メリークリスマス ![]()
![]()
![]()
本記事はPostgreSQL Advent Calendar 2021の25日目です。今年も面白い記事がたくさん揃いましたね!!!
さて、みなさん今年のPostgreSQLライフはどんな感じでしたでしょうか?
私はというと、なんだかチューニングばっかりやってました。1案件でいろいろお手伝いすることはまあまああったのですが、複数から次々チューニングの相談をもらって、歴代継承者の個性を発現したデクくんのごとく駆け回ったのが今年のハイライトです。
(この綱渡り感、、、伝われ!!!)
俺たちは雰囲気でチューニングしている
今回上手くいったけど、あの時たまたまひらめいた1案をぶつけてみたら効果でたのであって、次善の策なんてなかったけど??って毎回思ってるから、雰囲気でやっていると思う、マジで。コミュニティのノリだと笑いが起きていいんですけど、少しでも勝率を上げるために、若手の前でドヤ顔キメるために、雰囲気チューニングを言語化したいと考えたのでした。
関連するキーワード
- PostgreSQL(バージョン問わず)
- 実行計画
- EXPLAIN / EXPLAIN ANALYZE
初めの一歩「その方針あってる?」
(悪いSQLを特定できる人はスキップ)
ボトルネックを「特定」してピンポイントで効果的な対処をするのは理想ですが、はじめから「特定」でなくてもいい、まず現象を見つめる、考えることを大事にしています。
- xxの画面で時間がかかっている
- 全体にもっさりしてる気がする
といった悩みを書き出す。
→ 画面がわかればその裏で流れるSQLがわかる。
→ 全体的にもっさり遅いパターンだと一見どのSQLかわかりにくいですが、、、
それがSQLの問題ならpg_stat_statements(=pg_statsinfoやpgBadger)でちゃんと探せますから。この段階を経て、SQLやりきったぐらいからH/Wのボトルネックを見ていく感じ。
言い換えると、「結局SQLが悪いんじゃないの?」と疑ってかかり、まずは悪い子の特定を目指すことだと思います。
postgresql.confのパラメータチューニング、インスタンスタイプの増強に辿り着くのは、SQLの疑いを晴らす過程で道が見えてくることもあるって感じ。その人の得意分野にもよるのかなー。(あ、やっぱり雰囲気で書いている。ここはもうちょっと書けると思う。いずれ!!!)
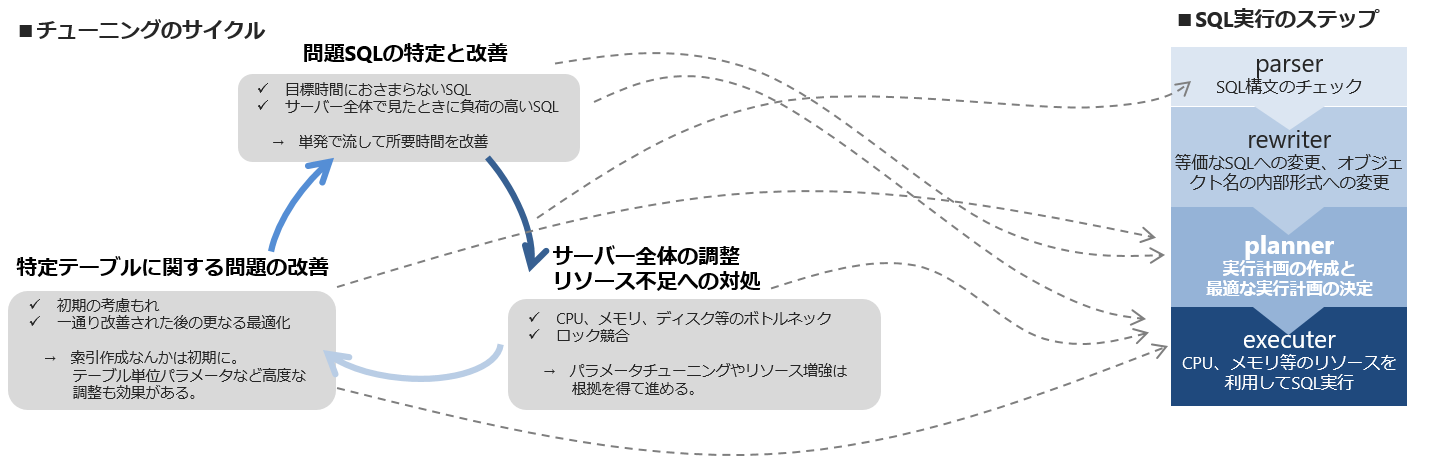
「ここ調整したらどう影響するかな?」をこんな感じで考えている。グレーの点線のような感じで、この対処はどこに効いてくるか、それって現在の事象にぴったりフィットするか、左のサイクルのどこから始めるか。この辺を雰囲気で選び取っているんだと思う。結局相互に関わってくるし、SQLチューニングにフォーカスすればサイクルの前後に対してもある程度見えてくるわけで、インデックスが足りなければ当然気づくし、パラメータが悪ければSQLを直す過程でメモリ足りなさそうだなーとか思ってくる。SQLから疑ってかかるというのはまず取っ掛かりとしてどこから行くかという感じです。
「実行計画を見よ!」
そんなわけで悪いSQLをピックアップするのに専念してみてほしいのですが、その先の、さあSQLをどう見ていきましょうか、というのが主題です。SQLチューニングと言えば実行計画を見よ。(DB製品を問わず世の中で言われることなのでここはまあ良いでしょう。)PostgreSQLで実行計画の見方はググればたくさん出てきますね。
-
EXPLAINだけでわかることなど無い。EXPLAIN ANALYZEだぞ。 - 一通りチューニングした後は
EXPLAIN (ANALYZE,BUFFERS)もあり。
BUFFERSまで取得するとアクセスブロック数などの情報がわかるので、次のステップでExecutionを改善していく上では役に立つ。が、索引や結合の善し悪しを考える段階では不要。実行計画が改善されれば大きく変わるからね。次の目XPLAIN(EXPLAIN)のためにもノイズを減らしたい派。
長すぎる実行計画('Д')
次のハードルは結構これ。というか、ほぼすべてのチューニング案件でこの状態。パッと見れるような実行計画はお客様自身で見てるからね。俺たちは長すぎる実行計画を紐解いていかなければならない。
▽PostgreSQLにおける目XPLAIN(EXPLAIN)
psqlで取得するPostgreSQLの実行計画はテキスト形式、階層化してインデントがついてくるので、それを活かす方法を紹介します。
目XPLAINという概念
@yoku0825 さんが中国地方勉強会で口走っていたパワーワード
https://www.slideshare.net/yoku0825/mysqler7
エンジニアたるもの目grepの経験があるじゃないですか。そういう用法ですよ。
用意するもの
- A3プリンター
- 30㎝ぐらいの定規
- マーカー(できれば水性の裏写りしないもの)
もしくは NoEditerなどの縦線を引けるエディタでもいいかもしれない。それでも数が多いと断念する。
目XPLAINのススメ
こう!

- 細かいSQLを、目を凝らして識別するのは大変なので、名前を付けてでっかく書いておく「売上報告A」beforeの所要時間なんかもあると識別しやすい
- Actual Timeが激増するところをマーク。「コスト激増」とメモって、該当箇所に赤線でマークしている
- その激増する行のもとになっている一つ下の階層(インデントの部分)をマーク「縦の点線」
所要時間が激増したJOINと、それに関わった下位のノードで何が起こっていたかを確認するのです。そうすると、たいてい、激増したゆえの理由が見えてくるかなーという感じ。この写真の例で言うと、JOINしてるのは実行計画の最下部。上下でこんなに離れた場所に問題の正体が潜んでいたんですね~
▽実行計画の多重下請け構造
実行計画を読み解くとき、みなさんはどこから目を付けますか?
- 階層の深いところから
- 上から
- 下から
どうでしょ?
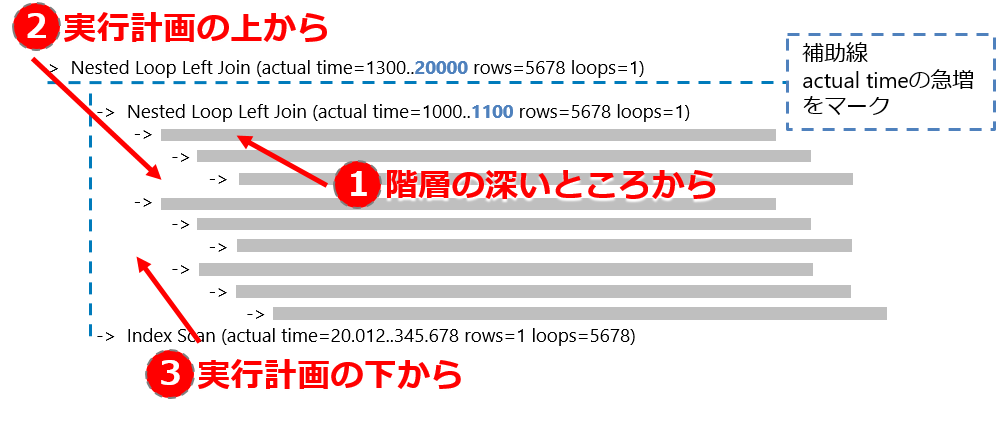
これ、正確なところを確認したことは無いのですが、実行計画では上の行から下に向かって処理をリクエストしていると思うんですよね。下請けはリクエストに応えて結果を親に返す。その際にさらに下請けに外注もしている。
「階層の深いところから読み解いていく説」は割とよく聞くし、あながち間違ってないと思うのですが、↓のようなケースでは多重下請け構造と思って、上から何を要求されてるかを理解していったほうがスッキリ明快です。なので正解というか自分なら**「2:実行計画の上から読み進めていく」**でやってます。
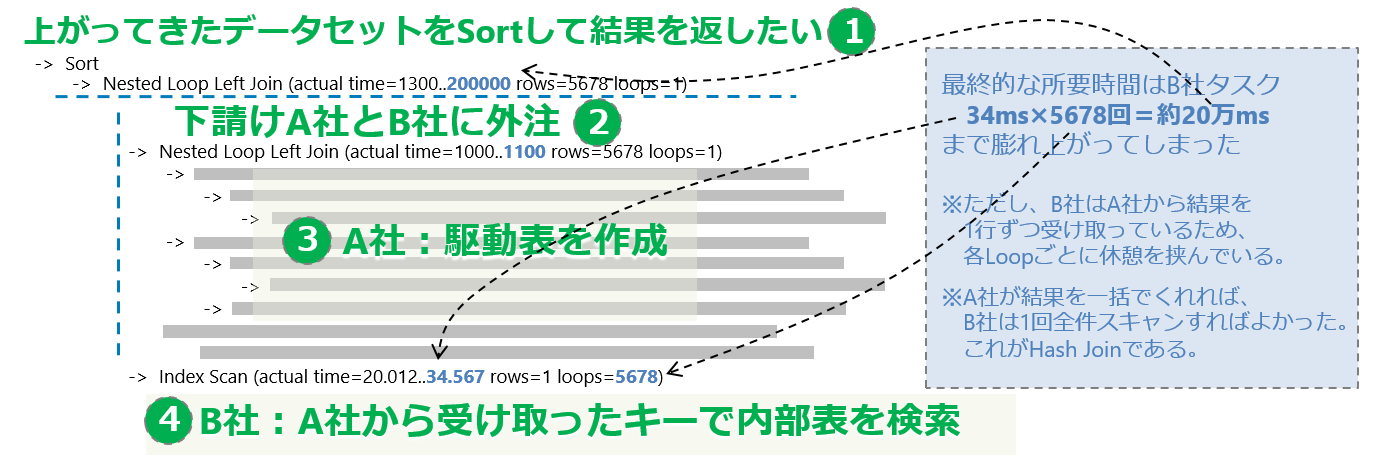
| 番号 | 該当行 | 内容 |
|---|---|---|
| 1 | 最上位のSort | 最終的にソートした結果を返したい |
| 2 | 続くNested Loop行 | A社の結果とB社の結果をNested Loop Join |
| 3 | その1行下 A社に発注したお仕事 |
上の塊、駆動表として全件利用するデータを作成 (以下多数の階層が3次請け、4次請けに・・・) |
| 4 | 末尾 B社に発注したお仕事 |
内部表としてloopし、条件に合う行をピックアップ。 実はここがボトルネック!!! |
最下行(内部表)のLoopsは上の塊(駆動表)で得られた結果の行数分発生していて、Loop回数×所要時間が膨大になってしまった。**B社は仕事を受けた時点ではこんなにLoopするとは思ってなかったのでしょう。**これ、行数の見積が正確なら最初からLoop回数の予測が立って、最初からHash Joinしてるでしょ。プランナ仕事しろ案件です。
階層が深いところから読む説に対して
問題であった「B社がIndexScan」してるところは実行計画の階層(インデント)としてはかなり浅いところに出てきてますよね。「階層が深いところ」から見ていく方式だと、全体としては概ね問題ない「A社内の一部の仕事(3次請け、4次請けの仕事)」を掘っているだけで、このタイプの問題にはなかなかたどり着けないんですよね。
「今まで深いところから見てたわ~」という方へ。アナタもワタシも雰囲気チューニングの同志ってことです🥰
▽長い実行計画 = JOINの数が多い説
ある箇所で急に激増していればそこに原因がある可能性が高い。多重下請け構造を思って読み込んでいくと、結構な勝率で問題を特定できているように思います。しかし、各処理を経るごとになだらかに時間が増加していて、どこが悪いと決めきれない場合・・・トライしてみてほしい2つのパラメータが。
from_collapse_limit と join_collapse_limitを10~12に変更してみてください。あわせて遺伝的問い合わせ最適化の無効化も検討します。(12という数字はこれらの境目になるので、一旦geqoしないように無効にしています。)
目がチカチカするような長い実行計画では、その各行は表や索引のスキャン、各ジョイン方式を指していると思って良いわけですから、登場人物が8人以上からむこのような長い問い合わせにおいて、そのままこのパラメータが有利に働くことが見込めます。Nested Loop JoinがHash Joinなんかに置き換わる部分があればしめたものでしょう。
まとめ
PostgreSQLのチューニング、EXPLAINの進め方について、
- 理論
- アイデア
- アナログな努力
の混沌としたところを解き明かしたく、最近経験して思ったところを整理してみました。
体系的な知識というには全然まだまだですが、チューニングに行き詰ったときにちょっとしたアイデアとして、現状打破する一つの視点として、どなたかの参考になれば幸いです。