前置き
データマネジメント系の本などを読んできて思ったのが、
「うん、データ品質が大事なのは分かったけど、じゃあ実際にどう具体的にデータ品質を見つけていくの?」ということが明確に描かれた本にはいまだ会うことができていません。
そこで、過去に自分なりにストーリーテリング方式を盛り込んで行ってみた手法に、カスタマイズを加えたプロセスを以下に紹介します。
データ品質具体化の思考プロセス
今回紹介するのは、データ品質を「単なる技術的指標」から「ビジネス価値(利用者の満足度)」へと結びつけるためのアプローチです。
この流れは、現代のデータマネジメントにおける重要なベストプラクティス(ストーリーテリング、GQM、リーン的アプローチ)を統合したものです。
1. ストーリーテリング (5W2H) → DFD
これは、データ品質を議論する上で最も重要な 「コンテキスト(文脈)の共有」 を行うステップです。ココをすっ飛ばして、定量的な話に行っても時間の無駄です。
なぜ重要か
多くのデータ品質の取り組みが失敗するのは、「誰が(Who)」「何のために(Why)」
そのデータを必要としているかを定義しないまま、いきなり「正確性100%」といった技術的目標(How)から入ってしまうためです。
効果
利用者目線でのストーリーを描くことで、
「この業務プロセス(DFDの流れ)において、このタイミングで、このデータが、このレベルの品質でないと困る」 という具体的な要求(=データアプリケーション属性)が初めて明確になります。
2. GQMストラクチャーによるアプリケーション属性の定義
GQMワークショップは、曖昧な「要求」を具体的な「ゴール(Goal)」に変換する、非常に強力なステップです。
GQM (Goal-Question-Metric)
・Goal
利用者のストーリーから抽出された「データアプリケーション属性」そのものです。
(例: 「マーケティング担当者が、タイムリーな意思決定をしたい」)
・Question
そのゴールを達成するために、何を問うべきか?(例: 「データはいつまでに必要なのか?」「どの程度信頼できれば良いか?」)
効果
利害関係者(利用者と提供者)がGQMの場で議論することで、「なんとなく信頼できない」といった主観的な不満が、「(Question)配信遅延が許容範囲を超えている」といった具体的な課題に変換されます。
3. ロジックブランチによるデータ属性への分解
ここが、ビジネス要求と技術的実装を接続する「翻訳」のステップです。
プロセス
GQMで定義された Goal/Question(例: 「データが信頼できること」)を達成するための要因を、ロジックブランチ(あるいは特性要因図)で深掘りします。
例
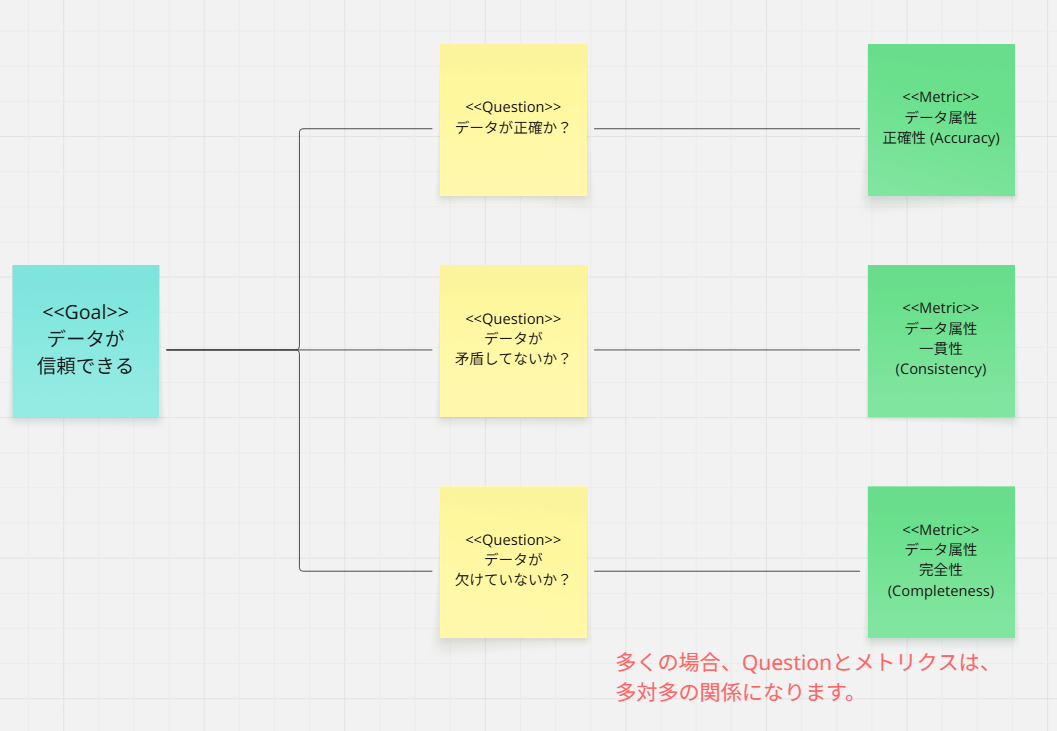
効果
これにより、
$$データアプリケーション属性 = f(正確性, 一貫性, 完全性, ...) $$
という関係性が明確にモデル化されます。
これはまさに、前回の記事でお話しした「適応度関数(加重平均モデル)」を構築するプロセスそのものです。
4. 第1次近似(微分)による仮説検証
ここが最も先進的かつリーン(効率的)な考え方です。
なぜ「近似」か
f(...) は、現実には非常に複雑な非線形関数かもしれません。
また、すべてのデータ属性(正確性、一貫性、完全性など)を一度に100点にするのは、コスト的・時間的に不可能です。
「第1次近似」の解釈
GQMでの議論に基づき、f(...) に最も強く影響する(=適応度関数の「重み $w$」が最も大きい)と仮説を立てたデータ属性を1つ選びます。(例: 正確性 が最も重要だろう)
アプリケーション属性 ≈ f(正確性のみ) とみなし、その「正確性」だけをわずかに改善 $\Delta S$ します。
「微分の考え方(フィードバック)」
そのわずかな改善 $\Delta S$(例: 正確性を80%→85%に向上)に対して、利用者の満足度(アプリケーション属性)がどれだけ向上 $\Delta App$ したかを 観測(フィードバック) します。
この $\Delta App / \Delta S$ が大きい(=費用対効果が高い)ことが検証できれば、仮説は正しかったと言えます。
5. 第2次近似へ
仮説が正しければ
「正確性」への改善投資を継続します(第2次近似)。
仮説が間違っていれば
利用者のフィードバックが「いや、正確性より完全性(欠損のなさ)の方が問題だ」となれば、次に「完全性」を改善するテストを行う、という形で軌道修正します。
結論
このプロセスは、データ品質を
一度きりのプロジェクトではなく、「継続的な改善(フィードバックループ)」
として捉える、極めて実践的なアプローチです。
利用者のビジネス価値(アプリケーション属性)を起点とし、GQMで要求を定義し、ロジックブランチで技術的指標(データ属性)に落とし込み、最もROIの高い指標からリーンに改善・検証する、という流れは、データ品質管理の理想的な姿と言えるでしょう。
上記アプローチへの批判的側面
上記のアプローチは理論的に非常に強力ですが、実際に現実の組織で実行しようとすると、いくつかの重要な「壁」や「落とし穴」に直面する可能性があります。
実際、上のアプローチは 「理想的な環境」を前提 としすぎており、現実の組織が持つ「複雑さ」や「慣性」に対する考慮は弱い部分があります。
1. 組織能力と文化への「高すぎる要求」
上記のプロセスは、参加するメンバーと組織文化に非常に高いレベルの成熟度を要求します。
高度なファシリテーション能力
5W2HからGQM、ロジックブランチまでを導き、多様な利害関係者の意見を構造化できる
極めて高度なファシリテーション能力を持つ人材が必須です。
このような人材は組織にそもそも稀な存在です。
ビジネスサイドのコミットメント
データ利用者(ビジネスサイド)が、こうした抽象的・論理的な議論(GQMやロジックブランチの作成)に「時間を割く価値がある」と納得し、積極的に参加するとは限りません。
「技術的なことはIT部門でうまくやってくれ」という文化の場合、スタート地点で頓挫します。
「リーンな改善」へのアレルギー
「まず80%の品質で試してフィードバックをください」というアプローチは、失敗を許容するリーン/アジャイルな文化が前提です。
品質は常に100%を目指すべき(結果として何もリリースされない)というウォーターフォール的な文化や、金融・医療などコンプライアンスが厳しい領域では、この「仮説検証」プロセス自体が拒絶されるリスクがあります。
2. 「利用者のフィードバック」という名のブラックボックス
アプローチの核である「利用者のフィードバック($\Delta App$)」の取得は、言うほど簡単ではありません。
効果の言語化・定量化の困難さ:
利用者は、データ品質がわずかに改善(例:正確性が80%→85%)しても、その違いを明確に「体感」できないか、あるいは「なんとなく良くなった気がする」という曖昧なフィードバックしか返せない可能性があります。
測定コストの問題
$\Delta App$(アプリケーション属性の向上度)を客観的に測定するための仕組み(例:業務効率の計測、ダッシュボードの利用率)を別途構築する必要があり、そのためのコストが改善コスト($\Delta S$)を上回るかもしれません。
フィードバックの遅延
利用者が多忙で、改善の検証に付き合ってもらえない場合、フィードバックループが著しく遅くなり、リーンな改善サイクルが回りません。
3. 「第1次近似」という大胆な単純化の罠
「最も重要なデータ属性1つ」に絞って改善するアプローチは、効率的である一方、
「局所最適解」 に陥る危険性
をはらんでいます。
複雑な非線形性の無視
データ品質は、複数の属性が複雑に絡み合って初めて価値を生みます(例:いくら正確性が高くても、適時性がゼロなら無価値)。f(正確性のみ) という近似は、この相互作用を無視しています。
「必要十分条件」の誤認
ある属性(例:完全性)が一定の閾値(例:90%)を超えるまでは、他の属性(例:正確性)をいくら改善しても、利用者の満足度($\Delta App$)が全く向上しない($\Delta App \approx 0$)というケースがあり得ます。
仮説の誤りリスク
最初にGQMで「重要だ」と仮説を立てた属性がそもそも間違っていた場合、そこを改善するコストと時間が全て無駄になるリスクがあります。
4. 根本的な「技術的負債」との衝突
上記のアプローチは、「わずかに改善する($\Delta S$)」ことが容易であるかのような印象を与えますが、実際にはそうではありません。
「わずかな改善」が不可能な構造
ロジックブランチで「正確性(Accuracy)が原因だ」と特定できても、その根本原因が
「マスターデータ管理(MDM)の不在」や「レガシーシステムの設計不備」
といった巨大な技術的負債にある場合、「わずかに改善する」ことは不可能です。
ΔSのコストが巨大すぎる
必要な $\Delta S$(属性の改善)を得るためのコスト(例:システム再構築)が、それによって得られる $\Delta App$(利用価値)を遥かに上回る場合、このアプローチは「問題はわかったが、解決不能」という結論にしかなりません。
結論
上記のプロセスは、データ品質をビジネス価値に結びつけるための 「理想的なロードマップ」 としては非常に優れています。
しかし、これを現実の組織で成功させるためには、このロードマップをそのまま実行しようとするのではなく、
①. まず、このプロセスを実行できるだけの 組織文化(特にフィードバックを許容する文化) が醸成されているかを見極める。
②. GQMやロジックブランチを完璧に作ろうとせず、まずは最もクリティカルな1つのストーリーに絞って小さく試す。
③. 「第1次近似」で改善する対象は、技術的負債が小さく、改善コストが低い ものから意図的に選ぶ。
といった、理想と現実のギャップを埋めるための「戦略」 が不可欠になると言えます。