Alireza Nejati 氏のブログ記事
https://pseudoprofound.wordpress.com/2016/06/07/neural-programmer-interpreters-programs-that-can-learn-programs/
の翻訳です。
翻訳の誤りなどあればご指摘お待ちしております。
Google DeepMind の人たちは、Neural Programmer-Interpreters (NPI) と呼ばれる一種のニューラルアーキテクチャに取り組んでいます。すべての機械学習は究極的には作業の自動化に関するもので、人間ができるすべての作業を自動的に実行できる機械を最終目標としています。特定の作業を自動的に実行することを機械に教えるという問題を考えてみましょう。足し算のような単純な作業かもしれないし、車を運転したり、洗濯物をたたむような、あるいはコーヒーをいれるようなもっと複雑な作業かもしれません。この作業を自動化する方法を考えてみましょう。
-
作業を自動化するための古典的な(AI以前の)方法は、その作業を実行するための詳細なプログラム仕様を完全に書くことでした。たとえば、コーヒーをいれたい場合は、ロボットのアクチュエータに適用する電圧レベルの詳細なシーケンスを与えて、ロボットを特定の場所に移動させ、カップをつかませ、などをします。また、さまざまなセンサーからの入力に基づいて動く特別な条件付きケースを含めることもできます。この方法の明らかな欠点は、不確実でノイズの多い現実世界と相互作用するためには、膨大な数の条件付き行動と特殊ケースをプログラムする必要があり、プログラムが複雑で手に負えなくなることです。
-
次のステップ(GOFAI(古き良きAI)の方法)は、十分な論理と「常識」をもってプログラムすることによって、機械が自分自身で作業を実行する方法を理解できるようにすることでした。たとえば、テーブルから赤いブロックを取り上げることができるようにするには、赤いブロックが何であるか、テーブルが何であるか、テーブルに移動するにはアクチュエータをどのように動かせばよいか、など、十分な知識をもってプログラムする必要があります。作業を仕上げることは、定理の証明に似た方法で、問題を解決するステップの記号シーケンスを探ることに似ています。このアプローチは一般的には失敗しました。なぜなら、現実世界を単純な方法で処理するためにはハードロジックはあまりにも柔軟性がなく、そのため、常識を論理ルールに基づいて単純にコンピュータにプログラムすることは本当に困難だからです。
-
次のステップ(ニューラル/統計的AIの方法、80年代から現在まで)は、現実世界の変わりやすさをとらえる多くの訓練例を見つけて、この大規模なデータセットで一般的な学習機械を訓練することでした。最初は、利用できる学習機械があまり良くなく、訓練は困難でした。時間とともに、より良いアルゴリズムとより多くの計算能力によって、このアプローチは非常に強力になりました。残念ながら、このアプローチにもいくつかの問題があります。大規模なデータセットが必要なことと、人間ように少数の訓練例から簡単ではない作業を学習することができるニューラルアーキテクチャを見つけることが難しいということです。
これが、NPIが必要な理由です。NPIは、少量の訓練データに基づいて単純な作業を実行するために、ニューラルネットワークの方法を用いて機械を訓練する試みです。そして、心臓部では、LSTMセルに基づくRNNを使用します。また、古き良きAIのアプローチから、いくつかのアイデアを使用しています。RNNに詳しくない方には、Andrej Karpathy 氏の人気ブログ記事を強くお勧めします。この記事は、私よりもはるかにうまくRNNを説明しています。実際にまだ読んでいない場合は、読み進める前に読んでおくべきでしょう。また、RNN/LSTMネットがどのように動くかの詳細については、Colah 氏のブログでLSTMネットワークの説明を読むことをお勧めします。
さて、あなたがRNNについて知っていると仮定します。作業を実行するためにRNNを訓練したい場合、1つの方法は、言語翻訳などで使われるような、シーケンス変換(sequence-to-sequence)(s2s)器を書くことです。言語翻訳では、入力はある言語のシンボルのシーケンスで、出力は別の言語のシンボルのシーケンスです。作業を自動化する場合、入力は環境からの観測(センサー)のシーケンスで、出力シーケンスは機械がその環境において実行できる機能の集合です。訓練例は、私たちが「機械の手をつかんで」、機械が何らかの作業を実行することを助けるシーケンスです。
以前は、この種のRNNを作業自動化のために使用しようとしていましたが、先ほど述べたように、多くの訓練データが必要であり、また、あまりうまく一般化されません。機械翻訳では十分に機能しますが、よりアルゴリズム的で構成的な作業の自動化ではうまく機能しません。単純な例題を見てみましょう。バブルソートを用いた数のリストの並べ替えです。床に広げられた一連の項目と、以下のアクションを実行できる「仮想ロボット」を想像しても良いです。
- 必要に応じて直線を行ったり来たりする
- 隣接する2つの項目を入れ替える
この場合、入力は、ロボットの現在の位置と、現在の項目が次の項目よりも大きいか小さいか、でしょう。出力アクションは、ロボットを左右に動かすか、項目を交換することです。あなたは手作業でいくつかの具体的な訓練の例によって、センサー入力と取るべき一連のアクションを提供するでしょう。しかし、単純な s2s 変換器ネットを使って訓練した場合、正確にソートを開始するには多くの訓練データが必要であり、また、大きなシーケンスに対しては一般化できないことに気が付くでしょう。特定の条件下でソート動作をエミュレートすることはできても、ロボットはソートの「要点を得ていない」(合点がいかない)でしょう。
人間はどのようにアルゴリズムを学ぶのでしょうか?私のブログ記事を読んでいれば、その答えは明らかです。私たちはアルゴリズムやプログラムを、世界の既によく開発されたモデルにフィットさせ、少数の訓練例から学ぶために個々の単純なサブプログラムの階層的なシーケンスに分解します。たとえば、バブルソートを分解して、サブプログラム「リストを上に移動して、単調増加していない数を入れ替える」を繰り返し適用することができます。
DeepMind の人たちは、このようなアイデアをNPIに取り入れました。
NPIは、単純なスタックのようなデータ構造の形の「作業記憶」を持つ s2s 学習器です。サブプログラムに「入る」たびに、スタックに「親」プログラムをプッシュし(そして隠れ状態を再初期化します)、サブプログラムを終了するたびに、親プログラムを中断したところから再開します。サブプログラムの動作は現在実行中の親プログラムに依存するため、親タスク(「入力プログラム」と呼ばれます)を s2s 変換器への入力ベクトルとして保持します。
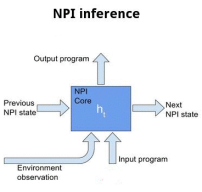
つまり、一言でいえば、NPIは、入力シーケンスが $(e_t, p_t)$ のシーケンスである s2s 変換器です。ここで、$e_t$ は時刻 $t$ での環境、$p_t$ は時刻 $t$ での親タスクです。単に $(e_t)$ ではありません。出力シーケンスは、以下のシーケンスです。
- 現在のサブプログラムを終了して親プログラムに戻るかどうかを示す真偽値
- 次に実行するサブプログラム
- そのサブプログラムへの入力引数。たとえば、電圧レベルや、移動する方向
NPIはプログラムへの出力引数を生成できるため、必要なプログラムの数が大幅に削減されます。たとえば。 1cm移動、2cm移動などのタスクを別々に持つ必要はありません。私たちは移動のためのプログラムを1つだけ持っていて、引数として動く量を与えます。
実際、NPIモデルでは、すべての出力アクション(環境で実行できるプリミティブでアトミックなアクション)は、単一の命令、ACT で、実行されます。実行するアクションのタイプは、単にその関数の引数の集合だけです。たとえば、バブルソートタスクでは、ACT(i, j, SWAP) によって入れ替えが行われ、ACT(1, LEFT) や ACT(2, LEFT) によって左への移動が行われる、などです。ロボットが持つ能力に対応するアプリケーション固有のタスクを指定できます。NPIの論文では、出力引数はいつも3タプルの整数です。
このモデルでは、訓練時、階層構造を指定することによって訓練が実行されます。 これはモデルの弱点の1つです。モデル自身が階層構造を推測することはできません。プログラムを自動的にサブプログラムに分解する方法を解くことは、興味深い未解決の研究課題です。
他にもいくつかの実装の詳細があります。主な詳細は、エンコードとデコードです。つまり、環境を s2s マシンへのベクトルとして表現する方法、s2s マシンからの出力ベクトルをプログラム呼び出しにデコードする方法です。いくつかのエンコーダの例は、論文のセクション4に記載されています。この論文の一般的なアイデアは、ほとんどの場合、単にセンサー値を連結することであると思われます。たとえば、センサーが複数の離散的な状態を持つ場合、センサー値は1ホットベクトルになるでしょう。例外は、センサーが視覚センサーである場合です。この場合、生のセンサー値を入力しないで、代わりにCNNを通して画像を入力して、CNNが生成するコードを出力します。
すべての入力が連結された後、これらの入力はMLPを介して入れられ、より短い固定長コードが得られます。「でも待って」、あなたは「なぜRNNに連結されたベクトルを入れないの?」と質問するでしょう。それは良い質問です。答えの一部は、入力が短い方がRNNの訓練が簡単だからです。しかし、コアRNNがすべてのタスクで共有されるためでもあります!そうです、論文では、RNNは、バブルソート、足し算、画像の標準化について同時に訓練されます。これは、モデルのもう一つの重要な側面で、システムが他のタスクから学んだ知識を新しいタスクに移し、より効率的に学習することを可能にします。
要約すると、NPIはRNN、LSTMベースの、シーケンスからシーケンスへの変換器で、以下を持ちます。
- サブプログラムを再帰的に実行し、その間呼び出しプログラムを追跡する機能
- すべてのタスクで共有されるRNNコア
- さまざまな状況に特化するためのタスク固有のエンコーダとデコーダ
訓練時、エンコーダとデコーダはRNNコアとともに訓練されます。これは、NPIの訓練をややトリッキーなものにします。なぜなら、良く知られた勾配降下法を使用しても、訓練中にアーキテクチャが変化するからです。時間や興味があれば、私は TensorFlow でこのモデルを訓練する方法について別の記事を書きます。