前置き
データメッシュへの移行を考える際に、絶対に避けては通れない道があります。
それが、
マイクロサービスへのデータプロダクトの所有権の割り当て
です。
これを考えずに、データメッシュ化を進めるのは、その時点で炎王してるようなものなので、必ず机上で十分に考えてから、移行を実行に移していきましょう。
ベースの思想
参考記事と書籍
参考記事
参考記事は以下にあります。是非読んでいただけると嬉しいです。
参考書籍


原則
マイクロサービスでのデータ所有権の割り当て同様に、データプロダクトも
「1つのマイクロサービス(を所有するチーム)に所有権を割り当てる」
という、データメッシュのドメインオーナーシップ原則があります。
データプロダクトの所有権が曖昧だと、品質や可用性に対する責任の所在が不明確になり、データメッシュは機能しません。
なので、必ず所有権の割り当ては、データメッシュ化の際に、第一歩として考える必要があります。
1. データ発生源(Source of Truth)パターン
これは、GRASPの情報エキスパート原則に最も近い、基本的で強力なパターンです。
考え方
そのデータの 「信頼できる唯一の情報源」 である業務システムを担うマイクロサービスに、対応するデータプロダクトの所有権を割り当てます。
これは最も基本的で強力なパターンです。
具体例
「顧客マスター」データプロダクトの所有権は、顧客情報の生成と更新に責任を持つ顧客管理マイクロサービスのチームに割り当てます。
「注文履歴」データプロダクトの所有権は、注文トランザクションを直接処理する注文マイクロサービスのチームに割り当てます。
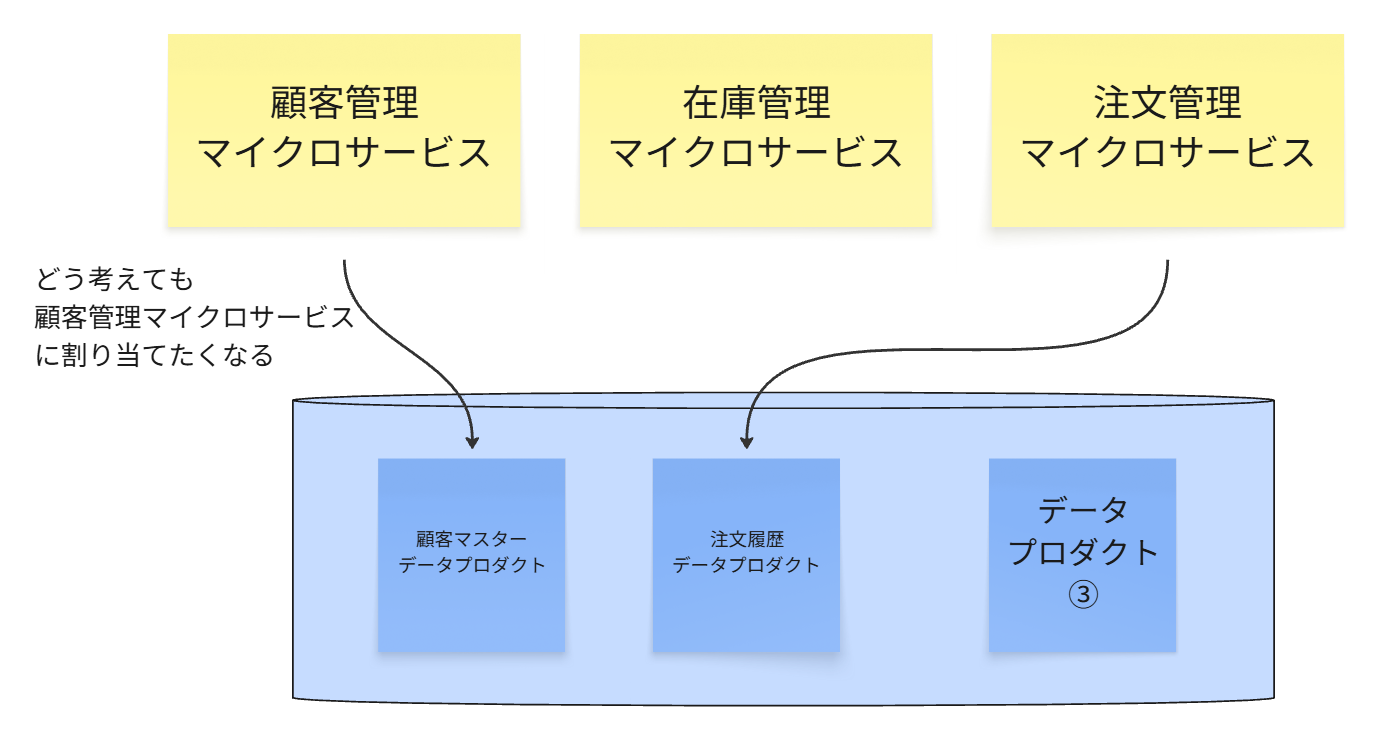
理由
データを生成するチームが、そのデータのビジネス上の意味、文脈、そして品質に関する最も深い知識を持っているためです。
これは、GRASPの 情報エキスパート がベースになってきています。
GRASPの情報エキスパート原則との対応関係
GRASPの情報エキスパート (Information Expert)
原則
あるロジックの責務は、
その責務を果たすために必要な情報(属性)を持つクラスに割り当てる
べきである。
目的
端的に言うと、カプセル化のため。データとそのデータを操作するロジックを同じ場所に配置することで、凝集度を高め、結合度を低くします。
データプロダクトのオーナーシップ
原則
「顧客データプロダクトを提供する」という責務は、顧客に関する
情報を最も多く、かつ正確に持っている顧客管理マイクロサービス(を所有するチーム) に割り当てる
べきである。
目的
このは、データ発生源(Source of Truth)パターンは、まさに情報エキスパート原則を、
マイクロサービスという、より大きな粒度に適用したものです。
データを最もよく知る専門家(情報エキスパート)が、そのデータの提供責任を持つことで、データの品質と文脈が保証され、組織全体の結合度が低く保たれるのです。
普遍的設計思想
データメッシュにおける「データ発生源にオーナーシップを委ねる」という考え方は、
決して目新しいものではなく、オブジェクト指向設計で長年培われてきた普遍的な設計原則の、データアーキテクチャへの応用といってもいいでしょうね。
✅ メリット:正確性と信頼性が非常に高い
データを最もよく知る専門家である、データを生成したチーム自身が、そのデータのビジネス上の意味や文脈を最も深く理解しています。
仲介者がいないため、変換プロセスでエラーや劣化が起きる前の、最も生の、高忠実度なデータが提供されるからです。
❌ デメリット:文脈不測のリスク
下流の消費者から見ると、提供されるデータが生のままで、文脈が不足している可能性があります。
生産者は、あくまで自身の業務遂行に必要な形式でデータを持っているに過ぎません。
分析消費者が必要とする形式に予め加工・整形されているわけではないため、データプロダクトの消費者は利用する際に一手間かける必要があります。
✅ 適用できる状況ケース
では、次にこのパターンが適したような状況をいくつかまとめましょう。
明確な単一の発生源
「顧客マスター」や「商品マスター」のように、そのデータの生成と更新に責任を持つマイクロサービスが、組織内で誰が見ても明確に唯1つに定まっている場合に最も有効です。
コアなビジネスエンティティ
企業のビジネスモデルの中核をなす、普遍的なデータ(顧客、商品、注文など)に適しています。
❌ 適用しない方が良い状況
逆に、以下のような状況では、このパターンはやめた方が良いです。
真実が分散している
あるデータの「真実」が、複数のマイクロサービスにまたがって断片的に存在する場合(例:顧客の基本情報はAサービス、行動履歴はBサービス)では、単一の発生源を特定するのが困難なため、このパターンは適していません。
データの価値が下流で付加される
データの価値が、生成された後、下流のプロセスで大きく変化・付加される場合(例:注文ステータスの更新)、このパターンだけでは不十分なことがあります。
2. 主要な更新者(Most Frequent Writer)パターン
データのライフサイクルに着目する、より動的なパターンです。
考え方
データのライフサイクルの中で、最も頻繁に、あるいは最も重要な状態更新を行うマイクロサービスに所有権を割り当てます。
具体例
注文データは、最初にチェックアウトサービスで作成されるかもしれません。
しかし、その後のステータス(「発送済み」「配達完了」「返品処理中」など)は、物流管理サービスによって頻繁に更新されます。
この場合、「注文ステータスデータプロダクト」の所有権は、物流管理サービスのチームに割り当てる方が適切な場合があります。
理由
データの価値が、生成時より、その後のライフサイクルの中で付加される場合に有効です。
この時、生成者にオーナー権限を無理に持たせる恩恵はないです。
同じような設計思想のもの
この記事にある全体所有というものが設計思想としては、ほぼ一緒の考え方です。
他マイクロサービスからの状態更新にはどう対処するか
「主要な更新者」パターンを実践する上で、ここが最も重要な論点です。
所有者であるマイクロサービスが、そのデータプロダクトへの唯一の書き込み口(ゲートキーパー)
となります。
所有者以外のサービスは、オーナーサービスに対して 「状態更新を依頼する」 という形で連携します。
これにより、データの所有権と責任分界点を明確に保ちつつ、他のサービスからの状態更新を受け入れることができます。
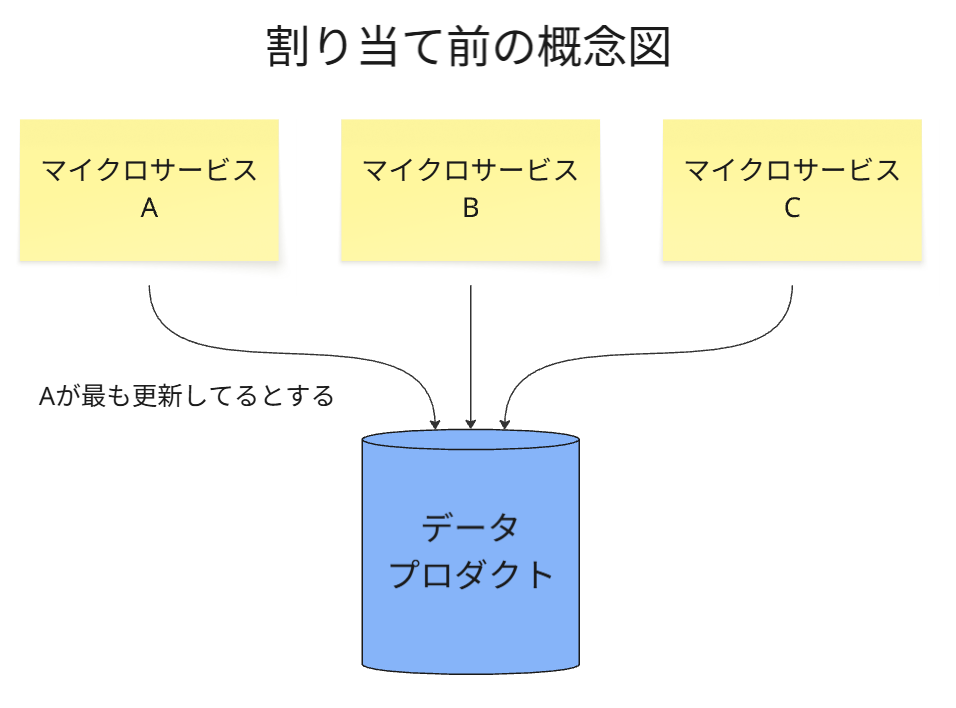
割り当て前
まず、たとえば以下の図のように、3つのサービスがあり、このうちでサービスAが最も
データプロダクトの状態更新をしている状況と仮定します。
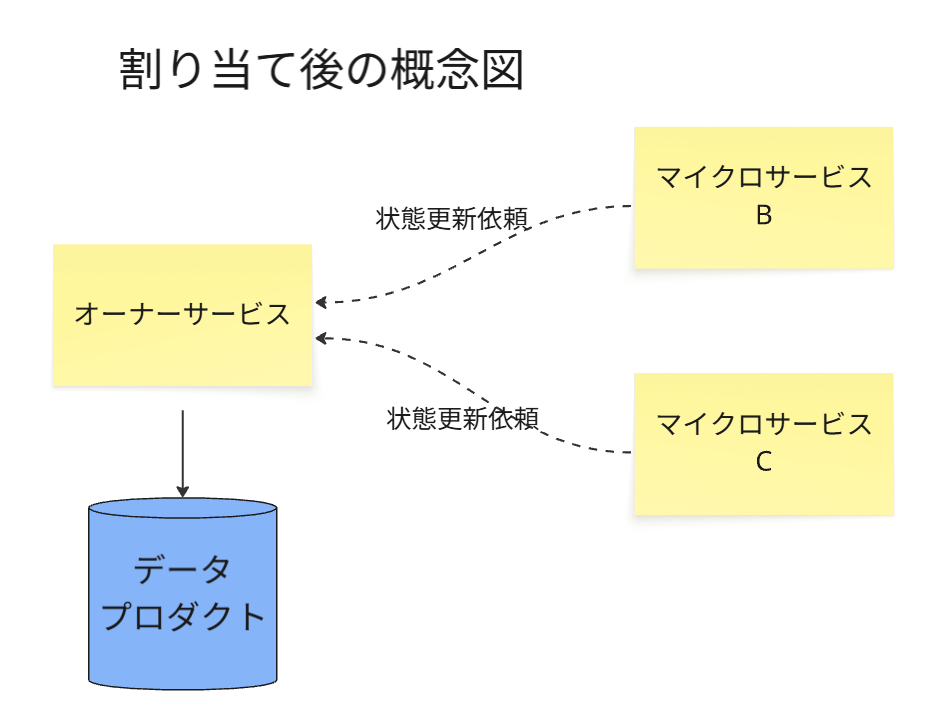
割り当て後
その後に、マイクロサービスAに所有権を割り当て後、サービスB・Cからの状態更新は、
下図のように、サービスB・Cから必ずオーナーサービスであるAに対して、
「状態を更新せよ」というメッセージを送って、オーナーのみが状態を更新できるようにします。
✅ メリット:適時性(Timeliness)& 現在性(Currency)が高い
データの最新の状態を管理するチームがオーナーであるため、ビジネスプロセスの最新の状況を最も正確に反映したデータプロダクトを提供できます。
❌ デメリット:属性の正確性が疎か
このチームの関心事は、データの初期作成時の品質よりも、状態更新の側面に焦点が当たります。
そのため、エンティティが作られた当初の基本的な情報(例:注文時の顧客名や住所)の
正確性に対する責任感が、元の発生源チームより低くなる可能性があります。
結果的に、エンティティの基本的な属性の正確性が疎かになるリスクがあります。
✅ 適用できる状況ケース
状態遷移が価値の中心
「注文ステータス」のように、データの価値がライフサイクル(例:受付→発送→完了)によって定義される場合に有効です。
ワークフローの中心となるサービス
複数のサービスが関わるワークフローの中で、そのエンティティの状態を最も頻繁に更新するサービスが存在する場合。
❌ 適用しない方が良い状況
状態が変化しない
「商品カタログ」のように、一度登録されたらほとんど変更されないような静的なマスターデータには適していません。
所有権の曖昧化リスク
複数のサービスが同程度にデータを更新する場合、どのサービスが「主要な」更新者なのかが曖昧になり、責任分界点がぼやける可能性があります。
3. 集約・合成(Synthesizer)パターン
複数のデータから新たな価値を生み出す、高度なパターンです。
考え方
複数の異なるドメインのデータプロダクトを組み合わせて、新たな価値を持つデータプロダクトを生成する場合のパターンです。
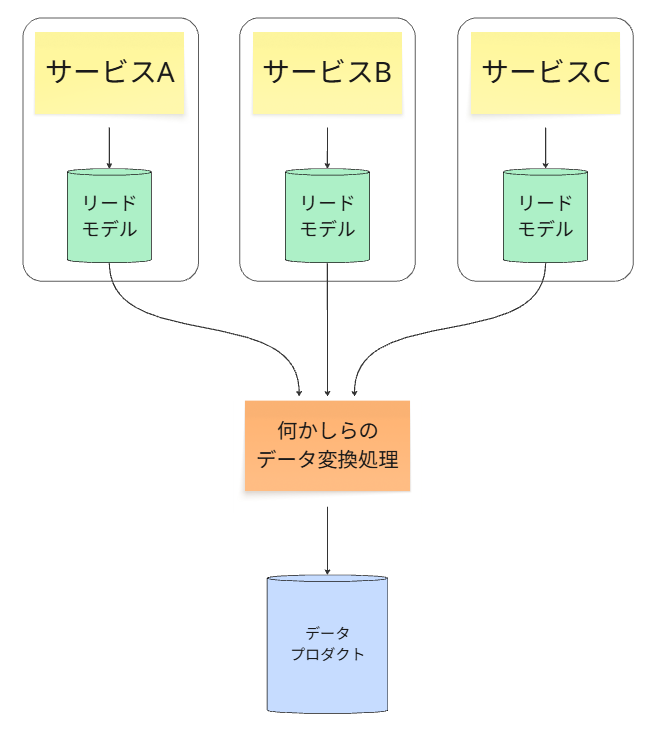
具体例
顧客LTV(生涯価値)データプロダクトを考えます。
これを作成するには、
・顧客データプロダクト
・注文履歴データプロダクト
・マーケティング活動データプロダクト
の3つが必要です。
所有権の割り当て方
a) 中核となるドメインに割り当て
これは、1つ前の 2. 主要な更新者(Most Frequent Writer)パターン の考えです。
この場合、「顧客」が分析の軸となるため、顧客ドメインのチームが、他の2つのデータプロダクトを「消費」して、顧客LTVデータプロダクトを生成・提供する責任を負います。
b) 主要な消費者に割り当て
これは、後述の4. 主要な消費者(Primary Consumer)パターンの考えでっす。
もし、この顧客LTVデータプロダクトを利用するのが実質的にマーケティング部門だけである場合、マーケティングドメインのチームが、自身で必要なデータを集約し、自分たちのためのデータプロダクトを生成するオーナーとなる方が合理的な場合もあります。
✅ メリット:価値と適切性が非常に高い
消費者の特定の分析ニーズに合わせて、複数の情報を統合し、高度なビジネスインサイトを提供することを目的として作られているため、そのまま意思決定に利用できる価値の高いデータとなります。
❌ デメリット:品質が上流の全ソースに依存
データ品質が、上流にある全てのソースデータプロダクトの品質に依存します。
「Garbage In, Garbage Out」
の原則通り、上流にある多数のソースデータのうち、一つでも品質が悪ければ、この下流の集約データプロダクト全体の品質も信頼できないものになります。
依存先が多いため、品質問題の根本原因の特定が複雑になりがちです。
✅ 適用できる状況ケース
派生的なデータが必要
「顧客LTV(生涯価値)」のように、複数のソースデータ(顧客情報、購買履歴など)を組み合わせて初めて計算できる、高度な分析指標をデータプロダクトとする場合に有効です。
ドメイン横断的なインサイト
複数のビジネスドメインにまたがる知見を提供することが目的の場合。
❌ 適用しない方が良い状況
単一ソースで完結するデータ
発生源が単一のシンプルなデータプロダクトを、このパターンを使ってわざわざ複雑にする必要はないです。
この場合には、1. データ発生源(Source of Truth)パターンが適しています。
過剰な依存関係
多数のソースデータに依存しすぎると、一つのソースの障害がデータプロダクト全体に影響を与える、脆い構造になるリスクがあります。
4. 主要な消費者(Primary Consumer)パターン
需要側の視点から所有権を決定するパターンです。
考え方
そのデータプロダクトが、実質的にただ一つの、あるいは極めて重要な消費者チームのために存在する場合、その消費者チーム自身に所有権を割り当てます。
具体例
不正利用検知スコア というデータプロダクトを考えます。
このスコアを生成するには、決済、顧客行動、注文履歴など、複数のドメインのデータが必要です。
しかし、このスコアを実際に利用するのは、セキュリティ・リスク管理チームだけです。
このような場合、彼らがオーナーとなり、必要なソースデータを集めて、自分たちのためのデータプロダクトを構築します。
理由
データプロダクトの価値は、その「使い方」によって定義されます。
そこで主要な消費者であるチームがオーナーとなることで、そのデータプロダクトが常に
ビジネス上の目的に合致し、価値を発揮し続けることが保証されます。
同じ設計思想のもの
「主要な消費者」パターンは、まさしくコンシューマー駆動契約の思想を、データプロダクトのオーナーシップモデルに応用したものと見なすことができます。
どちらの考え方も、
「提供されるもの(APIやデータプロダクト)の仕様や品質は、それを利用する消費者の要求によって駆動されるべきだ」
という共通の原則に基づいています。
消費者が自らオーナーとなることで、そのデータプロダクトが、最も重要なビジネス目的にとって、常に完璧にフィットすることが保証されます。
①. コンシューマー駆動契約(技術的なプラクティス)
APIの消費者(Consumer) が、
「自分たちは、このAPIに対して、このような形式のデータを期待している」
というテストコード(契約)を作成します。
APIの提供者(Provider)は、そのテストが常に通ることを保証する責任を負います。
これにより、提供者が意図せず消費者の期待を壊す変更をしてしまうのを防ぎます。
②. 主要な消費者パターン(組織的なパターン)
①の考え方をさらに一歩進め、データプロダクトの主要な消費者であるチーム自身が、
データプロダクトの 提供者(オーナー) にもなります。
✅ メリット:適切性(Relevancy)が最大化される
データを利用する本人(消費者)が、自身の目的に最も合致する形でデータプロダクトを
設計・構築するため、「目的適合性」 という観点での品質は完璧になります。
❌ デメリット:他の消費者にとって再利用性が著しく低い
特定の用途に過剰に最適化されたデータ構造やロジックは、他の想定外のユースケースには適合しないことが多く、組織全体で見た時にデータのサイロ化や重複開発を招く可能性があります。
以下の記事でも触れているように、いろいろなケースで「本当にこの境界でいいのか?」とデータプロダクトの境界を考察しましょう。
✅ 適用できる状況ケース
特定の目的のためのデータ
そのデータプロダクトが、実質的に単一の、極めて重要な消費者チームのためだけに存在する場合に有効です。(例:「不正利用検知スコア」は、リスク管理チームだけが利用する)
消費者の専門性が高い
消費者チームが、そのデータのビジネス上の意味合いや、あるべき品質について、生産者よりも深い知見を持っている場合。
❌ 適用しない方が良い状況
汎用的なデータ
複数の異なる部門で広く利用される、基本的なマスターデータ(顧客マスターなど)には適していません。
特定の消費者の都合に最適化されすぎてしまい、他の消費者が使いにくくなります。
5. コンプライアンス・レポーティング パターン
ビジネス上の要求ではなく、外部からの要求で所有権を決定するパターンです。
考え方
データプロダクトの存在理由が、法規制や業界標準への準拠(コンプライアンス) のためである場合、そのコンプライアンス要件に責任を持つ部門に所有権を割り当てます。
具体例
金融業界におけるアンチマネーロンダリング(AML)レポート用のデータプロダクト。
これを作成するには、顧客情報や取引履歴など、多数のドメインデータが必要です。
このプロダクトのオーナーは、
技術チームではなく、コンプライアンス部門
自身であるべきです。
理由
データの品質基準が、技術的な観点よりも、法的な解釈や規制要件の充足という観点によって、より強く規定されるためです。
✅ メリット:一貫性と監査性が外部基準で保証される
品質の基準が、規制当局などが定めた明確で客観的な外部の仕様に基づいているため、
その基準を満たしている限り、品質は非常に高いレベルで保証されます。
❌ デメリット:社内ユーザーにとっては価値が低い可能性
規制要件を満たすことだけが目的化し、フォーマットが固定化されているため、社内のビジネスユーザーにとっては、価値が低いまたは、データプロダクトになりやすいです。
社内のビジネス分析で求められる柔軟性や、より深い洞察を提供するデータとしては不十分なことが多いです。
✅ 適用できる状況ケース
法規制・監査対応
金融規制当局へのレポート提出など、法規制や監査などコンプライアンス要件を満たすことが、データプロダクトの唯一の目的である場合。
❌ 適用しない方が良い状況
社内の意思決定用データ
内部のビジネス分析や意思決定に使うことを主目的とするデータプロダクトには適していません。
俊敏性が求められる
規制要件は厳格で変更が難しいため、社内の迅速な意思決定や、変化の速いビジネスニーズに対応するためのデータプロダクトには不向きです。
6. 外部システム連携パターン
自社でコントロールできないデータソースを扱うパターンです。
考え方
データプロダクトの主要なデータソースが、
外部のSaaS(例: Salesforce, Google Analytics) である場合、そのSaaSの導入・運用管理に責任を持つチームに所有権を割り当てます。
具体例
代表的なのが、Salesforce営業案件データプロダクト。
このデータの「真実」はSalesforceの中にあります。
したがって、そのデータプロダクトのオーナーは、
Salesforceの運用を担当する営業企画チームやビジネスシステムチーム
となります。
理由
外部システムのデータ仕様、APIの制約、そしてビジネス上の意味合いを最も深く理解しているチームがオーナーとなることで、信頼性の高い、文脈の豊かなデータプロダクトを提供できるためです。
✅ メリット:外部データの専門家による品質管理
その外部システムの仕様やAPIの制約、ビジネス上の意味合いを最も深く理解しているチームがオーナーとなるため、外部データを正確な文脈と共に、信頼性高い安定して社内に提供できます。
❌ デメリット:品質が外部ソースに完全に依存
外部SaaS側で発生したデータ品質の問題(例:バグによるデータ欠損、APIの停止)に対して、オーナーチームは直接的な修正手段を持っていません。
品質は、外部ベンダーの対応に完全に依存することになります。
✅ 適用できる状況ケース
SaaSデータの活用
データソースがSalesforceやGoogle Analyticsといった外部SaaSである場合、そのSaaSの運用管理に責任を持つチーム(例:営業企画チーム)がオーナーとなります。
❌ 適用しない方が良い状況
当たり前ですが、内部で生成されるデータ: 自社システム内で生成されるデータに適用する理由はありません。
まとめ
これらのパターンを使い分けることで、各データプロダクトに対して、最も責任を持って品質を維持・向上させることができる、適切なオーナーを定義していくのです。
オーナーの割り当てなき状態では、データプロダクトの品質保証はできません。
必ず、どのサービスのオーナーに割り当てるのか?考察後に、データメッシュに移行しましょう。