はじめに
Web API の処理は基本的に「同期的」に応答しますが、
処理が長時間かかったり、高トラフィックでバックエンドが耐えられない場合は 非同期処理 を検討する必要があります。
実務で非同期処理を設計することがあり、その中で非同期処理の設計について学んだので(実務ではAzureですが)備忘録として設計時に考えたことを備忘録として残したいと思います。
今回はAWSで非同期処理を実装する際に最も基本的な構成のSNS+SQS+Lambda構成で考えてみます。
非同期処理の採用基準
非同期処理の実装を検討するのは以下のような場合かと思います。
実行時間が長いとき
非同期処理を検討する代表格が処理の実行時間が長い処理になるかと思います。
処理の時間が長い場合には、大きく2つの理由で非同期処理を検討するかと思います。
UXの低下
例えば重い処理などで実行時間が長い(体感3秒以上くらい)の場合にはその間ユーザを待たせてしまうので、UXが低下してユーザの離脱を招いてしまう危険性があるからです。私も3秒以上となると処理が長いなと思ってしまいます。
サービスの実行時間の最大値に引っかかるため
例えばAWS Lambdaでは最大時間が15分間という制限がありますし、APIGatewayには既定で29秒、ALBにも60秒を超えるとタイムアウトするという決まりがあります。つまり、あまりにも実行時間が長いような処理についてはこのような制限に引っかかってしまうために先にレスポンスを返し、処理を非同期に実行する必要が出てきます
高トラフィックが予想されるとき
また一時的にトラフィックが増えるような場合にも非同期処理は有効です。
マシンのスペック的に高負荷には耐えられないような時でも、とりあえずリクエストをキューに貯めておけば、あとは並列化などして、非同期で処理をしていけばいいので安心です。
設計の観点
次に非同期処理を設計するにあたって考慮するべきところについてまとめます。私も勉強中の身ですので、もし誤りがある場合には申し訳ありません。
また非同期処理というと、
- Fan-outパターン
- Kinesisシリーズを使用したストリーム
- EventBridge Pipesを使用したPipes連携
なども他に候補としてはあるかと思いますが、今回は最もオーソドックスな非同期処理のアーキテクチャである、Fan-outパターンをSNS+SQS+Lambdaで実現する際の考慮事項についてまとめます。
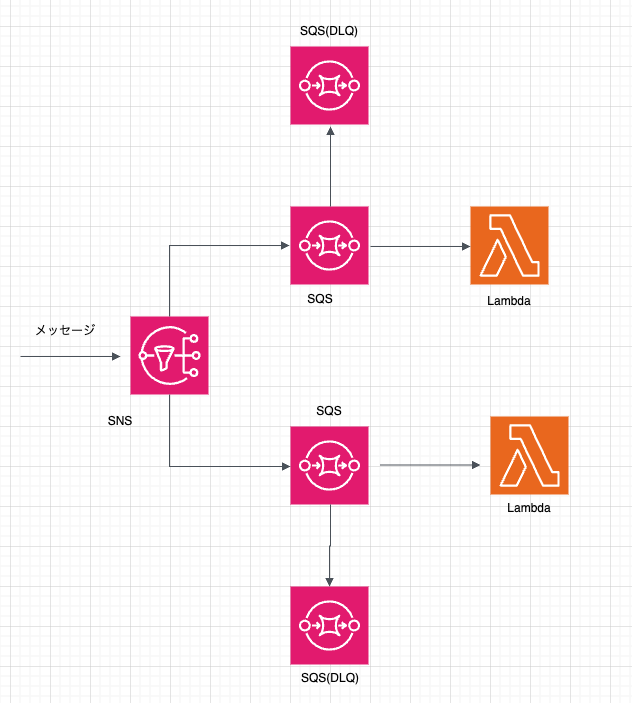
通知方式
ユーザに非同期処理を通知する方法にはいくつか種類はありどの方針を取るのかはその時のユースケースによって異なります。その後にこれはシステムの特性によりますが、ユーザに処理の完了を通知したい場合には代表的に以下の3つの通知方式があります。
- ポーリング
- SSE
- WebSocket
ポーリング
ポーリングとはまずリクエストを受けるとユーザに202を返してから、非同期処理を実行します。この方法ではユーザに完了を通知することができないので、進捗確認用の状態確認APIを準備し、定期的にAPIをコールすることで非同期処理の進捗状況を確認する方法です。
以下のような場合にこの通知方法を検討しましょう
- ユーザには即時で通知を返したい
- 非同期処理の進捗(何%完了しましたとか)はユーザに通知する必要がない
- 実装コストを抑えたい
SSE
SSEは、サーバーがブラウザに対して一方向にデータを送信することができる仕組みです。サーバから非同期処理の進捗をリアルタイムに受け取ることができます。
以下のような場合にこの通知方法を検討しましょう
- 画面を開いたまま進捗ログや%バーをリアルタイム表示
WebSocket
WebSocketはサーバ→ブラウザ、ブラウザ→サーバの双方向で通信することができる仕組みです。
SSEではサーバ→ブラウザの単方向しか通信できませんでしたが、WebSocketは双方向で通信ができるため、ユーザからリクエストを送信して、処理を編集したり、キャンセルしたりすることができます。
以下のような場合にこの通知方法を検討しましょう
- 画面を開いたまま進捗ログや%バーをリアルタイム表示したい
- チャット機能などユーザからのリクエストによって途中で処理をキャンセルしたい
- 低レイテンシーを確保したい
- 実装が複雑になり考慮事項が増えるが構わない
もちろんまだ細かい考慮事項はありますが、システムの仕様や開発期間、ユーザの要望に応じて上記の検討事項を検討すれば最適な通知方法を選択できると思います。
キュー
非同期処理を実現する上ではSQSなどのキューを使用して、データを一時的にキューに貯めておくことが多いと思います。
その際に考慮することについてまとめます。
順序・重複保証

キューには
- 標準キュー
- FIFOキュー
があります。違いはおおまかに以下です。
Amazon SQS キュータイプ
| 標準 | FIFO | |
|---|---|---|
| 順序 | メッセージの順序が保証されない | メッセージが送信された順番で処理される |
| 重複 | 同じメッセージが複数回送信されることがある | メッセージが1度だけ配信されることが保証される |
| スループット | 大量のメッセージを消費できる。 | 標準に比べると遅い。 |
まず順序においては、例えばユーザが5つのリクエストを送信した場合に、標準キューを選択してしまうと2つ目のリクエストよりも先に3つ目のリクエストが実行されてしまう可能性があります。しかし、順序が重要なシステムは存在しており、例えば、注文処理などで決済処理と出荷処理があった場合に、決済処理のリクエストが先に実行されてしまうと整合性が取れなくなってしまうのでこのような順序性が求められる処理ではFIFOキューを選択する必要があります。
次に重複についてですが、AWSのサービスにはAt-Least-Once Delivery(少なくとも1回届ける)という概念があります。これはつまり、少なくとも1回は確実に届けるけど2回以上届けてしまうこともあるという概念です。ですので、もし仮に2回以上同じメッセージが送信されその処理が実行されてもいい場合には標準キュー、そうではない場合にはFIFOキューを選択しますが、そもそもこの点についてはシステムは冪等性(2回以上実行されても同じ結果になる)を満たしている必要があるので、結論として、重複の観点だけで標準キューを選択するのか、FIFOキューを選択するのかの意思決定には影響しないと考えています。
ここまでをまとめると前提として、FIFOの方が料金は高いので、
- 順序性が求められる
- コストが高くてもOK
であればFIFOキュー、それ以外は標準キューという選択でいいかと思います。
メッセージ設計

次にSQSに貯めるメッセージの設計についてです。
メッセージにどんなパラメータを記載するのかはシステムによって変わりますので、今回は対象外とします。
ただ冪等性を守るために、メッセージを一意に特定できるIDを含めておく必要があります。
これにより万が一SQSが同じメッセージを2度送信した場合にも重複して処理を実行することがなくなります。
メッセージの設計で頭に入れておかないといけないのがメッセージサイズです。
SQS/SNSはメッセージ上限が小さい(1024KiB)ため、画像などの大きなペイロードは置かずにあくまで参照先を指定し、実態はストレージに格納しましょう。
メッセージ例
{
"schema": "job.created/v1",
"jobId": "J-2025-09-21-000124",
"downloadUrl": "https://s3.ap-northeast-1.amazonaws.com/acme-job-input/jobs/J-.../input.bin?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=...&X-Amz-Expires=900&X-Amz-Signature=...",
"expiresAt": "2025-09-21T03:30:00Z",
"checksum": "sha256:9f86d081884c7d659a2fe...d28"
}
可視性タイムアウトの設定
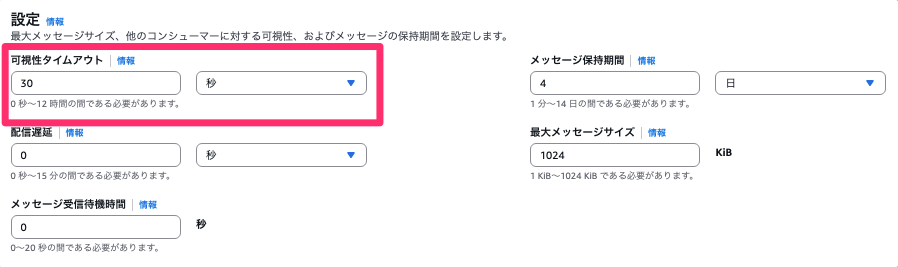
SQSには可視性タイムアウトというものがあります。
SQSには複数のメッセージが溜まっており、Lambdaなどのコンシューマー(処理する方)は定期的にSQSからメッセージを取得します。可視性タイムアウトとは、あるLambdaがあるメッセージAを処理している間に他のLambdaがメッセージAを処理してはいけないので、他のLambdaからは見えなくなる機能です。ここで設定した時間を超えるまでメッセージの処理が成功しなければメッセージは復活します。AWSの公式ドキュメントでは
キューの可視性タイムアウトを関数のタイムアウトの6倍以上に設定します。これにより、前のバッチの処理中に関数がスロットリングされた場合でも、Lambdaが再試行するのに十分な時間を確保できます。
と記載があるので、そのような設定が好ましいです。
AWS Lambda 関数をトリガーするための Amazon SQS キューの設定
DLQの作成
失敗したメッセージを保管する場所がDLQ(デッドレターキュー)です。これがないと失敗したメッセージが時間が経つと消えてしまうので必ず作成しましょう。
最大受信数の設定
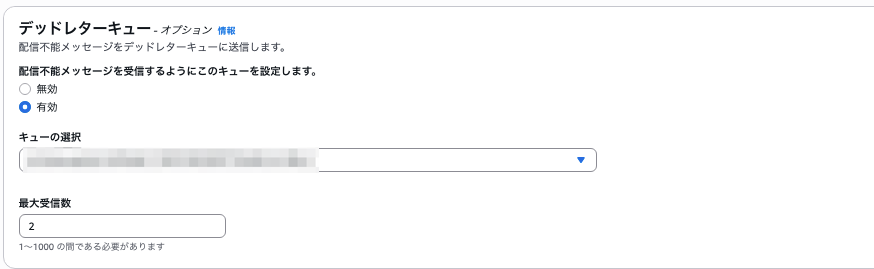
最大受信数というのは、何回まで処理の失敗を許容するかを設定した数値です。つまり画像のように2を設定している場合だと、2回そのメッセージの処理が失敗するとDLQに移動されるということになります。
保持期間と救出期限の設定
DLQもSQSなので保持期間は標準キューとFIFOキューともに14日が上限です。つまり、14日以内に原因分析して再処理する運用を設計しないと失敗したメッセージは消えてしまいます。もし長期で保管が必要な場合にはS3などに保管しましょう。
Lambdaで考慮すること
バッチサイズ
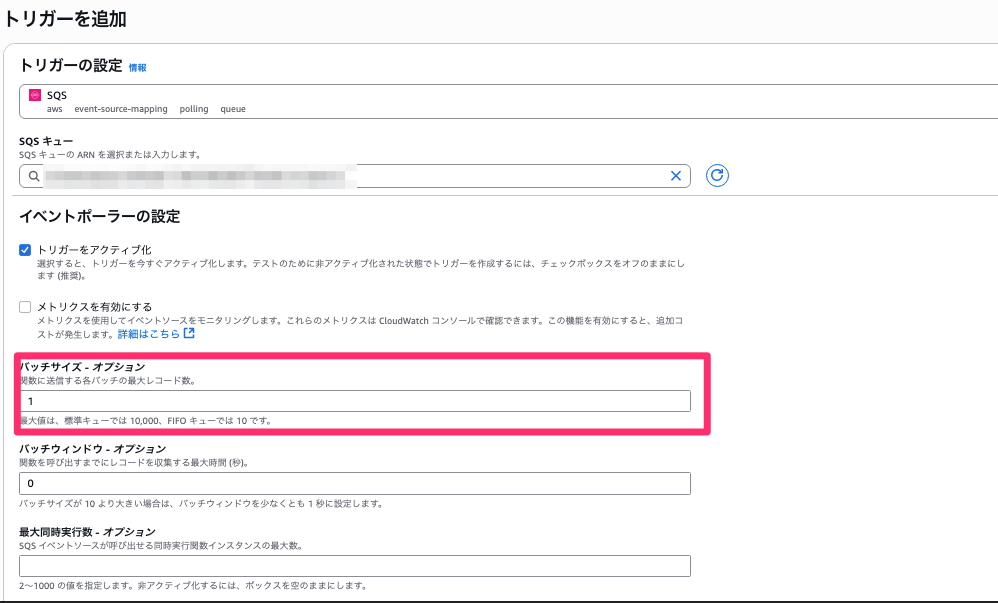
そもそもバッチとは何かという説明からします。LambdaがSQSからデータを取得する際には1つずつ取得するのではなくてまとめて取得します。これをバッチと呼びます。つまりバッチサイズというのはこの塊の大きさを示すものです。
小さい⇨起動回数が増えるのでコストは高くなります。
大きい⇨まとめて処理をするので、効率はいいのですがもし数件の中の1件でも処理が失敗してしまうと全ての処理がやり直しになってしまうのでそのリスクがあります。
そのため、冪等性を意識した設計をとっていないとデータの整合性が取れなくなるので冪等性はマストで意識しましょう。ただ、失敗したレコードだけを再実行する方法もあるようで、部分的なバッチレスポンスの実装には記載があります。
バッチウィンドウ
バッチウィンドウとは、関数を呼び出すまでにレコードを収集する最大時間 (秒)であり、これを長めに設定することで「メッセージが1件しか来てないのに即実行」みたいな非効率を減らすことができます。
予約済み同時実行数
最後に予約済み同時実行数です。これは同時に起動できるLambdaの数を指定できます。もしいきなりリクエストが増えて、SQSにメッセージが溜まった時にこの値を1000台と設定していると一気にLambdaが1000台立ちあがって、コストが増大してしまったり、Lambdaは1000台立ちあがって全ての処理を捌けるが、DBや外部連携先のシステムが耐えられないといった可能性もあるので、スケールした場合にどれくらいまで耐えれるのかから逆算してこの値を設定しましょう。
参考資料
Amazon Simple Queue Serviceとは?
SQS + Lambda という非同期処理黄金パターン再入門 | AWS Dev Day 2022 Japan
落とし穴にハマるな!AWS Lambdaを利用するときの6つの注意点