前置き
今回は、
段階的な非同期マイクロサービスへの進化移行と、
それに伴うカオスエンジニアリングの戦略的取り入れ
について触れていきたいと思います。
これは、単一のプロダクトだけでなく、組織全体の技術的・文化的成熟までを視野に入れた、包括的な変革のロードマップです。
技術的な変革と、組織的な変革を、信頼性の継続的な検証という活動を通じて、共進化させていくための、壮大かつ実行可能なロードマップとも言えます。
2回の記事に分けて、5つのフェーズに分けてお話ししていきたいと思います。
フェーズ1:分散モノリス期(エピック/伝言ゲームサーガ)
この段階は、分散化を導入初期のころです。
いってしまえば、マイクロサービスの赤ちゃんフェーズです。
アーキテクチャの状態
この段階では、アプリケーションはマイクロサービスとして論理的には分割されていますが、その実態は同期的・アトミックなトランザクションによって強く結合しています。
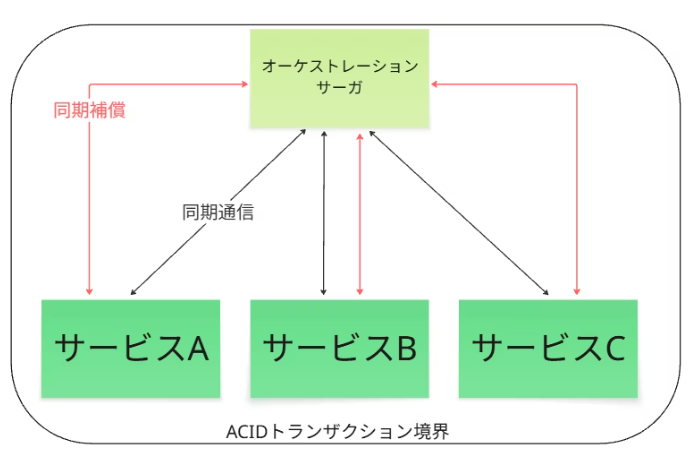
サービス間の通信はブロッキングなAPI呼び出しが中心であり、一つのサービスの遅延や障害が他のサービスに直接伝搬する、時間的な密結合状態にあります。
これは、論理的には分散されていますが、運用上はモノリスのように振る舞う「分散モノリス」です。
カオスエンジニアリング戦略
原則として、
この段階では、大規模なカオス実験は実施しません。
予算とリソースは、より不確実性の高い、未知の未知な領域に投資すべきです。
目的と焦点
このフェーズでの目的は、システム全体の複雑な振る舞いを検証することではありません。
なぜなら、インフラ層(DB、ネットワーク)に障害を注入すれば、システム全体が連鎖的に停止することは自明で、大規模な実験から得られる新たな学び(ROI)が低いためです。
なので、個々のコンポーネントの基本的な回復力(例:単一インスタンス障害時のLBの切り離し)を検証し、チームがカオスエンジニアリングの文化に慣れることに焦点を当てます。
具体的な実験仮説と検証項目
ただし、チームがカオスエンジニアリングの文化に慣れるための、ごく限定的なミクロな実験は非常に有効です。
・仮説
IF:商品サービスの単一インスタンスがクラッシュした場合、
THEN:ロードバランサーは3秒以内にそれを検知し、正常なインスタンスにトラフィックを振り分けることで、エンドユーザーへのエラーレートは1%未満の上昇に留まるはずだ。
・検証
この実験を通じて、
個々のコンポーネントの基本的な回復力と、監視アラートが正しく機能するか
を検証します。
このフェーズでの学びと次のステップ
システム全体の弱点を探る前に、まず個々のコンポーネントが最低限の堅牢性を持つことを確認しましょう。
そして、チームとして障害を意図的に起こして、そこから学ぶという文化づくりの第一歩を踏み出します。
フェーズ2:結果整合・同期連携期(おとぎ話サーガ)
2PCからアプリケーション層に、補償トランザクション系の処理が移った後です。
アーキテクチャの状態
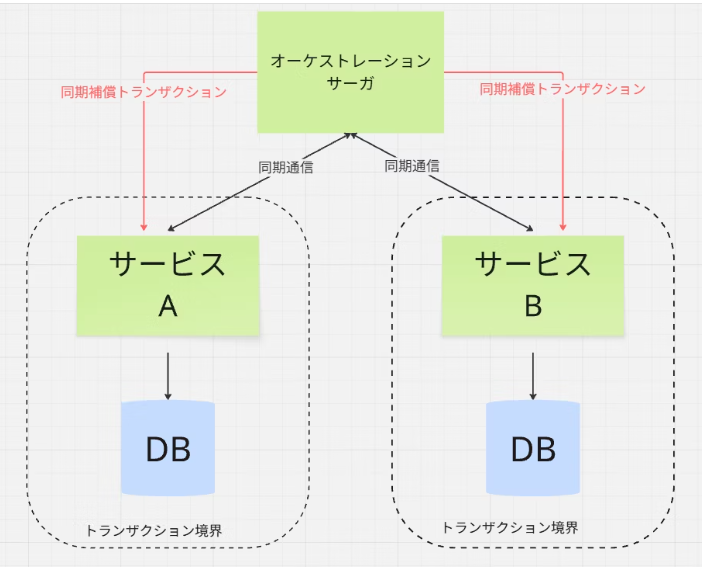
この段階では、アトミック整合性を放棄し、結果整合性へと移行します。
各サービスは自身のローカルトランザクションを持ちます。
サービス間連携は依然として同期的なAPI呼び出しが中心であり、時間的な結合は残存しています。
2PCによる、インフラレベルでのロックは解消されましたが、アプリケーションレベルでの依存関係は依然として強い状態です。
カオスエンジニアリング戦略
アプリケーション層への障害注入に実験を厳選・集中します。
目的と焦点
インフラ層の挙動(同期なので呼び出し先がダウンすると呼び出し元も当然影響を受けるetc)はある程度予測可能です。
このフェーズで最も不確実性が高いのは、
アプリケーション層に残存する 「隠れた依存関係」や「意図しない時間的結合」
です。これを実験でプロアクティブに発見することが目的です。
具体的な実験仮説と検証項目
・仮説
IF:依存先である決済サービスのAPI応答が、通常より500ms遅延した場合、
THEN:呼び出し元である注文サービスは、設定された800msのタイムアウトに従って適切に処理を中断し、自身のスレッドプールを枯渇させることなく、後続のリクエストを処理し続けられるはずだ
・検証
この実験を通じて、
タイムアウトやリトライのロジックが、高負荷状態で予期せぬ連鎖障害を引き起こさないか
を検証します。
この実験自体が、振る舞いに関する適応度関数(例:注文APIのレイテンシー < 800ms)が
現実的かどうかを評価するインプットとなります。
アクション
この実験を自動化し、CI/CDパイプラインに組み込むことで、意図しない結合がデプロイされるのを継続的に防ぐ。
これ、システムの 振る舞いに関する「適応度関数」 を構築していることに他なりません。
こいつが、次の非同期化への移行が安全に行えるかを判断するための、客観的な品質ゲートとなります。
このフェーズでの学びと次のステップ
アプリケーション層の隠れた結合を特定・解消することで、システムをより安全に非同期化するための土台を築きます。
フェーズ3:非同期化移行期(パラレルサーガへの段階的移行)
アーキテクチャの状態
ストラングラーフィグパターンを用い、一部のクリティカルパスから 非同期通信(イベント駆動) への移行を開始します。
この時、システム内には、従来の同期連携の部分と、新しい非同期連携の部分が共存する過渡期です。
カオスエンジニアリング戦略
比較実験を通じて、アーキテクチャ変更の有効性を定量的に証明します。
目的と焦点
非同期化によって、本当にシステムの耐障害性が向上したのか(爆発半径が縮小したのか)
を、経営層を含めた全ステークホルダーにデータで示すことが目的です。
具体的な実験仮説と検証項目
・仮説
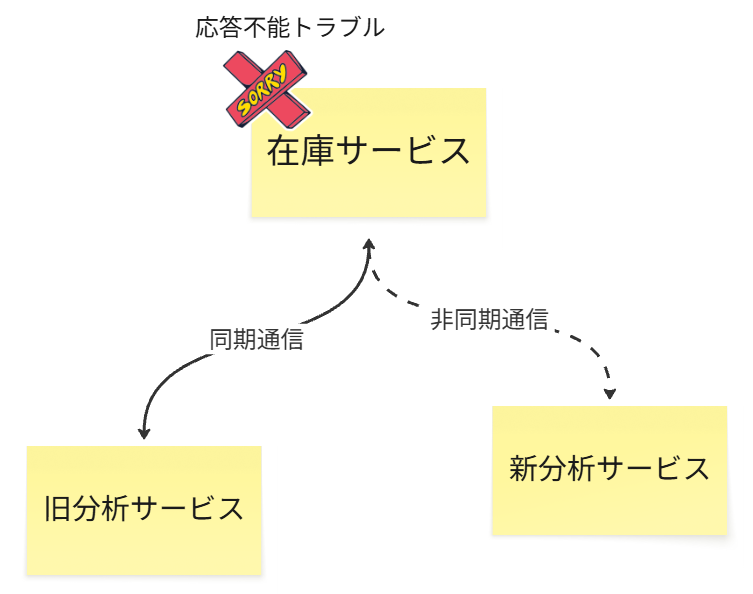
GIVEN:在庫サービスが応答不能になるという同じ障害を発生させた場合、
WHEN:同期連携している旧分析サービスと、非同期連携に進化した新分析サービスの両方で影響を観測すると、
THEN:爆発半径(影響を受けた上流サービスのエラーレート上昇率)は、新分析サービスの方が旧分析サービスよりも90%以上小さくなるはずだ
・検証
オブザーバビリティツールを用いて、エラーレート、レイテンシー、影響を受けたサービス数を計測し、爆発半径が意図通りに縮小していることを証明します。
※批判的な視点/さらなる論点
このアプローチを成功させるには、ステージング環境の忠実度が極めて重要になります。
本番環境と寸分違わぬ環境でなければ、実験結果の信頼性は揺らぎます。
この高忠実度な環境を維持するためのコストと労力が、考慮すべきトレードオフとなるでしょう。
このフェーズでの学びと次のステップ
もし爆発半径が期待通りに縮小していない場合、非同期化の設計(例:イベントの粒度、コンシューマーの実装)に問題があると判断し、アーキテクチャを再検討します。
この実験データに基づき、ストラングラーパターンを安全に次のステップへ進めます。
フェーズ4:成熟期とコレオグラフィへの進化
ここから、中央集権的なサーガの状態管理から、分散的な配置に移行していきます。
先日登壇で発表したこの内容がまさにこれのことです。
アーキテクチャの状態
ほとんどの連携が非同期化され、パラレルサーガ(非同期オーケストレーション) が主流となります。
この段階で、Istioなどのサービスメッシュを導入し、リトライやタイムアウトといった回復性の責務をインフラ層に移譲し、アプリケーションをよりクリーンにします。
次のステップとして、オーケストレーターに集中している状態管理の責務を各マイクロサービスへと分散させ、コレオグラフィ型サーガへの進化を検討します。
カオスエンジニアリング戦略
状態管理の分散 という、極めて困難な移行の安全性を検証します。
目的と焦点
状態を各サービスに分散させた結果、
システム全体としての一貫性が失われたり、循環依存による無限ループが発生したりしないか
といった、コレオグラフィ特有の創発的な(予期せぬ)振る舞いを検証します。
具体的な実験仮説と検証項目
・仮説
IF:注文確定イベントを処理するコンシューマーの一つである配送サービスが30分間停止した場合、
THEN:メッセージブローカーにイベントは滞留するが、配送サービスが復旧した後、システムは最終的に正しい状態に収束し、データの不整合は残らないはずだ
・検証
実際にサービスを停止させ、復旧後にデータの整合性をチェックするテストを実行します。
批判的な視点/さらなる論点
サービスメッシュを導入するタイミングは、もう一つの大きな論点です。
非同期化が完了してから導入するのも一つの道ですが、
フェーズ2(おとぎ話サーガ)の段階で先に導入し、同期通信の信頼性(リトライ、タイムアウト等)をまず固める
という戦略も存在します。
どちらが最適かは、組織のスキルセットや、直面している課題の性質に依存します。
このフェーズでの学びと次のステップ
コレオグラフィ型への移行に伴うリスクを事前に特定・対処し、より自律的で回復力の高いアーキテクチャへの進化を安全に進めます。
フェーズ5:システム分割とオーナーシップの決定
さて、いよいよ最終局面です。
システムとしても分離し、どのチームがシステムオーナーなのかの定義をするフェーズです。
アーキテクチャの状態
コレオグラフィ型サーガが成熟し、特定のサービス群(UAFの論理サービス境界に相当)が、他のサービス群と完全に疎結合になった段階で、それらをインフラレベルでも完全に分離した、システムオブシステムズ(SoS) へと進化させることを検討する。
カオスエンジニアリング戦略
システムの独立性の最終検証と、オーナーシップの割り当ての妥当性評価を行います。
目的と焦点
SoSとしての独立性を保証し、障害対応能力が最も高いチームにシステムの所有権(オーナーシップ)を割り当てるための、客観的なデータを提供することが目的です。
具体的な実験仮説と検証項目
仮説
IF:物流システム全体で大規模な障害(例:リージョン障害)を発生させた場合、
THEN:販売システムは、事前に定義したSLO(サービスレベル目標)の範囲を超える影響を一切受けないはずだ
検証
GameDay(障害対応訓練)としてこの実験を実施し、SLOが維持されるか
を確認します。
さらに、実験中に、
どのチームが最も迅速かつ効果的に障害を検知し、回復させられたか
を観測します。
この障害対応能力の高さが、そのシステムのオーナーとして最もふさわしいチームを決定するための、強力な根拠となります。
批判的な視点/さらなる論点
上記にある「一切影響を与えない」の検証は、SoSとしての最終目標です。
ただ、現実にはレイテンシーの微増や、下流システムでのエラーレートの一時的な上昇など、ある程度の「影響」は許容する必要があります。
なので、ここで重要になるのは、
「許容可能な影響の範囲(SLO)を定義し、カオス実験がその範囲内に収まることを検証する」
という、より定量的なアプローチです。
このフェーズでの学びと次のステップ
技術的な独立性と、組織的な対応能力の両方をデータで証明することで、真に自律的でレジリエントなエンタープライズアーキテクチャを完成させ、継続的な改善のサイクルを回し続けます。
もちろん、その後もサービスメッシュの上で、連携するSoSに対して、
定期的にGameDay(障害対応訓練)を実施し続ける必要があります。