昨日の記事の例文に対応する「タネ カ アトゥイ アヌカㇻ ルウェ ヘ アン」を、deberta-base-ainu-ud-goeswithの助けを借りて、アイヌ語Universal Dependenciesで解析してみた。Google Colaboratoryだとこんな感じ。
!pip install transformers deplacy
from transformers import pipeline
nlp=pipeline("universal-dependencies","KoichiYasuoka/deberta-base-ainu-ud-goeswith",trust_remote_code=True,aggregation_strategy="simple")
doc=nlp("タネ カ アトゥイ アヌカㇻ ルウェ ヘ アン")
import deplacy
deplacy.serve(doc,port=None)
私(安岡孝一)の手元では、以下の結果が出力された。
# text = タネ カ アトゥイ アヌカㇻ ルウェ ヘ アン
1 タネ tane ADV 副詞 _ 5 advmod _ _
2 カ ka ADP 副助詞 _ 1 case _ _
3 アトゥイ atowi NOUN 名詞 _ 5 obj _ _
4 ア a= PART 人称接辞 _ 5 nsubj _ SpaceAfter=No
5 ヌカㇻ nukar VERB 他動詞 _ 6 acl _ _
6 ルウェ ruwe NOUN 形式名詞 _ 8 nsubj _ _
7 ヘ he ADP 副助詞 _ 6 case _ _
8 アン an VERB 自動詞 _ 0 root _ SpaceAfter=No
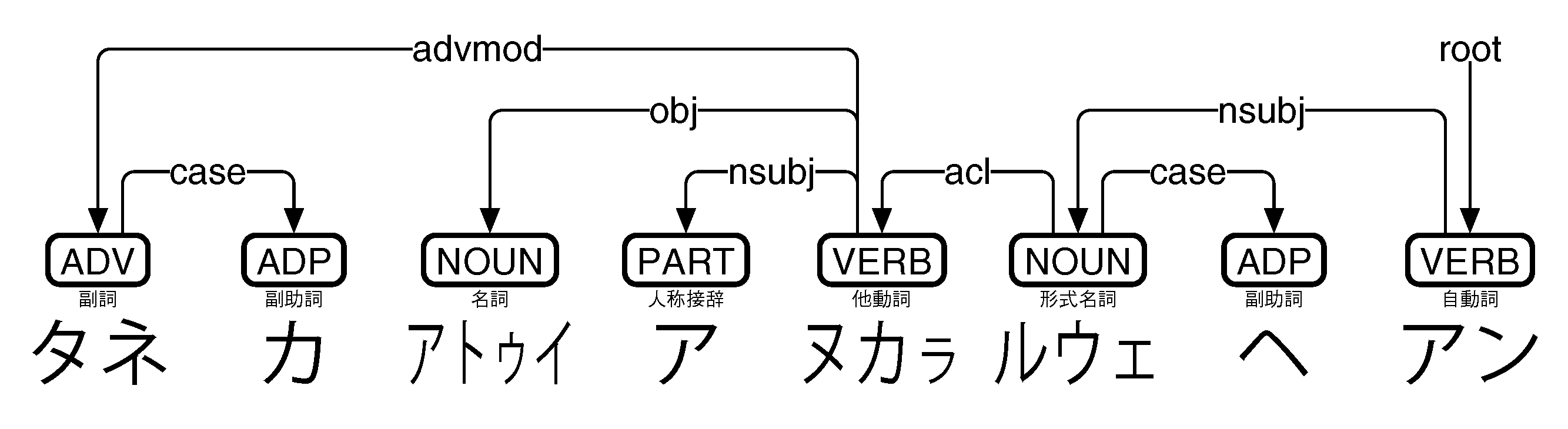
「アトゥイ」のLEMMAが間違っている(atowiではなくatuyが正しい)ものの、その点を除いては、品詞付与も係り受け解析も完璧だ。ただ、私が見る限り、この例文においては、アイヌ語とイテリメン語でかなり言語構造が違う。北千島アイヌ語と南部イテリメン語の間では言語接触があったらしい(cf. 村山七郎『北千島アイヌ語』吉川弘文館、1971年3月)が、残念ながらその痕跡は、少なくともこの例文には見当たらない。その点からすると、アイヌ語Universal Dependenciesの知識は、現時点では、イテリメン語への転用は難しそうである。