同期通信ベースのマイクロサービス
おとぎ話サーガのような、同期通信ベースのマイクロサービスでは、
アプリケーション層は高度に分離するものの、インフラチームが中央集権なプラットフォームチームとして機能する。
図を描いてしまってから気づいたんですが、
今回の記事の「オーケストレーションサーガ」となっている黄緑付箋の名前は、
すべて【オーケストレーター(指揮者)】と名前を修正して読んでください💦
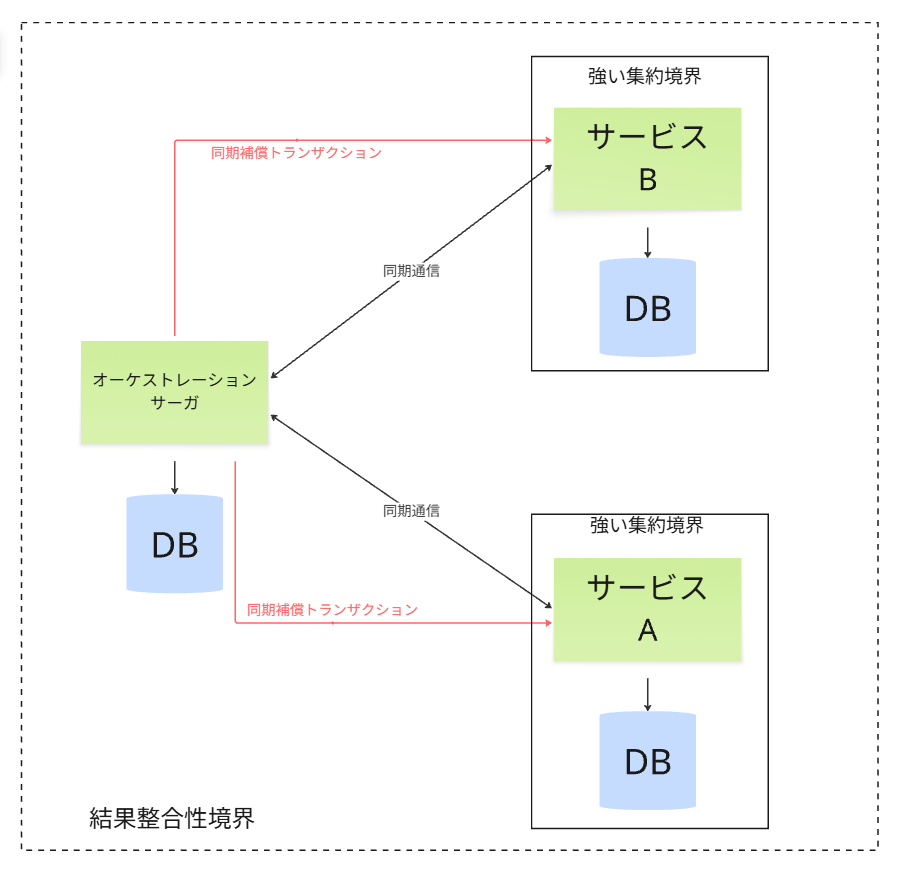
同期かつ結果整合のマイクロサービス模式図
模式図で表現すると、以下のような感じです。
上物の黄緑のアプリケーション層では、それぞれが高度に分離され、
アプリケーションの層では、たしかに単独でデプロイ可能な状態です。
しかしながら、同期通信である以上、
インフラ部分では蜜結合状態のため、インフラまで含めて単独でデプロイ可能
とは言えない状態です。
この状態では、サービスプロダクトを担当する各アプリチーム同士のコミュニケーション
構造は疎結合ではあるものの、
インフラチーム内のコミュニケーションは密な状態が求められます。
インフラチームのモノリス構造
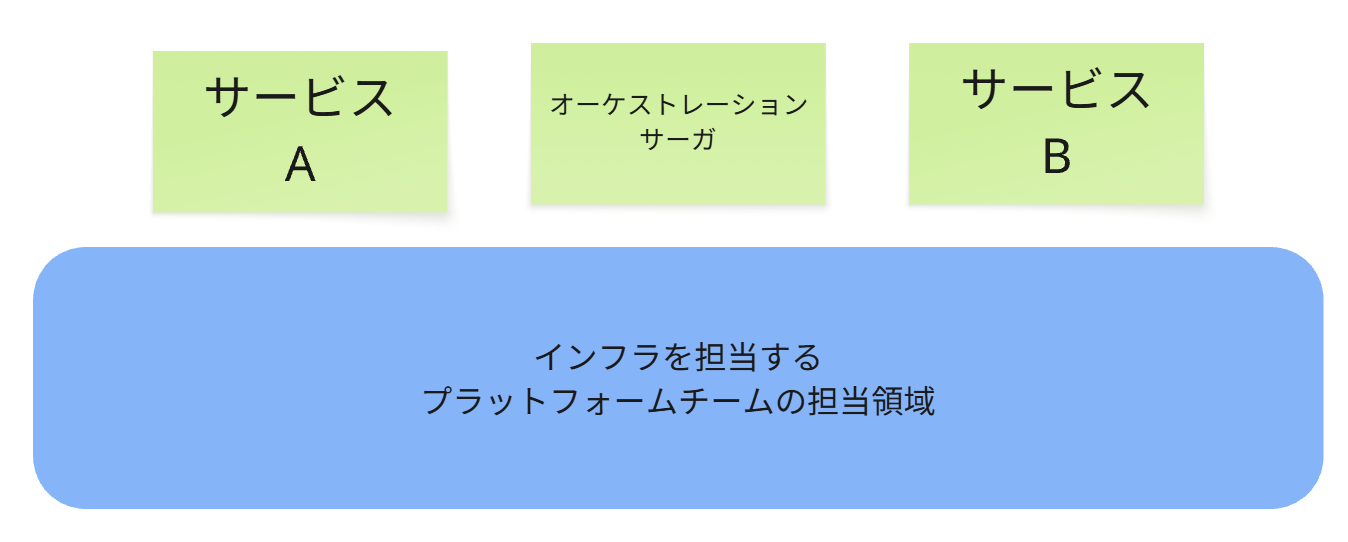
同期通信と「プラットフォーム・モノリス」
上記のような、同期通信ベースのマイクロサービスアーキテクチャでは、アプリケーションチームは疎結合に見えても、それを支えるプラットフォームチームは事実上の「モノリス」として振る舞わざるを得ません。
これはアーキテクチャ上、仕方のない負債です。
技術的な理由
APIゲートウェイ、サービスディスカバリ、中央集権的なロードバランサなど、同期通信を支えるコンポーネントは本質的に密結合です。
APIゲートウェイの設定変更は、多くのサービスに影響を与える可能性があり、サービスディスカバリの障害は図の3つのサービス全体に波及します。
組織的な結果
この技術的な密結合が、プラットフォームチーム内に密なコミュニケーションを強制します。
コンウェイによって、プラットフォームチームがモノリスなコミュニケーションパスを強制される。
「ゲートウェイ担当」と「サービスディスカバリ担当」と「ネットワーク担当」は、
常に同期を取りながら密なコミュニケーションをしながら作業を進める必要があり、
チーム全体が一つの脳のように動くことを要求されます。
非同期化とプラットフォームチームの「マイクロサービス化」
次に、仮説の第二、第三段階です。
アーキテクチャが非同期(イベント駆動)へと進化するにつれて、プラットフォームが提供すべき機能も疎結合化していきます。
模式図で言うと以下のような感じです。
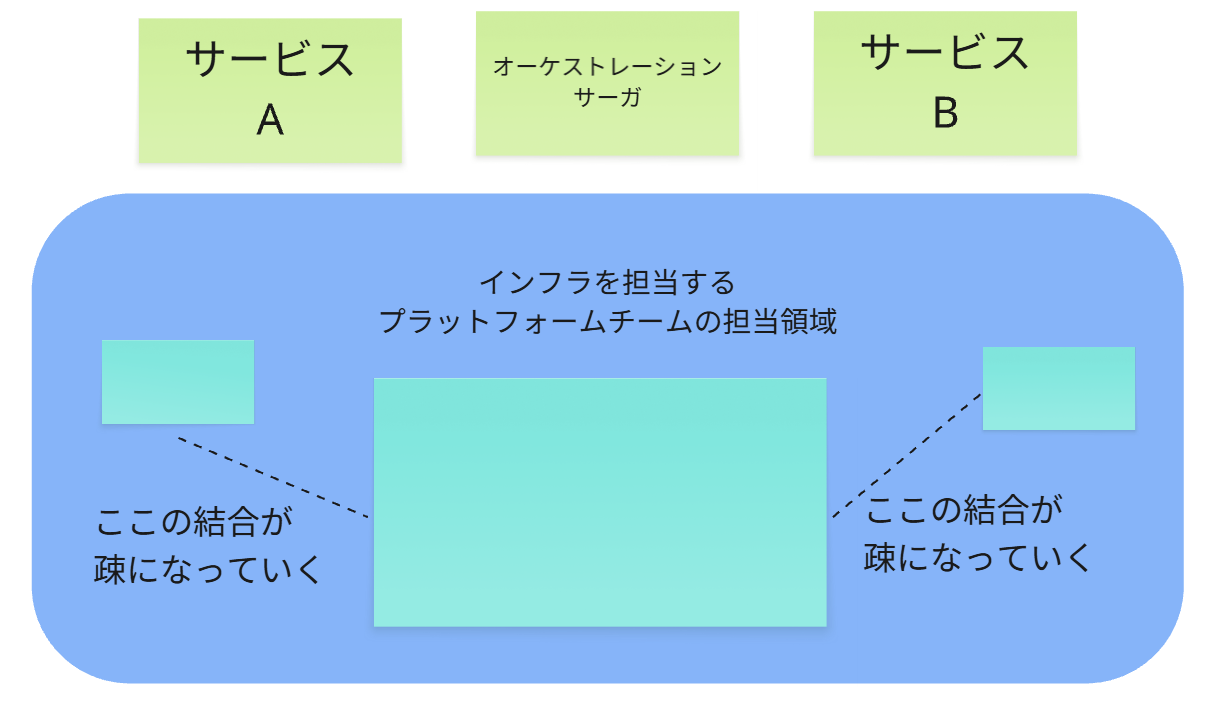
マイクロサービスの切り分け同様に、疎な連携部分を見つけ、徐々に小さく分割できるようにしていきます。
技術的な変化
中央のAPIゲートウェイの重要性が低下し、代わりにイベントバス(例: Kafka)やスキーマレジストリといった非同期メッセージング基盤が中心になります。
組織的な変化
この変化に伴い、プラットフォームチーム内も
専門領域ごとに疎結合なチームへと「マイクロサービス化」
されていきます。
「メッセージング基盤チーム」「コンテナ基盤(K8s)チーム」「オブザーバビリティチーム」といった形で、関心事が分離していきます。
チームへの吸収
さらに成熟が進むと、プラットフォームチームの役割は「管理」から「イネーブルメント」へと変化します。(サービスメッシュ担当者)
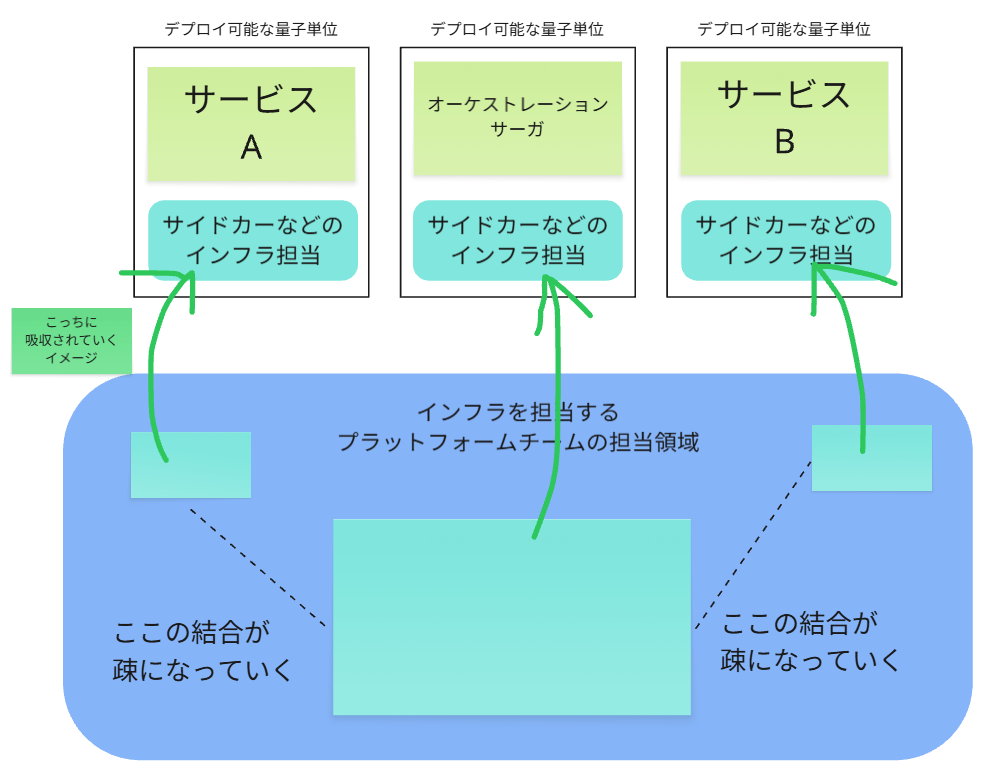
彼らが提供する基盤(サイドカーの設定など)を、プロダクトチームがセルフサービスで利用できるように整備し、その運用の一部をプロダクトチームに分散委譲していきます。
これは、上図のようにプラットフォームの機能が、サービス内のインフラ領域に吸収されるかのような動きに見えます。
これがダイナミックリチーミングそのものではないでしょうか?
で、最終的に以下のようになります。
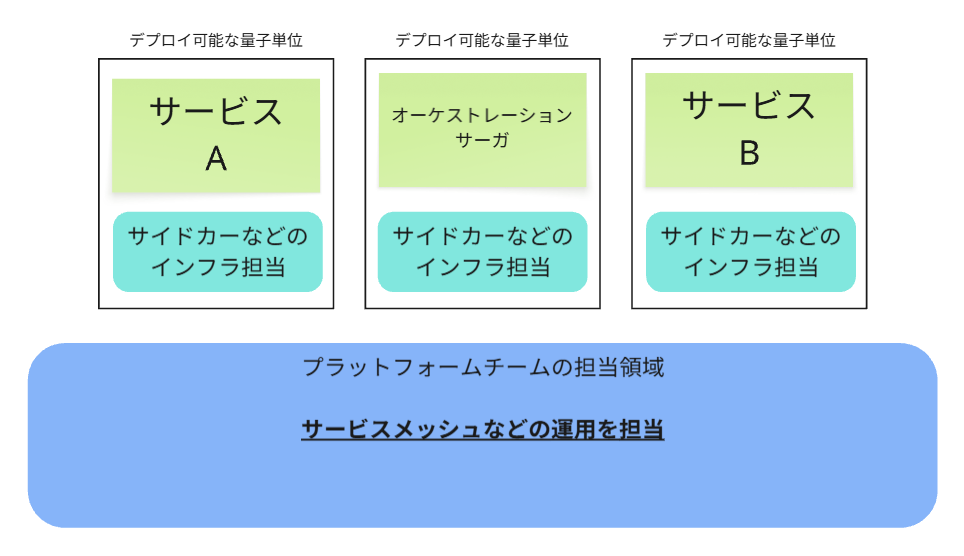
この状態が、非同期かつ結果整合な 単独でデプロイ可能な量子単位となった
マイクロサービスである、パラレルサーガ 状態と言えます。
コミュニケーションパスの可視化による分割点の発見
では、プラットフォームチームの
どの部分を、いつ、どのように分割・非同期化すればよいのか?
その問いに対する最も私が自信を持って言える答えは、
「チームのコミュニケーション構造をデータで観測すること」
にあります。
自信を持って分割点を特定するためには、以下のような定量的・定性的なデータを組み合わせるアプローチが不可欠だと思います。
✅ オブザーバビリティツールのデータ
相関性
特定のインシデント発生時に、プラットフォームのどのコンポーネントのメトリクスが常に同時に異常値を示すでしょうか?
例えば、ゲートウェイと認証サービスが常に同時にダウンするなら、それらは密結合しているといえるので、分離すべきではないはずです。
依存関係
分散トレーシングの結果、どのプラットフォームサービスが他のどのサービスを同期的に呼び出していますか?
💬 コミュニケーションツールのメトリクス
交流の可視化
Slack/Teamsなどのコミュニケーションツールのログなどをみて、
どのエンジニア同士が、どのチャンネルで頻繁にコミュニケーションを取っているのか?
ソーシャルネットワーク分析ツールでこれを可視化すると、チーム内に存在する
事実上の「派閥境界」や「ドメイン境界」
が浮かび上がってきます。
密に連携しているグループは、同じ関心事を持つ分割候補です。
🛠️ CI/CDのデータ
変更の追跡
プラットフォームのある部分(例: ネットワークポリシー)への変更が、他の部分(例: サービスメッシュ設定)の変更を常に誘発していたりはしないでしょうか?
同時に変更されることが多いコードは、分割すべきではないという強いシグナルです。
これは、コンポーネントの凝集原則の考えと同じです。
ここまでの結論
これらのデータを多角的に分析することで、
「我々は組織図上は単一チームだが、データを見る限り、実態は疎結合な2つのチームとして動いている。
ならば、正式にチームを分割し、それぞれが責任を持つコンポーネントも非同期化しよう」
という、データに基づいた意思決定が可能になるのです。
これは、組織構造がシステム設計を規定するという「コンウェイの法則」を意識的に利用し、望ましいアーキテクチャを導くために、まず組織とコミュニケーションのあり方から変革していく戦略です。
境界考察の注意点
ただし、この際に注意点があります。
メカニズム自体は、ドメイン駆動のコンテキスト境界の考察と一緒です。
「コミュニケーションパスの可視化による分割点の発見」というものも、置かれた状況というコンテキストとセット です。
あるシーンでのみのデータから得られた傾向としての
【プラットフォームチーム内の連携が疎な部分】
という「インフラにおけるコンテキスト境界」が見つかっても、
ビジネスインパクトの大きなかつ発生頻度も未知数な災害に対しては、常に他のコンテキストと密な連携が求められる
といった場合には、あえてその境界で区切らないという決断を私ならします。
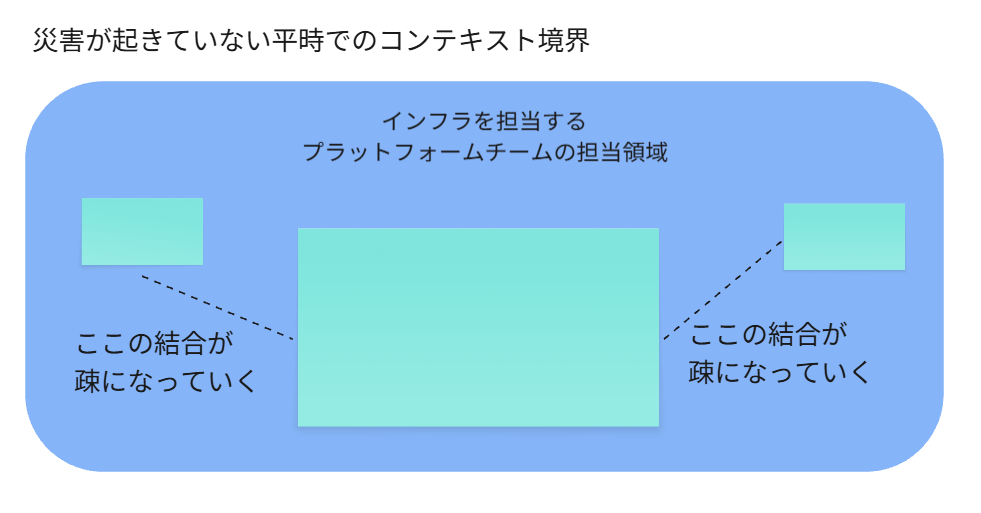
平時と有事での比較図
平時でのコンテキスト境界
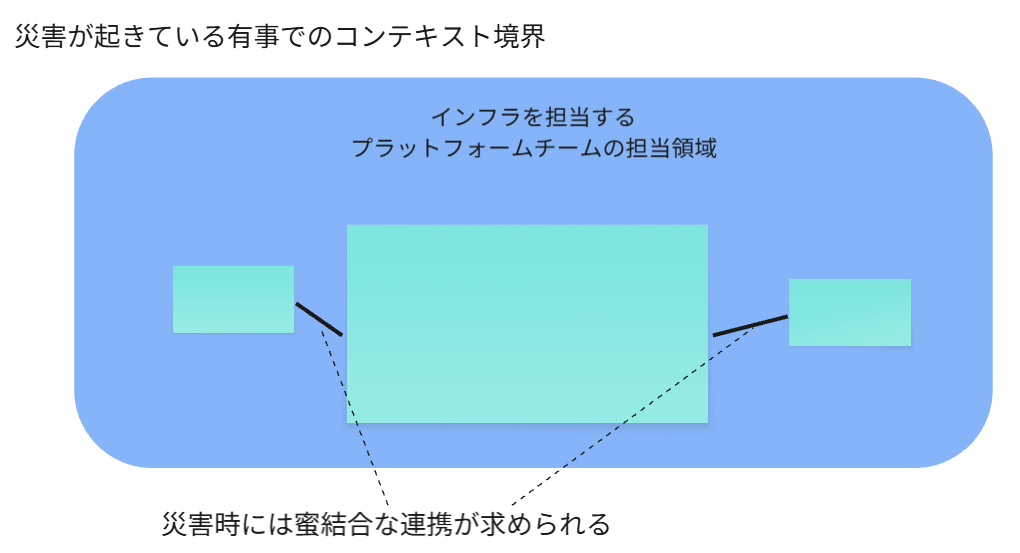
有事でのコンテキスト境界
平時と有事でのトレードオフ
上記の各ツールの提供するデータドリブンな意思決定の罠に陥らず、
システムの挙動を時間軸とインパクトの大きさで捉え、リスクベースで判断しましょう。
「あえて疎な境界で区切らない」という決断は、
「平常時の効率性」と「非常時の回復力(レジリエンス)」
を天秤にかけた判断です。
順に詳細に考えていきましょう。
「平常時」のデータ vs 「非常時」の要求
まず、それぞれの状況を整理します。
観測されたデータ(平常時)
・プラットフォームチーム内のAチーム(例: コンテナ基盤担当)とBチーム(例: メッセージング基盤担当)の日々のコミュニケーションは疎であるとします。
・彼らが担当するコンポーネントも、日常的な運用では独立して変更・デプロイされている。
・データ上の結論としても、AとBは分割可能であり、分割すれば平常時の認知負荷は下がり、作業効率は上がるでしょう。
想定されるシナリオ(非常時)
・大規模なクラウドリージョン障害や、深刻なゼロデイ攻撃が発生。
・原因究明と復旧のためには、コンテナの挙動とメッセージングの両方の深い知識をリアルタイムで突き合わせ、一体となって対処する必要がある。
・ここで仮にチームが分割されていると、所有権の押し付け合い、コンテキスト共有の遅延、意思決定の遅れが発生し、結果としてマイナスの事業インパクトが拡大する。
・さらに、この有事災害は、起きる頻度が予測不能であるとします。
わたしなりの決断
この対立構造において、わたしは「非常時の回復力」を優先し、
あえて、下図の点線部分でコンテキスト境界を定義しない
という決断をします。
これは、レジリエンスエンジニアリングの観点から見て、その境界位置の効果のデメリットの方が大きいと判断するからです。
その決断の正当性を支える3つの理由
1. 共有されたメンタルモデルの維持
非常時において最も重要なのは「対応速度」です。
チームが1つに統合されていると、プラットフォーム全体に対する共通の理解が醸成されます。
災害発生時に、コンテナ担当が「メッセージング側で何が起きているか」を、メッセージング担当が「コンテナ側の制約は何か」を即座に推測できます。
この暗黙知が、分秒を争う状況でのコミュニケーションコストを劇的に削減します。
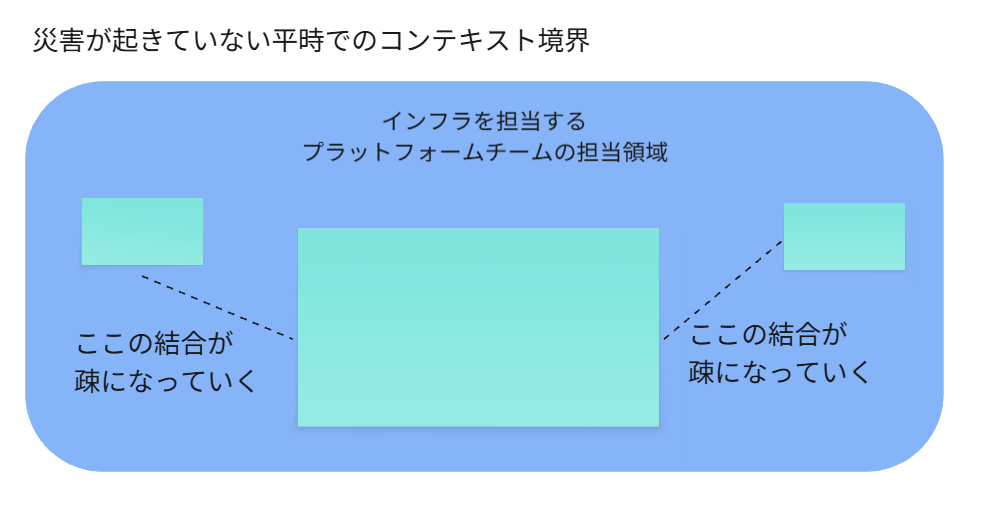
かりにこれが、下図のように非常時でも分離されていると、
3つのチーム間で余計にコミュニケーションコストがかかり、当然対応速度は遅くなります。
非常時での分割がダメッて言ってるんではなく、
平時では疎でもいい部分が非常時では、蜜結合が求められる場所は本当に分離していいのか?? を批判的に考えてという意味です。
2. 認知負荷のパラドックス
チームを分割すると 「平常時の認知負荷」 は確かに下がります。
しかし、その代償として 「非常時の認知負荷」 は爆発的に増大します。
これが生死を分ける・事業継続性の明暗をわける
と言っても過言じゃないです。
普段連携していないチームと、非常時というプレッシャーの中で、ゼロからコンテキストを共有し、協調作業するなんて非常に困難です。
統合されたチームは、平常時の認知負荷は確かに高いかもしれませんが、非常時の対応能力と速度でそのコストを補って余りある価値を生みだしやすいです。
3. コマンド系統の統一
大規模な災害対応は、効果的な指揮命令系統が不可欠です。
チームが統合されていれば、意思決定者(インシデントコマンダー)は一つのチームに対して指示を出し、状況を集約できます。
チームが不必要に分割されていると、複数のチームリーダーからの断片的な情報を統合し、
競合する提案を調整したりする必要があり、足並みが乱れる原因になります。
では、どうバランスを取るか?
「仮想的な境界」と「訓練」
では、平常時の効率性も捨てたくない場合、どうすればよいでしょうか。
答えは、
「組織的には一体だが、運用上は疎結合に振る舞う」というハイブリッドな状態を目指し、それを「訓練」によって維持すること
です。
仮想的なコンテキスト境界
これは、一種のコンポーネントの境界などの認知しやすいシステム境界ではなく、
わたしたちの 認知の世界、メンタルモデルの境界 という表現が妥当です
チームとしては一体感を保ちつつも、日常業務では
「コンテナ担当」「メッセージング担当」のように
仮想的な専門領域(仮想コンテキスト境界)
を設けて、それぞれの領域の自律性を尊重します。
説明はだいぶ端折りますが、この仮想的コンテキスト境界こそが、
UAFでいうところの Operationalビューで考えるべき責任境界
すなわち、 「Operational Performer」 の単位となります。
定期的な合同訓練(ゲームデー)
このアプローチが機能するための鍵が「訓練」です。
定期的に大規模障害を模した
「カオス実験のためのゲームデー」や「DR(ディザスタリカバリ)訓練」
を実施します。
この訓練の時だけは、その仮想的な境界を取っ払い、全員が一体となって問題解決にあたります。
これにより、非常時の連携能力を錆びつかせることなく、共有されたメンタルモデルを維持・更新し続けるのです。
まとめ
長々とつづってきましたが、ようはプラットフォームチーム内でも、
さらにフラクタル構造で、以下のようにチートポするってことです。
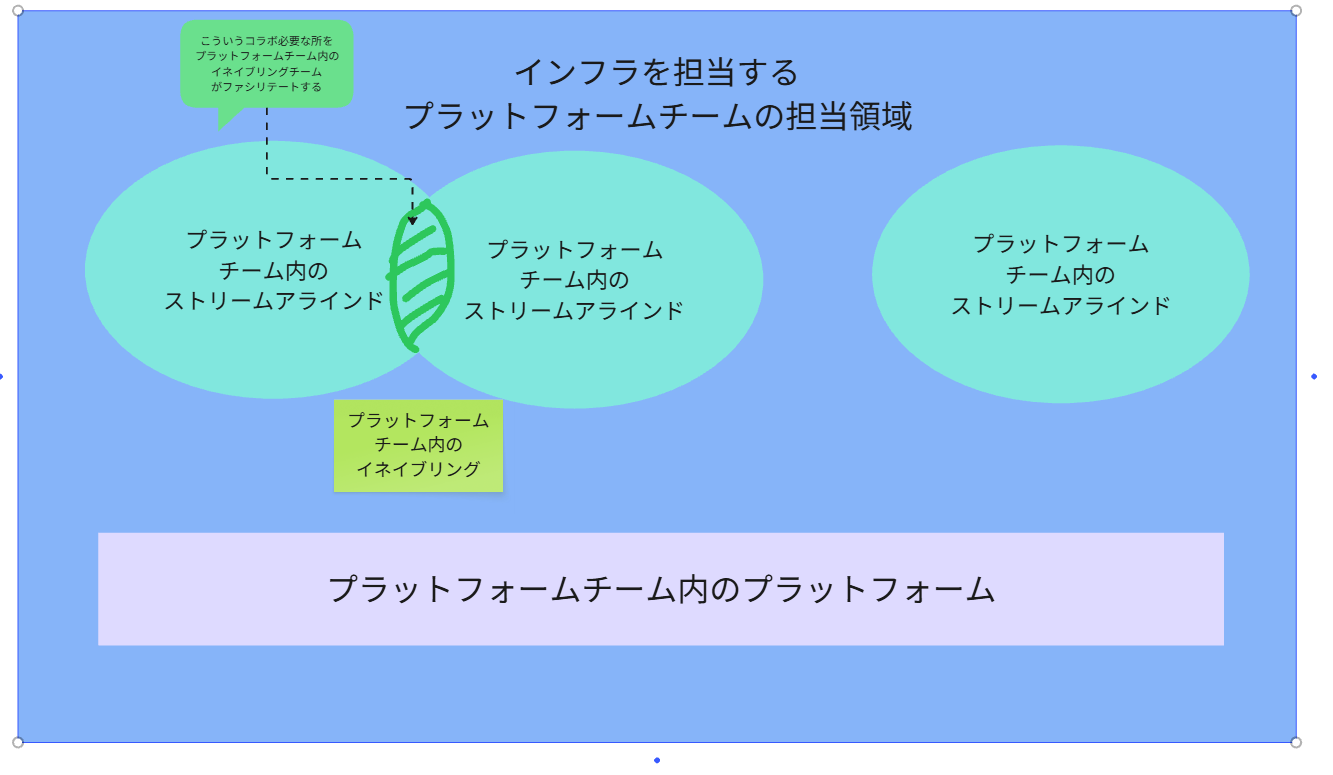
中央集権型から徐々にインフラ担当の人々も分散配置され、各サービスプロダクト内部に吸収されていきます。
これが、同期通信のマイクロサービスから非同期通信になった際のアーキテクチャおよび組織構造の変化です。
そして、平時と災害時の両方の境界位置をツールの提供するデータから読み解いて、
決して 特定の状況下でのみ効率的に機能する ようなコンテキスト境界で、
バシッと切らないでください。
仮想的な境界でのみ区切っておき、それをより具現化したサービス境界の層では、
一体となるようにふるまうという風に、
認知世界観での仮想境界と、論理空間での境界を分けて考えておく
という風にしてください。