適応度関数導入の推奨フェーズ
まだ重要な品質特性が定まり切っていないうちから導入はやめた方が良いと感じます。
早期に利用時品質の中で重要なものをマーケターの人と握って、そこから左にアブダクションする形で外部品質の優先順位付けを行うといったものができた上で、その優先度の高い品質特性(非機能)に対する、指標の随時チェックとして適応度関数を定義すべきです。
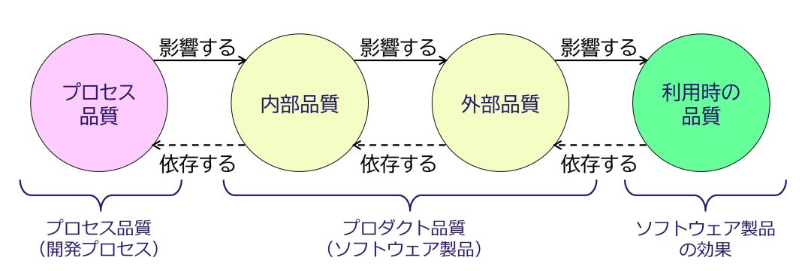
重要な品質特性が定まらないうちの適応度関数の導入は、目的のない計測となり、労力の無駄やチームの混乱を招くため避けるべきです。
【グッドハートの法則】の通り、木磯久が目的化しやすいです。
適応度関数の導入は、ビジネス価値に直結する重要な品質特性が特定・合意された後に行うのが最も効果的です。
フェーズ1:品質特性の発見と優先順位付け (仮説構築)
この段階が、
マーケティングの役割をするPdMさんやマーケターと利用時品質で重要なものを握り、そこから外部品質をアブダクションする
フェーズに相当します。
目的
ビジネスゴール達成のために、どの品質がなぜ重要なのかを明確にする。
活動
・ビジネス・プロダクトの目標(例: 新規顧客獲得率向上、解約率低下)を確認する。
・その目標から、重要な利用時品質(例: 満足度、効率性)を特定する。
・利用時品質から、それを実現するために必要な外部品質(例:パフォーマンス、セキュリティ、使いやすさ)を仮説として導き出し、優先順位を付けます。
この時点での適応度関数
まだコードレベルの適応度関数は不要です。
まずは、ビジネスKPIや手動での評価指標を定義する程度に留めます。
フェーズ2:適応度関数の初期定義と導入 (ベースライン測定)
優先度の高い外部品質が1つか2つ定まった時点で、最初の適応度関数を導入します。
目的
最も重要な品質特性が劣化しないことを保証する仕組みを構築し、チームにコンセプトを浸透させる。
活動
・優先度1位の品質特性(例: レスポンスタイム)に対して、計測可能な具体的な指標と閾値を定義します。
(例:「商品一覧APIの応答時間は、95パーセンタイルで200ms未満であること」)
この段階での、閾値の設定は、どうしても仮説ベースにならざるを得ません。
・これを検証するシンプルなテストやスクリプトを作成します。
最初はCI/CDパイプラインに組み込まず、手動実行や開発者のローカル環境で実行するだけでも十分に価値があります。
ポイント
最初から閾値含め、完璧を目指さず、最もクリティカルな1点から始めることが重要です。
むしろ、あまりにも適応度関数があり過ぎても、アラートがうざく機能するだけで、デリバリーの際のノイズになるだけです。
フェーズ3:自動化と段階的な拡充 (継続的インテグレーション)
システムの開発が進み、チームが適応度関数の価値を実感し始めたら、自動化と対象の拡大を進めます。
目的
適応度関数による品質のチェックを自動化し、開発サイクルの中で品質の劣化を即座に検知できるようにする。
活動
・作成した適応度関数をCI/CDパイプラインに組み込み、コミットやビルドのたびに自動実行します。
・優先順位の高い他の品質特性についても、順次、新たな適応度関数を追加していきます。
・アーキテクチャの原則(例: 「特定のレイヤーから別のレイヤーへの依存は禁止」)をチェックする静的解析ベースの適応度関数なども導入します。
ここまでの注意点のおさらい
適応度関数は
アーキテクチャの進化を導くガードレール
です。
どの方向に進化すべきか(=どの品質特性が重要か)が非機能要求として決まっていなければ、ガードレールを設置しようがありません。
ビジネス価値の議論 → 品質の優先順位付け → 最も重要なものから適応度関数を段階的に導入
という流れは、アーキテクチャをビジネスの成功に結びつけるための実践的アプローチです。
トレードオフへのセーフティネット
重要な品質特性のトレードオフになるような品質特性に対しても、実際のプロジェクトでは、完全に無視することはできないことの方が多いのではないでしょうか?
そういった時に、
「確かにこのトレードオフ項目は優先度が低いものの、この指標ラインは最低限満たしたい」
という水準がある際に、
最低限の水準(下限値)を保証するための適応度関数
として実装することは、非常に有効な戦略です。
なぜ「下限値保証」が重要なのか?
これは、アーキテクチャのガードレールやセーフティネットとして機能します。
優先度の高い品質特性(例:パフォーマンス)を追求するあまり、トレードオフとなる品質特性(例:保守性)が、許容できないレベルまで劣化することを防ぐためです。
チームは、このガードレールの範囲内で、安心して優先度の高い目標に集中できます。
例1:パフォーマンス vs 保守性
優先事項
APIのレスポンスタイムを極限まで高めること(パフォーマンス)。
トレードオフ
コードの複雑化(保守性の低下)
ガードレール適応度関数
「メソッドのサイクロマティック複雑度は15を超えてはならない」
「特定の重要モジュールのコードカバレッジは80%を下回ってはならない」
これらの適応度関数は、保守性を「最高にする」のが目的ではありません。
開発者がパフォーマンスチューニングに熱中するあまり、
将来の修正が困難になるほど複雑なコードを生み出してしまうのを防ぐ
ことが目的です。
例2:開発速度 vs セキュリティ
優先事項
新機能を素早く市場に投入すること(開発速度)。
トレードオフ
セキュリティチェックの簡略化
ガードレール適応度関数
「重大な脆弱性(Criticalレベル)を持つライブラリを検知したらビルドを失敗させる」
これは、世界で最も安全なシステムを目指すものではありません。
しかし、開発速度を優先するあまり、既知の致命的なセキュリティホールをシステムに埋め込んでしまうという最悪の事態を自動的に防ぎます。
トレードオフの適応度関数との組み合わせ
優先度の高い特性を「最大化(あるいは最適化)する適応度関数」と、トレードオフになる特性の「下限を保証する適応度関数」を組み合わせることで、アーキテクチャは明確な意図を持って、バランスを保ちながら進化していくことができます。
たとえば、パフォーマンスと保守性の両方のバランスを取るための適応度関数の実装は、
「独立した2つのチェックポイントをAND条件で強制する」
形になります。
単一の複雑な関数で「バランススコア」を算出するのではなく、CI/CDパイプラインのような自動化されたプロセスの中に、それぞれの品質特性に対する関門を個別に設けます。
実装シナリオとして、
開発者が「商品一覧API」のパフォーマンスを改善するコードを実装し、リポジトリにプッシュした場合を例に見てみましょう。
CI/CDパイプラインは、以下の2つの適応度関数を両方とも実行します。
1. パフォーマンス適応度関数 🚀
目的
APIのレスポンスタイムが規定の目標値をクリアしていることを保証する。
実装
パフォーマンス測定ツール(例: k6, JMeter)を使い、ビルドプロセスの一部として自動的に負荷テストを実行します。
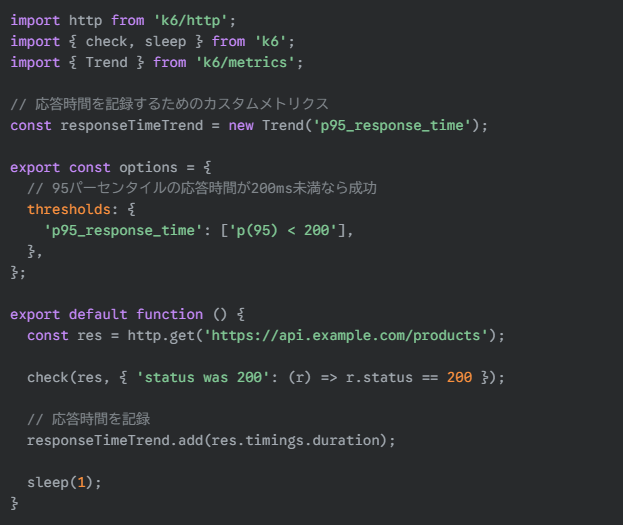
このテストは、CI/CDパイプライン上で実行され、p(95)の応答時間が200msを超えた場合、パイプラインは失敗します。
2. 保守性適応度関数 🛠️
目的
コードの複雑さが一定の基準を超えていないことを保証する。
実装
静的コード解析ツール(例: SonarQube, linterのプラグイン)を使い、コードの複雑度を計測します。
SonarQubeを使った設定の例
SonarQubeのクオリティゲート機能で、以下のようなルールを設定します。
・ルール1:新規コードのサイクロマティック複雑度が15より大きいメソッドが存在する場合、ビルドをERROR(失敗)とする。
・ルール2:新規コードの重複率が3%を超える場合、ビルドをERROR(失敗)とする。
これらのルールは、コードがリポジトリにマージされる前に自動的にチェックされ、違反があればパイプラインは失敗します。
CI/CDパイプラインにおける「バランス」の実現
開発者がプッシュしたコードは、以下のパイプラインを通過する必要があります。
①. コードプッシュ
②. ユニットテスト
③. 静的解析 (保守性チェック) 🛠️
[結果] 複雑度が15を超えるメソッドあり ❌ → パイプライン失敗
④. 負荷テスト (パフォーマンスチェック) 🚀
[結果] 応答時間が200msを超過 ❌ → パイプライン失敗
⑤. マージ / デプロイ ✅
この仕組みにより、開発者は両方の関門をクリアするコードを書かざるを得なくなります。
パフォーマンスを追求するために複雑すぎるコードを書けば、保守性のチェックで失敗します。
コードをシンプルに保った結果、パフォーマンス目標を達成できなければ、パフォーマンスのチェックで失敗します。
このように、適応度関数は 「AかつBを満たさなければならない」 という制約をコードで表現することで、アーキテクトが意図したトレードオフのバランスを開発プロセスの中に強制します。