前置き
上記の記事の続きになります。
今回の主要テーマは、データカオスエンジニアリングです。
事実課題
イベントストアは、「唯一の真実の情報源」という特性から、もしも消えてしまった時に、
事業継続性の観点から最悪なシナリオを辿ります。
仮説
そのため、いざインシデントが起きて、データが消えてしまってからでは遅いので、
プロアクティブな活動として、開発環境とかで試しに、イベントストアに対してデータカオス実験を行うことで、具体的なHowとして、
どのくらいの冗長性が求められるのか?
どのようなバックアップ戦略を取るのか?
を考えられるはずです。
これは、いざという時に「データは破損していないはず」という希望的観測を排除し、
「破損せずに動くことを証明する」ための、極めて科学的なプロアクティブ活動です。
なぜデータカオス実験が不可欠なのか?
イベントストアのバックアップ戦略は、机上の空論で完璧に設計したつもりでも、現実のインシデントでは、以下のような予期せぬ問題が必ず発生します。
隠れた依存関係
「復旧スクリプトが、実は削除対象のDBと同じリージョンにある認証情報に依存していた」
プロセスの不備
「復旧手順書はあったが、担当者がその存在を知らなかった。またはその内容が古くて実行できなかった」
ツールの問題
「バックアップからのリストアツールが、想定以上のデータ量でタイムアウトしてしまった」
これらの問題は、実際に障害を発生させてみなければ決して見つかりません。
データカオス実験の大枠の進め方
開発環境やステージング環境など、本番に影響を与えない隔離された環境で、以下のような実験を計画的に行います。(ぶっちゃけアプリケーションへのカオス実験と一緒です)
(本番環境と隔離する理由は、以下の記事で触れています。)
1. 定常状態の定義
まず、「正常」とは何かを定義します。
これはビジネス要件である RPO(目標復旧時点)とRTO(目標復旧時間) です。
事例:「RPOは5秒以内、RTOは15分以内」など。
2. 仮説の立案
次に、「何が起きても大丈夫なはずだ」という仮説を立てます。
事例
「もし東京リージョンのDynamoDBテーブルが完全に削除されても、
我々はグローバルテーブルを使ってバージニア北部にフェイルオーバーし、15分以内にサービスを復旧できるはずだ。」
3. 障害の注入(カオス実験)
この仮説を検証するために、意図的に障害を発生させます。
シナリオA (テーブル破壊)
aws dynamodb delete-table コマンドで、プライマリのイベントストアを本当に削除してみる。
シナリオB (リージョン障害)
ネットワーク設定を変更し、アプリケーションからプライマリリージョンへのアクセスを
完全に遮断してみる。
シナリオC (データ破損)
特定のイベントレコードを意図的に不正なデータで上書きしてみる。
その上で、PITRからの復旧が正しく機能するかを試す。
4. 検証と学習
実験後、結果を検証します。
「実際にRPOとRTOは達成できたか?」
「フェイルオーバーのプロセスで、手動の作業や想定外のトラブルは発生しなかったか?」
「復旧したデータに欠損や不整合はなかったか?」
この結果から、
「グローバルテーブルへの切り替えは自動化できるが、DNSの切り替えに思ったより時間がかかった。
そのため、手順書を改善し、TTL(Time To Live)を短くする必要がある。」
といった具体的な改善点を発見します。
ここまでのまとめ
バックアップ戦略を設計するだけなのは、ビルに火災報知器を設置するようなものです。
でもそれだけでは、
いざという時に従業員が安全に避難できるかは分かりません。
データカオス実験は、実際に防災訓練を行うことに相当します。
警報を鳴らし、避難経路を実際に走り、問題点(開かない扉、分かりにくい案内図)を洗い出す。
この訓練を継続的に繰り返すことで初めて、組織とシステムは本当の災害に対応できる
「レジリエンス」 を身につけることができるのです。
データカオスは、この「防災訓練」をデータアーキテクチャの世界で実践しようというアプローチです。
データカオス実験が多層防御に繋がるプロセス
データカオス実験は、机上の空論であったバックアップ戦略を、実績に裏付けられた多層防御システムへと昇華させるための、最も強力なフィードバックループです。
「もしも」の世界で防災訓練を行い、その結果に基づいて設計図を書き直し、実際に既存の仕組みを強化していく学習プロセスそのものなので、データカオス実験は、単に「動くか動かないか」を試すだけではありません。
そして、
実験により、自分たちの防御策の「限界」を意図的に明らかにし、次の防御層がなぜ必要なのかを証明する
ための科学的なプロセスです。
フェーズ1:設計図上の防御策(仮説)
まず、カオス実験の前には、以下のような 「こうすれば大丈夫なはずだ」という仮説に基づいた設計図が存在します。
また、誰もが共通認識を持ちやすく、かつ後からこの仮説のロジックの検証を行いやすくするため、下図のようなロジックブランチモデルで、
・前提条件となる原因
・置いている仮定
・その上で成り立つ結果
という形式で表現しておきましょう。
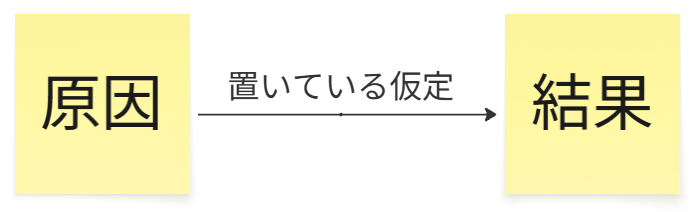
これにより、
・原因と置いている仮定は確かに存在したが、結果は別のものであった。
・原因も結果も確かに存在したが、仮定が足りておらず、原因の十分性が低いことが示された。
・結果は確かに存在したが、その背後のメカニズムとして別の原因があった。
といった振り返りを推論を用いて行いやすくなります。
第一防御層 (可用性)
「DynamoDBのグローバルテーブルがあれば、リージョン障害が起きても数秒で切り替わり、サービスは継続できるはずだ。」
第二防御層 (復旧性)
「もし人的ミスでデータを壊しても、ポイントインタイムリカバリ (PITR) を使えば15分以内に復旧できるはずだ (RTO=15分)。」
第三防御層 (最終防衛)
「万が一DB自体が破損しても、S3へのストリームバックアップからなら、時間はかかっても全データを復元できるはずだ。」
この時点では、これらはすべて希望的観測に過ぎません。
フェーズ2:模擬攻城戦(データカオス実験)
次に、この設計図の弱点を炙り出すために、意図的に攻撃(障害注入)を行います。
いきなり、複数の障害を注入することは、多変数解析となり、ただ複雑化し、学習効果が大幅に減るため、意図的に単独の障害のみの注入から始めましょう。
学習効果が十分になったと言える段階になってから、初めて複数の障害を同時に注入することで、2つの条件が揃った時のみ起こり得るトラブル の学習へ移行する。
この辺は、上記の記事で詳しく触れています。
実験①
プライマリリージョンのテーブルを本当に削除してみる。
実験②
アプリケーションからプライマリリージョンへのネットワークを遮断してみる。
実験③
大量の不正なデータを書き込み、PITRからの復旧を試みる。
フェーズ3:損害評価と分析(実験結果からの学習)
ここが最も重要な、実験と多層防御を繋ぐプロセスです。
実験後に得られた「動かぬ証拠」を分析します。
この時には、観測された事実という結果から過去へ遡る、アブダクション思考が必須です。
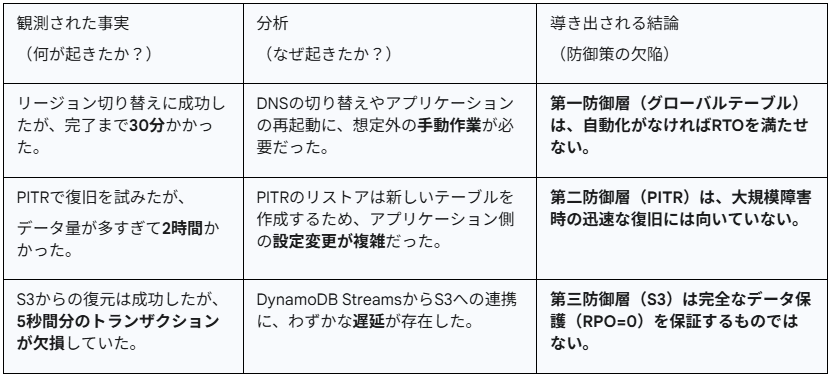
ここでの振り返り(レトロスペクティブ)を通して、もともとの仮説のロジックブランチモデルを修正します。
フェーズ4:城壁の強化(多層防御の構築)
上記の結論に基づき、設計図を現実の脅威に耐えうるものに書き換えます。
これが、具体的な多層防御の構築です。
第一防御層の強化
結論:自動化がなければRTOを満たせない。
対策:
・フェイルオーバーのプロセスを完全にコード化・自動化する。
・ヘルスチェックと連動し、人間の介在なしに数分で切替えが完了する仕組みを構築する。
第二防御層の役割の再定義と強化
結論:PITRは迅速な復旧には向いていない。
対策:
・PITRは「オペミスによる小規模なデータ破損」を直前の状態に戻すための限定的な手段と位置づける。
・大規模障害の復旧シナリオからは除外し、第一防御層の自動化に注力する。
第三防御層の補強
結論:わずかなデータ欠損(RPO)のリスクがある。
対策:
・欠損した数秒間のデータをどう扱うか、ビジネス上の復旧プロセスを定義する。
(例:顧客に通知し、手動で補填する手順を確立する)。
・また、S3への書き込みが成功したことを確認してからAPIのレスポンスを返すなど、アーキテクチャレベルでの保証を強化する。
まとめ
このように、データカオス実験は、
「この防御策は、この種の攻撃に対しては無力である」という事実を証明
します。
そして、その「無力さ」を補うために、次の、あるいは異なる種類の防御層を構築・強化していきます。
この繰り返しこそが、机上の空論を、幾重にも連なる堅牢な多層防御システムへと進化させる原動力となります。