インラインコード
前置き
今回は、カオス実験の際の仮説構築や検証時に学びを最大化させるためのちょっとしたコツを紹介します。
前提条件
KubernetesのPodとしては別のものとしてデプロイされた、2つのPod、Pod_AとPod_Bがあるとします。
想定シーン
カオス実験により、片方のPodへの障害の注入が、結果的にそのPod内に閉じておらず、もう片方のPodまで爆発半径に巻き込まれたことが判明したとします。
これは本来であれば、
「別Podに障害時の影響が出てはならない」という原則に反したアーキテクチャ
ということになります。
1. 爆発半径の違反
Pod Aへの障害注入がPod Bにまで影響(例:Pod Bのレイテンシー悪化やエラー率上昇)を及ぼした瞬間、それは
「アーキテクチャ上の爆発半径の設計(=Pod A内に閉じる)」が“失敗”している
ことの動かぬ証拠です。(影響範囲の局所化の原則に反する)
それは、論理的には分離されていても、実行時(ランタイム)において密結合している「分散モノリス」であることを示しています。
2. クリーンアーキテクチャ層別の障害注入
ココが私なりのカオス実験の際の最大の工夫点になります。
関心を分けていないと
関心を分けていない状態で、適当に障害を注入すると、そもそも仮説が非常に立てにくいです。これでは、検証時にも何を検証したらいいのかも不透明です。
関心を分けて実験を行う
そこで、クリーンアーキテクチャのように、関心をわけたアーキテクチャスタイルにし、
「どの層のコンポーネントに障害を注入したら、このようなことになる」
という仮説を立てやすくします。
これにより、実験のコントロール容易性が劇的に上がります。
「あるPod_Aのエンティティ層に障害を注入しても別Pod_Bには何も影響がないのに、Pod_Aのインフラ層に障害を注入時のみPod_Bにも影響が出る」
といった時に、
「Pod_Aへのインフラ障害の影響がPod_Bにも伝搬した。
→ ということは、間違いなく、インフラ層での意図しない結合があるはずだ。」
という最大の発見に繋がります。
これこそが、このアプローチがもたらす「最大の発見」です。
「層(関心事)を分けた実験」は、「障害の種類」を分離することで、「なぜ」そのカスケード障害(連鎖的障害)が起きたのかを即座に特定可能にします。
シナリオA:エンティティ層 / ユースケース層への障害注入
アプリケーションの 「ビジネスロジック(コアドメイン)」 のバグをシミュレートします。
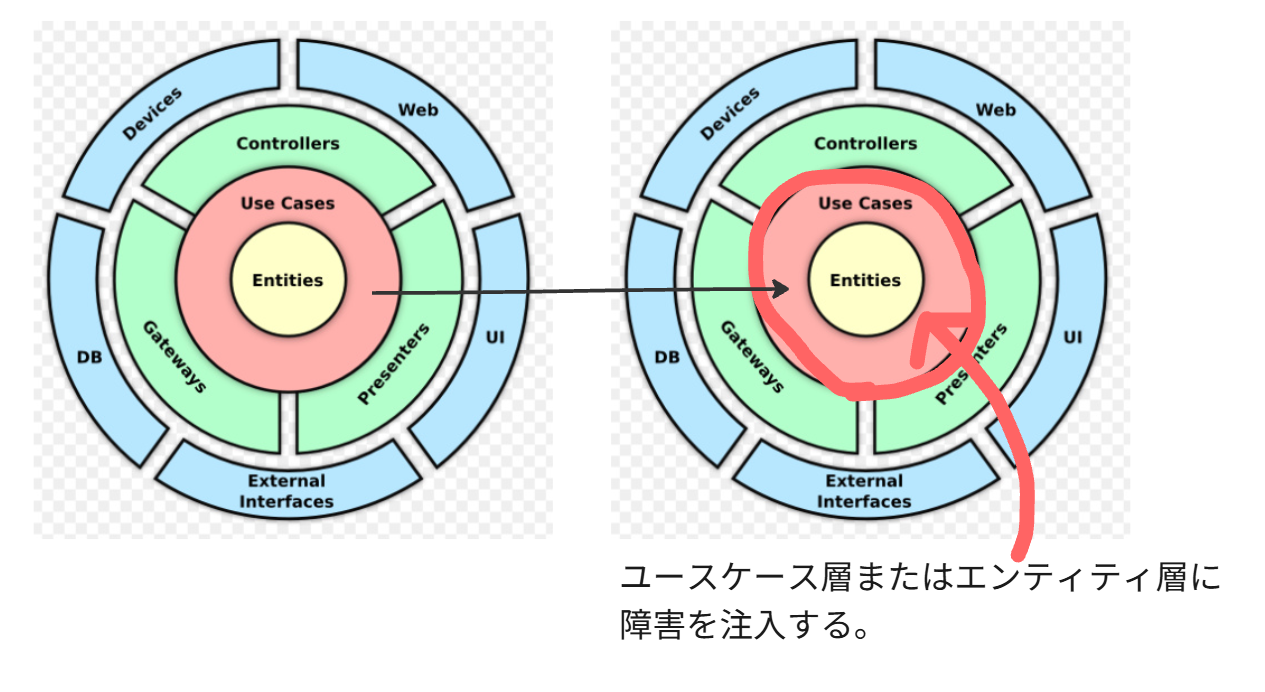
もしも、この部分で意図せず他のサービスと結合していたら、必ず他のPodにも影響が伝搬するはずです。
事例
・在庫計算ロジック(ユースケース層)がNullPointerExceptionでクラッシュする
・Orderエンティティ(エンティティ層)の検証ロジックが無限ループする
といった、コードレベルのバグです。
期待される結果(良い設計)
・Pod Aは500エラーを返すか、Liveness Probe(生死監視)に失敗して自己再起動します。
・Pod Bは、Pod Aからの応答がない(あるいは500エラーを受け取る)ため、サーキットブレーカーを開くなどして正常に動作し続けます。
分析結果
たとえば
「Pod_Aのエンティティ層に障害を注入しても、別Pod_Bには何も影響がない」
という、実験結果が得られたとします。
→ これは、アプリケーションの「論理的な疎結合」が成功している証拠です。
シナリオB:インフラ層への障害注入
アプリケーションの 「技術的詳細(外部依存)」 の障害をシミュレートします。
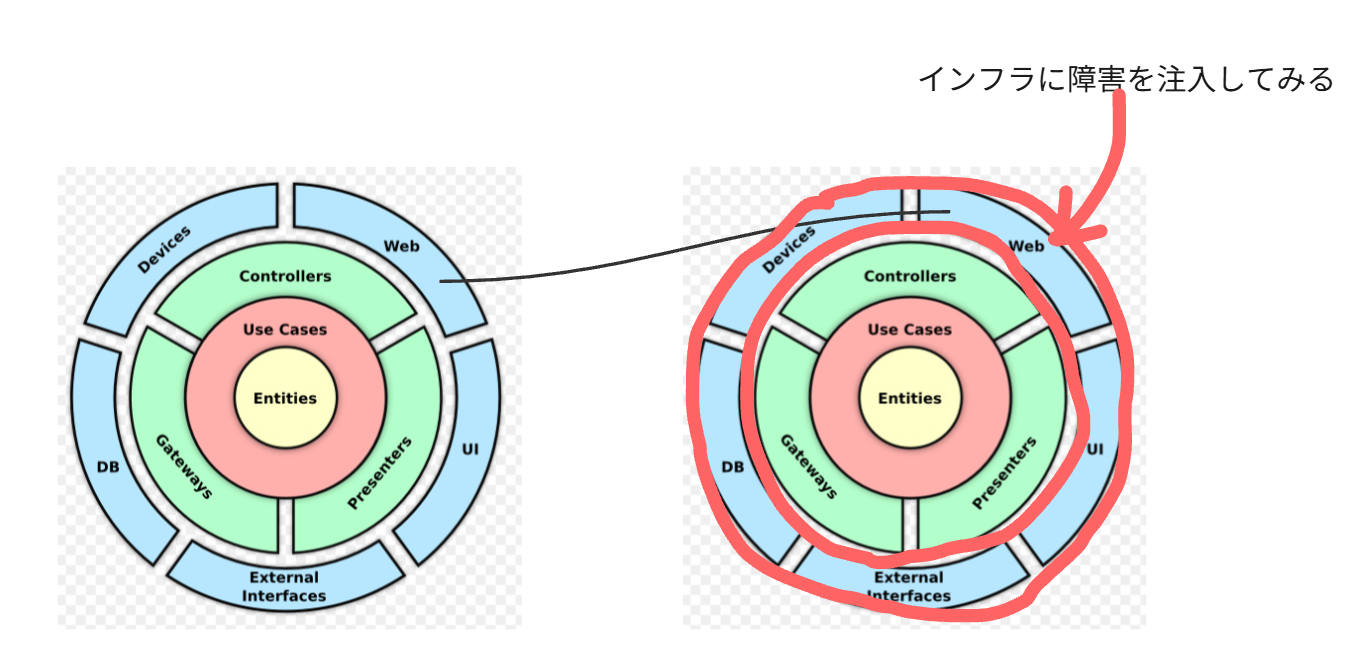
事例
・Pod Aが接続するデータベースへのコネクションを切断する、
・Pod Aのサービスメッシュ・サイドカーをクラッシュさせる
・Pod Aが利用する キャッシュ(Redis) を応答不能にする。
期待される結果(悪い設計=あなたの「発見」)
「Pod_Aのインフラ層に障害を注入時のみ、Pod_Bにも影響が出る」
→ これこそが「最大の発見」です。
なぜこの「発見」が起きるのか?
これは、Pod AとPod Bが、開発者が意図しない「暗黙のインフラ依存」 を共有していることを意味します。
事例①
Pod AがDB障害で処理不能になり、共有DBのテーブルロックを掴んだまま離さなかった。
その結果、そのロックを待っていたPod Bも道連れになってフリーズした。
事例②
Pod Aが依存するRedis(インフラ)が応答不能になり、Pod Aが停止した。
しかし、Pod Bも、同じRedisインスタンスを(Pod Aとは無関係に)使っていたため、道連れになった。
結論
カオス実験は非常にコストのかかる作業です。
実験室の設計だけでも、かなり骨の折れる作業だし、コストをかけた以上は、
現在のアーキテクチャのどこが自分たちの想定外の脆さを孕んでいるか?
どの水準までは耐えられるのか?
を確実に見つけなくてはなりません。
単純な実験結果
「Pod Aを落としたらPod Bが止まった」
という現象(What)を観測するだけの単純な実験結果だけでは、
「で、結局その後何をしたらいいの?」という、学びも特に得られず、何も改善に結び付きにくいです。
階層別の実験結果
なので、実験を行うとしたら、まずは実験がコントロールしやすい、最低限オニオンアーキテクチャの構造を作成していることを前提条件にしましょう。
それにより、前者の単純な実験から、
「Pod Aの“インフラ層”の障害“だけ”がPod Bを止めた。
よって、結合点はDBロックか共有キャッシュにあると断言できる。」
という根本原因(Why/Where)まで特定できる、極めて高度な診断 へと進化させます。