はじめに
お世話になっております。primeNumberの庵原です。
寒い日が続いておりますが、皆様いかがお過ごしでしょうか。
最近ですが、BigQueryからSQLだけを用いて画像から情報を抜き出せるという近未来的な機能がリリースされたのことだったので、何か記事にしたい!と考え、スターバックスコーヒー(以降スタバ)のレシートをSQLで呼んだらいいんじゃないか?なんならそれでカロリー計算したらいいんじゃないか?と思いつきました(??)
それを実現するための手順を皆様に共有できたらと思っております。
この記事の対象者
- BigQuery × AIに興味がある方
- DocumentAIのデータの活用手段の一例をみてみたい方
この記事の内容
- DocumentAIの簡単な説明
- DocumentAIの設定手順(モデル構築)
- BigQuery × DocumentAIの活用方法
今回のゴール
今回のゴールは実際のスタバのレシートの写真から購入商品の名前の情報を抜き出して、商品マスタテーブルと突き合わせてカロリー計算をしてみます。
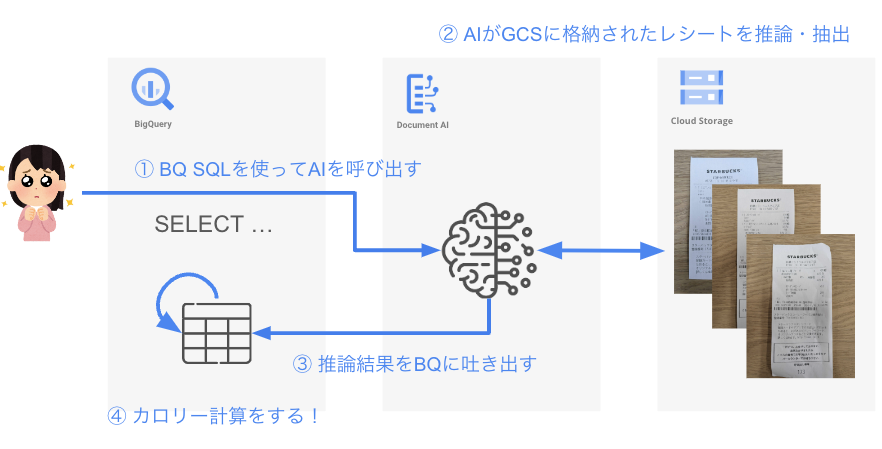
構成図
ざっくりとしすぎた構成図で大変恐縮ですが、まずBigQueryからSQLを使ってモデルを呼び出します。そのモデルがCloud Storageに事前に格納されたスタバのレシートに対して推論&抽出を行い、欲しいデータを取得し、BigQueryのテーブルに格納しておきます。最後に事前に用意したカロリー情報と突き合わせて、カロリー計算をしてみます!
図にすると以下のようになります。
サービスについて
DocumentAIとは
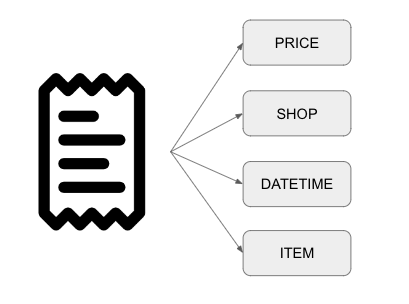
Google CloudにおけるDocumentAIはいわゆるOCRと呼ばれる部類のもので、ドキュメントや画像からデータを抽出することができるサービスのことです。
例えば、レシートから「なんの商品を買ったのか?」「いくらしたのか?」「どこで買ったのか?」「いつ買ったのか?」などの情報を読み取ることができます。
BigQuery
Google Cloudが提供するデータ分析に特化したデータベースです。
元々は大量データを高速かつ安価に集計・集約して分析におけるさまざまな障害をとっぱらって加速させるようなサービスですが、以前ご紹介したPaLM2・Natural Language APIの記事(読んでくれると飛び跳ねまs ((殴)のように、AIサービスとの連携強化により、データを直接AIに渡すことができるようになり、データ×AIの活用レベルが格段に上がってきています。
DocumentAIを触ってみよう!
では早速DocumentAIを使えるようにするために、設定していく流れを見ていきましょう!
このセクションでは実際にスタバのレシートから情報を抜き出すためのモデルを作成する手順をお見せしたいと思います!
今回の手順については、公式が公開している以下の記事を参考にしております。
1. プロセッサ作成と抽出データ定義
DocumentAIの画面に入ると以下のような画面が出てきます。
ここから「カスタムプロセッサを作成」と押してみましょう。
今回はレシートから特定の情報を抜き出したいので、一番左の「Custom Extractor」を選択し、適当な名前をつけて作成します。
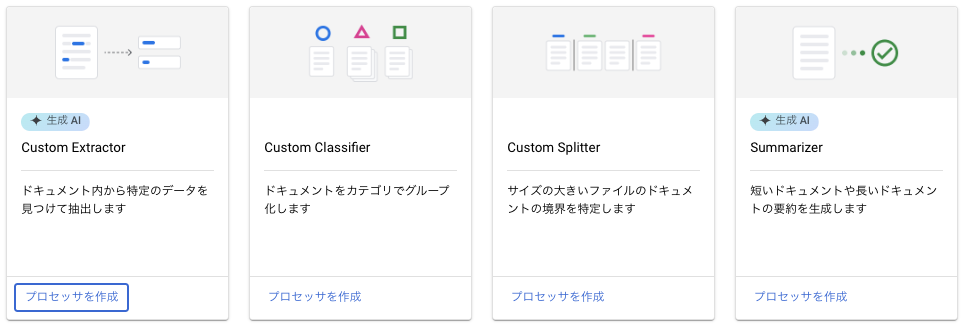
作成後、以下のような画面が出てきます。
ここでデータセットの用意やモデルの学習・デプロイなどを一括で管理することができます。
ここで画像左側の「開始」を押してみると下記のようなページに遷移します。
ここでは実際に取り出したいデータの項目を定義することができます。
今回はレシートからデータを取り出したいので、以下のようなデータを取り出そうと思います。使わないデータがほとんどですが、せっかくですから多めに取っておきます。
※ スタバでは「エスプレッソショット追加」「氷少なめ」「アーモンドミルク変更」など、様々なカスタマイズができますが、今回は省略します。
| 項目名 | 物理名 |
|---|---|
| 商品名 | name |
| 商品のサイズ | drink_size |
| 商品の数 | amount |
| 商品の値段 | price |
| 合計金額 | total_price |
| 決済日時 | payment_datetime |
| 決済方法 | payment_method |
| 店舗名 | shop_name |
| 店舗電話番号 | phone_number |
| 登録番号 | registration_number |
| 店内利用か持ち帰りかのフラグ | stay_label |
これを元にフィールドを作成すると以下のようになります。
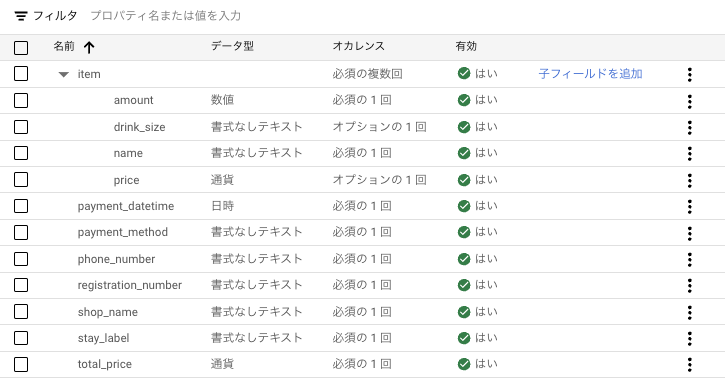
ここでitemというラベルの配下にamount〜priceまでありますが、1つの親フィールドに対して、複数の子フィールドを関係付けることができます。これにより、データ項目をまとめて扱うことができるようです。
2. データセットの作成・アノテーション
次にCloud Storageから画像をデータセットとして扱えるようにDocumentAI側にインポートします。
今回はあらかじめ写真で撮っておいたレシートの画像をCloud Storageに配置してあります。
DocumentAIの左のタブの「ビルド」を押すと以下のような画面に遷移します。
青ボタンの「ドキュメントをインポート」を押すとインポートする際の条件を指定することができます。
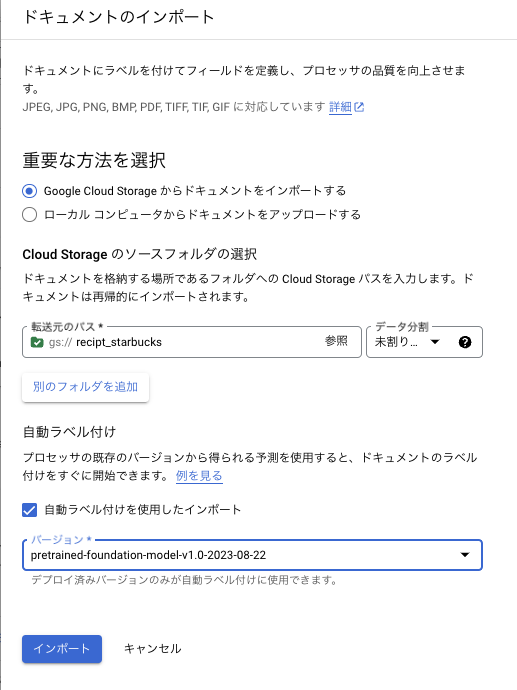
事前に用意したバケットを指定します。この段階ではデータ分割(トレーニング用データかテスト用データか)の選択はせず、未割り当てとして進めていきます。
さてここで「自動ラベル付け」というものが選択できます。ここではGoogleが事前に作成しているモデルや、自分が過去に作成したモデルを用いて、ある程度アノテーションを行ってくれる機能を利用することができます。
今回はここではGoogleが事前に作成しているモデルを使ってみましょう。
これでインポートされた画像を実際に見てみましょう。
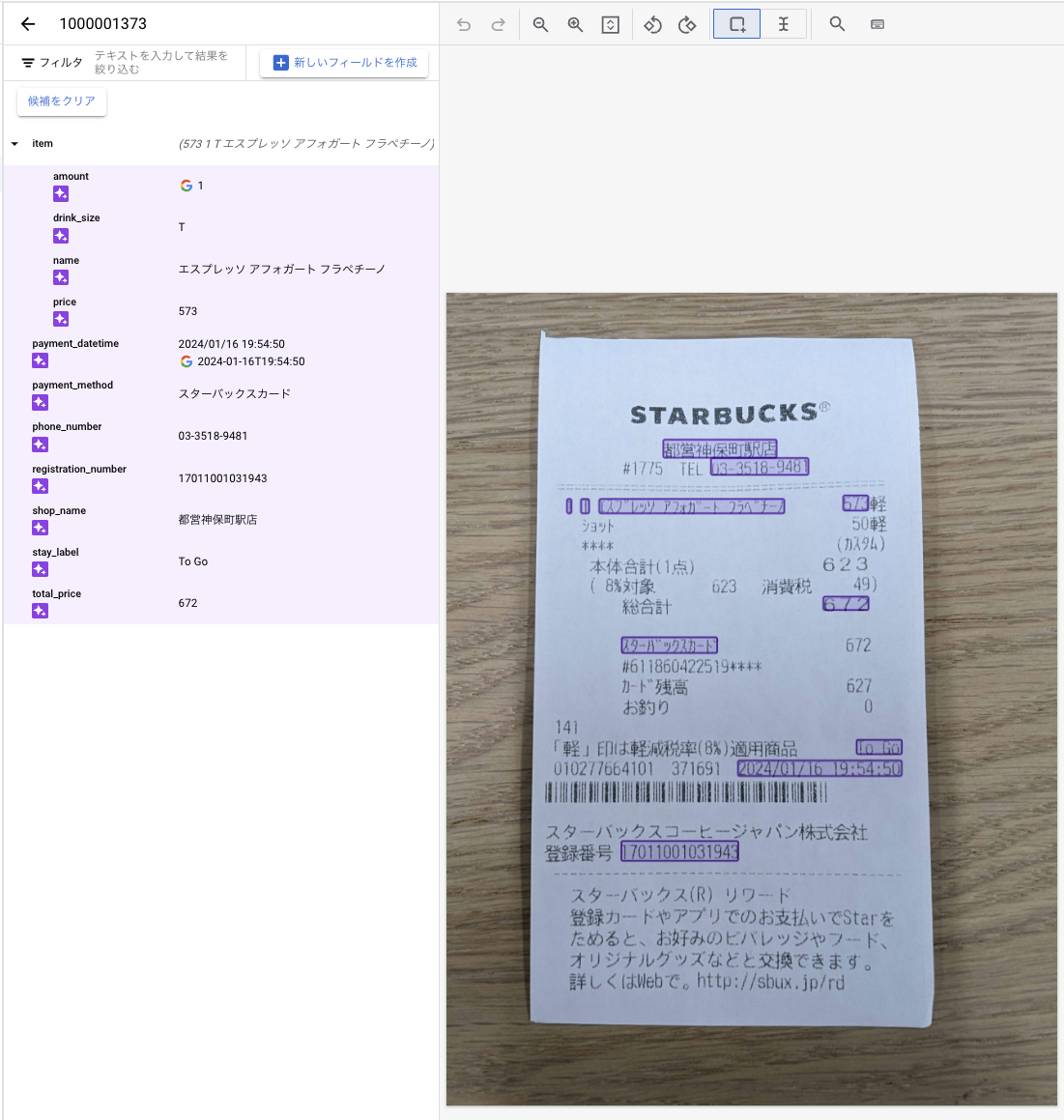
作成された項目をもとに、モデルが勝手にアノテーションしてくれてるではありませんか!!!
しかも、場所については完璧にアノテーションされており、抽出されているデータ内容もほぼ齟齬がありません。
場合によっては自動アノテーションが行われなかったり、場所が間違えていたり、取れているデータが違うこともあります。
ですが、それもドラッグ&ドロップで簡単に修正できちゃうんです。
わかりづらいGIFですが、こちらが実際の作業映像です。
これのおかげで20枚以上アノテーションする必要があっても、自動ラベル付け + GUI簡単アノテーションでスイスイできちゃうわけです。本当に感動しました。
アノテーションが完了したので、合計21枚あるデータを11枚は訓練データ、10枚はテストデータとしておき、次のステップにいきましょう!
3. モデル作成
データセットの用意もチャチャっと用意できたので、次は推論をしてくれるモデルを作成していきましょう!
モデルには大きく2種類があるようです。
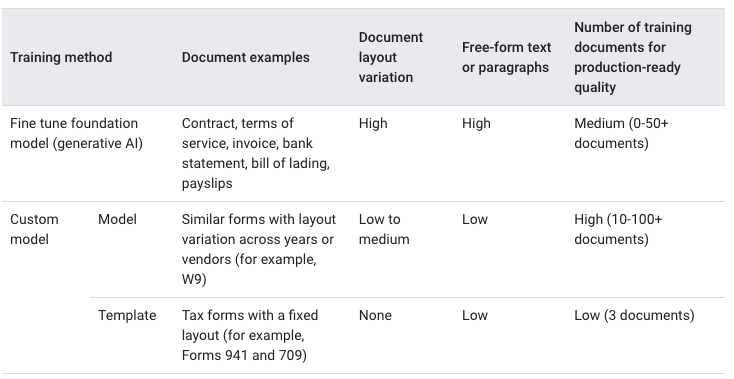
- ファインチューニングした基盤モデル(生成AI)
- 契約書、利用規約、請求書、銀行取引明細書、船荷証券、給与明細向け
- ドキュメントのバリエーションが高いもの向け
- 自由形式向き
- 品質担保のためのトレーニングデータセットの推奨数は0から50以上
- カスタムモデル
- モデル(ニューラルネットワーク)
- 年やベンダーによってレイアウトが若干異なる類似のフォーム向け
- バリエーションは低から中程度のものが対象
- 品質担保のためのトレーニングデータセットの推奨数は10から100以上
- テンプレート
- 固定レイアウト向け
- バリエーションはないものしか対応していない
- 品質担保のためのトレーニングデータセットの推奨数は3以上
- モデル(ニューラルネットワーク)
今回はレシートであり、特に商品の部分は購入する数や決済方法によってレイアウトがコロコロ変わってしまうので、生成AIを活用した基盤モデルのみを使ってみましょう。
データセットのインポートと同じ「ビルド」の画面から「基盤モデルを呼び出す」 > 「新しいバージョンを作成」からモデルを作成します。
モデルを作成するとトレーニングが1分程度かかりますが、すぐに完成します。
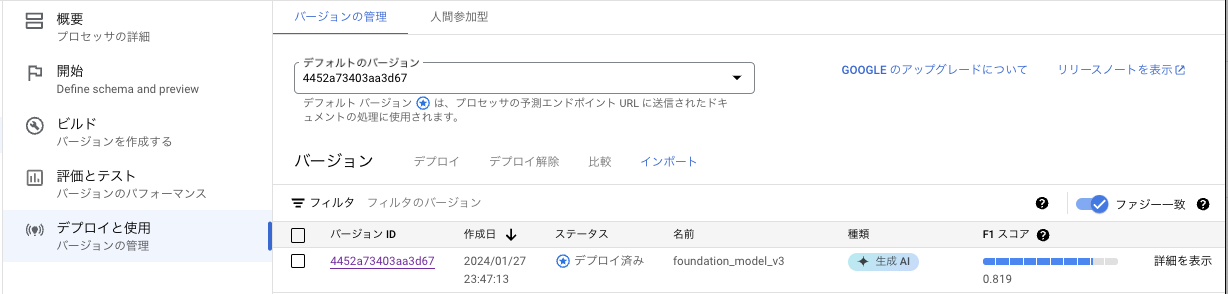
「デプロイと使用」のページに移ると次のような形で、作成したモデルが表示されます。
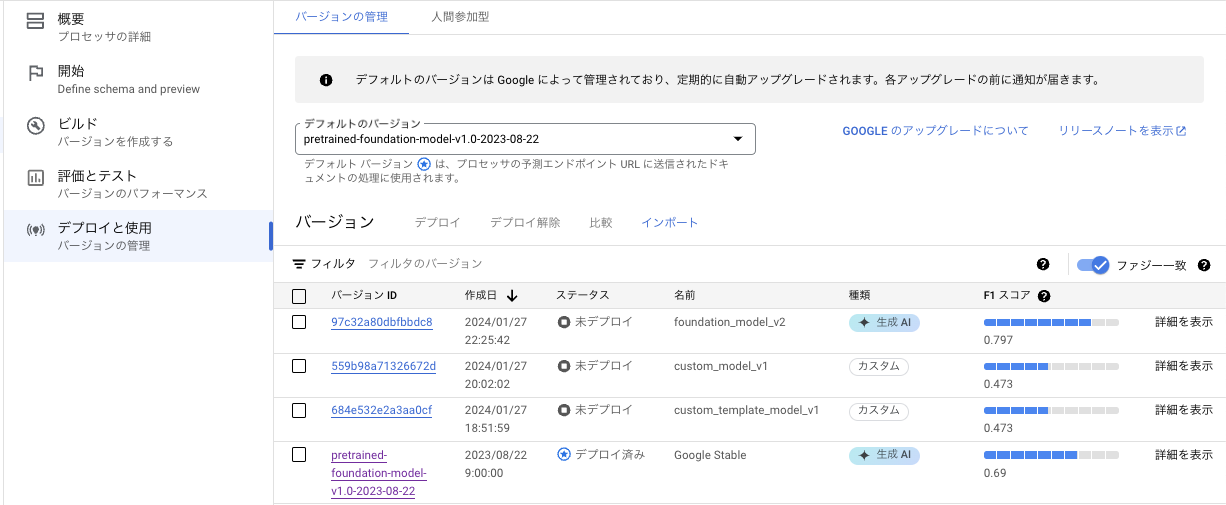
わかりづらいですが、作成したのはfounddation_model_v2(v1は消しました)でF1スコアは0.797と出ています。怒られそうですが、大体8割くらいの精度だということです。
ちなみにカスタムモデルもトレーニングしてみましたが、時間がかかった割には精度があまり良くなかったです。説明通り、バリエーションが高すぎると精度が下がるようでした。
4. 詳しい評価を見てみる
さて、作成したモデルが具体的にどこで間違いやすいのか?を調べることはAIの精度を上げていく上で重要なプロセスですが、これも実は簡単に見ることができます。
「評価とテスト」 > 「評価全体を表示」を見ると、作成したモデルの各項目に対する精度を見ることができます。
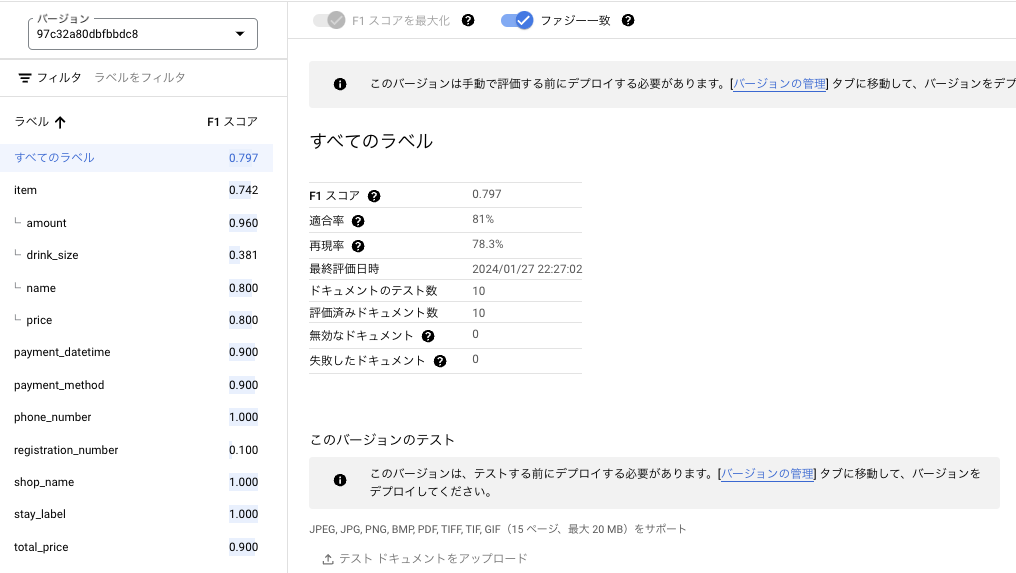
例えば、item.amountのF1スコアは0.960とかなり高いですが、item.drink_sizeは0.381とかなり低いです。
どのように間違えているかを見てみると、例えば「偽陰性(予測できなかったもの)」を見てみると以下のような間違え方をしていました。
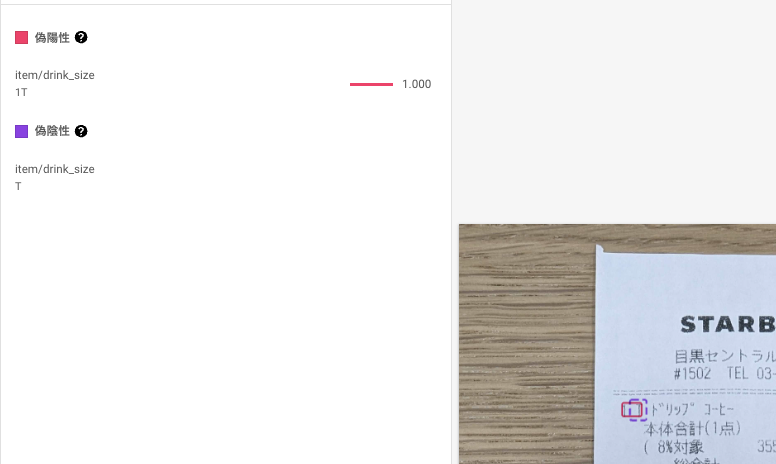
本来はTのみを出力しなければならないところを、推論した結果は1Tと出力されています。
このようにどのようにして間違えたか、ということをすぐにわかるようになっています。これを元にアノテーションのラベル位置を変えたり、画像を用意しなおしたり、これを訓練データから弾くなどの選択肢が取れるかと思います。
今回はこの結果を受けて、アノテーションの改善と訓練・テストの再配置を行い、再度モデルを作成すると、F1スコアが0.842となり、約0.05ポイントも改善されました!
このように、モデル自体がどこに苦手意識を持っているか?を探るのも、精度を上げるためのtry&errorもこんなに簡単に行えてしまうことがわかりましたね!
5. デプロイ
最後にデプロイ画面から一番良いモデルを外部からも利用できるようにデプロイし、完了です。
ここまで全くプログラミングを記述したりやコマンド入力をせずにここまでできてしまいました。
ある程度の機械学習に対する知識があればすぐにでも使えるのが強みに感じました。
BigQuery × DocumentAIを体験してみよう!
さぁ次にお待ちかねのBigQuery × DocumentAIについてみていきます!
ここの手順は以下の公式ページを参考視しております。
https://cloud.google.com/blog/ja/products/data-analytics/add-gen-ai-to-your-apps-with-bigquery-and-document-ai-integration
事前準備
いくつかの事前準備が必要のため、さくっとご説明します。
1. 外部テーブル作成
まずは、Cloud Storageのデータを外部テーブルとして呼び出すために以下を実行します。
画像データをテーブルのように扱うためのものです。これを実行することで、キャッシュを効かせたり、アクセスの制御を細かくすることができます。
-- 外部テーブル作成
create or replace external table sample_dataset.recipt_starbucks
with connection `us.doc-ai-function`
options (
object_metadata = 'SIMPLE',
uris = ['gs://recipt_starbucks/*']
);
2. 外部接続作成
外部接続の作成をします。
細かい説明は端折ってしまいますが、外部接続という名のサービスアカウントがBigQueryとそれ以外のサービスの橋渡しをしてくれるイメージです。
作成されたサービスアカウントには以下のロールを付与してください。
- DocumentAI閲覧者
- Storageオブジェクト閲覧者
- (Vertex AIユーザー)
また今回の外部接続の名前はus.doc-ai-functionで進めさせていただきます。
BigQuery上でモデル定義
さて、外部テーブルと外部接続の設定が済んだので、DocumentAIの訓練させたモデルを呼び出すための設定を行います!
以下のクエリを実行します。
CREATE OR REPLACE MODEL `sample_dataset.recipt_extractor`
REMOTE WITH CONNECTION `us.doc-ai-function`
OPTIONS (
remote_service_type = 'CLOUD_AI_DOCUMENT_V1',
-- document_processorはデプロイしたモデルのuriとversionを入力する
document_processor = 'projects/*****/locations/us/processors/*****/processorVersions/*****'
);
たったこれでだけです!
これでとDocumentAIをSQLで呼び出すためのモデルを定義できます。
実行してみよう!
呼び出すのも簡単で、ML.PROCESS_DOCUMENT関数を呼び出すだけです。
呼び出す時には、推論したい画像データがある外部テーブルと、作成したモデルを指定するだけです。
SELECT
*
FROM ML.PROCESS_DOCUMENT(
MODEL `sample_dataset.recipt_extractor`,
TABLE `sample_dataset.recipt_starbucks`)
実行すると以下のようになります。
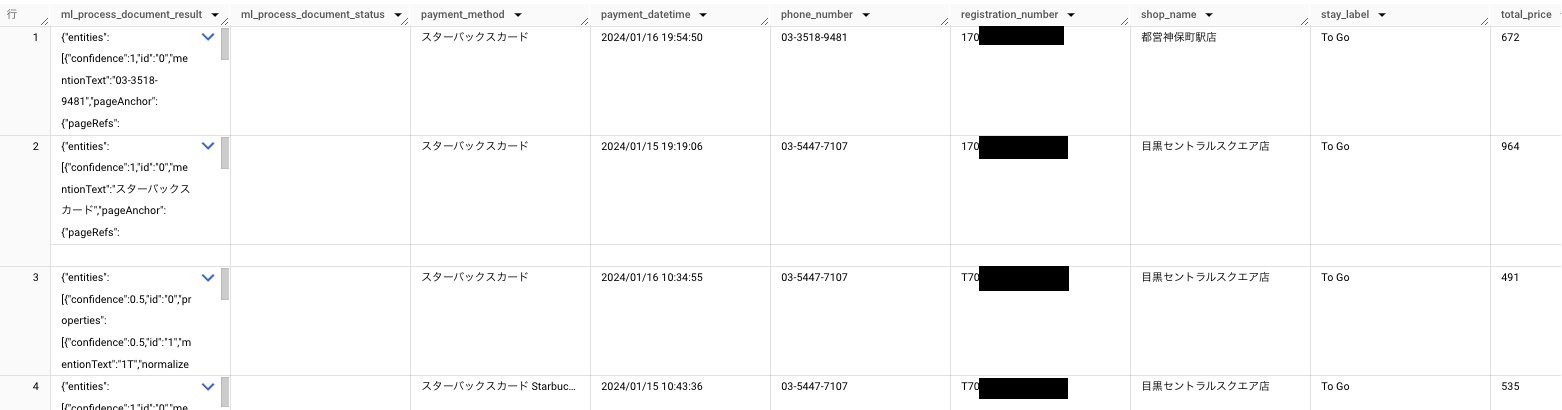
ちゃんとにデータが取れていますね!
このような形で、SELECT文数行のみでAIの呼び出しと推論ができてしまうのです!
カロリー計算してみよう!
では最後にレシートから取得できたデータを使って全部で何キロカロリー摂取したのか?を計算してみたいと思います!
カロリー情報の用意について
これを進めて行くにあたって、カロリーのマスタテーブルが必要になります。スクレイピング等で取得する方法もあるかと思いますが、グレーな部分でもあるので、今回は真心を込めた手動スクレイピングで対応します。
また今回はサイズについては便宜上全てトールサイズとして計算しています。
補足程度ですが、スクレイピングの注意点や法律、実際に行う場合のセルフルールなどについては、こちらの記事が大変参考になります。スクレイピングの注意点
手動でかき集めたデータは以下のとおりです。

計算結果
primeNumberの近くのスターバックス店舗で「目黒セントラルスクエア店」があるのですが、そちらで購入した商品の合計カロリーを算出してみましょう!
SELECT
SUM(mst.kcal) AS sum_kcal
FROM
sample_dataset.recipt_unnest
LEFT JOIN
sample_dataset.item_mst AS mst
USING
(name)
WHERE
shop_name = '目黒セントラルスクエア店'
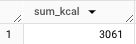
ということで結果は3,061kcalでした...
めちゃめちゃに余談ですが、厚生労働省が発表している成人男性(18~29歳)の適正摂取カロリーは2,300kcal 〜 3,050kcalなので、それを超えた量は購入していたことになります。スタバ恐るべし...
最後に
さて今回の内容はいかがでしたでしょうか?
DocumentAIのUX/UIがとても良かった点とBigQueryとDocumentAIのシナジーが強化されていた点についてお伝えできていれば嬉しいなと思います!
また、OCR機能自体はビジネス上いろんな場面で活用ができるものかなと考えられるのでこの記事を参考にしていただけますと幸いです!