前置き
アプリケーションアーキテクチャの方をマイクロサービスアーキテクチャにし、CI/CDパイプラインが、エンドツーエンドパイプラインモデルに成長したものの、
その後のETL系のデータパイプラインは、依然としてまだファンインパイプラインの構造である状態を想像してください。
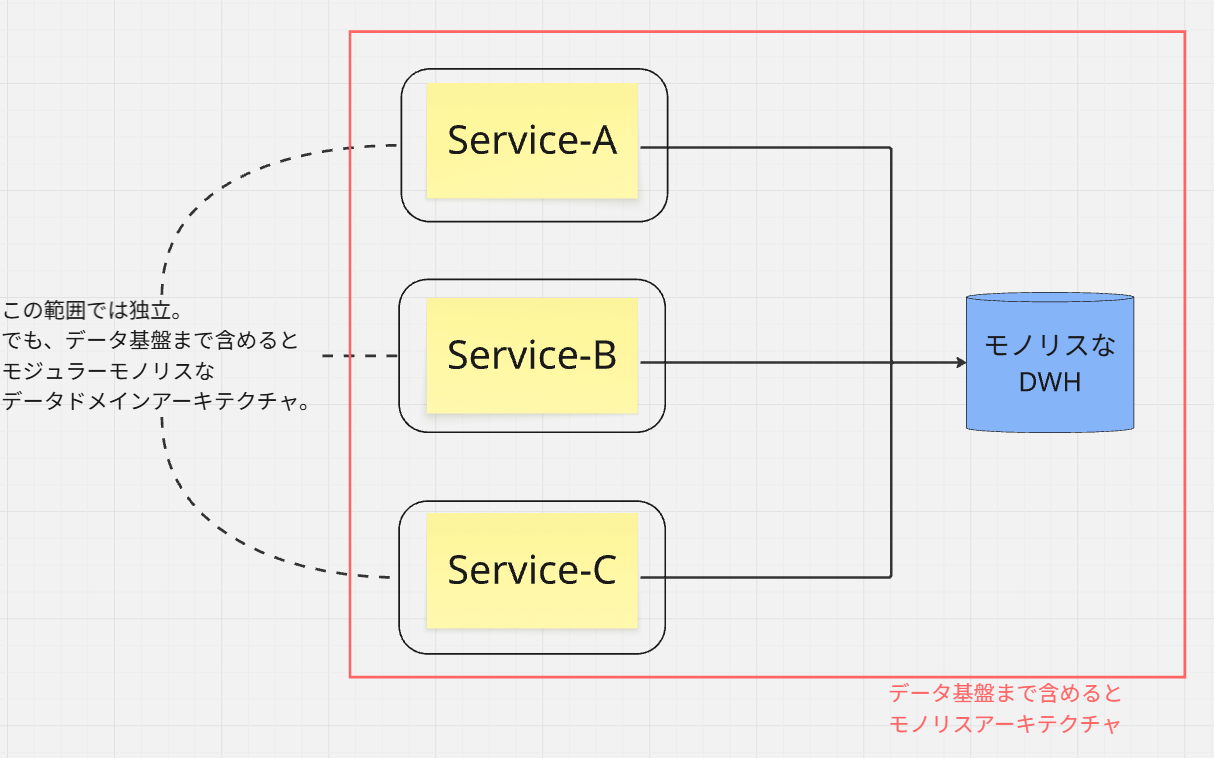
これは、データプロダクトの所有権をどのサービスに持たせるのか?などは、まだ未定義のフェーズです。
これはアプリケーションの進化(マイクロサービス化)とデータ基盤の進化(データメッシュ化)の 「歩調がズレている」 という、非常に現実でよくある、困難なシナリオです。
分散モノリス状態
アプリケーションのCI/CDはすでに独立した「エンドツーエンドパイプライン」になっているにもかかわらず、データパイプラインが依然として「ファンインパイプライン」(=中央集権的なETL)である状態は、データ層における「分散モノリス」 と呼べます。
この状態から、「ストラングラー・フィグ・パターン(絞め殺しのイチジク)」 を使って、
データパイプラインも「エンドツーエンド」に進化させる(=データメッシュ化する)ための段階的な移行プロセスを今回は扱っていきます。
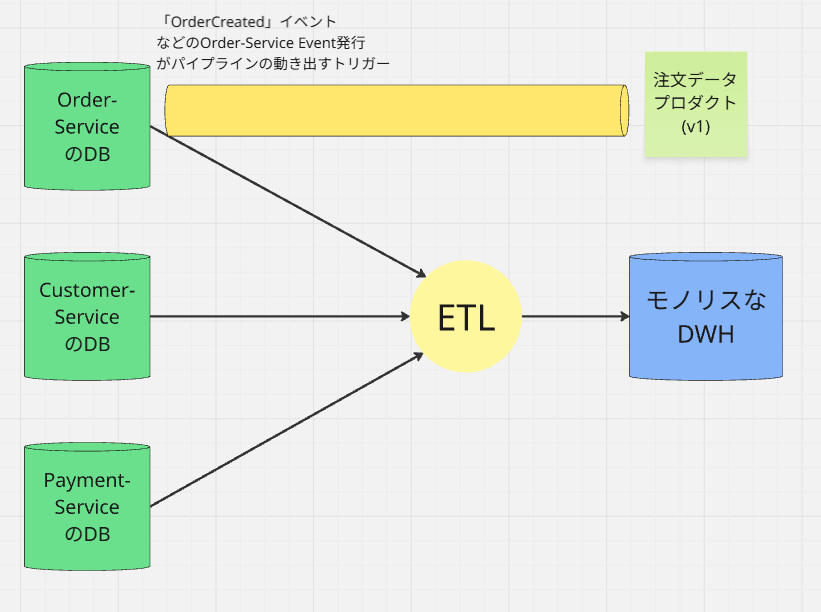
フェーズ1:現状(ファンイン・パイプライン / データ・モノリス)
下図の緑の枠で囲った所までが、アプリケーションのCI/CDパイプラインで、
そこから右側がETL系の処理を行うデータパイプラインという風に見なしてください。
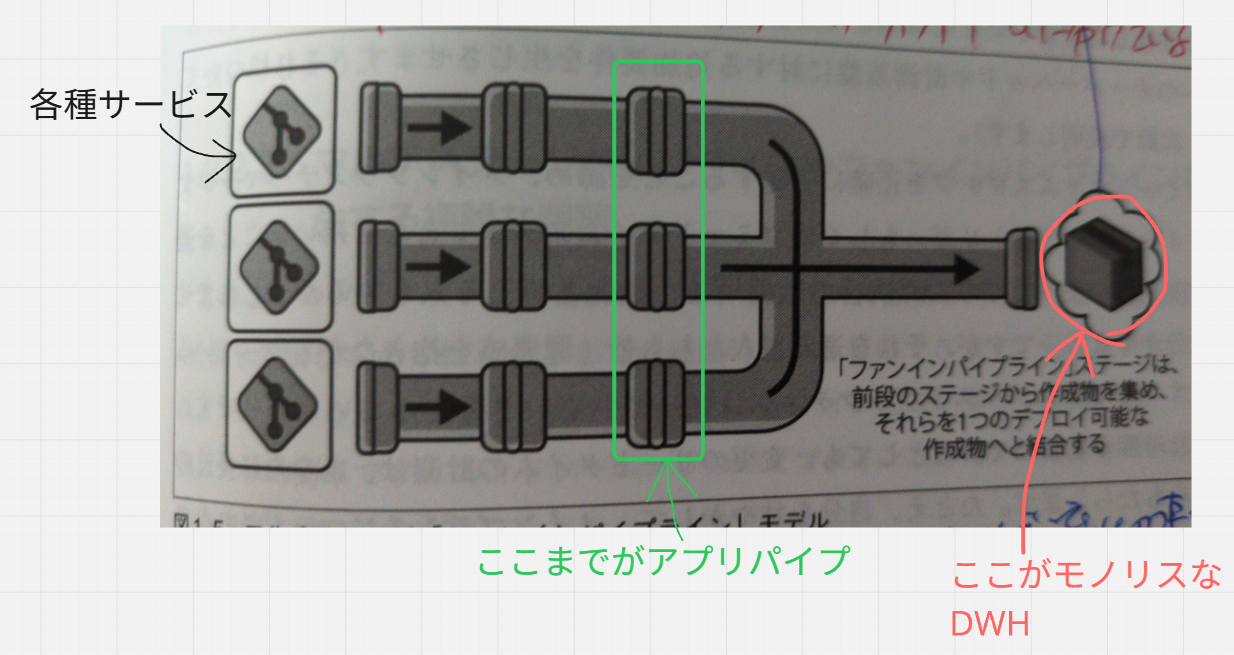
アプリケーションパイプラインの範囲では、各種サービスは、独立したCI/CDパイプラインの構造となっています。
アーキテクチャの構造
パイプラインの構造と対応付けられるように、アーキテクチャの図も貼っておきます。
アプリケーションパイプライン (E2E)
この区間では、それぞれは独立したパイプラインの構造です。
・Service-A → Deploy-A (独立)
・Service-B → Deploy-B (独立)
・Service-C → Deploy-C (独立)
データパイプライン (Fan-in)
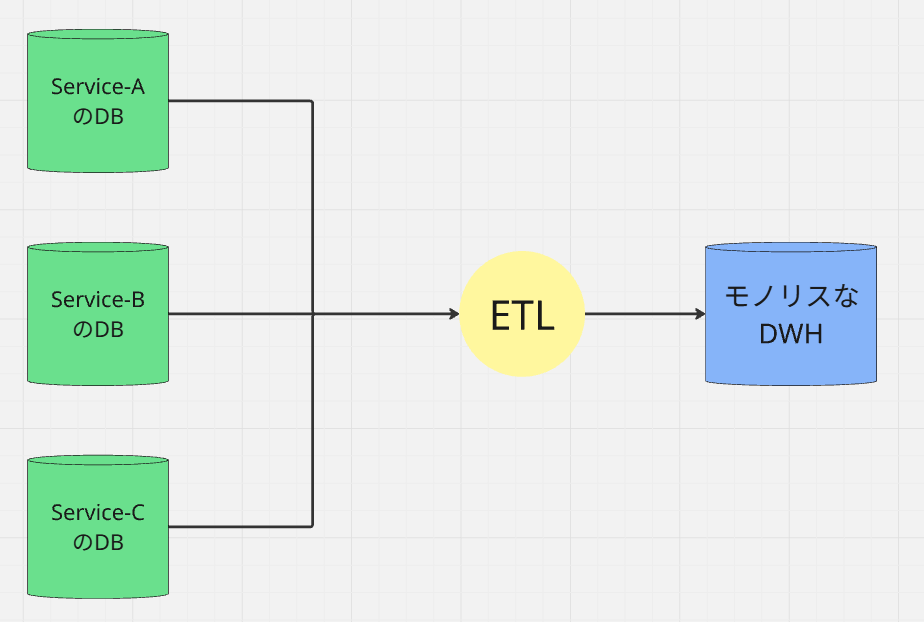
この構造では、Service-Aがアプリを10回デプロイしても、データ層ではCentral ETLという単一の巨大なプロセスに縛られています。
フェーズ2:移行期(ハイブリッド・パイプライン / ストラングラー・パターン)
ここで「徐々に変化させる」ための、最も重要なステップを踏みます。
既存のファンイン・パイプラインを直接修正するのではなく、新しい「E2Eデータパイプライン」を“横に”構築し、古いパイプラインの責務を一つずつ奪っていきます。
①. 最初の「データドメイン」を選定する
まず、最も価値のあるデータドメインを1つ選びます(例:「注文(Order)ドメイン」)。
この選定の仕方は、DDDのコアドメインの選定と同じメカニズムです。
②. 最初の「E2Eデータパイプライン」を構築する
「注文」ドメイン専用の、完全に独立した新しいデータパイプラインを構築します。
これは、アプリケーションのE2Eパイプラインと考え方は同じです。
トリガー
Order-ServiceのDBで変更(CDC)があったら、
または Order-Serviceが「OrderCreated」イベントを発行したら。
プロセス
Extract → Transform (注文ドメイン固有のロジック) → Load
出力
「注文データプロダクト (v1)」 として、独立した場所(例: 専用のS3バケットやDBスキーマ)に発行します。
③. 既存の「ファンイン・パイプライン」を修正(ECRS: 排除)
ここがストラングラーパターン のポイントです。
既存の巨大なCentral ETLから、
「注文データに関する処理」をすべて「排除(Eliminate)」
します。
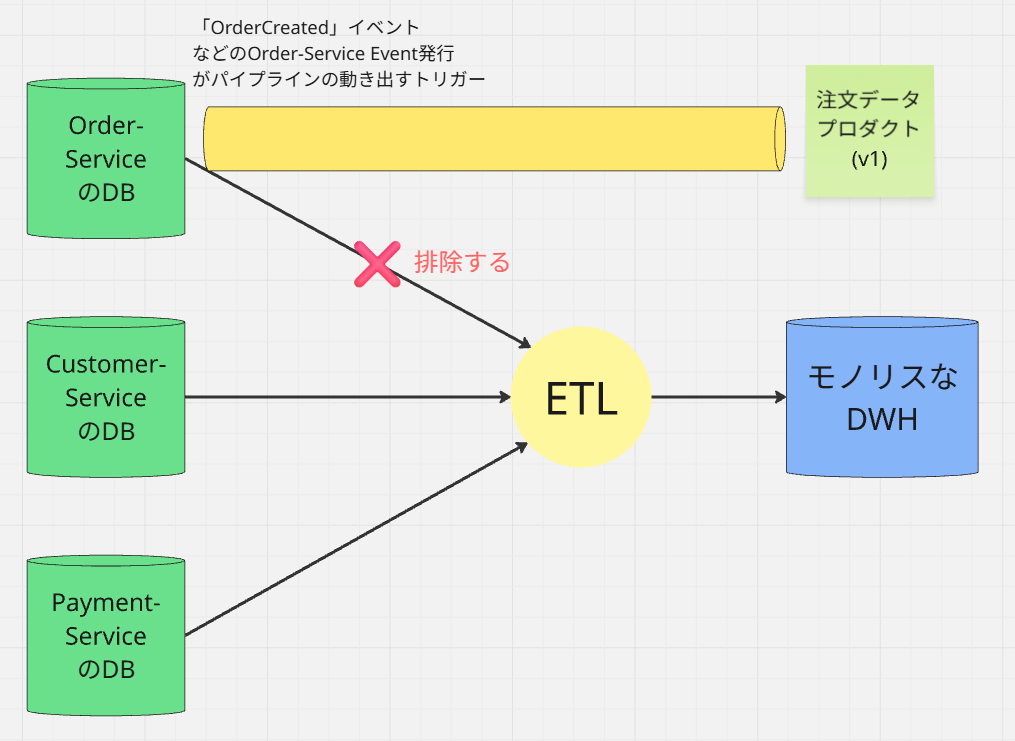
もしCentral ETLが、下流の分析のために「注文データ」を必要としていた場合は、
Order-ServiceのDBから直接Extractするのをやめて、新しく作られた 「注文データプロダクト」を読み込むように修正します。
このフェーズの終了時、パイプラインアーキテクチャは以下のハイブリッド状態になっています。
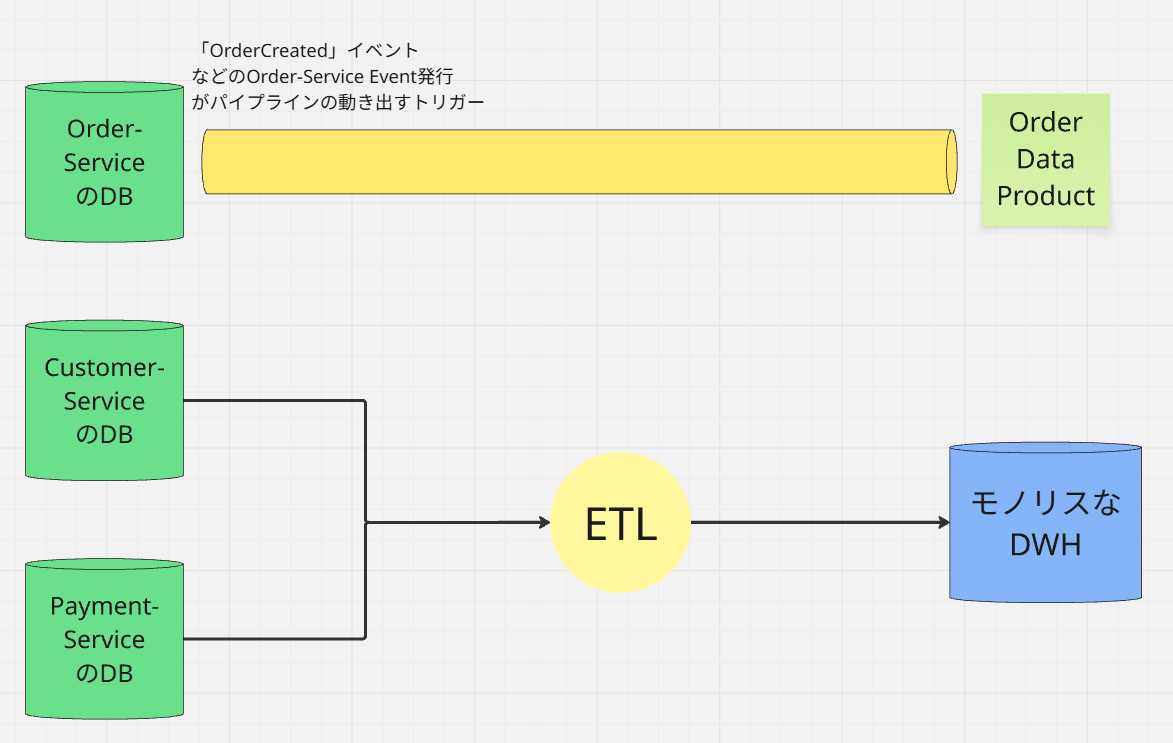
フェーズ3:最終形(E2Eパイプライン・コレクション / データメッシュ)
フェーズ2のプロセスを、ドメインごとに繰り返します。
詳細な手順
①. 「顧客(Customer)ドメイン」用のE2Eデータパイプラインを構築し、「顧客データプロダクト」を発行します。
②. 既存のCentral ETLから「顧客データに関する処理」を排除します。
③. これをすべてのドメインで繰り返します。
最終的に、Central ETLの責務はすべて新しいE2Eパイプライン群に奪われ、
Central ETL(ファンイン・パイプライン)とモノリシックDWHは、完全に「排除(Eliminate)」 されます。
最終的なパイプライン構造
・E2E Pipeline (Order) → Order Data Product
・E2E Pipeline (Customer) → Customer Data Product
・E2E Pipeline (Payment) → Payment Data Product

これで、アプリケーションアーキテクチャとデータパイプラインアーキテクチャが、どちらも独立したエンドツーエンドの構造として、完全に一貫した状態になります。
アプリパイプラインとデータパイプラインの進化の共通性
繰り返しになるかもですが、念のため、アプリのパイプラインの進化と、データパイプラインの進化の共通性を見ていきましょう。
アプリケーションアーキテクチャの方で、
「モジュラーモノリス→分散モノリス状態なエピックサーガ→アプリ層では独立したものの依然としてまだインフラ層で蜜結合なおとぎ話サーガ」であるフェーズ。
(ここまでは、CI/CDは、中央集権的なファンインパイプラインモデル)
そのフェーズから、インフラ層を非同期にし、インフラ層まで分離したパラレルサーガやアンソロジーサーガに進化させたい場合、先に上記のストラングラーパターンのメカニズムで、新しい「E2Eデータパイプライン」を“横に”構築し、古いパイプラインの責務を一つずつ奪っていくというメカニズム。
データパイプラインを、データメッシュ化に伴い、「E2Eデータパイプライン」にするのも
「中央集権的なモノリス(ファンイン・パイプライン)」から「分散的で独立したコンポーネント(E2Eパイプライン)」
へと、稼働中のシステムを停止させずに安全に移行する、という同じ課題を解決しようとしています。
そして、そのための最も安全な戦略が 「ストラングラー・フィグ・パターン(絞め殺しのイチジク)」 です。
2つのシナリオの共通点
どちらのシナリオも、名前が違うだけで、本質のメカニズム構造は一緒です。
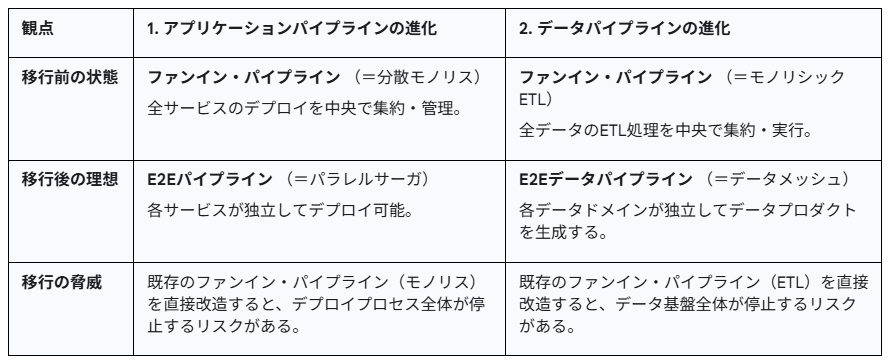
ストラングラー・パターンによる共通の解決メカニズム
この「移行の脅威」を回避するため、どちらのシナリオも全く同じストラングラー・パターンのメカニズムを適用します。
①. 新しい「つる」を横に構築する (Build New)
アプリ側
移行対象の「サービスA」だけを独立してデプロイできる、新しいE2Eパイプラインを横に構築します。
データ側
移行対象の「注文データ」だけを処理できる、新しいE2Eデータパイプラインを横に構築します。
②. 古い「幹」の責務を奪う (Strangle Old)
アプリ側
既存の「ファンイン・パイプライン」から、「サービスAのデプロイ責務」を
排除(ECRSのE) します。
古いパイプラインは、「サービスB, C」のデプロイだけを行うよう縮小します。
データ側
既存の「ファンイン・ETL」から、「注文データの処理責務」を排除します。
古いETLは、「顧客データ、決済データ...」の処理だけを行うよう縮小します。
③. 責務がゼロになるまで繰り返す (Repeat)
このプロセスをすべてのサービス(またはすべてのデータドメイン)で繰り返します。
最終的に、古い「ファンイン・パイプライン」は責務がゼロになり、安全に停止・削除されます。
結論
アプリケーションアーキテクチャであれ、データパイプラインアーキテクチャであれ、
「モノリスから分散システムへの移行」という課題に対する戦略的な答えは、ストラングラー・フィグ・パターンという共通のメカニズムです。