前置き
前回からの話の続きになります。
今回は、メッセージリレーの話を深ぼっていきます。
メッセージリレーの実装
イベントストアとアウトボックスへのアトミックな書き込みが完了した後、下図のように、
そのメッセージはメッセージリレーと呼ばれる専用のプロセスを経由して、メッセージブローカーに送られます。
このリレーの実装には、主に以下の2つのパターンがあります。
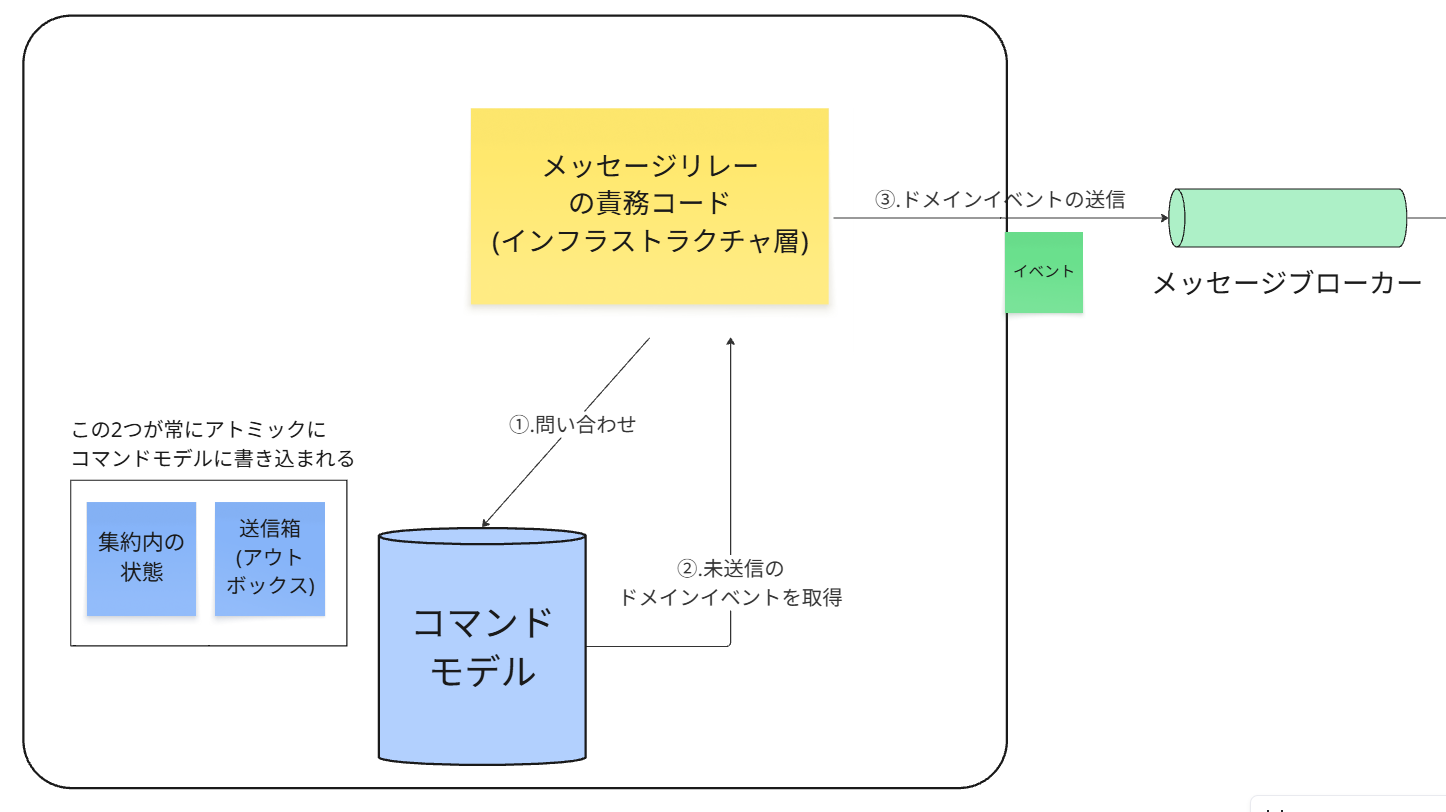
パターン1:ポーリング・パブリッシャー
これは、各サービス内にメッセージリレーの責務を実装する 最もシンプルで一般的な方法です。
メカニズム
アプリケーションとは別のプロセスやスレッド(メッセージリレー)が、データベースのoutboxテーブルを定期的にポーリング(問い合わせ) します。
経路の詳細
①. メッセージリレーが、outboxテーブルに対して
「まだ処理されていないメッセージ(例: status = 'UNPROCESSED')をください」という
クエリを定期的に実行します。
②. 未処理のメッセージを見つけると、その内容をメッセージブローカーに発行します。
③. メッセージブローカーから正常な応答を受け取ると、リレーはoutboxテーブルに戻り、
そのメッセージのステータスを'PROCESSED'に更新するか、レコードを削除します。
実装
各マイクロサービスの内部に、バックグラウンドで動作するスレッドやワーカーとして、メッセージリレーのロジックが組み込まれます。
アプリケーション本体と同じプロセスとして、あるいは同じPod内の別のコンテナとしてデプロイされます。
✅メリット
データベースの種類を選ばず、実装が比較的容易です。
・自律性
サービスは、外部のリレーサービスに依存せず、自身のメッセージを自身で発行できます。
・疎結合
サービスとそのアウトボックスは、完全に自己完結しています。
❌デメリット
・遅延とDB負荷
ポーリングによるわずかな遅延が発生し、データベースに常に小さな負荷がかかります。
・自前実装の必要性
各サービスに同じようなリレーのロジックを実装する必要がある。
(ただし、これは共通ライブラリ化することで解決可能)
パターン2:トランザクションログ・テイリング
これは、メッセージリレーの責務を CDCプラットフォームとして分離する より高度で低遅延な方法です。
メカニズム
DebeziumのようなCDC(Change Data Capture) ツールが、データベースのトランザクションログ(例: PostgreSQLのWAL)を直接監視(テイリング)します。
経路の詳細
①. アプリケーションがoutboxテーブルに新しいメッセージを書き込み、トランザクションがコミットされます。
②. CDCツールは、データベースのトランザクションログへの書き込みを即座に検知します。
③. CDCツールは、そのログの内容を解析し、メッセージブローカー(特にKafkaと相性が良いそう)に対してイベントとして発行します。
実装
メッセージリレーの責務は、DebeziumのようなCDCプラットフォームという、外部の共有インフラが担います。
各マイクロサービスは、このプラットフォームに自身のデータベースを監視するように設定するだけです。
✅メリット
・アプリケーションからの完全な分離
アプリケーションは、メッセージングについて一切関知する必要がなく、自身のDBに書き込むだけで済みます。
・高性能
ポーリングが不要なため、ほぼリアルタイムでメッセージを転送でき、データベースへの負荷もありません。そのため、非常に低遅延なデータ連携が可能です。
❌デメリット
データベースがトランザクションログのストリーミングに対応している必要があり、
CDCツールの導入・運用という専門的で複雑なインフラを別途構築・運用する別の複雑さが生じます。
結論
「メッセージリレーの責務は誰が持つか」 という問いに対しては、
・ポーリング方式なら:各マイクロサービス自身が持つ。
・CDC方式なら:外部の共有プラットフォームが持つ。
という答えになります。
どちらのアプローチでも、アプリケーションのビジネスロジックとメッセージ転送という技術的関心事が分離されていることが重要です。
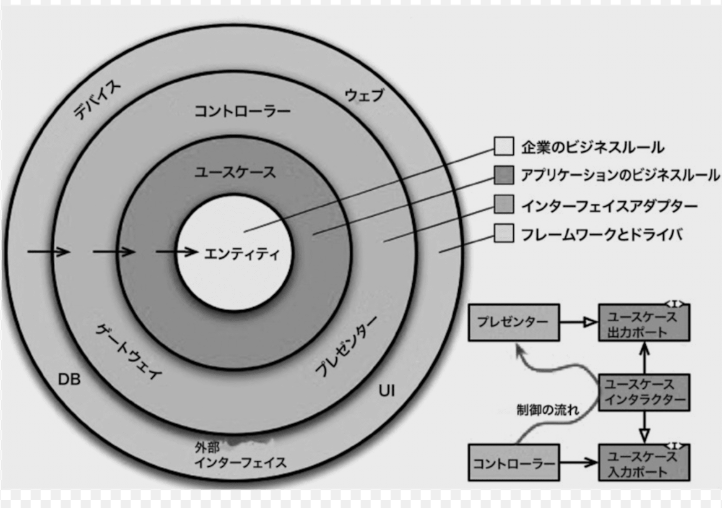
クリーンアーキテクチャとの関係
上記の関心を分けたい という設計思想は、はクリーンアーキテクチャの核心です。
また、上記のメッセージリレーの配置場所は、インフラストラクチャ層がより適切です。
なぜインフラストラクチャ層なのか
クリーンアーキテクチャの最も重要なルールは 「依存性のルール」 です。
内側の円(エンティティ、ユースケース)は、外側の円(インフラ)について何も知ってはいけません。
データベースのoutboxテーブルをポーリングし、メッセージを 特定のメッセージブローカー(Kafkaなど) に発行する。
これが、メッセージリレーの責務です。
この処理は、特定の技術(特定のDB製品、特定のメッセージブローカー製品)に強く依存しています。なので、まさしくインフラストラクチャ層が担うべき責務です。
アプリ層に配置してしまうと、、、
もし、メッセージリレーをアプリケーション層に配置すると、アプリケーション層がKafkaのクライアントライブラリやDBのポーリングといった具体的なインフラ技術に依存してしまい、クリーンアーキテクチャの依存の向きのルールを破ってしまいます。
クリーンアーキテクチャにおける正しい役割分担
アプリケーション層 (ユースケース層) の責務
・ビジネスロジックを実行します。
・その結果として外部に通知すべきイベントが発生したら、「イベントをアウトボックスに保存する」という指示を出します。
・この指示は、インフラ層が実装するリポジトリのインターフェースを通じて行われます。
アプリケーション層は、その保存先がPostgreSQLなのか、実際にどうやって送信されるのかを知りません。
インフラストラクチャ層の責務
・アプリケーション層から指示されたイベントを、outboxテーブルに永続化する具体的な実装を提供します(リポジトリの実装)。
・そして、メッセージリレーをバックグラウンドプロセスとして実行し、outboxテーブルからイベントを取り出し、具体的なメッセージブローカーに送信します。
このように、
アプリケーション層は「何を通知したいか」を決定
インフラストラクチャ層のメッセージリレーが「どうやって通知するか」
を実現します。これにより、ビジネスロジックとメッセージ転送という技術的な関心事が明確に分離できます。
購読側のコンシューマー
さて、ではドメインイベントのメッセージの購読側(受信側)は、どのような流れでアプリケーションロジックを実行していくのでしょうか?
多くの場合、コンシューマーはメッセージブローカーを能動的に問い合わせる(ポーリングする)のではなく、ブローカーからイベントをプッシュで受け取るか、ロングポーリングで待機します。
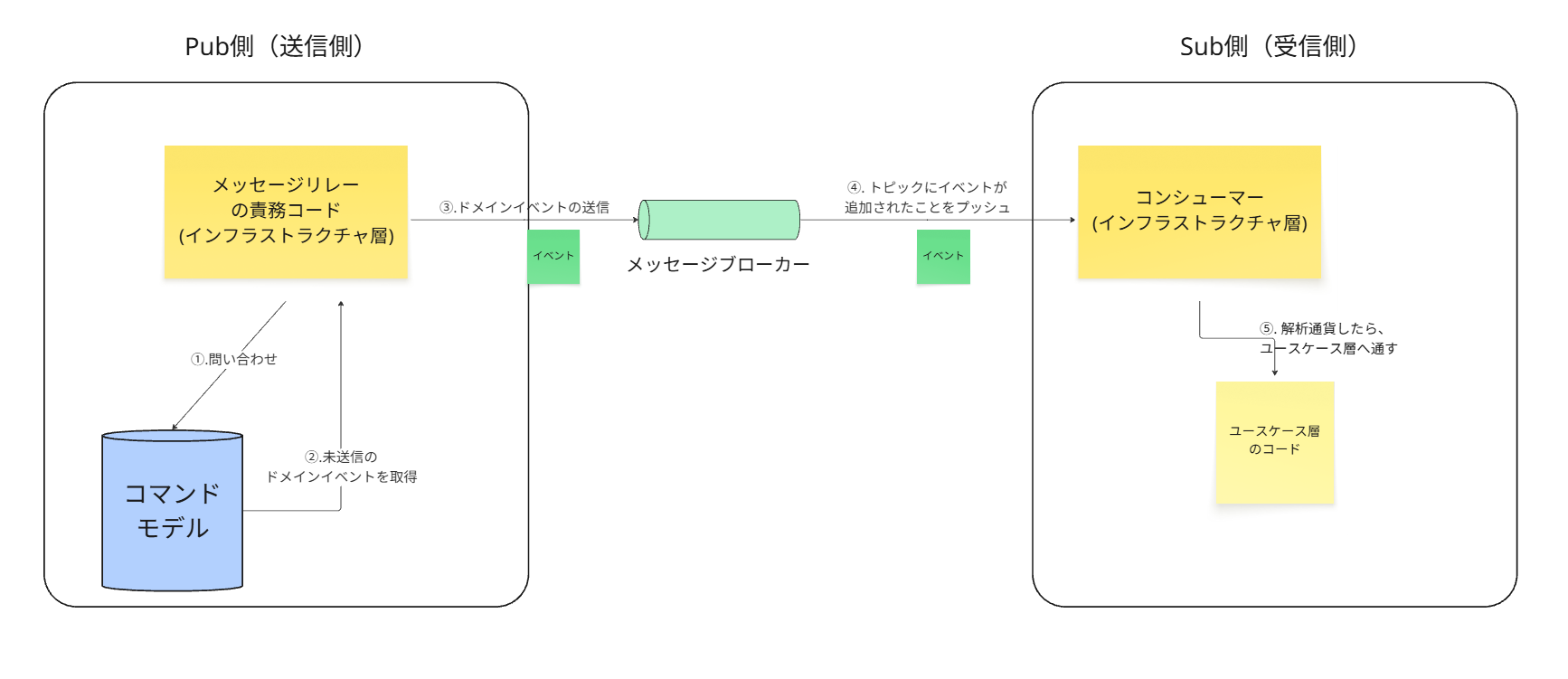
コンシューマーの役割と仕組み
コンシューマーは、購読側マイクロサービスの内部に存在する部品です。
こいつの役割は、外部のメッセージブローカーと接続し、メッセージを受け取って、アプリケーション内部の処理を開始させることです。
クリーンアーキテクチャにおける配置
このコンシューマーは、外部の技術(メッセージブローカー)と直接対話するため、インフラストラクチャ層に配置されます。
処理の流れ
①. メッセージブローカーが、購読しているトピックに新しいイベントが到着したことをコンシューマーに通知(プッシュ)します。
②. インフラストラクチャ層にいるコンシューマーは、そのメッセージを受け取り、データを解析します。
③. コンシューマーは、解析したデータを使って、ユースケース層の適切なビジネスロジックを呼び出します。
ネットワークレイテンシー
メッセージブローカーとコンシューマーの間にはネットワーク通信が存在するため、
必ずレイテンシー(遅延)が発生します。
この遅延は、主に以下の要素で構成されます。
ネットワーク遅延
ブローカーのサーバーから、コンシューマーが稼働するサーバーまで、データが物理的に移動する時間。同じデータセンター内であれば非常に短いですが、ゼロではありません。
ブローカーの処理時間
ブローカーがメッセージを受け取り、どのコンシューマーに配信すべきかを判断し、配信キューに入れるまでの時間。
コンシューマーの処理時間
コンシューマーのクライアントライブラリがメッセージを受け取り、アプリケーションのイベントハンドラーに渡すまでの時間。
なぜこのレイテンシーが許容されるのか
このアーキテクチャは、このレイテンシーが存在することを前提に設計されています。
非同期・コレオグラフィ型の設計の目的は、サービス間を時間的に疎結合にすることです。
つまり、「イベントの発行」と「イベントの処理」が、即座に行われる必要がないビジネスプロセスに適用されます。
事例
注文サービスがOrderPlacedイベントを発行してから、通知サービスがそれを受け取って確認メールを送信するまでに、数百ミリ秒〜数秒の遅延があったとしても、ビジネス上は全く問題ありません。
この許容できる遅延(レイテンシー)と引き換えに、システムは耐障害性(通知サービスがダウンしても注文サービスは影響を受けない)とスケーラビリティという、より大きなメリットを得ているのです。
まとめ
このように、発行側のメッセージリレーが「アウトボックス→ブローカー」という出口の役割を担うのに対し、購読側のコンシューマーは「ブローカー→ユースケース」という入り口の役割を担います。
セキュリティ観点での補足事項
クリーンアーキテクチャの同心円的に言うと、
各種マイクロサービス量子の内側のユースケース層やドメインロジック部分が汚染されないように、
受信側のサービスは、
「コンシューマーというインフラ層でメッセージを受け取り、データを解析する」
という部分で、適応度関数を用いて、データが事前に許可されたものなのか?などのチェックをした上で、そのチェックを通過したもののみユースケース層に通す
というロジックを満たす必要があります。
なぜそのロジックが正しいのか
クリーンアーキテクチャの核心は、内側のドメイン層やユースケース層を、外側の技術的な詳細から守ることにあります。
つまり、外部から入ってくるデータは、本質的に信頼できない(Untrusted) ものであり、
それを無防備にビジネスロジックの中心に通すのは極めて危険です。
1. インフラストラクチャ層の「国境検問所」としての役割
インフラストラクチャ層にいるコンシューマーは、マイクロサービスのいわば、
「国境検問所」 のような役割を担います。
責務
外部(メッセージブローカー)から来る全てのデータ(人や物)を検査し、
安全で、かつ正当なもの
であることを確認する。
2. 適応度関数による厳格な検査
この「検査」こそが、ご指摘の適応度関数です。
特に、コントラクトが緩いときなどに、マストになってくるものです。
具体的には、以下のようなチェックを行います。
スキーマ検証
データは、事前に定義された契約(スキーマ)通りの構造か?(例: Avro, JSON Schema)
データ妥当性検証
order_idはUUID形式か? amountは正の整数か?
認可チェック
このイベントを発行したサービスに、この操作を実行する権限があるか?
(例: JWTの署名やクレームの検証)
不正な値のフィルタリング
SQLインジェクションやクロスサイトスクリプティングに繋がりうる危険な文字列が含まれていないか?
3. クリーンなデータのみを内側へ
この厳格な検査を通過した、安全でクリーンなデータのみが、次の層である、アプリケーション層(ユースケース層)が理解できる、純粋なデータ構造(DTO: Data Transfer Objectなど)に変換されて渡されます。
この設計により、ユースケース層とドメイン層は、常にクリーンで信頼できるデータが渡されることを前提に、自身のビジネスロジックに集中できます。
これにより、コードはシンプルになり、テストも容易になり、そして何よりシステム全体のセキュリティが劇的に向上します。