Keiです。前回投稿したPythonで人工社会シミュレーションの記事で予想外に沢山のいいねを頂けてニヤニヤしています。
前回の投稿ではひとまず人工社会でエージェントたちに好き勝手ゲームをさせるとこまでは行きましたが、おまけに載せているような綺麗なヒートマップの作り方は説明していませんでした。
そこで今回はPandasとMatplotとSeabornを使ってシミュレーション結果の可視化手法を説明していきたいと思いますが、ただグラフを書くだけなら他の記事でも散々紹介されているので、せっかくなので今回は「とにかく大量のcsvを読み込んでヒートマップやら散布図を書かなきゃいけない!こんなんExcelでやってたら日が暮れちまう!」という方向けに、大量のデータを一発でグラフにしてしまうTipsを紹介していきます。
やりたいことその1.大量のヒートマップを一度に描いて見比べる
例えば
output1.csv
output2.csv
output3.csv
.
.
.
output100.csv
のようにファイル毎に数字の連番が降ってあるcsvファイルを一気に全部ヒートマップにしたい!みたいな時ってたまーにないですか?
特に自分のように確率的シミュレーションとかやってると、計算結果が毎回実行するごとに微妙に変わる(使用する乱数系列の関係)ので、100回くらい違う乱数系列を使って計算してそれぞれのエピソードで計算結果がどのくらい違ってくるのかをチェックしたい場面が頻繁にあり、そんな時に以下のスクリプト達が役に立ってくれています。
なおcsvファイルの名前は上で書いたように"output(数字).csv" のようになっている場合を想定しています。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
num_figure = 10 # 描画したいcsvファイルの数
fig = plt.figure()
for i in range(1, num_figure+1):
df = pd.read_csv('output{}.csv'.format(i)) # csvファイル読み込み
df_pivot = df.pivot('column1','column2', 'value') # col1, col2, valueの部分は読み込みたいデータに応じて変えてください
ax = fig.add_subplot(2, 5, i) # これだと10枚のヒートマップを2行5列の配置で順に描画してくれます。
sns.heatmap(df_pivot, cbar=False) # cbar=Trueにすると同じカラーバーが10個出てくるので鬱陶しければこの例のようにFalseにしておく。
ax.set_title("Episode{}".format(i)) # それぞれのヒートマップにタイトルをつける
plt.tight_layout() # こいつを書くだけでグラフ同士の間隔を程よく調整してくれる
fig.suptitle('Fraction of Cooperation') # グラフ全体のタイトル
plt.savefig('heatmaps.png')
plt.show()
上ではfor文とformat文を使ってファイルごとに数字が異なっている部分を変えながらデータを読み込んでいってます。ちなみにこんな感じで10枚のヒートマップを並べて見比べることが出来ます↓
 これは僕が以前研究中に人工社会シミュレーションの計算結果を10個のエピソードについて見比べた際のものですが、Episode7だけ他のエピソードより色の明るい範囲が広くなっています(=より強い社会ジレンマの下でも利他的な人間が生き残れている)。これは計算時に使用した乱数系列の違いで、たまたま利他的なエージェントにとって有利な初期条件で計算が始まったのがEpisode7だったということになります。
これは僕が以前研究中に人工社会シミュレーションの計算結果を10個のエピソードについて見比べた際のものですが、Episode7だけ他のエピソードより色の明るい範囲が広くなっています(=より強い社会ジレンマの下でも利他的な人間が生き残れている)。これは計算時に使用した乱数系列の違いで、たまたま利他的なエージェントにとって有利な初期条件で計算が始まったのがEpisode7だったということになります。
やりたいことその2.大量の時系列データを一つのグラフにまとめて描画
上と似たような感じで大量の時系列データも1つのグラフに押し込んで比較出来ます。
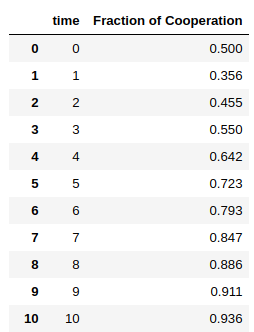
例えば上のような形で時系列データが格納されている沢山のcsvファイルに、
time_series(parameter=0.0).csv
time_series(parameter=0.1).csv
.
.
time_series(parameter=1.0).csv
のようにしてパラメータ設定がファイル名に振られている状況を考えると、以下のような感じで一気に描画できます↓
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(12, 8))
for param in [format(i, '.1f') for i in np.arange(0.0, 1.1, 0.1)]: # ここのformat文重要
df = pd.read_csv('time_series(parameter={}).csv'.format(param))
ax = fig.add_subplot(111)
ax.scatter(df['time'], df['Fraction of Cooperation'], label='Parameter ={}'.format(param))
ax.set_xlabel('Time step')
ax.set_ylabel('Fraction of Cooperation')
ax.set_xlim([0, 300])
plt.legend()
plt.tight_layout()
plt.savefig('time_series_data.png')
plt.show()
 この例みたく10個の時系列データくらいならExcelでももちろん出来ますけど、これが100個とかなってくると流石にダルいじゃないですか。そういう時この手のスクリプト作っとけば`python script.py`って打てば終わりなんでありがたいですよね。
この例みたく10個の時系列データくらいならExcelでももちろん出来ますけど、これが100個とかなってくると流石にダルいじゃないですか。そういう時この手のスクリプト作っとけば`python script.py`って打てば終わりなんでありがたいですよね。