(2021年5月13日追記)七声ニーナをリリースしました。DeNAの音声変換をご体験ください。
DeNAのAIシステム部、音声チームの豆谷と申します。私は2020年10月に新卒入社しましたが、2021年の新卒組として記事を書きます。
私は今まで音声合成や距離学習の研究をしてきて、音声変換(voice conversion;VC)については入社後キャッチアップしています。本記事では、DeNAの音声チームが注目する最先端の音声変換技術を紹介し、ユーザの喜びと驚きを生み出したいDeNA視点を交えながら解説します。
想定する読者は、音声変換に興味を持つ方、音声技術を生かして新たなエンタメ作りに挑戦したい方です。特に、
-
音声変換に関心がある学生がサクッと論文レベルで最先端の音声変換を把握できるようなお得な記事で
-
読者の「音声変換による新しいエンタメ作りに向けた研究開発の一歩」になる
ように努めます。
目次
DeNAと音声変換
近年の音声変換手法
音声認識の学習を活用する手法
音声合成の学習を活用する手法
オートエンコーダを活用する手法
GANベースの手法
DeNAと音声変換
本章では、最先端の音声変換技術の解説に移る前に、DeNAとして、音声変換で何を実現したいか、どう研究を評価するかという軸について説明します。
DeNAは以前より音声技術の研究開発に取り組んでいます。今までは音声合成技術を中心に扱い1、その研究成果は「ハッカドール・プロジェクト」や「バーチャル警備員」などで実用されています。一方で、音声変換の研究開発は比較的新しい取り組みになります。これまでにも音声変換技術の技術的な対外発表を行っており、その成果は過去のTechConでも紹介してきました。音声変換の基礎的な説明や「どれくらい夢のある技術か」という部分は、以前のTechConの記事2を参照してください。
TechConの記事で紹介されているように、音声変換は入力できる話者数が一人か複数かの場合で、解決すべき問題や必要となるデータセットが異なります。DeNAではゲームやライブ配信といったアプリで、多数のユーザに使っていただき、複数の話者を扱うことを想定しているので、複数の話者を入力に変換できる手法(many-to-one、many-to-many変換)に注目しています。
また、DeNAではPocochaやSHOWROOMといった配信系のサービスが多く、そうしたサービスへの応用を考えると、音声に処理を加える場合はリアルタイム性の要求は厳しいです。さらに、そうしたサービスで音声変換をモバイル端末上で実行することを想定すると、実行モデルのメモリ使用量に注意しなければなりません。他に、日本語の音声を中心に扱うことになるので、使える音声データ(コーパス)が研究で一般的に使われる英語の大規模コーパスよりも比較的少ないということも考慮する必要があります。
DeNAでの音声変換技術の活用は、下記の通り大きく2種類を想定しています。
-
ターゲット話者に完全になり切りたい場合
-
バーチャル配信者の新しい声のアイデンティを提供
-
配信者の匿名化、プライバシ保護
-
-
ソースの話者性を残しつつ声を変えたい場合
-
ゲーム内なりきりボイスチャット
-
オンラインで声を「盛れる」美声フィルタ
-
近年の音声変換手法
音声変換とは、言語情報(linguistic content)を変えずに、入力音声の話者性(speaker identity)を分離し、別の人の声の特徴を使って復元する技術です。もう少し具体的な変換のイメージは、話者に依存する声の特徴(声の高さ、話速など)を変えながらも、話し方(発話内容、感情など)は変えない変換です3が、決まった定義はありません。「話者性を分離する」というと難しく聞こえますが、多かれ少なかれ、人は音声から話者性特徴と言語情報を分離することができます。例えば、モノマネ芸人は、モノマネの対象となる人物の話者性特徴を分離し、さらに復元することにより、任意の文章を対象人物の特徴を用いて発話できます。
 (変換フローの概念図、学習のフローはまた異なる)
(変換フローの概念図、学習のフローはまた異なる)
上の図に複数話者の音声を変換する手法を概念レベルで示します。近年提案される多くの音声変換では、任意の話者の音声から「話者性を分離する部分」と、話者性が除かれた言語情報からターゲット話者の「音声を復元する部分」に大別できます。そして、この2つのプロセスの間には、情報のボトルネックがあり、ここで「話者に依存しない言語情報」を獲得することを狙い変換モデルを設計します。複数話者を一つのモデルで取り扱うので、「話者性の分離」プロセスは、任意の話者に対して実行可能であることが理想です。ターゲット話者が一人である場合は、「話者性の復元」プロセスは話者に関して汎化させる必要はありません。複数の話者への変換を目的とする場合は、話者に関して汎化させて学習し、目標となる話者の特徴(上図の緑部分)を途中で付け加えて復元することが多いです。
こうしたモデルの構成・要件は、従来主流であったパラレルデータ(同じ発話内容を様々な話者に発声させた音声データセット)を用いた一対一の音声変換とは大きく異なります。パラレルデータを利用する場合は、話者非依存の言語情報が入出力で同一であるので、わざわざ話者性を分離する必要がありませんでした。そのため、入出力の音声データの対応を分析し、音響特徴を変換する手法を考えるだけで済んだのです。ただ、パラレルデータの制作はコストが非常に大きく、複数の話者のパラレル音声を集めることは非実践的で応用の幅が限られています。
こうしたことを背景に、ノンパラレルデータ(複数話者の異なる発話音声を集めたデータセット)を活用する手法が近年の音声変換研究の中心です。データセット内で言語の情報がバラバラなので、この情報の影響を受けずに音声を変換したいのです。そのため話者性と言語情報をなんとか分離し、ソースの話者性を取り除き(情報のボトルネックを作る)、ターゲットの話者性を使い音声を復元します。そのボトルネックを通る言語情報の種類は、文字列・音素列だけでなく、いろいろ考えられます。例えば、(かなり特殊な例ですが)口の動きの電磁信号(Electromagnetic Articulatory; EMA)を正規化したものが話者性に依存しない言語情報になることを活かした研究4もあります。今のところ、「どう情報のボトルネックを作れば良いか」という問いに答えはありません。すなわち、情報のボトルネックの設計は音声変換の研究者のクリエイティブさが試される部分の一つです。例えば、本記事では、エンコーダ・デコーダ型の系列変換モデル、VAE、U-net型のGeneratorを持つGANなどでボトルネックを作る手法が登場します。
また機械学習技術の発展により、音声変換の固有の知識や理論(ソースフィルタモデルや線形予測符号など)に頼るだけではなく、別の音声タスクや画像処理の研究成果を音声変換に適用することが可能になりました。その結果、多種多様の音声変換手法が提案・研究されています。サーベイ論文5では機械学習以前の音声変換手法やそこからの進展について詳しく紹介しています。本記事では、2016年以降に登場した機械学習ベースの音声変換に焦点を絞っています。これらの手法をベースとなる技術や関連する研究の観点から4つに大別し、それぞれの手法の発達の流れと各手法の代表例を1つ挙げて具体的に解説します。
**参考・初めて音声変換システムを評価する人向け**
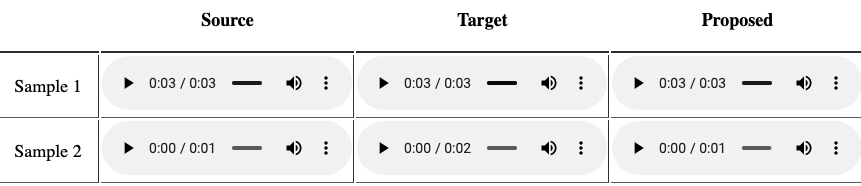
音声認識は音声からテキスト、音声合成はテキストから音声、と入出力のモーダルが違うので感覚的に評価しやすいです。一方で、音声変換は、音声から音声への変換の評価になるので「入出力でどう変わったか?」と把握することが初めは難しいです。ここでは音声変換の出力結果を評価するコツを紹介します。親切な研究者たちは提案手法のデモとして、以下の図のように3つの音声を用意することが多いです。Sourceは変換モデルの入力となる人の音声、Targetはターゲット話者の本物の録音音声(マネしたい人の音声)になります。そして、Proposedでは、Sourceを入力した時の提案手法の出力になります。ノンパラレルデータで音声変換を学習する場合でも、提案手法の性能を見る時はパラレルデータ(CMU Arcticなど)を使い実際の録音音声と変換音声を比較する場合があります。比較する際にはいくつかコツがあり、例えば、音声の変化がわかりやすい異性間の変換の確認を優先したり、(パラレルデータで比較している場合)変換後の音声の時間長がターゲットの音声と等しい(話速を変換できている)か確認するというポイントがあります。
音声認識の学習を活用する手法
上述のように、音声変換では、入力の音声から「話者に依存する特徴」と「話者に依存しない言語や音韻の特徴」を分離する(disentangle)必要があります。しかし、一般的にこうした複雑なタスクを実現するために必要なデータは膨大で、音声変換に最適なパラレルデータを用意することは現実的でありません。そこで、同様のタスクに特化し、データと研究のリソースがより多い別分野の研究成果を有効活用する手法が注目されています。本章では音声認識を活用した音声変換の研究例を、次章で音声合成を活用する研究例を紹介します。
下図にあるように、一般的に音声認識では、音声(話者に依存する)を入力にとり、文字列または音素列(話者に依存しない)を出力します。機械学習のモデルで考えると、入力層に与えられる音声の情報から、各層での変換で徐々に入力から話者性を取り除き、出力層で完全に話者性が抜けた言語情報を得ます。音声変換として注目する点は、この変換の途中(主に出力層または出力層付近)で、音声を作る上で必要な「話者に依存しない言語情報」が生成されていると考えられる点です。
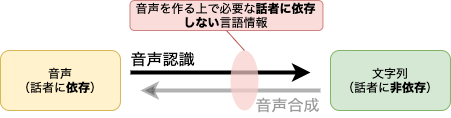
ここで重要なことは、音声変換として活用したい情報は、単に話者に依存しない言語情報(文字列や音素列)ではありません。なぜなら、こうした簡単な情報では、音声変換でうまく音声を生成できないからです。例えば、「正月(しょうがつ)」という文字の言語情報だけでは、「う」を明確に発音せず「しょーがつ」と一般的な(話者に依存しない)発声をするための音韻の情報を捉えられません。例の問題は、音素を使用することで解決できますが、実際にリアルな音声を作る上で必要な「話者に依存しない言語情報」は想像以上に複雑です(例えば、音声を合成するために必要な言語情報として、従来のHMMベースの音声合成では53種類6の情報を使う)。故に、こうした特徴を知識ベースで設計するのではなく、高度な機械学習モデルを用いてデータ・ドリブンに学習しようという考えが背景にあります。
PPG
近年、この「音声の生成に必要な言語情報」として、音声認識を活用する手法の中で有力視されているものが、Phonetic PosteriorGrams(PPG)です。PPGとは、音素クラスの事後確率を時間軸上に表現する下図のような行列(時間のフレーム数x音素クラスの行列)です。PPGは、音声認識システムの出力で使われることが多く、マルチ話者音声認識を学習することで、話者に依存しないPPGを得ることができます。(Sun, 2016)7らは、マルチ話者音声認識システムから抽出したPPGを話者に依存しない言語情報として扱い、ノンパラレルデータを用いて多対一音声変換を実現しました。ここで使うPPGは、学習済みの音声認識器から得られるもので、これらは音声認識用の大規模な音声コーパスを利用した学習の結果であり、質が良いという強みがあります。Taco-VC8(サンプル音声)でも同様に、入力音声を学習済みの音声認識器を用いてPPGの表現に変換していますが、その後に続く、話者性を復元するプロセスでより優れたモデルを適応することを提案しています。
音声認識を活用する手法の強みの一つが、大規模な音声コーパスを活用できる点です。しかし、大規模な音声コーパスは主に英語音声であるので、その他の言語で音声変換を構築するには工夫が必要です。PPGは、短い時間フレーム(例えば12.5ms)を単位にする特徴で、このような短い時間フレームの特徴は言語に依存しないと考えられています9。なので、PPGの表現は、話者だけでなく言語にも依存しない音声の表現方法として扱えます。これは、日本語の音声変換を狙う上では便利な発想で、大規模な英語音声のコーパスで学習した高性能な話者非依存の音声認識を、そのまま日本語のPPGの抽出に使える可能性があるということです。同様の発想に基づき、英語の音声認識器からPPGを抽出し、中国語の音声生成に使用しています10。しかし、この研究では言語間で登場する音素の分布が異なることから、単純に異なる言語の音声認識をPPGの抽出に扱うことが難しいことが報告されています。そこで、(Zhou, 2019)11らは、高性能な英語の音声認識器に加えて、ターゲットのなる言語(中国語)の音声認識器も別に学習させて、二つのPPGを用いて、話者性を復元するプロセスに入力しています。こうした異なる言語間をPPGを使い橋渡しする手法は、日本語音声変換の研究でも注目に値するといえます。

音声認識のその他の活用
PPGに限らず、音声認識モデルの中間表現が「音声生成に必要な話者非依存の情報」を捉えているこということが実験的に知られています。こうした主張を裏付ける研究もあり、例えば、機械学習ベースの音声認識の中間表現の分析12から、音声認識の中間層から抽出した特徴が、音素や音素の調音方法(子音の摩擦音やはじき音のこと)を表すことがわかっています。
ConVoice13(サンプル音声)は、典型的なエンコーダ・デコーダ型のモデルで、エンコーダ部分は、QuartzNet14を用いる音声認識の4層目までを使います。このエンコーダは、585時間に及ぶ英語の読み上げ音声データセット(LibriTTS15)で学習していて、音声認識器としても最高性能を示すまで学習されています。この音声認識器の4層目の出力をエンコーダの出力、すなわち、「音声生成に必要で話者に依存しない言語情報」として音声変換に活用します。
Parrotron16(サンプル音声)では、音声認識のデコーダを補助的な分類器として学習に組み込んでいます。この音声認識のデコーダは、音声変換のエンコーダの出力を入力にとり、ソース発声の発話内容を推測することを学習します。こうすることで、音声変換のエンコーダは言語情報(発話内容)を保存する低次元への変換を学習することが可能になります。学習済みの音声認識器を用いるので話者性を取り除くためには強力な手法ですが、デコーダで「音声を生成する上で必要な言語情報(アクセントなど)」を獲得するかは未知な部分があります。
PPG-VC
音声認識の学習を活用する手法の代表例として、(Tian, 2020)17を具体的に見ていきましょう。この手法は、(Sun, 2016)7の改良版であり、従来手法では一部の音響特徴($F_0$と非周期成分)をPPG以外に抽出して利用していましたが、本モデルでは完全に機械学習ベースの音声認識器のみで話者の情報を取り除きます。他にも、ニューラルボコーダへの対応、マルチ話者TTSモデルを使うことで、多対一だけでなく多対多の変換を可能にしています。
PPG-VCの実現には、話者非依存のPPGを抽出する音声認識器と、獲得したPPGを音声に変換する変換モデルの2つを学習する必要があります。音声認識器の学習では、音声認識用の大規模音声コーパスを利用し、本研究では、LibriSpeech18の中から460時間分の1172話者の英語発声を用いています。ここでは、一つの音声認識モデルで多くの話者からPPGの抽出を学習すると話者に依存しないPPGを獲得できるようになると仮定しています。
PPG-VCの変換モデルの学習は下図の(a)と(b)の2つに別れます。(a)では、マルチ話者に対応して話者性を再生する変換を学習します。ここで新たに工夫が加えられており、話者非依存の音声認識器(SI-ASR)から抽出されてボトルネックを通る情報は、PPGそのものではなく、SI-ASRのPPG出力層の一つ手前のボトルネック層から抽出した(PPGよりも低次元)特徴になります。このようにして、マルチ話者のデータで変換モデルを学習した後、(b)のように新たなターゲット話者に変換モデルをチューニングすることができます。最後に、(c)はPPG-VCでの音声変換の流れを示していて、まずソース話者の発声をメルスペクトログラムに変換し、次に話者非依存の音声認識でボトルネック特徴量(発話内容など)を抽出し、その後に、ターゲットの話者性を加えて変換音声のメルスペクトログラムを復元、最後にボコーダでメルスペクトログラムから音声波形を復元します。
 (図・引用[^ppgvc2020])
(図・引用[^ppgvc2020])
音声合成の学習を活用する手法
音声認識の学習によりPPGのような「話者非依存の言語情報」を獲得できますが、こうした特徴は本来、音声を認識するためにあり、音声を生成する場合に必ずしも有効であるとは限りません。一方で、音声合成と音声変換のタスクには共通の目的があり、それは「ターゲット話者の音声を生成する」ということです19。すなわち、音声合成ではテキストを入力とし、音声変換では異なる話者の音声を入力としますが、共通の目的のもとで学習する音声合成のモデルや内部の特徴を音声変換に活用しようとする研究が行われています。
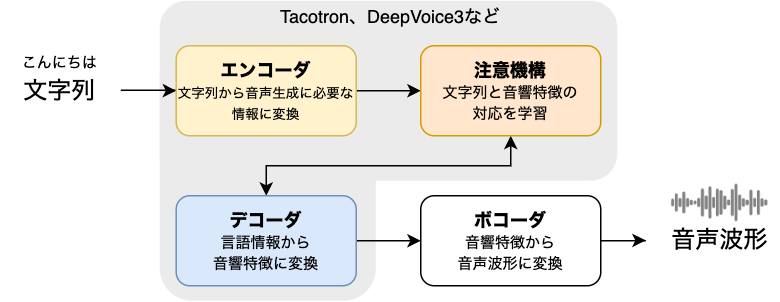
最先端の音声合成モデルは、平文の一般的な読み上げといったタスクでは人間の区別できないレベルの音声を任意のテキストから合成できます。近年の強力な音声合成モデルの多くは下図のような「エンコーダ・デコーダ型の系列変換と注意機構」により構成されています。エンコーダで入力テキストを音声生成に重要な言語情報に変換し、デコーダで言語特徴から出力音声のフレームに変換し、その間の注意機構では、文字単位の言語特徴と音声フレームの対応づけを学習します。出力の音声はメルスペクトログラムで表現されているので、実際の音声を波形に復元するためには別途ボコーダを利用します。
音声変換の研究でよく活用される音声合成モデルは、Googleが開発したTacotron20モデルです。これも強力なエンコーダ・デコーダ+注意機構を備えていて、既にGoogleの様々なプロダクトで実用されています21。特に、注意機構に工夫が施されていて、人間が文字を読み上げる際に視線の動きを模倣・学習することを達成しています22。要するに、人が文字を読み上げる際に視線(注意)を一方向に動かすように、注意機構で言語情報と音響特徴の対応づける時に後戻りをしなくなっています。
ここで注意することは、音声合成のデコーダなどをモジュールとして転用する際の入力です。音声合成の入力であるテキストの長さと音声変換の入力である音声の入力の長さ(時間フレームの数)は大きく異なります。しかし、実はこれらのモジュールは初めから再帰型ニューラルネットなどを活用していて可変長に対応しています。ですので、比較的簡単に音声変換に転用することが可能です。
上述のように、音声合成と音声変換は目的が似ているタスクであるので、(Zhang, 19)23らは音声合成と音声変換を一つのモデルで同時に学習する手法を提案しました。初期のTacotronモデルにテキスト入力用のエンコーダに加えて、音声入力用のエンコーダを付け足し、後者を音声変換の場合に使用します。独立した2つの注意機構を用いて異なるエンコーダ出力に対応し、同一のデコーダにつなげています。この手法では音声合成用の大規模なデータで音声変換のデコーダを学習できるという強みがあります。一方で、many-to-oneの音声変換を実現したい場合、パラレルデータが必要になります。(Luong, 19)19らは、同様に音声合成のデコーダを共用する構成に加えて、音声変換用のエンコーダを教師なし学習で新しい話者に対応させる手法を導入し、ノンパラレルデータのみでany-to-oneの音声変換を実現しました。このような音声合成のデコーダを共用する手法では、大規模な英語のコーパスで学習した高性能な音声合成のデコーダを、少リソースの言語向けの音声変換で共用できます。例えば、日本語の少量データで再学習すると、容易に日本語の音声変換を実現できる可能性があります。
Cotatron24(サンプル音声)は、音声変換で必要な「話者性非依存の言語情報」を獲得するために、音声変換用のエンコーダの学習で読み上げテキスト(トランスクリプト)を教師データとして与えて、音声合成の学習済みエンコーダと注意機構の出力を簡易的に計算し言語情報を獲得します。ここで、音声合成用の高品質で話者非依存のテキスト・エンコーダと注意機構を用いるので、得られる言語情報(Cotatron特徴)も高品質になります。音声変換のデコーダとしては、Tacotronのデコーダを採用し、Cotatron特徴と特定の話者の情報を入力として、スペクトログラムの復元ロスで学習します。Cotatronの扱いで注意すべき点は、実際に音声を変換する際には、変換するソース音声のトランスクリプトが必要になるという点です。この特殊な入力の条件が、Cotatronの応用可能性を狭める懸念があります。Voice Transformer Network25(サンプル音声)も同様に、学習済みの音声合成を活用する試みで、こちらはTacotronではなくTransformerの構造を利用します。音声変換のための学習ではパラレルデータが必要になることと、Transformerはメモリの使用量が大きいことに注意する必要があります。この手法の詳細については同僚のまとめ記事26を参考にしてください。また、同系列の手法でmany-to-many変換に対応したモデルも提案されています27。
TTL-VC
Text-to-Speech Transfer Learning for Voice Conversion28(以下、TTL-VC;サンプル音声)は、今まで紹介した音声合成の学習を活用するモデルの一つの完成形ともいえる手法です。事前学習した音声合成のデコーダを推論時に活用し、学習時には音声合成のエンコーダも活用します。活用する音声合成のモデルはTacotron2です。
TTL-VCでは、学習済みのTacotron2を活用することで以下の点で恩恵を得ています。
-
音声合成のエンコーダの出力(Context Vector;文脈情報ベクトル)を活用し、話者性を除いた埋め込み表現を作ることが可能な点
-
学習済みの音声合成のデコーダをシンプルにそのまま使える点
-
比較的収集しやすい(ノンパラレルな)音声合成コーパスを用いて音声変換タスクを学習可能な点
TTL-VCの学習
下図にTTL-VCの学習手法を示します。図の上の部分はTacotron2の学習で、下の部分の音声変換の学習とパラレルになっていて構造としてはシンプルです。音声変換と音声合成用の2種類のエンコーダ($Encoder_S$と$Encoder_{T}$)が登場します。$Encoder_S$はメルスペクトログラムのフレームを入力にとり、$Encoder_T$は文字列を入力にとり、それぞれ独立してcontext vector $H_S$と$H_T$を生成します。ポイントは、ここで生成するContext Vector $H_S$が$H_T$に近づくように、以下のような制約 $Loss_{cont}$を加えます:
$Loss_{cont} = \mathop{\mathbb{E}}[|| H_S - H_T||_{2}^2 ]$
$H_T$はテキスト入力から生成され、元々マルチ話者音声合成向けに学習したものなので話者に関しても汎化し、依存しないと考えられます。なので、$Encoder_S$は$H_T$を「話者に依存しない言語情報」として獲得したいのです。実際に、Tacotron2と同様のEnd-to-End音声合成システムのcontext vectorでは、音素や音韻の情報が獲得されることが実験的に示されています29。
以上が$Encoder_S$の学習に必要な計算です。$Decoder$は音声合成のデータセット(テキスト$X_T$と音声スペクトログラム$Y_S$)を使って学習します。$Encoder_T$を使い、$X_T$から$H_T$を生成します。その後、話者情報$z$とともに$Decoder$に入力し出力音声$\hat{Y}_S$を以下のように得ます。
$\hat{Y_S} = Decoder(concat(H_T, z))$
そして、学習データである本物のターゲット音声$Y$と比較する
$Loss_{mel} = \mathop{\mathbb{E}}[|| Y_S - \hat{Y_S} ||_{2}^2 ]$
で出力音声をターゲットに近づけるように学習します。
音声合成用に学習された$Decoder$をそのまま使うことが可能ですが、論文では音声合成と同様の方法で、$Decoder$の入力だけ$H_T$ではなくて$H_S$を使い再学習し音声変換により良く適応することを狙います。最終的なロスは$Loss_{joint}$は先の2つを足し合わせた
$Loss_{joint} = Loss_{cont} + Loss_{mel}$
になります。

(図・引用28)
TTL-VCの評価
原論文でまとめられているTTL-VC28の評価結果で注目すべきポイントは、MS-TTS(マルチ話者Tacotron2)との比較で主観評価(Mean Opinion Score;MOS)がほぼ同等になるということです。TTL-VCの様な音声合成の学習に頼るモデルは、同一手法の音声合成の性能が性能限界であると考えられます。なので、TTL-VCは音声合成を活用する手法の中では完成形といえるかもしれません。また、他のベースラインの比較(2016年版のPPG-VC7、VAEベースの手法)では、TTL-VCの音声変換は圧倒的に高品質であることを示しています。
TTL-VCに関しては、音声チームの同僚の詳しい説明30を参考にしてください。実際にTTL-VCを実装し検証する中で、論文で言及されていない問題が出てきて、その解決手法についても説明しています。
ちょっと待って、音声認識と音声合成だけでよくない?
さて、音声認識や音声合成を部分的に活用する手法を見てきました。なぜ音声認識と音声合成をそのまま使い音声変換しない?と疑問に思った方もいるかもしれません。確かに、音声認識で発話内容を文字に起こし、マルチ話者音声合成で好きなターゲット話者の音声を作ることも音声変換です。例えば、「名探偵コナン」に登場する「蝶ネクタイ型変声機」はこの発想に従っていて、ソース話者(コナン君)の話者情報は変換後の音声(毛利小五郎)では完全に失われるようです(ただし平次の声に変換した時におかしな関西弁のイントネーションが残ったりすることもある)。
要するに、この手法は「音声入力可能な音声合成器」です。それはそれで価値あるアプリケーション(音声翻訳など)ですが、音声変換としては非効率的で面白味にかけます。ユーザにとって面白い音声変換とは、ただ発話内容をターゲット音声で伝達するだけでなく、ソース話者の言語以外の情報(程度の問題ですが例えば、感情やイントネーション)が残り、自分と異なる人物の発声をコントロールできる変換ではないでしょうか。こうした考えから、(文字列に落とし込まず)ある種の話者情報を残しつつ変換する手法が求められます。
とはいうものの、音声認識・音声合成と音声変換は切っても切れない縁です。これまでの説明のように、よりポピュラーな前者の技術を転用するところから音声変換の研究が始まったりします。音声合成技術の研究をしてきたDeNAとしては、過去の研究リソースを活用できるという点で注目度が高いです。
オートエンコーダを活用する手法
さて、音声変換において「話者性に依存しない言語情報」を分離することが研究の要点の一つというところを見てきました。このように重要な特徴を抽出したり、情報の次元を上手に圧縮することは機械学習の研究の共通のテーマです。このようなタスクに特化した代表的な手法がオートエンコーダです。その名から推察されるように、上述のエンコーダ・デコーダ型のネットワークに基づき、情報のボトルネックを介してエンコーダの入力をデコーダの出力で復元することを学習します。このような学習を通して、入力の情報のエッセンス(ここらの研究ではlatent variableやcodeと呼ばれる)がボトルネックを通過し、その少ない情報からデコーダ側で元の入力を復元が可能になります。
下の図でオートエンコーダの構成を示すように、入力と入力の復元の比較(復元誤差)だけで学習する教師なし学習で、オートと言われる所以です。つまり、音声認識・音声合成を活用した手法では、大規模なコーパス(音声+トランスクリプト)が必要で英語以外の少リソースの言語での適用は容易ではありませんでしたが、オートエンコーダを活用すれば音声のみの学習が可能になります。
オートエンコーダの弱み
単純なオートエンコーダ(vanilla auto-encoder;理論的には非線形PCA)で学習されるボトルネックの特徴は、入力の分類や複製系(ノイズ除去31など)のタスクでは強力ですが音声変換などの「生成」タスクに向いていないといわれていて32、理由としては大きく以下の2つがあります。
-
オートエンコーダは非連続的なボトルネックの特徴を獲得する傾向にあり33、連続的な特徴の分布(生成モデル)からサンプリングしたい生成のタスクには向いていないこと
-
前述の方法でPPGや音声合成のエンコーダ出力を使いボトルネックの特徴をモデル化していたが、単純なオートエンコーダでは学習する特徴をコントロールできないこと
Variational Auto-Encoder
Variational Auto-Encoder(VAE)はオートエンコーダから派生した手法です。オートエンコーダの決定的な違いは、VAEでは正規分布からボトルネックの特徴が生成されると仮定して学習します。すなわち、正規分布から生成されるボトルネックの情報は連続的になり生成タスクに向いているといえます。この強みをVAEは次のように(下図参照)実現します。まず、エンコーダがボトルネックの特徴をそのまま出力するのではなく、ボトルネックの特徴を生成する正規分布のパラメタ(平均と標準偏差)を出力します。この分布が正規分布に近づくように新しく追加された制約が図のKL誤差です。その後、その分布からランダムサンプリングしてボトルネック特徴を生成します。ランダムサンプリングをニューラルネットの途中で取り入れると、単純には誤差逆伝播(backpropagation)で学習できません。そこでVAEの原論文34では、reparametization trickという呼ばれる方法を使い学習可能にしました。
これらの手法で注目すべき点は、ボトルネックのパラメータを選択することでボトルネックの特徴を生成する分布の設計できるという点です。このような設計が上手くいくと優れた音声変換モデルを学習する可能性があります。一方で、音声認識や音声合成の学習で得られる言語に関する情報を一切使わないので、質の良い特徴を捉える難しさもあります28。

オートエンコーダを活用する手法は、よりボトルネックの設計を意識するモデルです。そこで、ボトルネックの情報に関しておさらいしてみましょう。下図で、(a, b, c)は音声変換の学習の様子を表していて、入力の音声がボトルネックを通り(話者非依存の情報を抽出し)、元の音声に復元できるように学習しています。(a)はボトルネックが広すぎた場合で、話者非依存の言語情報に加えて、話者情報がボトルネックを通ってしまい、これでは実際の変換ではソース話者の話者性が変換後の音声に残ります。(b)では逆にボトルネックが狭すぎて、変換後の音声がソース音声の発話内容の一部を失っています(読みミスなどを引き起こす)。(c)が適切なボトルネックを設計できた場合の様子です。(d)では、適切なボトルネックにより適切にソースの話者性が取り除かれ、任意のターゲットの話者性を加えて変換する様子を示しています。

(図・引用35)
以上のように、適切なボトルネックを設計することがオートエンコーダを活用する音声変換の決め手です。
オートエンコーダを活用する音声変換の研究の初期に、(Hsu, 2016)36らによってVAEを活用するモデルが提案されました。この研究で、VAEのボトルネックの特徴を使い「話者情報」と「言語情報」を分離できることが示されました。以降の研究では、他の手法と同様に「話者性の分離と復元」という点での改善が中心です。例えば、(Hsu, 2018)37では、CDVAE(Cross-domain VAE;サンプル音声)と呼ばれる2つのVAEの組み合わせを用意し、異なる音声のスペクトル表現(STRAIGHTスペクトル38とメルケプストラム係数)を入力に与え、それぞれが作るボトルネック表現が同一になるように制限をかけます。これによりで入力によらず一般化されたボトルネックの特徴を獲得するように学習が進み、話者性をより良く取り除けることを示しました。(Chou, 2019;サンプル音声)39らは、画像処理の分野で広く使われているAdaptive Instance Normalization40(AdaIN)とInstancce Normalization41を使い、「話者情報」をより良く分離する手法を提案しています。また(Saito, 2018)42らは、VAEのエンコーダで「話者非依存の言語情報」を推測するのではなく、度々登場するPPGをエンコーダ・デコーダどちらにも条件づけて学習し、言語情報が保存する手法を提案しています。
CycleVAE-VC43では、ノンパラレルデータを扱う上での基本的な問題として「(比較となる本物のターゲットの読み上げ音声がないので)ターゲット話者で復元された音声で直接モデルを最適化できない」点を挙げ、この問題の解決をVAEの活用により実現しています。具体的には、ターゲット話者で復元された音声を再びVAEの変換モデルに入力し、本物の音声があるソース話者の音声に変換し比較します。そうすることで変換された音声を用いて直接モデルを最適化することを実現します。ターゲットの話者性を変換先でより良く反映させるということについては、ACVAE-VC44(サンプル音声)では、補助的な分離器を使い、変換後の音声からターゲットの話者を分類するタスクを設定し、そのタスクの誤差を変換モデルの学習に使います。これにより変換音声にターゲットの話者性がより反映されることを示しています。
ところで、VAEの一般的な問題点として"posterior collapse"という現象が知られています。これはデコーダがボトルネックの特徴を無視するという現象で、自己回帰型のネットワーク(例えば、WaveNet)をデコーダに使うVAEで顕著です。この問題の対策として離散的なボトルネックの特徴を作るVAE(VQVAE45)が提案され、これをmany-to-manyの音声変換に適応したモデルはVQVAE-VC45として知られています。この方法により、ボトルネックの特徴に音素の情報がより多く保存されることを示しました。一方で、離散的なボトルネックの特徴を生成することで、単純なオートエンコーダで見た弱みに関連し、変換後の音声で発音ミスなど引き起こします。そうした問題を解決するために、VQVAE-VCのボトルネックの特徴を上手く配置・グループ化する手法が提案されています46。
また、VAEは生成モデルである確率分布を明示的にモデル化してから学習するので、平均的で「ぼやけた(over-smoothed)」出力になりがちです。こうした問題を解決するために、VAEをGAN(後述)を取り入れる手法が音声変換47を含めた様々なタスク48で研究されています。本記事では、これらの手法に関しては参照するまでにしておきます。
SPEECHFLOW (a.k.a SpeechSplit)
単純なオートエンコーダは、上述のように音声変換のような「生成」タスクに適していないといわれています。こうした懸念とは裏腹に、単純なオートエンコーダに注意深いボトルネックの設計を施しただけの有力な音声変換モデル、SPEECHFLOW49(デモページ)が知られています。SPEECHFLOWは、人間の音声を「発話内容」「音色(timbre)」「リズム(話速)」「ピッチ(音高)」の4つに明確に分解し、それぞれを独立して音声変換することもできる画期的なモデルです。
SPEECHFLOWは同じ著者が提案したAutoVC35(サンプル音声)というモデルの進化系で、AutoVCもVAEではなく単純なオートエンコーダの構造をしています。AutoVCでは、注意深くボトルネックを設計することで、一つのエンコーダは他のエンコーダが表現できない情報だけ表現するようになるということを理論的に示しています。つまり、外部から「音色」の情報を含め話者性の情報を与えているなら、デコーダはエンコーダ出力に含まれる話者性を持つ音色の情報がなくとも復元誤差を下げるようにでき、結果的にエンコーダ出力(ボトルネックの情報)から音色の情報を取り除くことができます。
先の2つの論文では、ボトルネックを「注意深く設計する」という表現がよく出てきますが、要するにハイパーパラメタチューニング50という意味だと思われます。SPEECHFLOWとAutoVCのどちらにも、下図のようなダウン/アップサンプリング層がボトルネック部分で使われています。どちらのモデルでもエンコーダは2方向性のLSTM(BiLSTM)を使っていて、ボトルネックのパラメタとして「LSTMの出力の次元(2方向あり$C_{\rightarrow}$と$C_{\leftarrow}$;言語情報を表せる容量)」と「ダウンサンプリングのサイズ($T$;時系列上の情報量)」を操作できます。ボトルネックを狭くしたい場合、$C_{\rightarrow}$と$C_{\leftarrow}$を減らすか$T$を増やし、逆もまた然りです。こうしてパラメタを調整しながら学習結果の良くなる組み合わせを見つける必要があると推測されます。また、AutoVCの論文では、調整されたパラメタが実際に「話者の分離」に効果的であることを実験的に示しています(原論文35Table 1)。
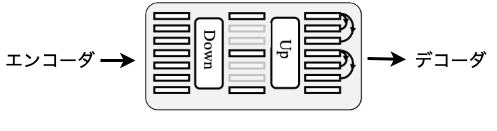
(図・引用35(筆者により一部改変))
下図の比較からわかるように、SPEECHFLOWでAutoVCから改善された点は、「音色」に加えて「リズム($R$)」「ピッチ($f$)」「発話内容($C$)」の分離が可能になった点です。SPEECHFLOWではこれら情報を分離するために、それぞれの情報の特性に応じて3つのエンコーダ($E_R$、$E_C$、$E_f$)のボトルネックを注意深く設計します。まず、「リズム」の情報を分離する方法ですが、リズムを抽出するエンコーダ$E_R$以外のエンコーダの入力で、ランダムリサンプリング(RR)という時系列構造を壊す仕組みを導入します。これにより、$E_R$だけが「リズム」情報を保存する特徴$Z_R$に学習します。こうなると「発話内容」の情報を保存できるエンコーダは$E_C$だけになり(注:$E_f$の入力に$C$は含まれてない)、$E_C$は$C$だけ保存する特徴$Z_C$を学習します。最後に、「ピッチ」以外の音声の特徴は既に保存されるので、$E_f$はピッチ等高線の入力から「ピッチ」情報のみ保存する$Z_f$を学習します。それぞれのエンコーダのパラメタチューニングの結果は(原論文49Table1)で与えられます。
 (図・引用[^speechflow])
(図・引用[^speechflow])
SPEECHFLOWは「音色」の情報の変換(外部から与える話者情報のみ使う場合でAutoVCと条件が等しい場合)で、AutoVCの変換音声よりも主観評価で優れています。また、AutoVCの優れた成果を継承しています。例えば、話者情報としてone-hotベクトルで与えるのではなく、話者の埋め込み情報(i-vector51やx-vector52)に置き換えて条件づけることで無数のソース話者に学習なしで対応できるzero-shot変換を実現しています。また、AutoVCの論文は理論的な説明も豊富で、上述のボトルネックの設計の状態(d)のように、オートエンコーダのボトルネックを正しく設計することで完全にターゲット音声に変換できることを理論的に示しています。AutoVCに関しては、同じく音声チームの同僚による詳しい説明53を参考にしてください。
GANベースの手法
4つ目の音声変換の手法として、GANベースの手法を紹介します。GANはGenerator(G)とDiscriminator(D)の2つのネットワークから構成されます。音声変換では、$G_{X \rightarrow Y}$がソース話者からターゲット話者へ音声を変換し、$D_{Y}$は音声が本物(ターゲット話者の発声)か偽物(ソース話者から変換された発声)かを見分けます。GANが、他のネットワークと大きく異なることは、$G$と$D$を相互かつ敵対的に訓練するという点です。
GANの学習について、もう少し詳しく見てみましょう。ネットワークをNとし、ロス(損失関数)を$L(N)$と表す場合、初歩的なGANで使われるロス(Adversarial Loss)$Loss_{adv}$は交差エントロピーの形をしていて
$Loss_{adv}(G_{X \rightarrow Y}, D_Y) = $
$\mathop{\mathbb{E}}_ {y \sim p_{data}(y)}[\log D_Y(y)] + \mathop{\mathbb{E}}_ {x \sim p_{data}(x)}[\log (1 - D_Y(G_{X \rightarrow Y}(x))]$
となります。$G_{X \rightarrow Y}$はこのロスを最小化する($D_{Y}$が変換音声$G_{X \rightarrow Y}(x)$を本物と間違える)ように学習し、$D_Y$はロスを最大化するように学習します。もともと$D_Y$の出力は本物であるかの予測、すなわち確率でした。ただ、$D$が確率を出力するためにシグモイド関数を使うことで勾配消失を引き起こすので、最近の$D$の出力は確率でないことが多いです。後述のモデルで出てきますが、WGAN54では、$D$は本物か偽物のスコアを計算し、その差を出力します。また、この$D$を普通の$D$と区別するためにCriticと呼ぶことがあります。
GANの強みは、VAEよりも「よりリアルな出力」を生成できる点です。VAEでは、KL誤差を導入し潜在変数の分布が正規分布になるように制約をかけていました。こうした強い制約をつけることで、(イメージとしては)似た入力は潜在空間でかなり近くで表現されます55。その結果、入力にある細かい違いは変換の中で無視されて、平均的で「ぼやっと」した出力になる傾向があります。GANでは、こうした制約がないので、よりはっきりとした出力を得ることができます。
GANの研究は機械学習の中でも新しい分野で問題が多くあります56。GANの学習の設定では、$G$の「本物に似たデータを生成するタスク」の方が、$D$の「入力の真贋を見分ける」タスクより難しそうです。こうした直感に基づき$G$と$D$の学習回数をうまく調整する必要があります。この学習のバランスが崩れると、画像生成タスクなどで知られるモード崩壊54($G$が任意の入力に対して同一的な変換するようになる)といった現象が起こります。このように、普通の教師あり学習ではロスが減れば基本的に変換が上達していますが、GANではそうなりません。$G$と$D$は敵対的に学習していくので、それぞれのロスの推移は原理的に常に拮抗します。多くの場合、$G$の生成出力が主観的に満足できるものになった時が、学習のやめ時です。Spectral Normarization57などで安定した学習を実現しやすくなったものの、学習の不安定さ・不確実さゆえに、今のところ最初に試す手法としてGANベースの手法を選ぶことは推奨されていません58。
ちなみにGANはもともとノイズ画像を入力して、新しい画像を生成するDCGAN59の研究が有名です。このようにノイズデータを入力する場合は、Unconditional GANと呼び、ノイズでない場合をConditional GANと呼びます。音声変換で使用する場合は、必ずソース話者の音声が$G$の入力となるのでConditional GANのみ登場します。

GANベースの手法の研究例
one-to-one変換の場合
前置きが長くなりましたが、トレンディなGANを使った音声変換の研究例を見ていきましょう。音声変換でのGANの登場は、画像の変換(Image-to-Image Translation)の研究成果を適用するところから始まりました。画像の変換といえば、ある画像のドメイン(例えば、リンゴの画像)から異なる画像のドメイン(例えば、オレンジの画像)に変換するタスクが一般的です60。この画像処理のタスクをうまく実現したモデルがCycleGAN61です。CycleGANは$Loss_{adv}$に加えて、すでにある$G_{X \rightarrow Y}$と逆の変換を行う$G_{Y \rightarrow X}$と$D_{Y \rightarrow X}$を用意し(全部で$G$が2つ、$D$が2つのネットワークで構成される)、cycle consistency lossを計算することで、ノンパラレルなデータで変換を学習することを可能にします。
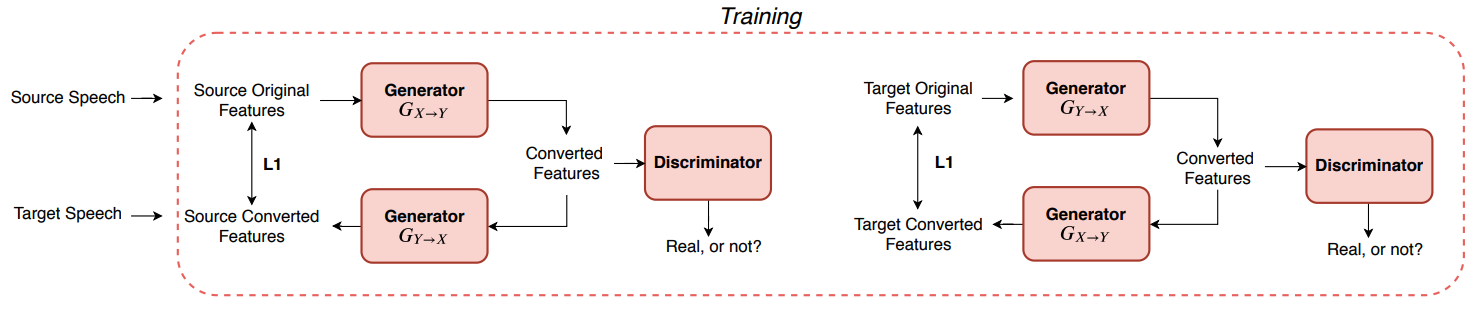
(cycle-consistency-lossの例・引用62)
CycleGANを音声変換に適用した場合、一人の話者が一つの画像ドメインに対応するといえるので、モデルが学習する変換はone-to-oneになります。CycleGANを実現した音声変換モデルがCycleGAN-VC62(サンプル音声)です。CycleGAN-VCは音声を変換するGのネットワークでダウン/アップサンプリングを取り入れて情報のボトルネックを作っています。ただ、CycleGAN-VCを始めとする多くのGANベースの手法で、明示的に中間表現を設計していません。このようにGANベースの音声変換は、ボトルネックの表現(PPGなど)を明示的にモデル化せずに変換するので柔軟性があるといえます。ですので、感情や話者性、話の早さといった大域的な特徴を柔軟に変換する手法の開発が期待されます。
それでも、音声変換であるので、やはり変換を通して「話者性に依存しない言語情報」の保存する(すなわち、発話内容が変換前後で不変である)ことが必要不可欠です。cycle consistency lossは、この目的に対して有効と考えられています。というのは、$G_{X \rightarrow Y}$と逆変換$G_{Y \rightarrow X}$を通して音声が不変になる(ロスが小さい)場合、変換前後で発話内容が不変であるといえるからです。Identity Mapping Loss63(ソース音声がすでにターゲット音声のドメインと同じならば変換により不変にする仕組み)も同様の目的に効果があると報告されています。実験結果からは、ノンパラレルデータで学習したCycleGAN-VCが、パラレルデータで学習したベースラインモデルと同等の音声変換を達成できることが示されました。
CycleGAN-VCは後に改良が加えられて、第二弾64(サンプル音声)では、2つの目の$Loss_{adv}$を加えてOversmoothing効果の改善、PatchGAN Discriminator65の導入、Generatorの改良がなされました。第三弾66(サンプル音声)では、$F_0$とメルケプストラムの別々の入力ではなくメルスペクトログラムの入力に対応し、より複雑な音声の表現を入力できるようになりました。
Scyclone67も、CycleGANにインスパイアされて提案されたモデルで、CycleGAN-VC第二弾の性能を上回ることが報告されています。このモデルの特徴は、CycleGAN-VCにあったダウン/アップサンプリングによるボトルネックを完全に取り払ったことです。また、本研究では線形スペクトログラムを用いた変換の方が、メルスペクトログラムの場合よりも後段のニューラル・ボコーダの性能がより良くなることを報告しています。
MelGAN-VC68(デモビデオ)は、画像変換タスク向けに開発されたTraVelGAN69を音声変換に適用した手法です。cycle consistency lossはGの変換を実質的に制限していて、$G$が複雑な変換を学習することを妨げていると考えて、cycle consistency lossを使っていません。言語情報を保存するための代わりの方法として、Siameseネットワーク70で入出力の音声をそれぞれ2つに分けて(言語情報に相当する)低次元の特徴に変換し、各ペアの特徴ベクトルの距離が変換前後一定になるようにSiameseネットワークを学習することで実現できると主張しています。
many-to-many変換の場合
さて、CycleGANを活用した音声変換はone-to-one変換になると説明しました。many-toの変換にスケールするためには、複数のone-to-one変換を複数用意する方法が考えられます。ただ、$n$話者の間でCycleGAN-VCを用いてmany-to-many変換を実現するには、$n(n-1)/2$のCycleGANの学習が必要で、これらを学習させることは効率的ではありません。また、複数の話者が共有する大域的な音声の特徴というものは確かに存在するにも関わらず、各話者のペアで変換を学習させる方法は音声の本質を無視した非効率的な手法ともいえます。
StarGAN-VC71(サンプル音声)は、画像変換タスクで提案されたStarGAN72モデルを活用し、一つの$G$と$D$で複数話者間での音声変換を可能にした最初のGANベースの手法です。StarGANもcycle-consistency lossを含みますが、CycleGAN-VCとの違いは、$G$と$D$の学習の際に、ターゲット話者を特定するone-hotベクトルを$G$と$D$のそれぞれに与えて条件づける点です。また、StarGANと同様に、Gの変換後の音声にターゲット話者の話者性が十分に反映されるように、Domain Classifierという新しいネットワークを導入しています。StarGAN-VCの第二弾73(サンプル音声)では、学習時にソース・ターゲット話者を特定する話者情報を与える方法、マルチ話者に対応するInstance Normalizationを導入しています。
(Lee, 2019)74もStarGAN-VCと同じ発想で、CycleGAN-VCを複数話者に汎化させる方法を提案しました。StarGAN-VC2よりも先にソース・ターゲット話者の話者情報を与える手法を使い、12話者間での音声変換を実現しました。構造的に見てCycleGAN-VCの性能が限界であると指摘しつつも、複数話者の変換の平均でCycleGAN-VCの主観評価と同等またはそれ以上の結果を出しています。
GAZEV
GANベースの音声変換の代表例としてGAZEV75(サンプル音声)を紹介します。GAZEVはStarGAN-VCに基づいた手法で、AutoVCと同様のzero-shot変換を実現しています。AutoVCの説明で触れたように、zero-shot変換に対応するためには、話者の情報をone-hotベクトルではなく、より密な情報である話者埋め込み表現を使う必要があります。AutoVCでは話者埋め込み表現(Speaker Embedding)を作るために、学習済みの話者認識モデルから取り出した外部の特徴を用いていましたが、GAZEVでは、この話者埋め込み表現の生成も学習に組み込まれています。この新しく追加された話者埋め込み表現は下の図の($F$と$E$)になります。さらに、リッチな情報を持つ話者埋め込み表現を大いに活用するため、$G$にAdaINを導入しています。
このように話者の情報をone-hotベクトルで与えないならば、Domain Classifierは何を分類することになるのでしょうか?GAZEVでは、Domain Classifierで入力話者のジェンダーを分類するように設定しています。こうすることで分類器は大いに簡約になり分類誤差の減りが速くなります。この結果、Domain Classifierが$G$の学習により貢献できるようになると主張しています。ただ、ターゲットの話者性を付与するための
今まで見てきたように、zero-shot変換に対応したノンパラレルの音声変換モデルはいまだにほとんどありません。従って、評価としてはAutoVCとの比較だけになります。結果としては、GAZEVはAutoVCと比べて、変換音声の自然さという点で大いに優れていて、変換音声のターゲット音声との類似度では同程度であることがわかりました。ターゲット音声との類似度では、AutoVCは話者埋め込み表現の大規模なコーパスを使っているにも関わらず、小規模データを使ったGAZEVで同程度の精度を達成しています。このことから、GAZEVをより大きなデータで学習すると結果を更新できる可能性があります。
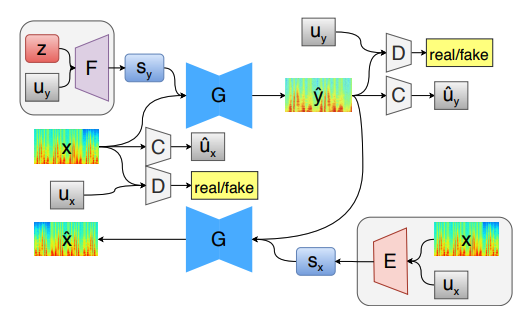
(図・引用75)
結び
最先端の音声変換をザッと紹介してきました。いかがでしたでしょうか?
-
私はマルチモーダルな音声認識や音声合成の手法が気になる!
-
私はVAEを使って話者性を取り除くボトルネックをあれこれ検討したい!
-
私はGANのような柔軟な変換を考えて今までにない音声変換に挑戦したい!
このように読者が音声変換の研究開発の可能性を感じ、音声変換を用いた新しいエンタメに向けた研究開発の一歩となれば光栄です。
謝辞
記事をレビュー・助言していただいた音声チーム・広報部の皆様、お忙しい中ありがとうございました。
宣伝
この記事を読んで「面白かった」「学びがあった」と思っていただけた方、よろしければ Twitter や facebook、はてなブックマークにてコメントをお願いします!
また DeNA 公式 Twitter アカウント @DeNAxTech では、 Blog記事だけでなく色々な勉強会での登壇資料も発信してます。ぜひフォローして下さい!
Follow @DeNAxTech
参考文献
-
Transferring Source Style in Non-Parallel Voice Conversion ↩
-
Articulatory-Based Conversion of Foreign Accents with Deep Neural Networks ↩
-
An Overview of Voice Conversion and its Challenges: From Statistical Modeling to Deep Learning ↩
-
An example of context-dependent label format for HMM-based speech synthesis in English ↩
-
Phonetic posteriorgrams for many-to-one voice conversion without parallel data training ↩ ↩2 ↩3
-
Taco-VC: A Single Speaker Tacotron based Voice Conversion with Limited Data ↩
-
A frame mapping based hmm approach to cross-lingual voice transformation ↩
-
Personalized, Cross-Lingual TTS Using Phonetic Posteriorgrams ↩
-
Cross-lingual Voice Conversion with Bilingual Phonetic Posteriorgram and Average Modeling ↩
-
Analyzing Phonetic and Graphemic Representations in End-to-End Automatic Speech Recognition ↩
-
ConVoice: Real-Time Zero-Shot Voice Style Transfer with Convolutional Network ↩
-
QuartzNet: Deep Automatic Speech Recognition with 1D Time-Channel Separable Convolutions ↩
-
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech ↩
-
Parrotron: An End-to-End Speech-to-Speech Conversion Model and its Applications to Hearing-Impaired Speech and Speech Separation ↩
-
Librispeech: An ASR corpus based on public domain audio books ↩
-
Bootstrapping non-parallel voice conversion from speaker-adaptive text-to-speech ↩ ↩2
-
Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions ↩
-
Google says its Parallel Tacotron model generates synthetic voices 13 times faster than its predecessor ↩
-
https://github.com/Rayhane-mamah/Tacotron-2/wiki/Spectrogram-Feature-prediction-network ↩
-
Joint training framework for text-to-speech and voice conversion using multi-source Tacotron and WaveNet ↩
-
Cotatron: Transcription-Guided Speech Encoder for Any-to-Many Voice Conversion without Parallel Data ↩
-
Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining ↩
-
Transfer Learning from Speech Synthesis to Voice Conversion with Non-Parallel Training Data ↩ ↩2 ↩3 ↩4
-
論文解説:Transfer Learning from Speech Synthesis to Voice Conversion with Non-Parallel Training Data ↩
-
https://www.isca-speech.org/archive/archive_papers/interspeech_2013/i13_0436.pdf ↩
-
When should I use a variational autoencoder as opposed to an autoencoder? ↩
-
AUTOVC: Zero-Shot Voice Style Transfer with Only Autoencoder Loss ↩ ↩2 ↩3 ↩4
-
Voice Conversion from Non-parallel Corpora Using Variational Auto-encoder ↩
-
Voice Conversion Based on Cross-Domain Features Using Variational Auto Encoders ↩
-
Tandem-STRAIGHT: A temporally stable power spectral representation for periodic signals and applications to interference-free spectrum, F0, and aperiodicity estimation ↩
-
One-shot Voice Conversion by Separating Speaker and Content Representations with Instance Normalization ↩
-
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization ↩
-
Instance Normalization: The Missing Ingredient for Fast Stylization ↩
-
NON-PARALLEL VOICE CONVERSION USING VARIATIONAL AUTOENCODERS CONDITIONED BY PHONETIC POSTERIORGRAMS AND D-VECTORS ↩
-
Non-Parallel Voice Conversion with Cyclic Variational Autoencoder ↩
-
ACVAE-VC: Non-parallel many-to-many voice conversion with auxiliary classifier variational autoencoder ↩
-
Group Latent Embedding for Vector Quantized Variational Autoencoder in Non-Parallel Voice Conversion ↩
-
Voice Conversion from Unaligned Corpora using Variational Autoencoding Wasserstein Generative Adversarial Networks ↩
-
Autoencoding beyond pixels using a learned similarity metric ↩
-
Unsupervised Speech Decomposition via Triple Information Bottleneck ↩ ↩2
-
Deep Neural Network Embeddings for Text-Independent Speaker Verification ↩
-
Spectral Normalization for Generative Adversarial Networks ↩
-
Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks ↩
-
CycleGAN Apple-to-Orange Translation Trained on ImageNet Competition Data ↩
-
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks ↩
-
Parallel-Data-Free Voice Conversion Using Cycle-Consistent Adversarial Networks ↩ ↩2
-
Semantic Consistency and Identity Mapping Multi-Component Generative Adversarial Network for Person Re-Identification ↩
-
CycleGAN-VC2: Improved CycleGAN-based Non-parallel Voice Conversion ↩
-
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/39#issuecomment-305575964 ↩
-
CycleGAN-VC3: Examining and Improving CycleGAN-VCs for Mel-spectrogram Conversion ↩
-
Scyclone: High-Quality and Parallel-Data-Free Voice Conversion Using Spectrogram and Cycle-Consistent Adversarial Networks ↩
-
MelGAN-VC: Voice Conversion and Audio Style Transfer on arbitrarily long samples using Spectrograms ↩
-
TraVeLGAN: Image-to-image Translation by Transformation Vector Learning ↩
-
Learning a similarity metric discriminatively, with application to face verification ↩
-
StarGAN-VC: Non-parallel many-to-many voice conversion with star generative adversarial networks ↩
-
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation ↩
-
StarGAN-VC2: Rethinking Conditional Methods for StarGAN-Based Voice Conversion ↩
-
Many-to-Many Voice Conversion using Conditional Cycle-Consistent Adversarial Networks ↩
-
GAZEV: GAN-Based Zero-Shot Voice Conversion over Non-parallel Speech Corpus ↩ ↩2