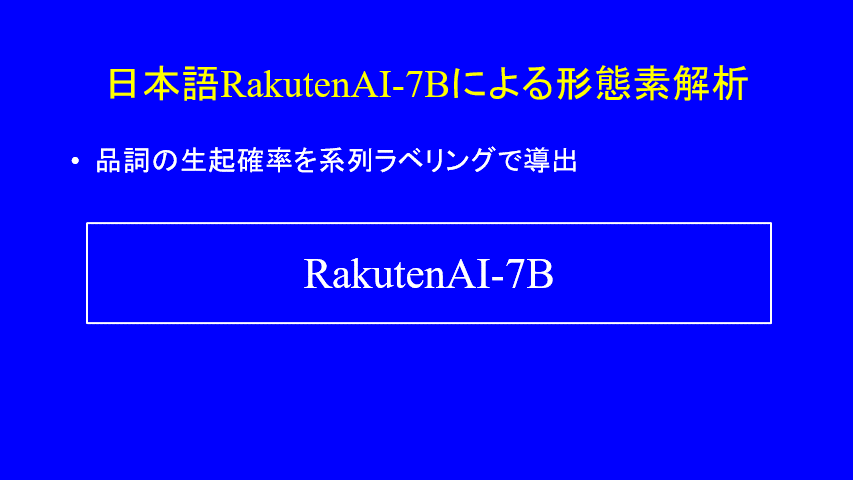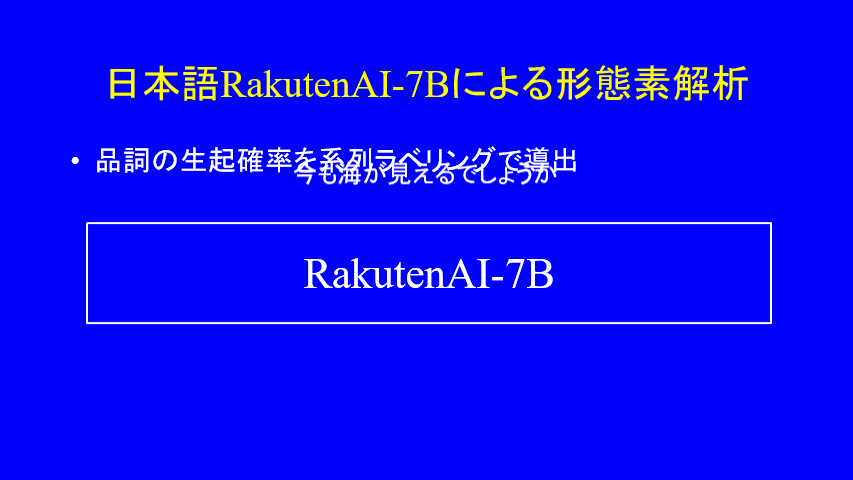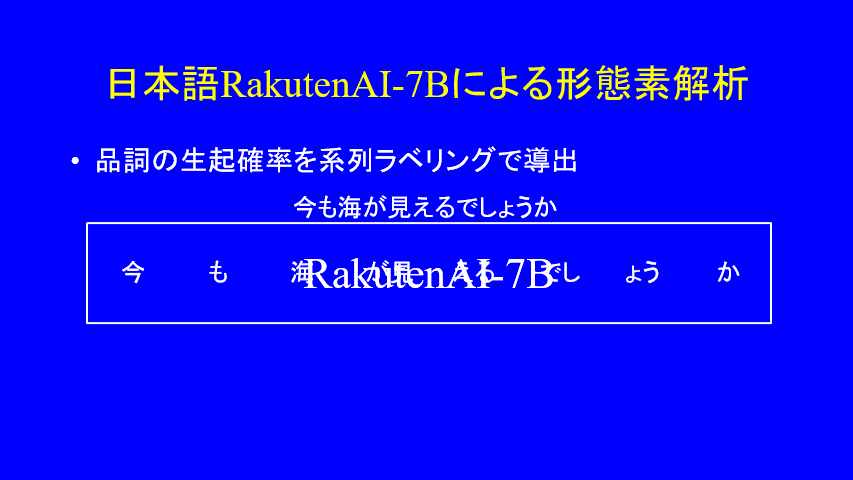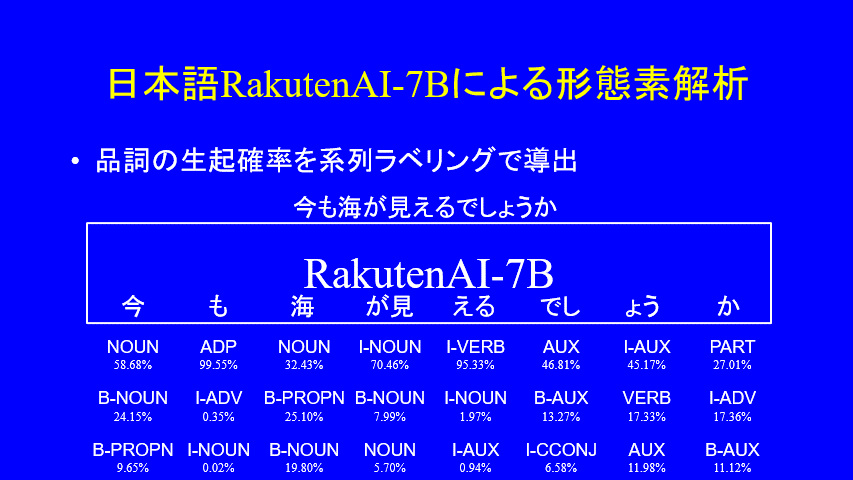
昨日のJHPCNシンポジウムでも指摘したのだが、RakutenAI-7Bのトークナイザは非常に出来が悪く、MistralForTokenClassificationによる系列ラベリングに適さない。たとえば「今も海が見えるでしょうか」を「今」「も」「海」「が見」「える」「でし」「ょう」「か」とトークナイズしてしまうので、「が見」がどうにもならないのだ。
だったらトークナイザを改造して、「が見」が「が」「見」になるようにすればいい。そう考えて、私(安岡孝一)なりにRakutenAI-7B-char-uposを作ってみた。ちょっと動かしてみよう。
>>> from transformers import pipeline
>>> nlp=pipeline("upos","KoichiYasuoka/RakutenAI-7B-char-upos",trust_remote_code=True)
>>> doc=nlp("今も海が見えるでしょうか")
>>> for t in doc:
... print(t["text"],t["entity"],t["score"])
...
今 NOUN 0.40114793
も ADP 0.9626548
海 NOUN 0.33803082
が ADP 0.9801759
見える VERB 0.42835698
で B-AUX 0.3523871
し I-AUX 0.24315608
ょ I-AUX 0.26823658
う I-AUX 0.4992607
か PART 0.12613676
うまく品詞付与できているようだ。B-・I-を解消してみよう。
>>> doc=nlp("今も海が見えるでしょうか",aggregation_strategy="simple")
>>> for t in doc:
... print(t["text"],t["entity_group"],t["score"])
...
今 NOUN 0.40114793
も ADP 0.9626548
海 NOUN 0.33803082
が ADP 0.9801759
見える VERB 0.42835698
でしょう AUX 0.24315608
か PART 0.12613676
よし、OK。つまり、トークナイザを適切に改造すれば、Mistralなどの生成AIも系列ラベリングに使えるということだ。そのあたり、他の生成AIもそれぞれ頑張ってほしいなあ。