前置き
今回は、各マイクロサービスの保有するコマンドもしくは、リードモデルを源泉として、
最終的な成果物であるデータプロダクトを作成するためのアーキテクチャパターンを紹介します。
すでにネタバレしてしまってますが、大きく分けて、
リードモデルを源泉とするパターン
コマンドモデルを源泉とするパターン
の2つに大きく分類されます。
それぞれの特性やメリデメを見ていきましょう。
パターン1:リードモデルを源泉とする(現実的なアプローチ)
こちらの方が割かし多いアプローチです。模式図は以下の通り。
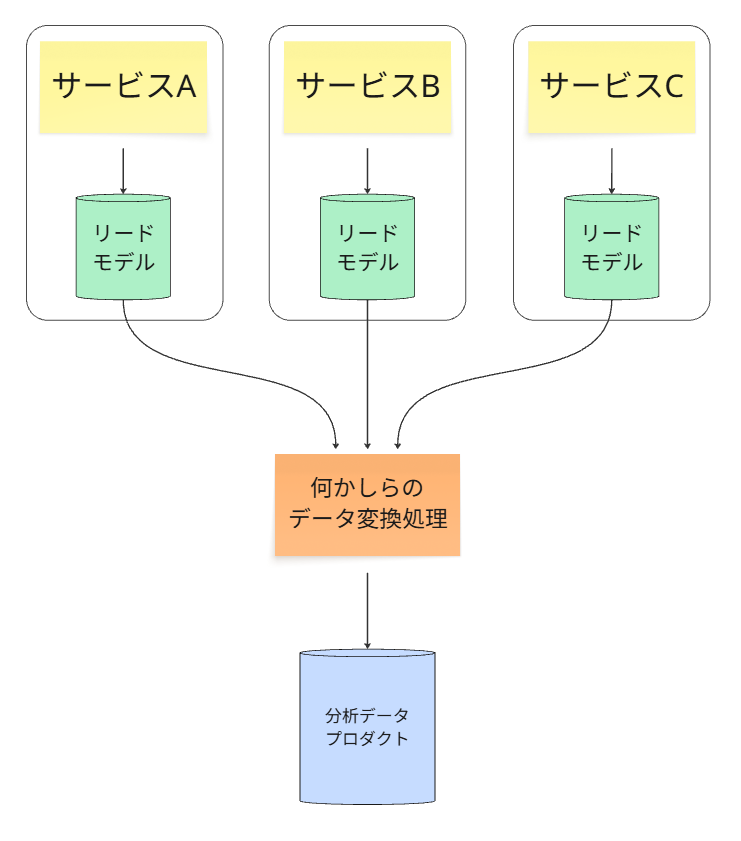
仕組み
マイクロサービスが持つ読み取り専用のリードモデル(例: PostgreSQLのテーブル)
のデータを、ETL/ELTツールが定期的に抽出し、データウェアハウスなどにロードして、
分析用のデータプロダクトとします。
✅ メリット
実装が容易
リードモデルはすでに消費しやすいように整形された「最新の状態」を持っているため、
データパイプラインの構築が比較的簡単です。
分析価値の早期実現
実装が容易であるため、完璧ではないにせよ「十分な」品質のデータを、より早く分析チームに提供できます。これにより、ビジネスは迅速にデータ活用を開始できます。
要求スキルの平易さ
一般的なRDBに対する、従来型のETL/ELT処理の知識で対応可能です。
高度なストリームプロセッシングの専門知識は必ずしも必要ありません。
❌ デメリット
データ粒度の限界
リードモデルは「最新の状態」しか保持していないため、コンテキスト情報となる
「どのようにその状態に至ったか」 という詳細な変更履歴は失われています。
そのため、分析の深さに限界があります。
運用負荷
分析のための大規模なデータ抽出が、オンラインの業務を支えるリードモデルのパフォーマンスに影響を与える可能性があります。
ビジネス文脈の喪失
リードモデルは業務クエリ用に最適化された状態であり、イベントが本来持っていた
豊かなビジネス上の意味(例:TrialUserConvertedToPaidPlan)が、単なるステータス変更(status = 'PAID')に情報圧縮されてしまっている可能性があります。
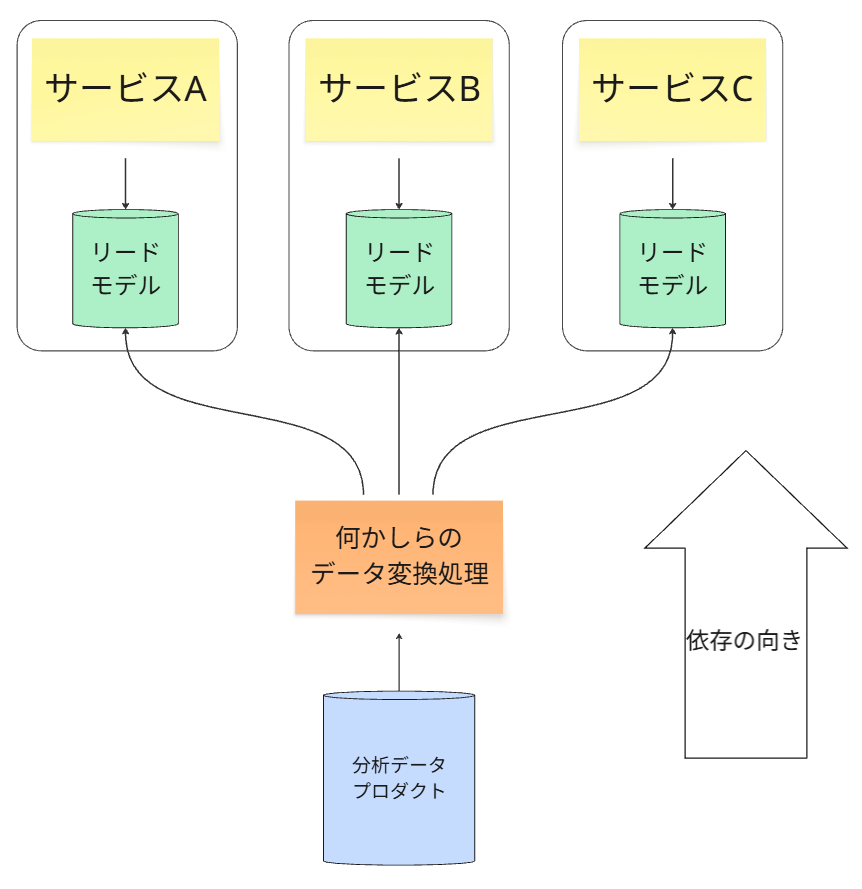
アーキテクチャの結合
分析データプロダクトのスキーマが、業務用リードモデルのスキーマに強く依存します。
アプリケーションチームが、自身の業務都合でリードモデルのスキーマを変更すると、
下流の分析パイプラインが連鎖的に破壊されるリスクがあります。
パターン2:イベントストアを源泉とする(理想的なアプローチ)
こちらはそんなに頻繁に出てくるものではないですが、イベントストアが源泉である分、
データ品質は、リードモデルの時よりも高くなります。
仕組み
分析用のデータパイプラインが、マイクロサービスのリードモデルではなく、
書き込み専用のイベントストア(例: Kafkaのトピック) を直接購読します。
✅ メリット
最高のデータ品質
「いつ、誰が、何をしたか」というビジネスプロセスの全履歴が、イベントとして完全に記録されています。これにより、遥かに深く、リッチな分析が可能になります。
完全な疎結合
分析用のデータ処理が、業務用の読み取りシステム(リードモデル)に一切負荷をかけません。これは、性能と耐障害性の観点からだと、非常に優れた設計です。
将来の分析への対応力
現在は不要でも、将来新しい分析軸(新しいリードモデル)が必要になった際に、過去の
イベント履歴を全て再生することで、いつでも新しいデータプロダクトを構築できます。
リアルタイム分析の実現
イベントストリームを直接処理することで、日次バッチのような時間差のある分析ではなく、リアルタイムでの分析が可能になります。
❌ デメリット
実装の複雑性
イベントストリームを直接処理し、分析可能な「状態」へと変換するには、より高度なストリームプロセッシングの技術が必要となり、パイプラインの実装は複雑になります。
データ量の増大とコスト
全ての変更履歴をイベントとして永続化するため、最新状態のみを保持するリードモデルに比べて、データストレージのコストは増大する傾向にあります。
高度なガバナンスの必要性
イベントは不変であり、一度記録されると修正が困難です。
そのため、イベントのスキーマをどうバージョン管理するか(スキーマレジストリ)、
個人情報をどう扱うかといった、より厳格なデータガバナンスが求められます。
特性の違う2つのデータパイプライン
【パターン2:イベントストアを源泉とする(理想的なアプローチ)】 では、
確かにデータ品質上は最高かもしれないですが、
・コマンドモデルからリードモデル
・コマンドモデルから分析モデル
の2つのデータパイプラインを考えないといけない。(図の緑と青線部分)
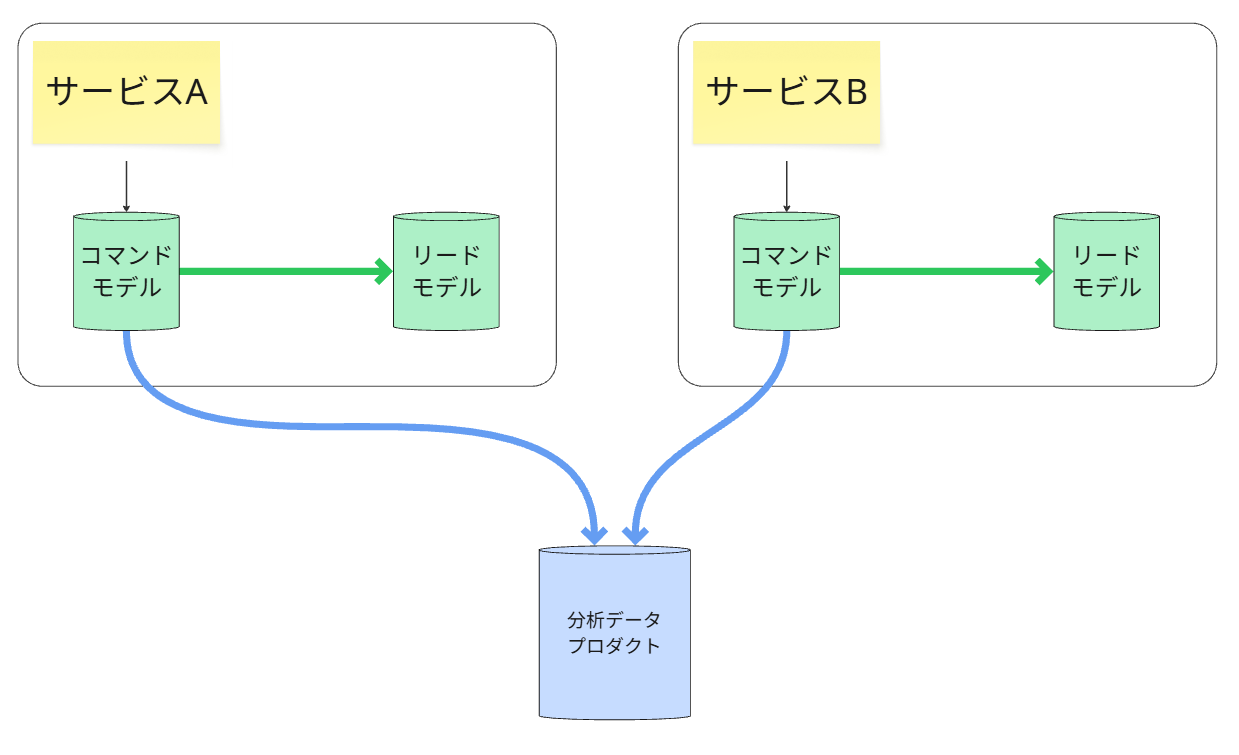
同じイベントストアという源泉から出発しても、そのデータの「消費者」であるリードモデルと分析モデルでは、目的と求められる品質特性が全く異なるため、それぞれに最適化された2つのデータパイプラインが必要になります。
①. リードモデルへのパイプライン(プロジェクター)
図の緑の矢印線のパイプラインです。
目的
アプリケーションのオンライン業務(例:画面表示)を支えるため、「現在の状態」 に
関するクエリに高速に応答すること。
求められる品質特性
・低レイテンシー
書き込みが、できるだけ速く読み取りに反映されること(Read-Your-Writes問題の緩和)。
・シンプルな変換
通常、イベントから1対1の関係に近い、単純なデータ変換が求められる。
データ構造
特定のIDで高速に検索できるような、正規化された、or ドキュメント形式のデータ構造。
②. 分析モデル(データプロダクト)へのパイプライン
図の青い矢印線のパイプラインです。
目的
BIツールや機械学習モデルといった、オフライン分析を支えるため、過去からの全履歴を
効率的に集計・分析できるようにすること。
求められる品質特性
・高スループット
大量の履歴データを一度に処理できる能力。
・複雑な変換および集約
複数のイベントを組み合わせたり、他のデータプロダクトと結合したりといった、
複雑なデータ加工が求められる。
データ構造
大規模なスキャンや集計に適した、非正規化されたワイドテーブルや、カラムナフォーマット(例: Parquet)。
※注意事項
この異なる2つの要求を、単一のデータパイプラインで同時に満たそうとすると、
どちらの要求も十分に満たせない、中途半端なものが出来上がってしまいます。
したがって、目的と要求が全く異なる2つの消費者のために、
それぞれに最適化された2つの異なるデータパイプラインを設計・運用
するのが、このパターンのベストプラクティスです。
ここまでのおさらい
結論として、
「リードモデルが源泉になる」は、多くの実用的なシナリオにおいて正しい
しかし、最高のデータ品質とシステムの疎結合性を追求するならば、イベントストアを直接の源泉とすることが、アーキテクチャの最終的な理想形と言えます。