorのカスタムスラッシュコマンドを利用し、独自のチェックリスト項目を満たしているか確認してもらう
- ブランチの差分からクイズを生成し、それを解くことで変更内容の概要を把握する
- カスタム指示を加えたGitHub Copilot Agentをレビュアーにアサインし、自動でコードレビューしてもらう
なお、本記事では最適なモデルの選定やプロンプトの構成、トークン使用量などの詳細には触れませんので、あらかじめご了承ください。
はじめに
コードレビューはチーム開発において欠かせないプロセスですが、どうしても時間と労力を必要とする作業です。
タイポのような単純な指摘から、仕様変更に関わる本質的な指摘まで、見るべき観点は多岐に渡ります。
かく言う私もコードレビューには時間がかかってしまい、「何とか効率化できないかな?」と常々考えていました。
(「このコメントの言い方キツくないかな...?」など、伝え方の面で悩むこともあります)
そこで、CursorやGitHub Copilotを「一次レビュアー」として起用し、あらかじめ軽微な指摘をコメントしてもらう方法を模索しました。AIによる一次レビューを挟むことで、レビュー全体の時間を短縮し、人間はより深い指摘に集中することを目指しています。
今回はチーム全体への導入を提案する前のステップとして、「まずは個人で行える範囲」で試した内容を紹介します。
(個人開発でもそのまま活用できるテクニックです!)
開発環境
前述の通り、本検証ではツールとして Cursor と GitHub Copilot を使用しています。
Cursor Rules
Cursor Agent用のルールとして、kinopeeさんが公開されている cursorrules の「v5」を使用しています。
MCP Server (Cursor)
context7 と serena を設定して利用しています。
Cursor スラッシュコマンド
Cursorのカスタムスラッシュコマンド機能を利用します。
チャット欄で「/」と入力するだけで、独自のコードレビューチェックリストに基づいた確認をしてもらう設定です。
公式ドキュメントでも「コードレビュー・チェックリスト」がコマンド例として紹介されており、これを参考にしました。
紹介されているコマンド
# コードレビューチェックリスト
## 概要
品質、セキュリティ、保守性を確保するための包括的なコードレビュー実施チェックリスト。
## レビューカテゴリ
### 機能性
- [ ] コードが想定通りに動作する
- [ ] エッジケースが処理されている
- [ ] エラーハンドリングが適切
- [ ] 明らかなバグや論理エラーがない
### コード品質
- [ ] コードが読みやすく構造化されている
- [ ] 関数が小さく焦点が絞られている
- [ ] 変数名が説明的
- [ ] コードの重複がない
- [ ] プロジェクト規約に準拠している
### セキュリティ
- [ ] 明らかなセキュリティ脆弱性がない
- [ ] 入力検証が実装されている
- [ ] 機密データが適切に処理されている
- [ ] ハードコードされた秘密情報がない
コマンドファイルの作成
カスタムコマンドで実行するための定義ファイルとして、コードレビュー用のチェックリストを作成しました。
項目の選定にあたっては、普段から相互にコードレビューを行っているチームメンバーと相談し、実用的な内容になるよう調整しました。
※私が所属する開発チームでは、1つのプルリクエストに対してレビュアーを2名アサインする運用ルールになっています。
今回作成したチェックリストは以下の通りです、(Qiita公開用に一部調整しています)
プルリクエストの差分がこのリストの観点に沿っているか、Cursorにチェックしてもらいます。
# コードレビュー チェックリスト(Qiita 公開用)
### 概要
コードレビューを徹底的に行い、品質・保守性・セキュリティを確保するための包括的なチェックリストです。
- バックエンドおよびフロントエンドのコードを対象とする。
- コードレビューは、差分表示(例: `@Add Context` の `@Branch(diff with main)` など)から取得した変更差分をもとに行う。
- チェックリストに沿ったコードレビューを行うため、必要なコンテキスト(例: `use context7` などプロジェクト固有の機能)は必ず利用する。
- 修正箇所については、循環的複雑度を計測するコマンドを実行し、複雑度が過度に高くなっていないかを確認する。(例: `...`)
## パフォーマンス
- [ ] 不要なデータ変換や引数渡しを行っていないか
- [ ] 配列・リストなどに展開してから利用するなど、無駄な繰り返し評価を避けているか
- [ ] 特定メソッドで代用可能な処理を、独立した関数として無駄に実装していないか
- [ ] N+1 問題を発生させず、データ取得を適切に使用しているか
- [ ] 大容量オブジェクトによるメモリ使用量への配慮がなされているか
- [ ] システム固有の制約を考慮しているか
## 可読性・保守性
- [ ] 実際の型とタイプアノテーションが一致しているか
- [ ] 使用されていない変数や関数が残っていないか
- [ ] 組み込み関数名のシャドウイングや、一般的でない省略記法を避けているか
- [ ] 不要なネストや、複雑な処理をそのまま直接記述していないか
- [ ] 変数・関数・クラスの命名が適切で、意図が明確になっているか
- [ ] 可読性を保ちつつ、適切に簡略化・効率化されているか
- [ ] エッジケースや境界値の処理が、コード上で適切に考慮されているか
## セキュリティ
- [ ] データのバリデーションを適切に行っているか
## 技術的妥当性
- [ ] 実装の背景理由や設計判断が妥当であり、コードやコメントなどから明確に読み取れるか
- [ ] 技術的判断が、推測ではなく公式ドキュメントや確実な根拠に基づいているか
- [ ] 既存システムや他機能への副作用・影響が適切に分析されているか
コマンド実行
Chat欄で「/」を入力するとコマンド候補が表示されるので、作成したレビューコマンドを選択します。
私の場合は、現在の変更差分をコンテキストに含めるために、合わせて @Branch(Diff with main)も指定して実行しています。

これで実行できます。モデルは gpt-5.1-codex を使ってみます。

検証用に意図的に問題を含ませたPythonのコードを用意しました。
検証用コード
"""テスト用のpythonコード"""
def filter(data, threshold):
"""ビルトインfilterのシャドウイング"""
picked = []
for item in data:
if item > threshold:
picked.append(item)
return picked
def process_user_data(x, y, z):
"""単文字変数と未使用値"""
unused_config = {"debug": True}
a = x * 2
b = y + 10
c = z - 5
return a + b + c # 無意味な合算
def calculate_price(quantity: int, price: int) -> int:
"""戻り値の型宣言不一致"""
return quantity * price * 0.8
def analyze_nested_data(data: list) -> dict:
"""過剰なネスト"""
result = {}
if data:
for i in range(len(data)):
if isinstance(data[i], dict) and "value" in data[i]:
if isinstance(data[i]["value"], (int, float)) and data[i]["value"] > 0:
result[f"item_{i}"] = data[i]["value"] * 2
return result
def process_items(items: list) -> list:
"""不要な多重イテレーション"""
first = [{"id": item, "processed": False} for item in items]
second = [str(entry) for entry in first]
return [entry.upper() for entry in second if entry]
def main():
"""未使用値と誤った型注釈"""
data = [1, 2, 3]
filter(data, 1)
process_user_data(1, 2, 3)
price: int = calculate_price(2, 50)
analyze_nested_data([{"value": 10}, {"value": -1}])
process_items(data)
print("テスト実行完了")
if __name__ == "__main__":
main()
コマンドを実行すると、以下のようにチェックリストの項目を満たしているか判定し、結果を出力してくれます。
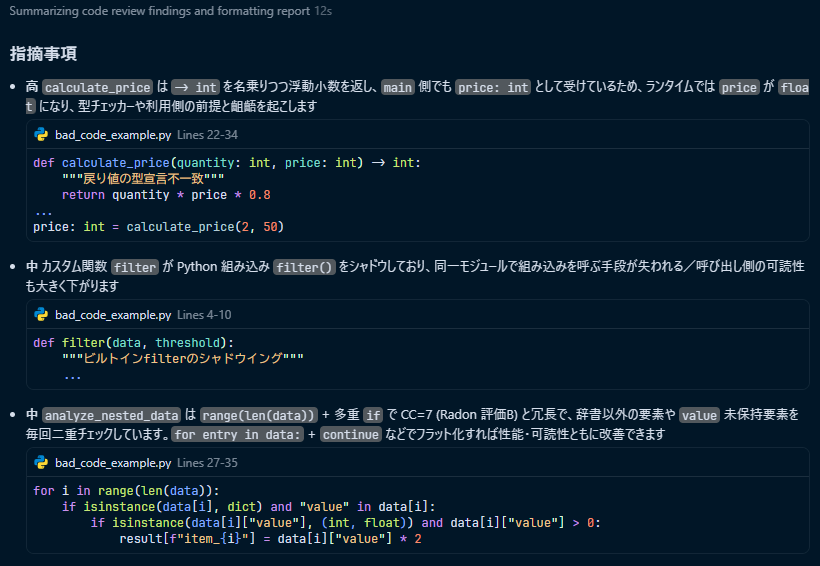

(「指摘事項」の前にはgitコマンドや循環的複雑度計測コマンドが実行されたりする)
gpt-5.1 の場合



Composer1 の場合

(gitコマンドで差分取得)


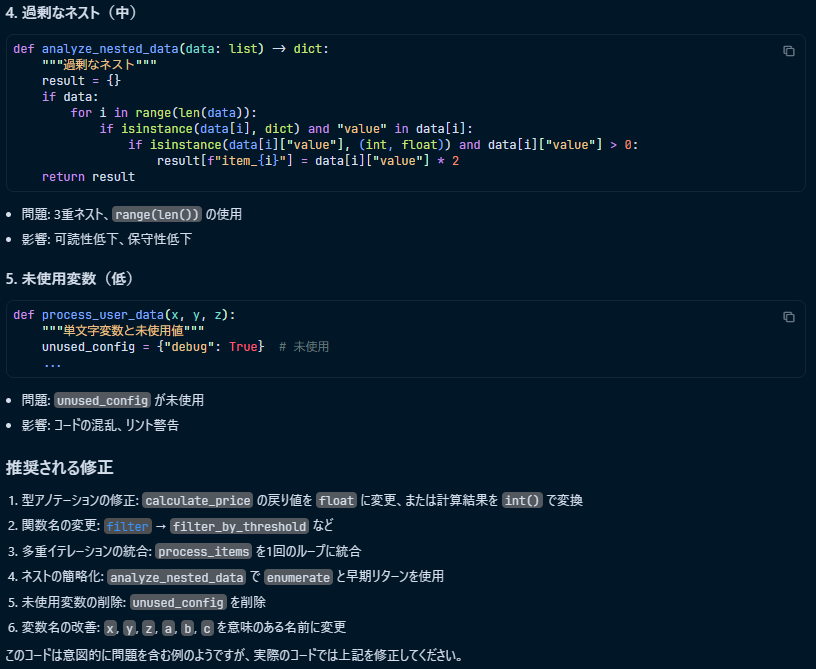
所感
PRの差分に対するレビュー結果を一覧で確認できるため、全体感を掴むのに非常に役立っています。ここで問題点が指摘された箇所については、重点的にコードを確認するようにしています。
また、今回は簡単なカスタムコマンドとして作成しましたが、コマンド実行のログや出力結果からの所感として、gitやghコマンドを利用して「差分の取得」から「分析」までをコマンド定義内で完結させるのも良いかもしれません。実行したい手順を順に記述していく形が、カスタムコマンドの構成としては相性が良さそうです。
Cursor PR-Quiz
pr-quiz という、プルリクエストの内容をAIが解釈してクイズを出題してくれるユニークな GitHub Action があります。
本来は CI 上で動くものですが、GitHub Actions のワークフローをチームのリポジトリに追加するには、合意形成や設定などのハードルがあります。
そこで今回は、このツールのコアである「プロンプト」部分のみを流用し、Cursorのカスタムコマンドとして手元で実行する形式を試しました。
オリジナルのプロンプト内容に加えて、「生成されたクイズと回答をファイルとして保存する記述」を書き加え、以下のようにカスタムコマンドとして定義しています。
# Pull Request to Quiz
## 概要
あなたは、プルリクエストの理解度をテストするための、コードレビュー教育ツールです。
複数選択肢のクイズ形式で出題を行います。
目的:レビュー担当者が、コードの変更内容を理解せずに形式的に承認(ラバースタンプ)するのを難しくすること。
### 出題数の目安
- **小規模変更(1-3ファイル、軽微な修正)**:2-3問
- **中規模変更(4-8ファイル、機能追加・修正)**:4-5問
- **大規模変更(9ファイル以上、大きな機能変更)**:6-8問
### 要点
(ほぼ参考元のプロンプトと同じため省略)
### make & save files
問題と回答ファイルはMarkdown形式で作成し、以下のルールに従って保存してください。
また、保存先ディレクトリは存在しない場合のみ作成すること。
確認コマンド `ls -ld .pr-quiz/quizzes .pr-quiz/answers`
- 各ファイルには以下のコマンドで取得したブランチ名(branch_name)を付けること。
- `git branch --contains | cut -d " " -f 2`
- 問題:
- ファイル名: `pr-quiz__{branch_name}.md`
- 保存場所: `.pr-quiz/quizzes`
- 回答:
- ファイル名: `pr-quiz-answer__{branch_name}.md`
- 保存場所: `.pr-quiz/answers`
コマンド実行
前述のレビューコマンドと同様、チャット欄で「/」と入力し、対象の @Branch を指定して実行します。
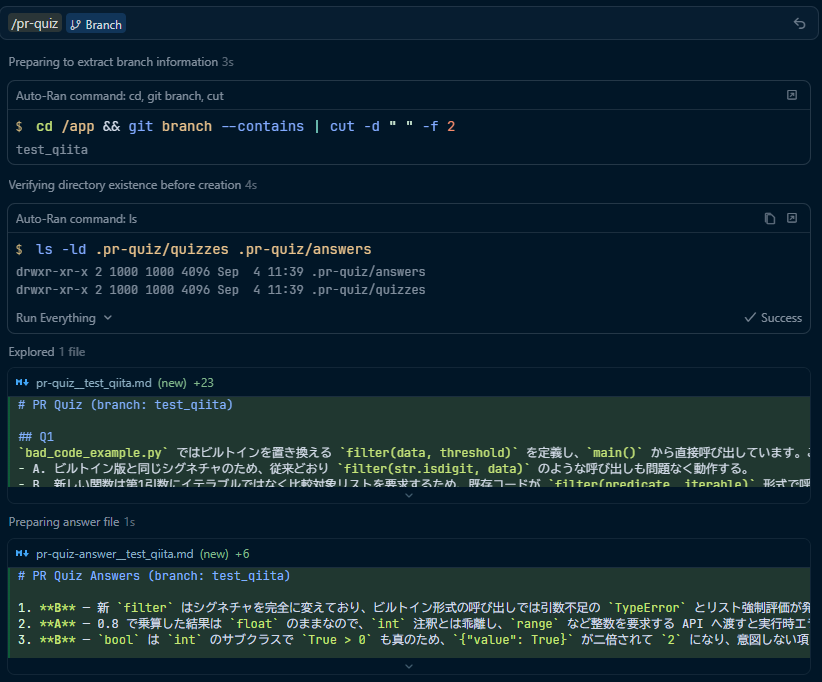
例えば Issue_12345 というブランチで実行した場合、以下のようなファイルが生成されます。
-
問題:
.pr-quiz/quizzes/pr-quiz__Issue_12345.md -
回答:
.pr-quiz/answers/pr-quiz-answer__Issue_12345.md
活用フローとしては、まず軽くコードに目を通した後にクイズを解き、最後に回答ファイルと照らし合わせます。これにより、変更内容や実装者の意図を正しく読み取れているか(理解度)をセルフチェックできます。
これで実行できます。

pythonサンプルコードで作成した場合のチャット
ブランチ名は test_qiita
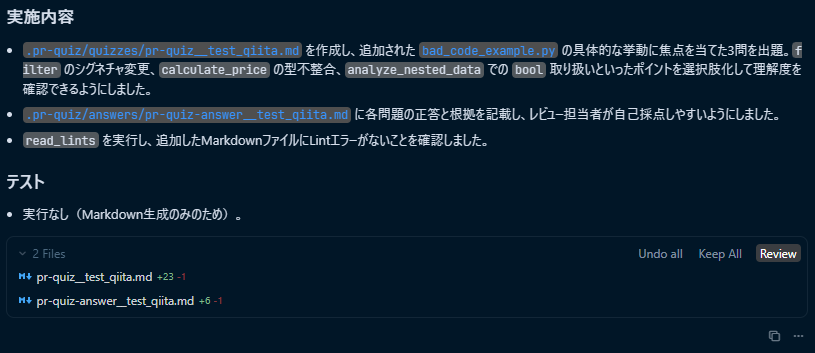
以下は、実際の開発ブランチを元に生成された問題と回答の一例です。
(内容は抽象化・マスキングしています)
- 問題
# Pull Request Quiz - Issue_12345
## 問題1 (難易度: 中)
このPRの変更で、「対象Aの識別子(ID)」を扱うハンドラクラスのコンストラクタが変更されました。
以前は「対象Aオブジェクト」と「利用者オブジェクト」の2つを受け取っていましたが、
変更後は、それらから取得した「対象AのID」(単一の識別子)のみを受け取るように簡素化されました。
この設計変更の主な理由として最も適切なものはどれでしょうか?
* A. メモリ使用量を削減するため、オブジェクト参照を減らした
* B. コンストラクタでの不要な依存関係を減らし、テストしやすくするため
* C. 対象Aと利用者からIDを取得する処理があちこちで重複していたため
* D. 内部のキャッシュ処理では対象AのIDのみを使用しており、それ以外の情報が不要だったため
## 問題2 (難易度: 中〜高)
ある設定項目では、「どの対象に対して処理を行うか」を柔軟に指定できるようになっています。
この項目には、ざっくり次のようなフラグ・状態があります。
* 設定ごとに対象を個別指定するかどうか(個別指定フラグ)
* 「対象A」を基準に指定するかどうか(対象A形式フラグ)
* 「対象B」を基準に指定するかどうか(対象B形式フラグ)
* 既定パターンを使うか、カスタムパターンのみを使うか(既定パターンの有無)
*
新しく追加されたバリデーションクラスの validate() に相当するメソッドは、これらの組み合わせによって妥当性を判定します。
このとき、validate() が False(不正)を返す組み合わせとして最も適切なものはどれでしょうか?
* A. 個別指定 = 有効、対象A形式 = 有効、対象B形式 = 無効、カスタム対象Aパターンあり
* B. 個別指定 = 無効、対象A形式 = 無効、対象B形式 = 有効、既定対象Bパターンあり
* C. 個別指定 = 有効、対象A形式 = 有効、対象B形式 = 有効、カスタムパターンのみ
* D. 個別指定 = 無効、対象A形式 = 有効、対象B形式 = 有効、既定対象Aパターンあり
- 回答
# Pull Request Quiz 解答 - Issue_12345
## 問題1 解答: **D**
正解: D. 内部のキャッシュ処理では対象AのIDのみを使用しており、それ以外の情報が不要だったため
解説:
このハンドラの実装では、キャッシュキーの生成および内部状態の管理において、
実際に必要なのは「対象AのID」だけでした。元の「対象Aオブジェクト」や「利用者オブジェクト」のその他のプロパティは参照されていません。
そのため、コンストラクタの引数を「本当に必要な情報(対象AのID)」に限定することで、依存関係が減り、責務が明確になり、コードの保守性が向上します。
誤答の解説:
A: オブジェクト参照を減らすことでメモリ使用量はわずかに減る可能性がありますが、それは副次的な効果であり主目的ではありません。
B: テスタビリティの向上は結果として得られますが、「内部でIDしか使っていない」という設計上の事実がより直接的な理由です。
C: 「処理の重複」が主な問題だったわけではなく、そもそもコンストラクタやキャッシュ処理で他の情報を使っていなかった点が本質です。
## 問題2 解答: **C**
正解: C. 個別指定 = 有効、対象A形式 = 有効、対象B形式 = 有効、カスタムパターンのみ
解説:
このバリデーションでは、「個別指定フラグ」が有効な場合、1つの設定の中で対象A形式と対象B形式を同時に有効にすることを禁止する という業務ルールが実装されています。
選択肢Cは
* 個別指定 = 有効
* 対象A形式 = 有効
* 対象B形式 = 有効
という組み合わせであり、「1つの個別設定で対象Aと対象Bを同時に扱おうとしている」状態のため、不正(False)となります。
誤答の解説:
A: 個別指定が有効で、対象A形式のみを使うパターンはルール上許可されています。
B: 個別指定が無効で、対象B形式のみを使うパターンも許可されています。
D: 個別指定が無効な場合は、「どの形式を既定として使うか」を柔軟に選べる設計であり、対象A形式と対象B形式を両方有効にしていても許容される前提です。
所感
変更規模が大きいPRをレビューする際、クイズ感覚で要点を把握できるため非常に有用だと感じました!
変更量やファイル種別に応じて、問題の難易度や出題数をうまく自動調整したいところです。
また、単に差分を見るだけでなく、PRの概要文(Description)やコミットメッセージもコンテキストとして読み込ませることで、実装者の意図をより深く汲み取った作問が可能になるかもしれません。
GitHub Copilot Agent Review
最後にご紹介するのは、GitHub Copilot を活用したコードレビューです。
プルリクエストのレビュアーとして Copilot をアサインするだけで、AIが自動的にコードレビューを行ってくれる機能です。
さらに、リポジトリ内にカスタム指示ファイルを追加することで、レビューの観点や振る舞いをプロジェクトに合わせてカスタマイズすることが可能です。(参考)
リポジトリにカスタム指示を追加することで、Copilotのコードレビューをカスタマイズできます。
リポジトリ固有のカスタム指示は、リポジトリ全体または特定のパスに限定して適用できます。リポジトリ全体に対するカスタム指示は、リポジトリ内の.github/copilot-instructions.mdファイルで指定します。 このファイルを使用すると、リポジトリ内の任意の場所でコードレビューを行う際に Copilot が考慮すべき情報を保存できます。
これらのドキュメントを元にカスタム指示用ファイルを2つ作成しました。
.github/copilot-instructions.md
# GitHub Copilot カスタム指示
## 言語設定
すべてのレスポンス、コードレビュー、コード生成、説明は **必ず日本語** で回答すること。
## プロジェクト概要
このプロジェクトは XXXXX ベースのバックエンドとフロントエンドを含む XXX アプリケーションである。
## 技術スタック
- バックエンド: Xxxxx, Yyyyy, Zzzzz
- フロントエンド: Aaaaa, Bbbbb, Ccccc
- 品質管理: Ddddd, Eeeee, Fffff
## コードレビュー
コードレビューを行う際は、変更内容や対象となる言語・技術に応じて、`.github/review-checklist.md` に記載された項目の中から該当するもののみを選んでチェックしてください。
該当しない項目はスキップして構いません。
.github/review-checklist.md
# コードレビュー チェックリスト
(Cursorスラッシュコマンドのレビューチェックリストと同じ内容)
## 新規追加
### 命名規則
- Xxxxx: snake_case (関数・変数), PascalCase (クラス), UPPER_SNAKE_CASE (定数)
- Aaaaa: camelCase (関数・変数), PascalCase (クラス)
実行
先ほどのpythonサンプルコード用いてプルリクエストを作成し、Copilotにレビューを依頼しました。
以下はCopilotレビューのコメントの一部です。
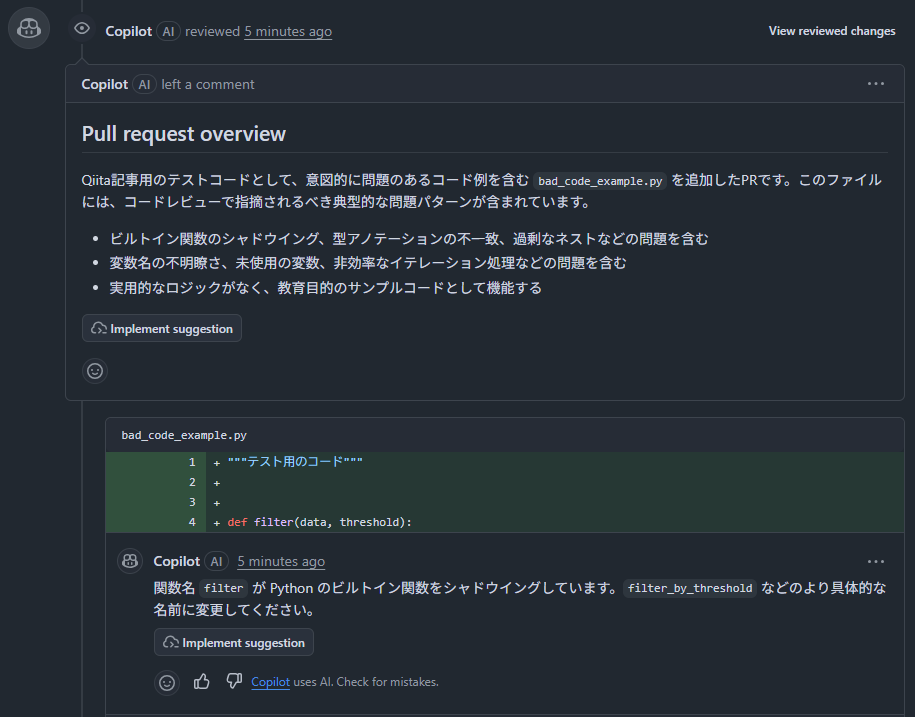

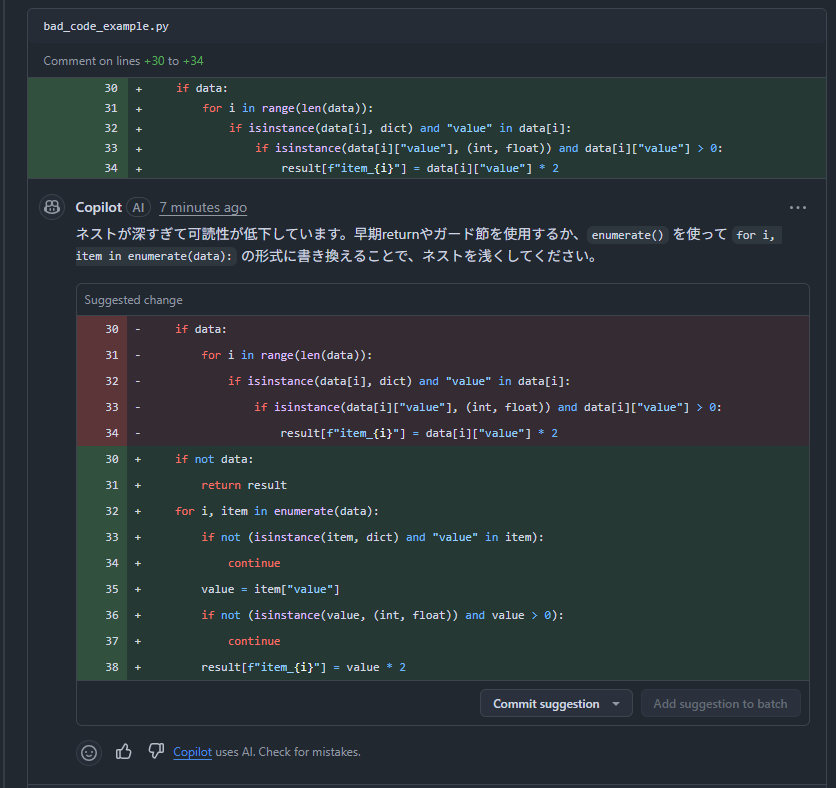
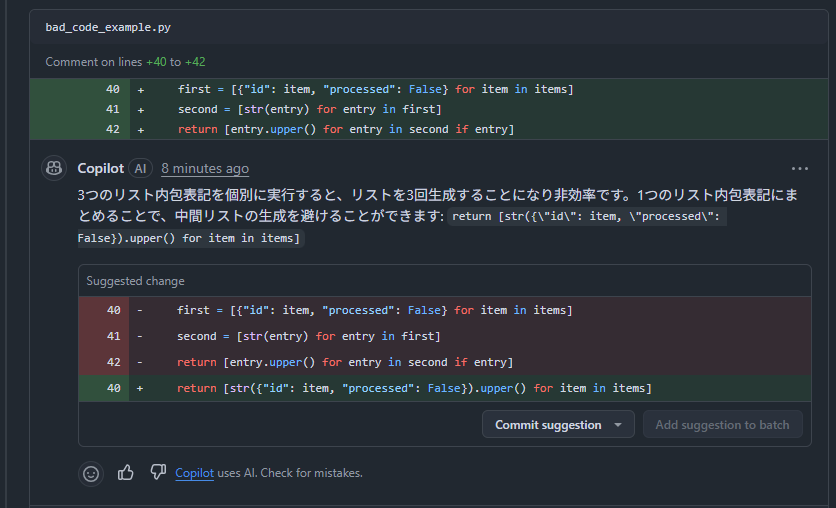
Tips: 以下の操作でCopilotコメントの変更提案を簡単に取り込めます
所感
変更に対して基本的な指摘をコメントしてくれるため、一次レビューとして十分機能する印象です。
一度、自分のプルリクエストをCopilotにレビューさせた際、普段自分が他人のコードに対して指摘しているような内容を逆に指摘され、ハッとしたことがあります😅
現状の挙動としては、プロジェクトの背景情報や他のディレクトリ構造まで深く考慮しているわけではなく、あくまで「変更されたコードブロック内」での局所的な分析に留まっているイメージです。
そのため的外れなコメントも散見されますが、それに対してプルリク作成者が「なぜその実装にしたか」を返信(反論)することで、実装意図の再確認や言語化の練習にもなるため、逆に良いのかなと思っています。
また、明示的に指示を出していても回答が日本語にならないケースがあったため、カスタムインストラクションの最適な設定については現在も模索中です。。
感想
今回検証した手法は、どれもコードレビューにおける「一次レビュー」として十分な役割を果たしてくれました。
厳密な数値計測までは行っていませんが、体感としてレビュー全体にかかる時間や労力は確実に削減されており、深いレビューに注力できていると感じています!
もちろん、あくまでAIツールによる補助であるため、最終的な意思決定や深い観点でのレビューはレビュアーが行う必要があります。
プロジェクト固有の背景情報や、複雑な仕様の意図も汲み取ってくれるような仕組みを考えつつ、今後も開発プロセスの効率化について模索していきたいと思います。
もし他にも良い方法やアドバイス等があれば、ぜひコメントで教えてください!!🦋
Special Thanks
チェックリスト作成の相談に乗ってくれたり、コマンドの動作検証に協力してくれた @djwq さん(明日のアドカレ10日目担当です!まさかの去年と同じく連番!)
おまけ
最後に少し宣伝です。
私が所属する株式会社DONUTSおよびジョブカン事業部では、新卒・中途を問わずエンジニアを積極的に採用しています。
もし弊社に興味を持っていただけた方、あるいは「業務で堂々と最新のレビュー効率化ツールを試してみたい!」という方は、ぜひ応募をご検討ください!!