背景
カオスエンジニアリング勉強会のメンバーや
ドメイン駆動設計をはじめようを一緒にやってきたアーキテクト仲間と、
改めてサーガパターンの理解や、それに伴うビジネスモデルの変化
ガバナンス構造の変化の理解を深めるために、
3度目のソフトウェアアーキテクチャハードパーツの勉強会をやりました。

今回は、この本の中で以下の章に絞ってワークをやってきました。
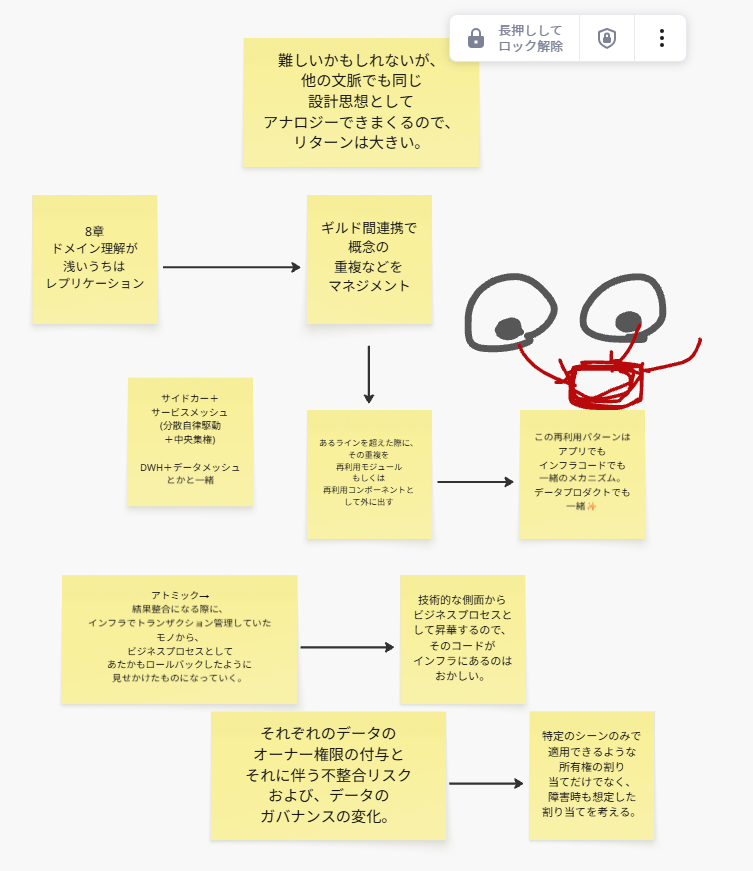
8章:再利用パターン
9章:データの所有権と分散トランザクション
発見
自分では、無意識にやってしまっていた設計手法ですが、
改めて人に説明している中で、「あ、これ言語化大事だな」と思えたことは、
以下の3つです。
業務理解が浅いうちからのコード再利用はやめて、
一旦は意図的な重複(コードレプリケート)を許容する。
中央集権的なSREから、自律分散型+中央司令塔へ
ER図の点線で、データの境界を表現する。
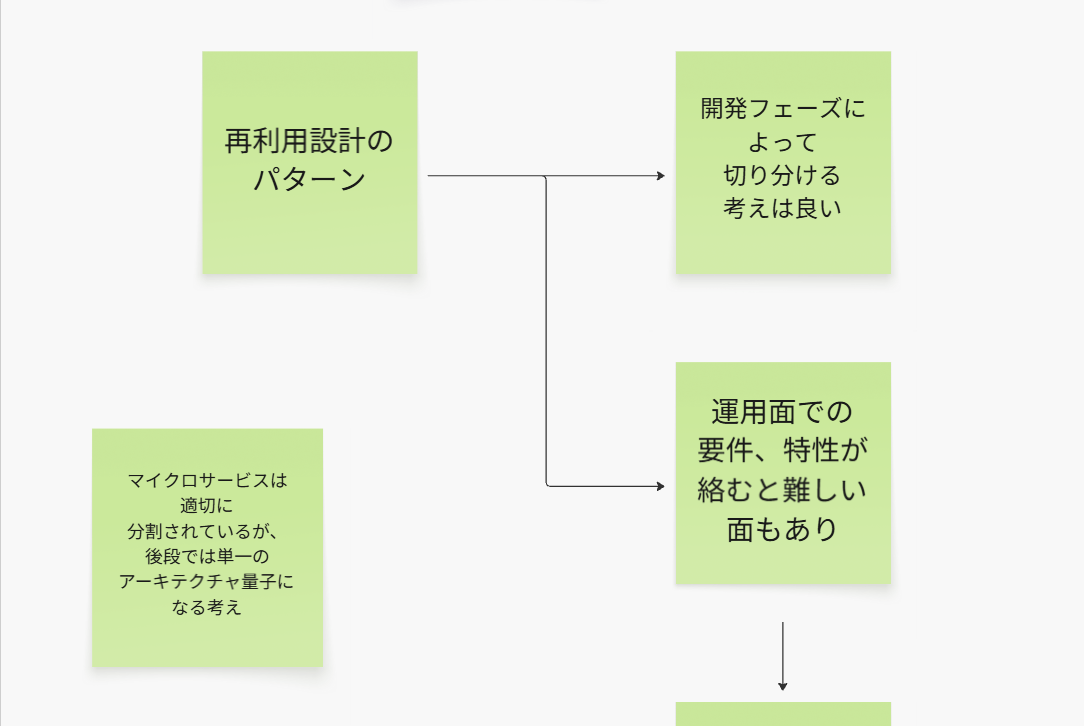
再利用パターン
まずは、再利用パターンから。
この章では、アプリケーションコード上の再利用パターンとして
大きく共有ライブラリと共有サービスに触れられていますが、
その導入として、レプリケーションパターンについて触れられています。
よくある設計思想として、
DRY原則に従い、重複を避けよ 一か所にまとめるべきだ
というものがありますが、あれは1つ気を付けないといけません。
概念の重複は初期から発見できない
今回のワークでも、私は以下のようにボードに書かせてもらいました。
モジュラーモノリスでの事例
たとえば、サービスを立ち上げた当初や、業務理解がまだ深くはない場合、
以下のようなモジュラーモノリスの各モジュールにある重複したコード(赤付箋部分)
が、概念として完璧に同じと、どうやって判断できますか?
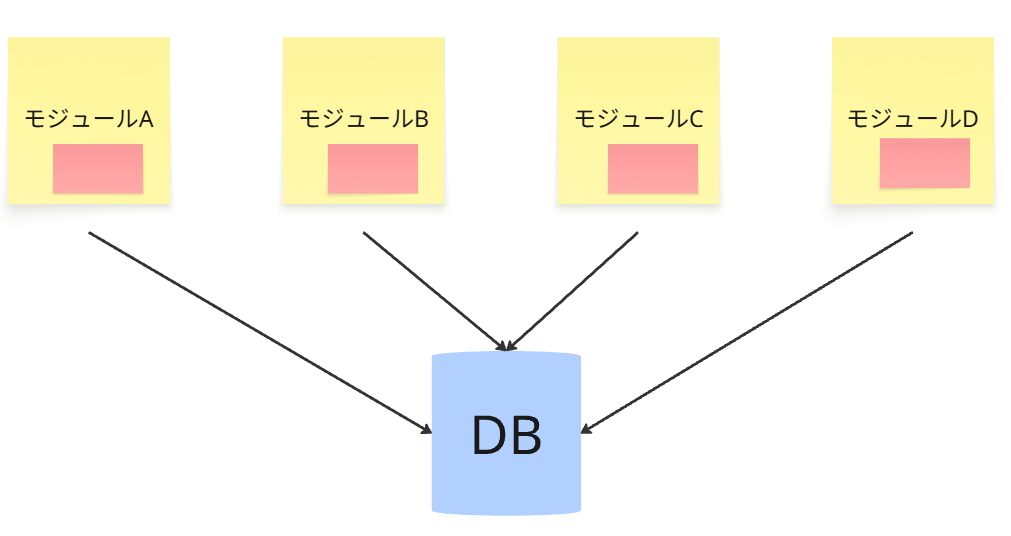
もしかしたら、同じに見えて
・それぞれ、事前条件や事後条件・不変条件が微妙に異なる。
・契約は一緒であるものの、変更理由やタイミングが微妙に異なる。
などの理由があるかもしれません。
マイクロサービスでの事例
マイクロサービスでの場合にも同様です。
下図の重複した赤い部分のモジュールが、
・契約の内容
・変更理由やタイミング
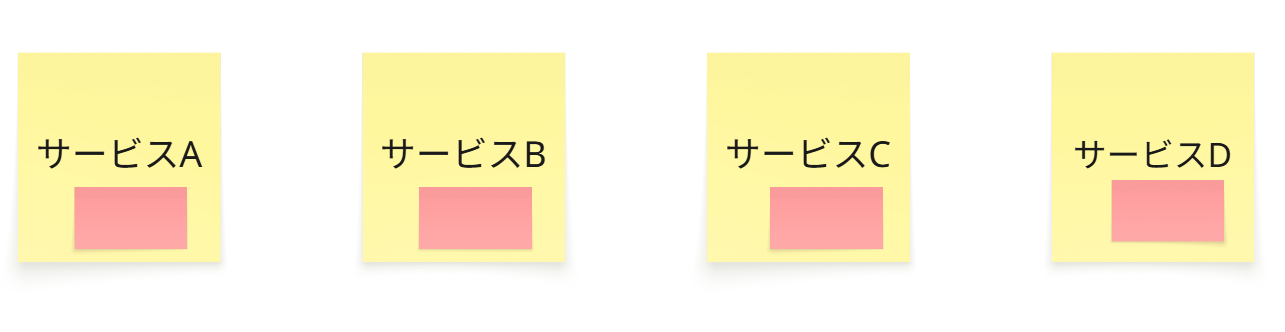
それ以外にも、
・スケーラビリティやセキュリティ水準などの非機能側面
が若干異なるかもしれません。
早期からの再利用は危険
にもかかわらず、早期から
「あ! ここもここもコードが似ているから1つにまとめよう!」という浅はかな考えは、
実は、個別ごとにセキュリティ水準が違ったことが判明してしまい、
再利用として1つにまとめてしまった後だと、もっとも強いセキュリティのサービス要件に合わせないといけないかもしれません。
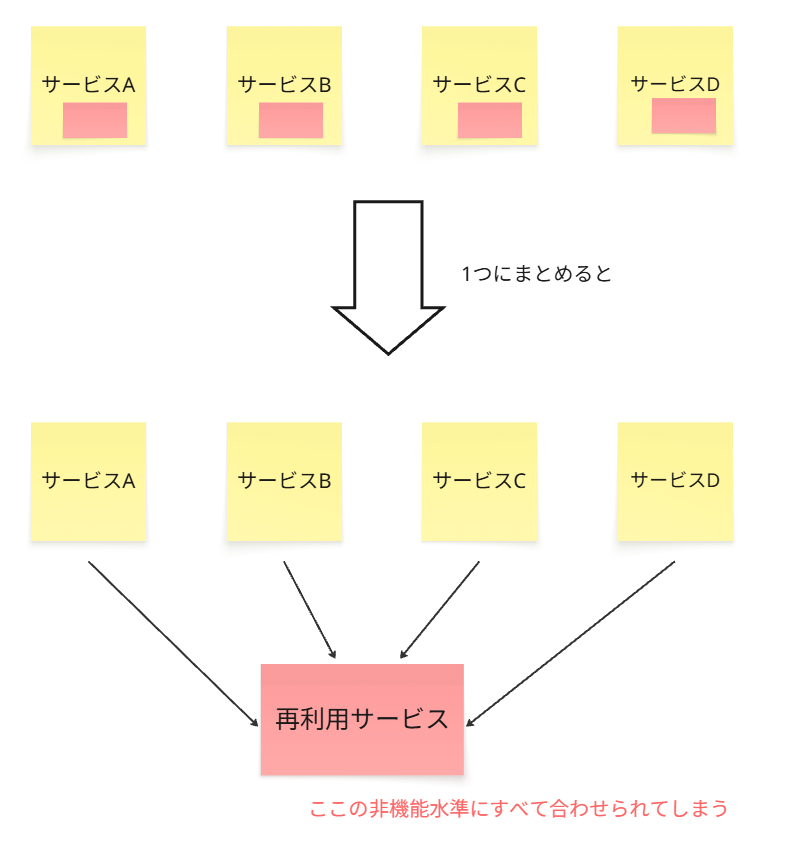
でもそうすると、セキュリティレベルの低くても良かったサービスは、
その不要な強さのセキュリティを満たすために、どうしてもレイテンシーが大きくなり、
UX低下を確実に招きます。
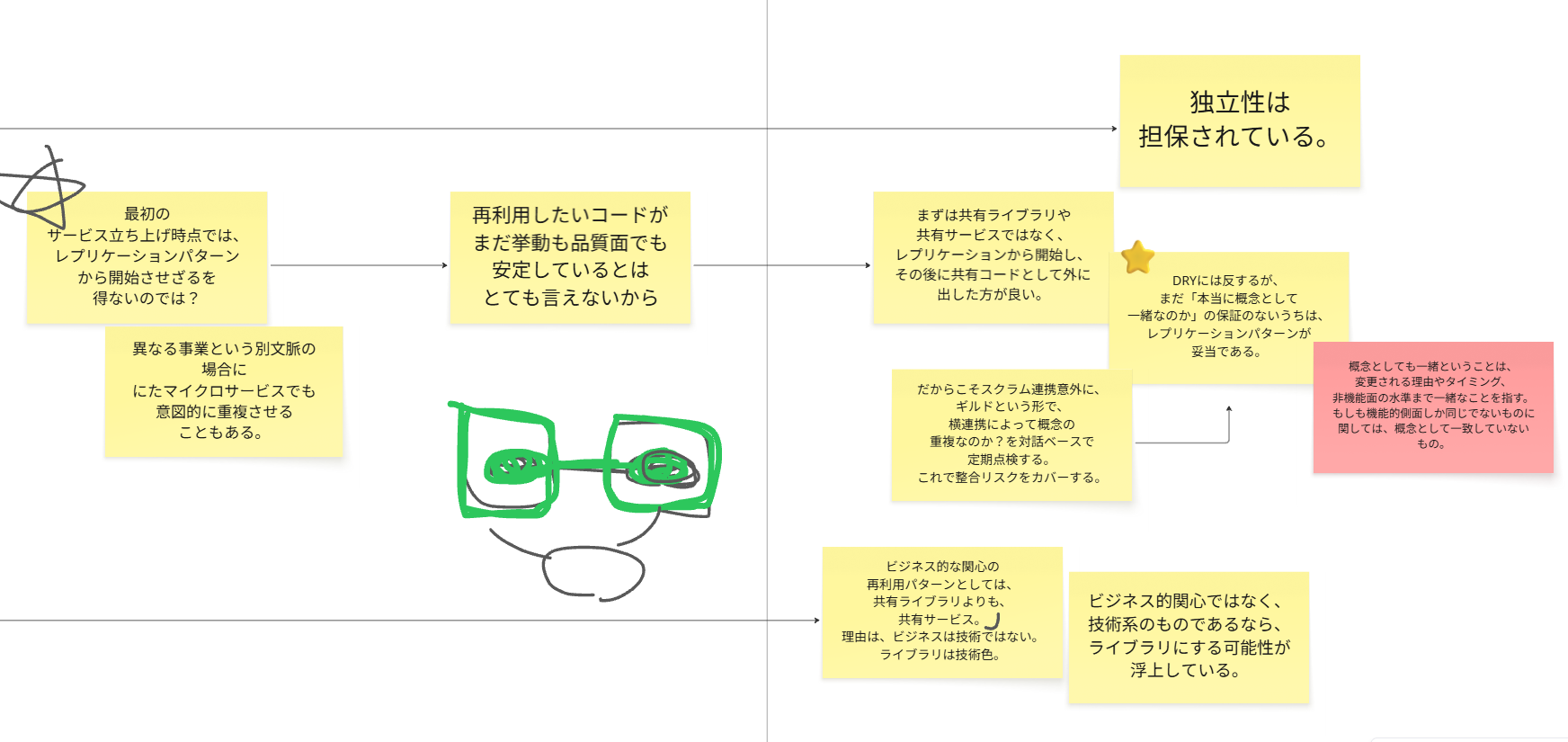
打開策 -ギルド連携-
上記などの理由によって、私のオススメは、事業理解の浅いうちは下手に再利用を進めないことです。
つまり、意図的にコードの重複を認めるのです。
そして、保守運用フェーズで継続的にチェックをします。
その際に、チーム間のコミュニケーションパスのデザインが重要です。
ギルドで横のつながりで、コミュニケーションという運用でカバーする
ギルドとは、単に仲良しこよししているだけではなく、
以下の明確な意図をもってして、コミュニケーションしなくてはいけません。
業務ロジックコードだったり、横断関心事のコードや、
インフラコードの重複の有無を探し続ける
・ビジネスチームのギルド連携 >> ビジネスロジック上の重複チェック
・アプリケーションエンジニアのギルド連携 >> アプリコードの重複チェック
・データベースチームのギルド連携 >> テーブルの重複チェック
・インフラやSREチームのギルド連携 >> インフラコードの重複チェック
というように、それぞれの関心ごとのコードや運用プロセスの概念重複を発見します。
もちろん、永遠にやる訳にもいかないので、事前に
この水準に到達したら、再利用によるデメリットがあっても許容して、
1つの共有コンポーネントとしてまとめる
という水準を設けておきましょう。
※ 絶対にやってほしいこと-関係性づくり-
この時に、横の連携によって、人間関係が劣化してしまうと、
本来は再利用としてまとめるべきものだったコードが、以下のようになりかねません。
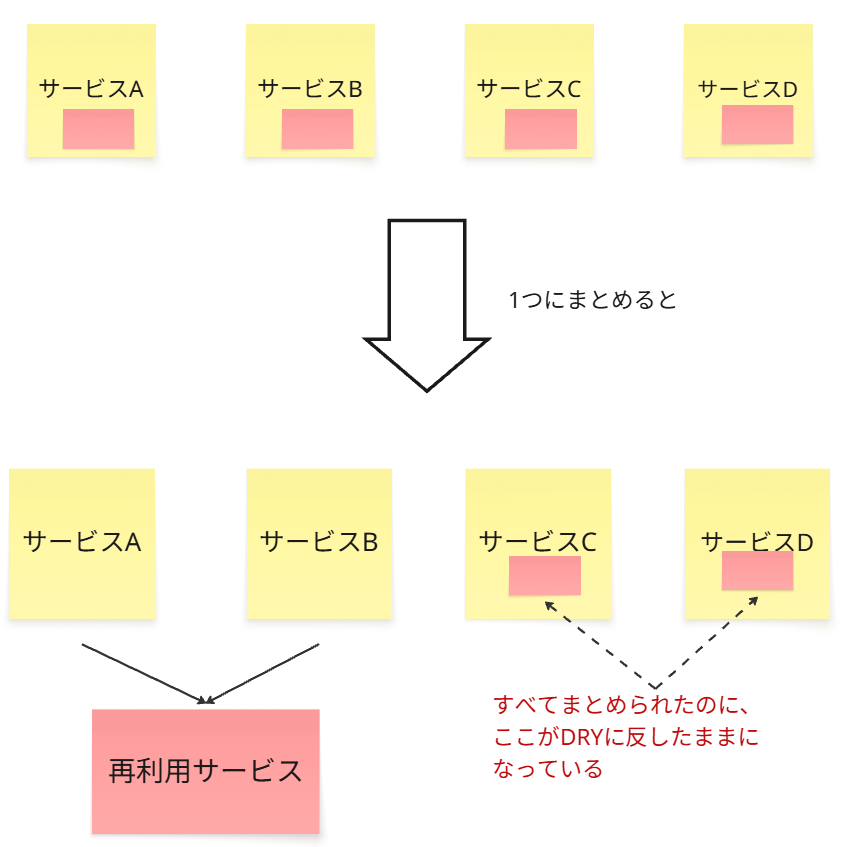
実は、4つのサービス内の重複コードが一か所にまとめられるのに、
関係性が悪いと、図のようにサービスCとD部分がDRYに反した状態となり、
このままでは、再利用サービス部分のコードが仮に変更されるとなった場合に、
サービスC・Dへの調整コストが発生し、さらにサービスABと C・Dとの関係が悪化し、
コミュニケーション構造の分断
が起きたままになってしまいます。
そのため、この横の連携というギルド活動は、あくまでも横の島との対話が促進されるようなファシリテーター同席のもとで、良好な関係性構築に努めてください。
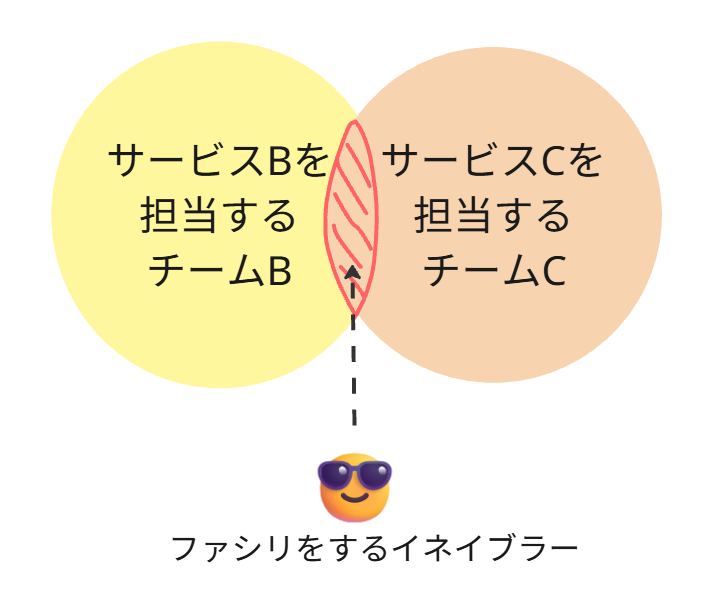
図の赤い斜線部分が、重複している可能性のあると思われるコードです。
もしも、その継続的なギルドミーティングの中で、概念重複していないことが判明したら、
チームBC間の連携は、XaaS連携に切り替えて、BとCの重複していると思われたコードは、独立して運用することになります。
大事なマインド
この時に忘れないでほしい大事なことは、
DRYに反したらいけないということではなく、
「DRYに反している可能性がある」ということを認知でいていることが重要
ということです。
反しているかもしれないというリスクの軽減策として、
上記で触れたように、ギルドという横の連携活動という運用活動を通して、
概念上の重複なのか? それともたまたま似ているだけなのか?
を浮き彫りにするのです。
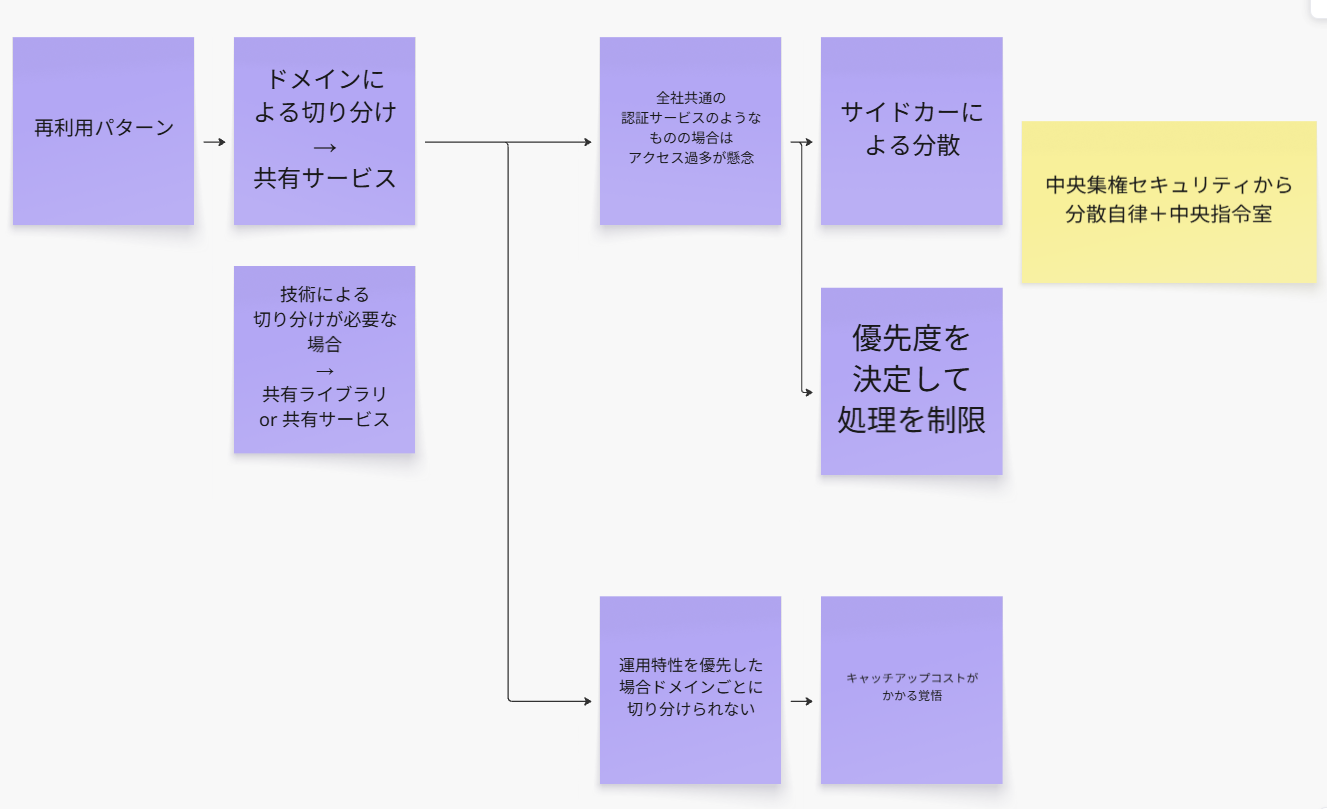
共有サービスか共有ライブラリか
ちょっと上記の図で、再利用サービスっていう風に名前が一致していないのは、気にせんでください。
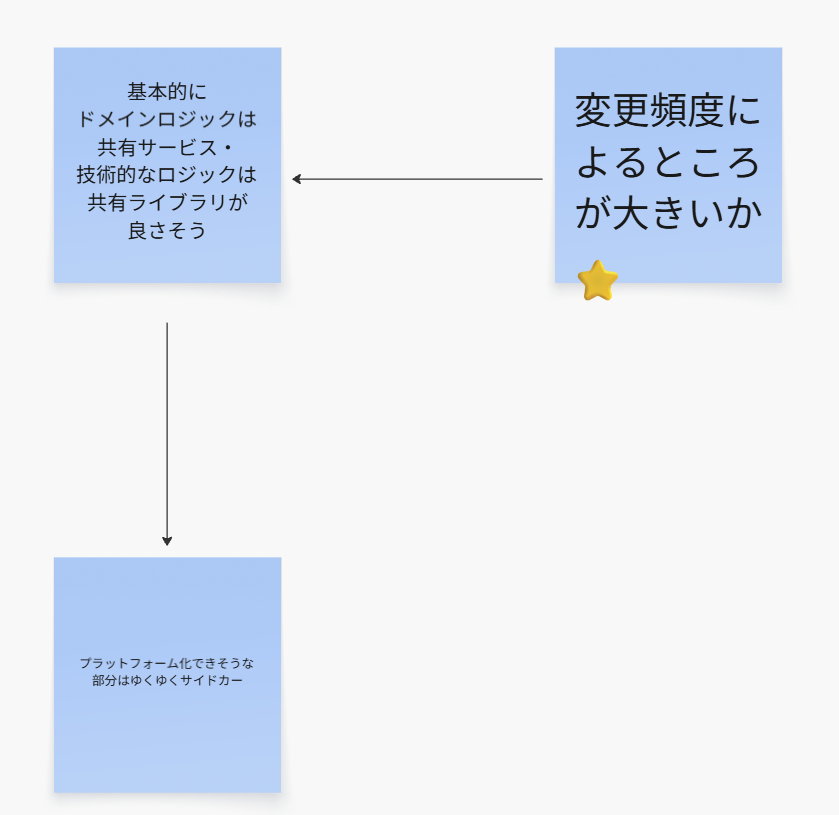
ここでの章では、共有ライブラリか共有サービスかの判断が章末トピックで触れられていますが、そもそもビジネスロジックなどのビジネス上の関心事は、共有ライブラリではなく、共有サービスを選んでください。
それは、そもそも共有ライブラリがコンパイル時に静的にバインドしているのに対して、
共有サービスに関しては、後から動的に連携するからです。

この特性の大きな違いがあるから、ビジネス的なことは絶対に共有サービス。
ビジネスのアーキテクチャの特性と、ITアーキテクチャの非機能面の特性を一貫させるためにも。
技術的なことに関しては、極力より難易度の低い共有ライブラリを選ぶというのが無難です。(※もちろん、技術的なことで共有サービスを選ぶことはあります。)
共有ライブラリ
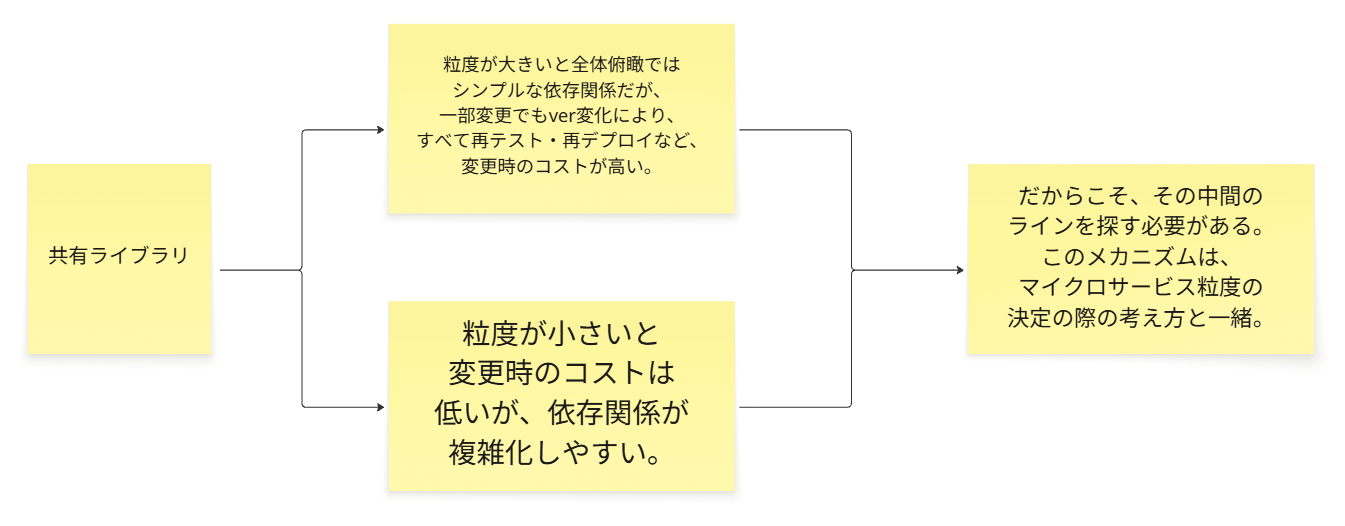
上記の記事でも触れていますが、共有ライブラリパターンでは、
粒度感が大きすぎても依存関係がシンプルですが変更時に大変
小さすぎても変更時コストは抑えられても依存関係がクモの巣状態で複雑化
バージョン管理が複雑化しやすい
などの課題が付きまといます。
ただし、共有サービスと違って、
コンパイル時に静的に結合させる感じなので、動作させてから問題が起きる
という共有サービスのような問題がないこと
は最大の恩恵だと感じます。
これが理由なので、技術的なことは迷ったら一旦共有ライブラリにしておくのが無難。
共有サービス
こちらは、共有ライブラリと違って、ネットワーク通信を介しての結合です。
なので、動作をさせてから問題が浮き彫りになるという不確定要素はあるのですが、
共有ライブラリと違って、デプロイまでのフローのコストは低く抑えられます。
さらに、下図のように同期通信ですと、デプロイする際に、
結局インフラ部分で蜜結合状態なので、共有サービスの恩恵はあまりないです。
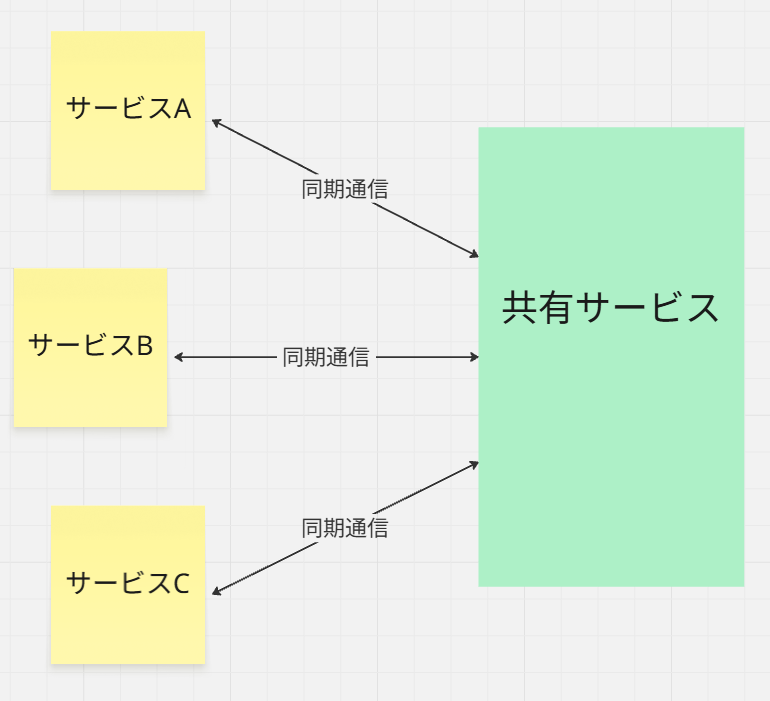
共有サービスを選定するような場合には、非同期が前提と思ってください。
同期通信が必須な場合には、技術的な関心のものなら、迷わずに共有ライブラリを選んでもいいと言っても過言ではないです。
(もちろん、時間経過で共有サービスにすることはありえます。)
レイテンシー問題
共有ライブラリと違って、通信を介して繋がるので、絶対にレイテンシーによるUX低下は避けられない問題です。
セキュリティ問題
共有サービスパターンにした場合には、下図のように共有サービスを使う側の
サービスを増やしていくとなった場合には、そこが新たな脆弱ポイントになります。
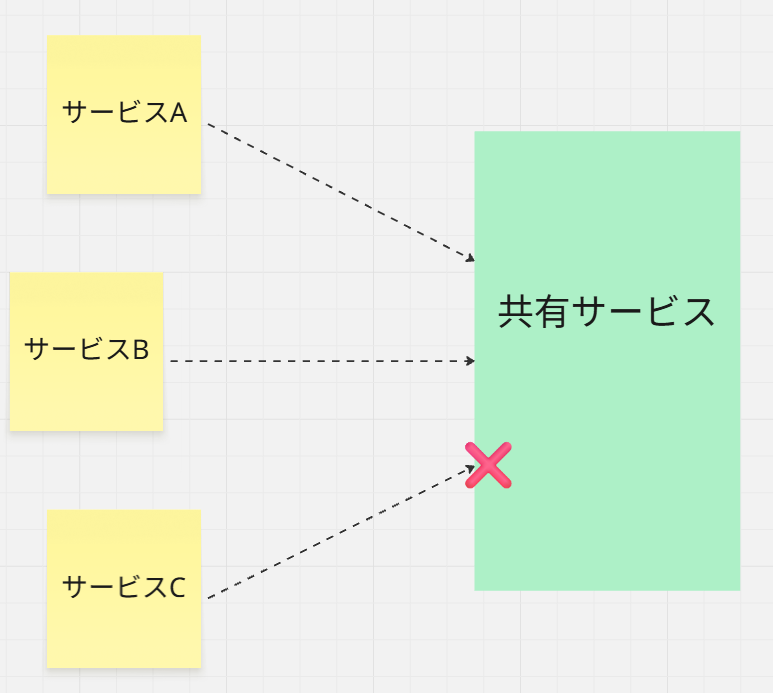
そこを防ぐために、セキュリティチェックをするとなると、今度はその処理が理由で、
どうしてもセキュリティレイテンシーが発生してしまう。
競合リスク
たとえば、以下の図のように同期通信でつながっていた場合には、競合リスクは避けられない問題です。
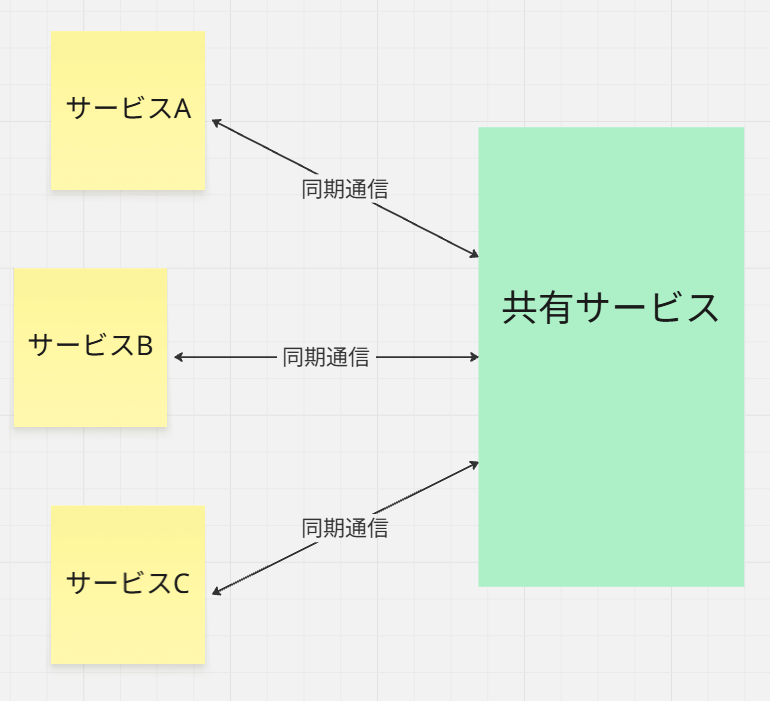
この辺のどの処理を優先的に処理させるのか?といったCCPM的に考えて、
順番をコントロールしたりする手間暇は、複雑度が共有ライブラリと違って、一気に増します。
耐障害性
仮に共有サービスと非同期通信でつながっていたとしても、インシデント発生時に爆発に巻き込まれない保証はありません。
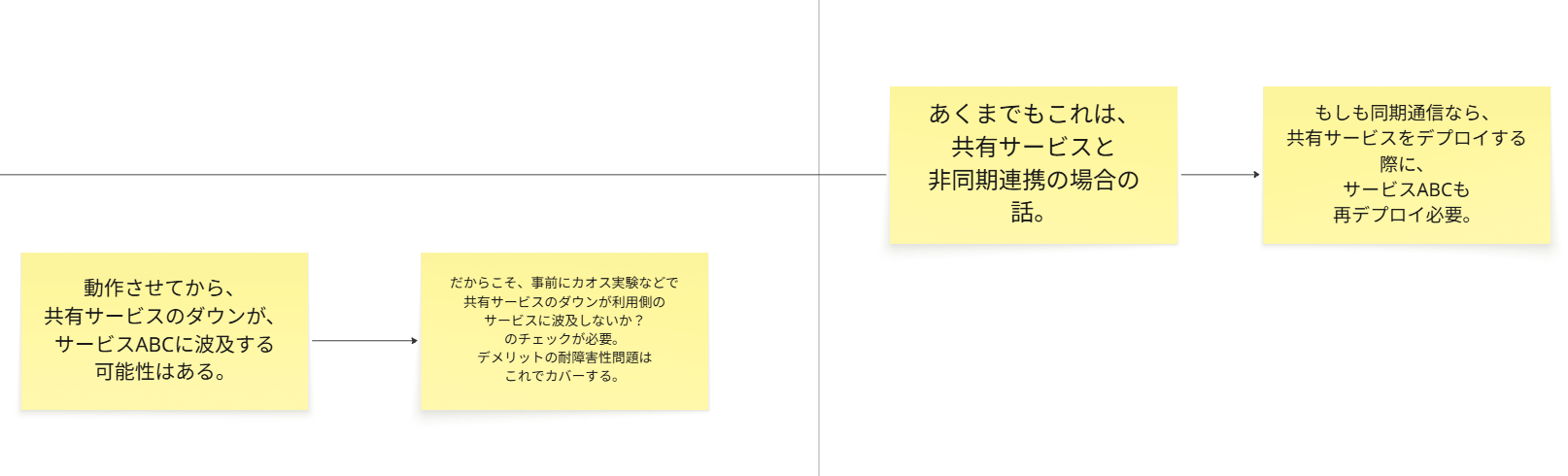
共有サービスをステージング環境でダウンさせるなどといったカオス実験によって、
本当にコンシューマー側のサービスがダウンするなどの影響を受けないのか?をチェックする必要もあります。
サービスメッシュがないと大変
また、共有ライブラリと違って、より疎結合だからという理由で、共有サービスを変更した場合に、動的に共有サービスのAPIエンドポイントのバージョンがコロコロと変わります。
その際の、コンシューマーサービス側との調整コストが高く付くんじゃ、そもそもサービスとして切り出す価値は低いです。
変更時の調整コスト含むリスクを抑制させるには、どうしても後述のサービスメッシュのような仕組みがないと太刀打ちできないです。
どっちのパターンにも共通すること
再利用コンポーネントの粒度感
上記でも触れましたが、共有サービスでも共有ライブラリでも、そのコンポーネントの粒度感は、大きすぎてもダメだし、小さすぎてもダメです。
個々のコンポーネントと、全体をマネジメントする人目線でのマネジメントコスト、
その両方のバランスのいい所を探しましょう。
再利用系の凝集原則


クリーンアーキテクチャ本や、ひさてるさんのちょうぜつ本に書かれた、
コンポーネントの凝集原則3つのうちの再利用系のまとめ方の2つの原則をまとめ方の参考にするといいです。
ただし、ある特定の品質特性軸のみでのコンポーネントの大きさの判断にならないようにしてください。
必ず、複数のステークホルダーにとっての重要な関心事である品質特性軸から
レーダーチャートのように多角的に評価してくださいね。
中央集権からの脱却
この再利用パターンの中で、よく見かける中央集権型のセキュリティサービスのお話をしました。
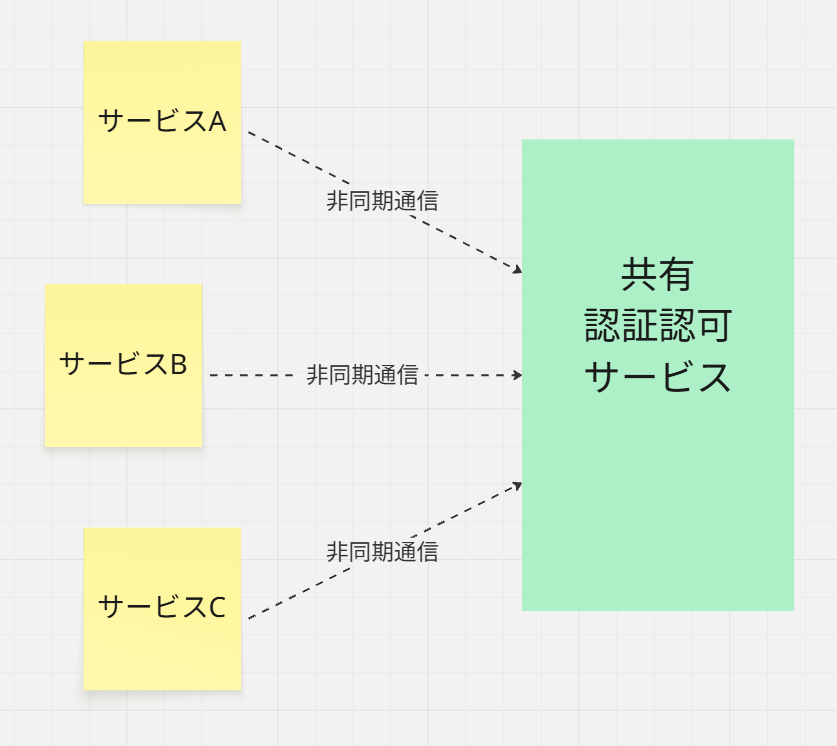
✅中央集権セキュリティによるメリット
確かにこの手法は、以下のような恩恵はあります。
各マイクロサービスごとにセキュリティ機能を用意しなくていい
それによる、セキュリティ機能のDRY破りによる不整合問題
各サービス開発チームは少しでも負荷を軽減し、開発に専念しやすい
このあたりは、上記で触れたような通常のコードへのDRY原則の考え方と全く一緒です。
だから、この本でも、再利用パターンの所に持ってきたんでしょうね。
中央集権型のみでのデメリット
中央集権のセキュリティマネジメント体制だと、どうしても以下のデメリットが避けて通れません。
各サービスチームのセキュリティへの意識が向きにくい
セキュリティチームとの分断が起きやすい
その結果、デリバリーの足かせになるようなセキュリティという関係になり、
更に分断の亀裂が深くなるという負の循環
すべてのサービスを同じセキュリティレベルに合わすという制約がある
自律分散型+中央司令塔のセキュリティ
詳しくは別の記事でも書いていますが、セキュリティの成熟度を上げていくために、
中央集権型のみの体制から、徐々にセキュリティアーキテクチャも変えていきましょう。
横から見た図
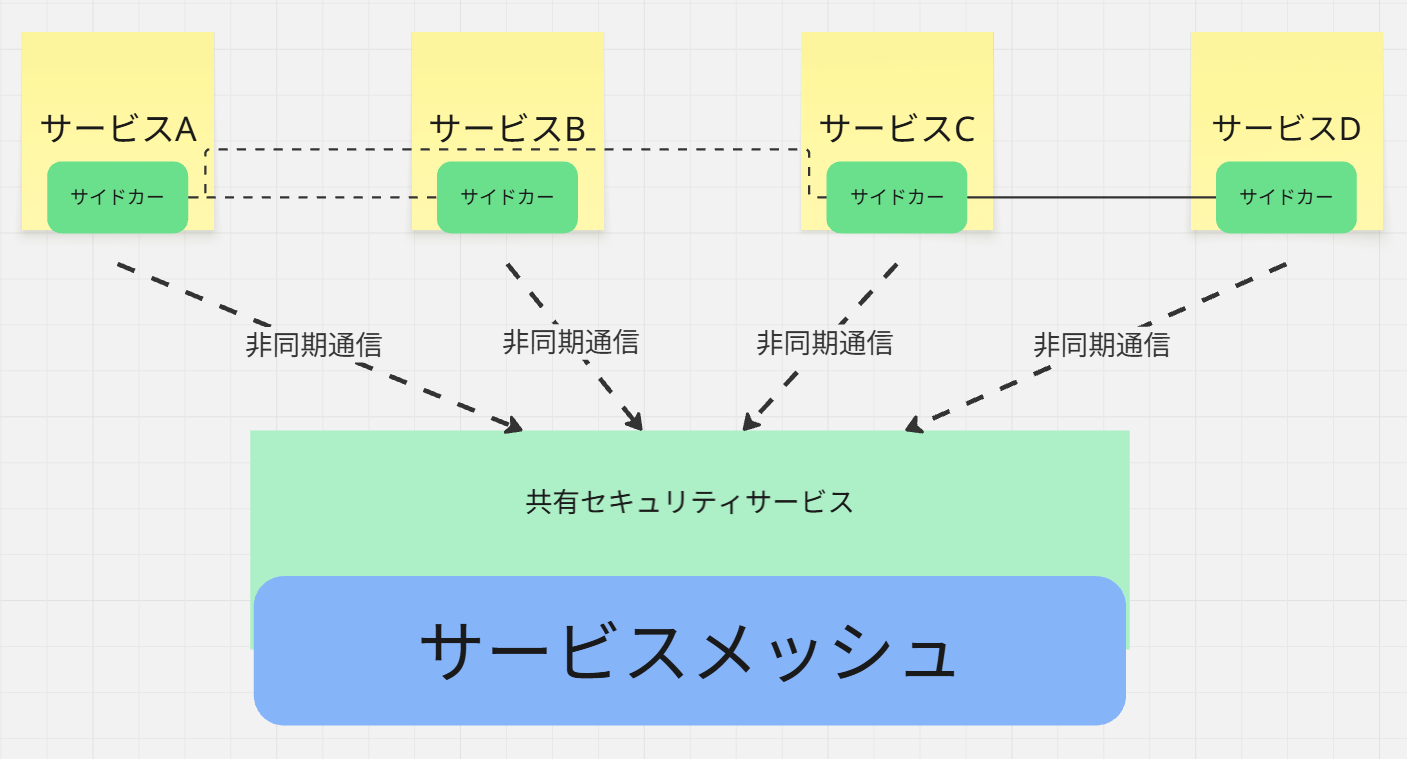
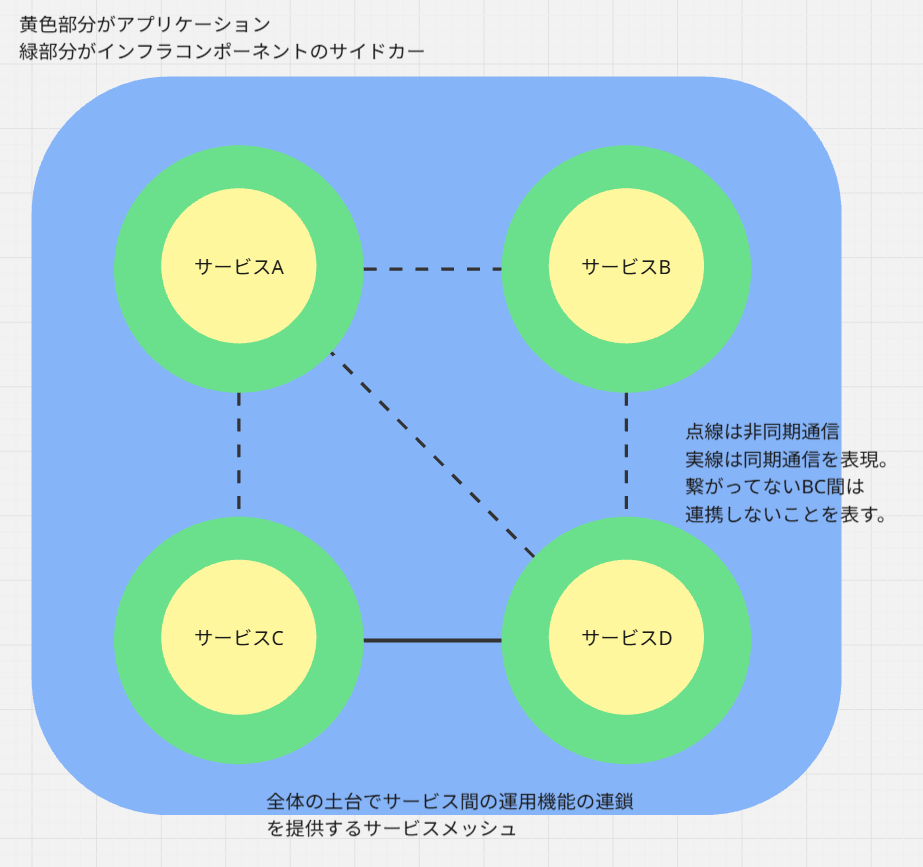
真上から見たアーキテクチャ図
色は上の図のものと対応付けています。
データドメインパターン
9章のデータ所有権の割り当て、ココはいつも私が悩んでいたところです。
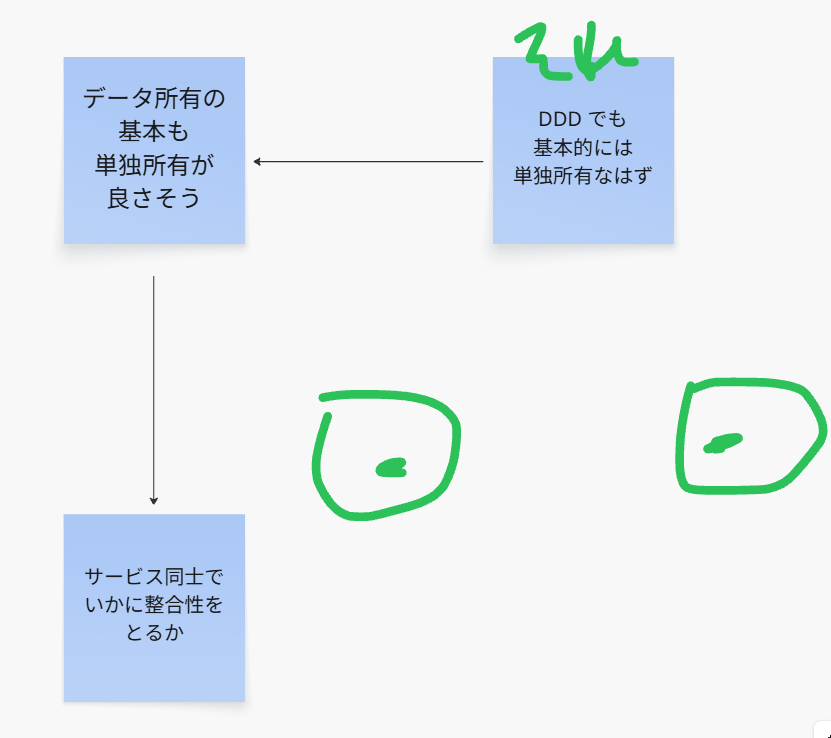
マイクロサービスの際に重要なのは、テーブルの所有者であるサービスは、
1つに絞り込む
という大原則があります。
しかし、このデータドメインパターンは、以下のような構図になっています。
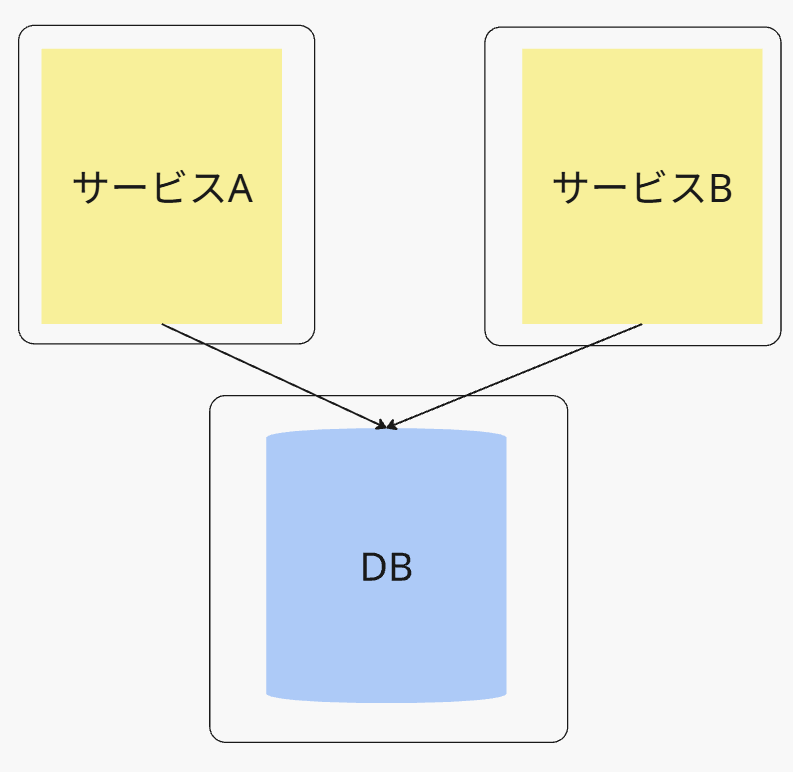
詳しくは、以下の記事を参照ください。
データドメインパターンと少し違うものの、似たアプローチにコンソリデーション?
というものがあります。
サービスコンソリデーション
サービスコンソリデーションの構造は以下の図の通りです。
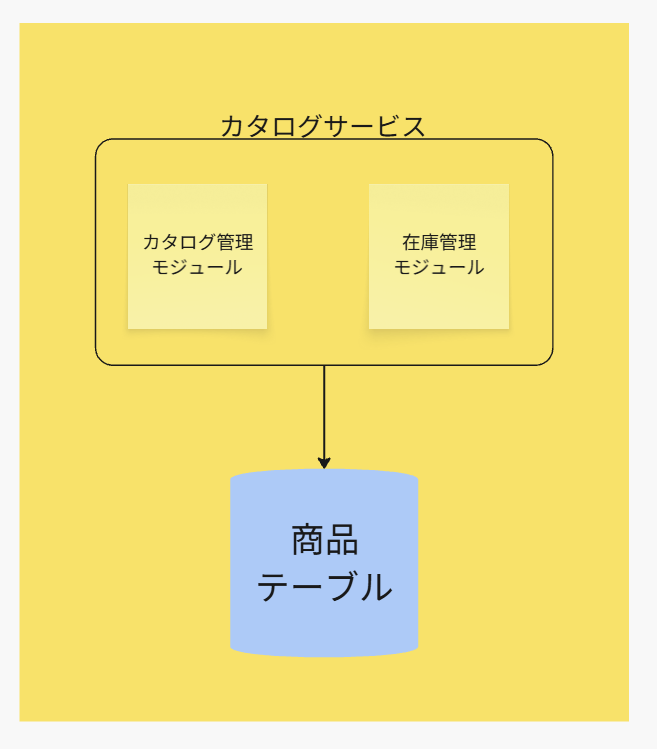
サービスコンソリデーションとデータドメインの共通点
データドメインパターンも、このサービスコンソリデーションもどちらも、
データの所有権の割当先をどっちにしたらいいか不明なので、一時的にとる手法。
という点は一緒です。
サービスコンソリデーションとデータドメインの異なる点
ただし、明確に違うのは、サービスコンソリデーションの方は、
どうしてもアプリケーションチームで、
カタログ管理モジュールの方だけスケーラビリティを上げたい
といった柔軟な設計ができない。さらに、
カタログ管理モジュールチームと在庫管理モジュールチームは、
どうしても密なコミュニケーションが求められる
という特徴があります。
つまり、書籍「ドメイン駆動設計をはじめよう」の文脈で言うと、
良きパートナーの関係性を求められる
ということです。
かりに、両チームの関係性が良いのなら問題ないので、このサービスコンソリデーションは有力な候補となりますが、現実にはそうもいきません。
無理やり関係性の悪いチームに、このサービスコンソリデーションの連携を強いた結果、データの所有権争いが起きかねません。
それは、さらなる不健全なコミュニケーションの分断となります。
データドメインパターンがうまくフィットするようなケース
ここからは私の経験談も踏まえた上で、どのようなケースでデータドメインパターンがフィットするかを書いていきます。
メインの論点は、「どのような政治的背景がある際に適すか?」にフォーカスします。
結論から話すと、下図のように設計案を考えた際に、
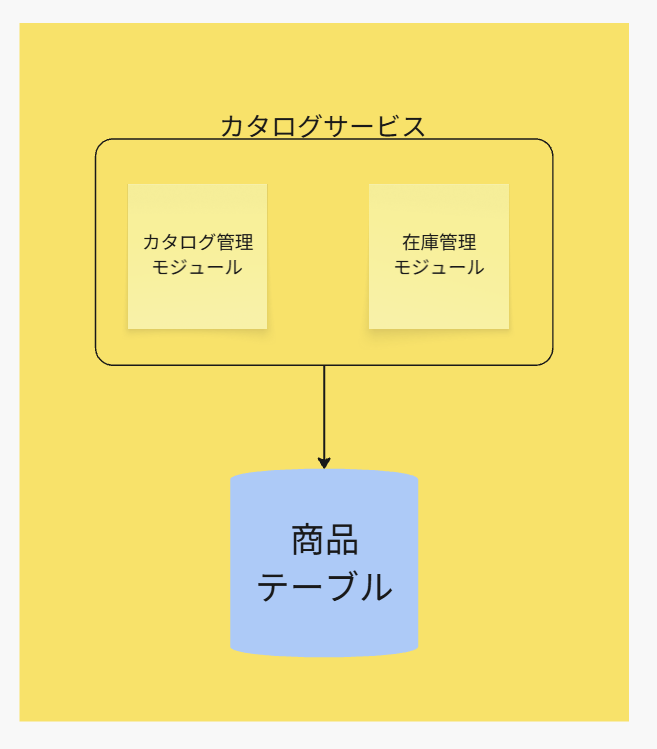
所有権の割り当てができる状態ではない
かつ
2つのアプリケーションチーム、カタログモジュールと在庫モジュールを担当する開発チームが、とても仲が悪い
かつ
データベースエンジニア同士のコミュニケーションコストは比較的低い
かつ
データスキーマの変更やカラム列の変更は少ないと予測できる
という状況があったとします。
こんなときには、データドメインパターンを使った方が良い場面です。
なぜなら、モジュールチーム間のコミュニケーションコストを払わなくていい代わりに、
下図の青枠で囲った部分を担当するデータチームにその連携のコストを払わせる構図
だからです。
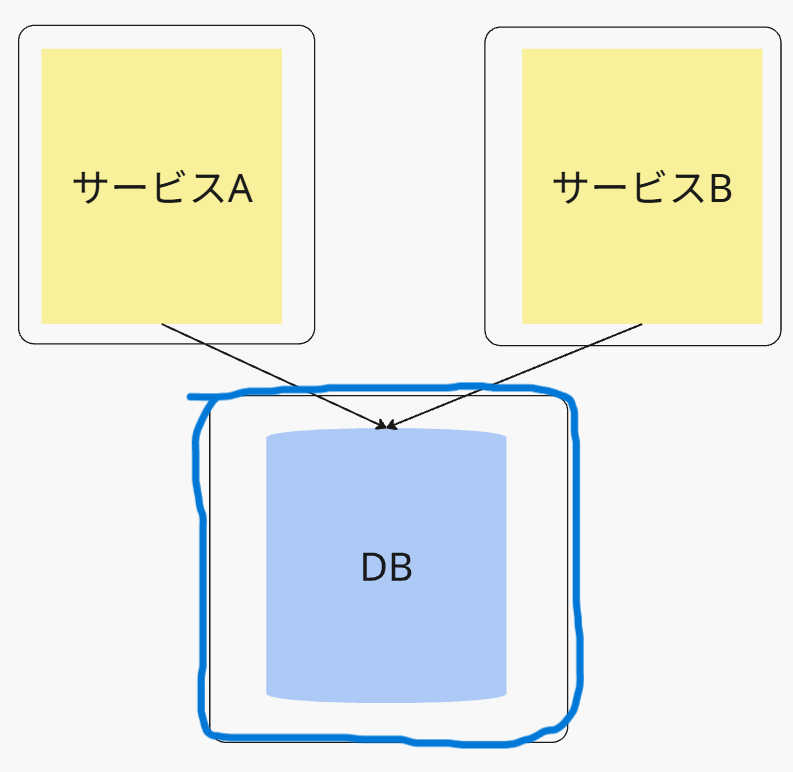
注意点
最終的には単独所有にさせる
このパターンはあくまでも、
1つのマイクロサービスへの単独所有をさせるための通過点
にすぎません。
あとあと、図のいずれか、もしくは新しいより所有者として適切な1つのサービスに、
そのオーナー権限を割り当てなくてはいけません。
データチームとの連携部分は同期通信にしておく
上記で書いたように、後々1つのオーナーに所有権を割り当てるので、
サービスとDBの間の連携は、非同期にしてはいけません。
そんなことしたら、オーナーはどっちがいいのか?の考察なんて、さらに困難を極めます。
さらに、サービスA・Bどちらかに割り当てた方が良いとなった際に、設計の修正も大変。
これすなわち、
コミュニケーション構造も非同期にしたらダメ
ということです。
調整役になれるか
ここがデータメッシュに進化させる前の方との明確な違いだと思います。
データメッシュを目指す前のデータ基盤とアプリケーション基盤との連携は、非同期でいいからです。
しかし、今回のサービスと業務データ担当との間は、
同期通信でないといけない。
そのため、データスキーマに仮に変更が生じてしまう場合には、データチームは、2つのサービスへの調整ファシリをしてあげないといけないでしょう。
振り返り
最後に、今回の勉強会での各個人のまとめの図を添付します。