
はじめに
Pandocで図表番号を参照するときにpandoc-crossrefを使う方は多いと思います.ところが先日,MarkdownファイルをPDFファイルに変換したときに不都合が生じました.1ページを超える長さのソースコードを記載したときに,ソースコードがページを突き抜けて読めなくなってしまうのです(図1).
この記事では
- pandoc-crossrefでソースコードが突き抜ける原因の調査
- ソースコードが突き抜けないようにするフィルタ1の開発
の方法を紹介します.

図1 突き抜けているソースコード
原因を調査する
MarkdownファイルはどのようにPDFファイルになっているのか
Pandocはファイルを様々なフォーマットから様々なフォーマットに変換します2.より詳しく説明すると,まずPandocが入力ファイルをAST(Abstract Syntax Tree; 抽象構文木)に変換し,ASTを好みの内容に変換するフィルタを通り,最後にASTを出力ファイルに変換します(図2).ただしPDFに関しては一旦LaTeXファイルを出力してからlualatexでコンパイルします.
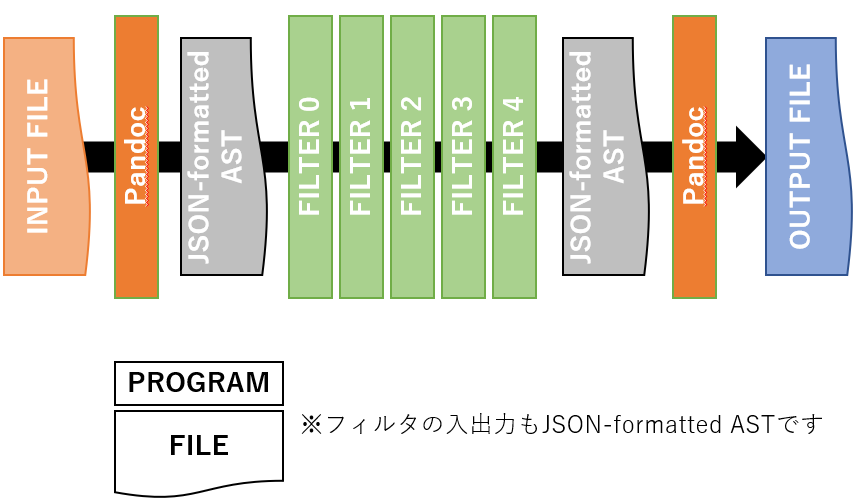
図2 Pandocの詳細
今回の問題は,pandoc-crossrefを使用した場合にソースコードがページを突き抜けてしまうことでした.つまりpandoc-crossrefが出力したASTに原因があると予想されます.そこでまずはPandocが出力するLaTeXファイルから原因を探し出し,次にASTの対応する部分を見つけましょう(図3).
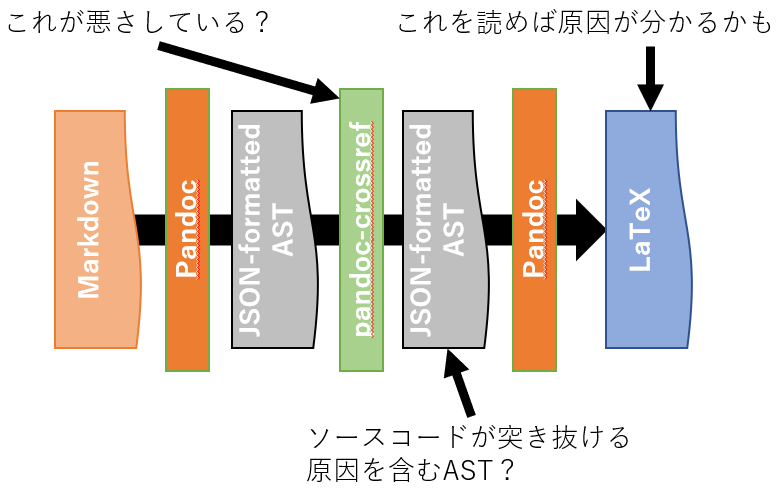
図3 原因の探し方
LaTeXファイルから原因を探す
ソースコードを載せたMarkdownファイルをLaTeXに変換します.ただしpandoc-crossrefを使う場合と使わない場合でそれぞれLaTeXファイルを出力します.二つのファイルの差分を取ることで,pandoc-crossrefによって追加,削除及び変換されたLaTeXコマンドを見つけます.
diffコマンドで見つけた差分は以下の通りです.両者を比較したところ,ソースコードを記載している部分がcodelistingブロックで囲まれています.この\begin{codelisting}と\end{codelisting}(とcaption)を消せば複数ページにまたがってソースコードを表示できるようです.
$ diff without-filter.tex with-filter.tex
4c4,8
< {[}@lst:source\_code{]} shows source code.
---
> コード.~\ref{lst:source_code} shows source code.
>
> \begin{codelisting}
>
> \caption{sample}
74a79,80
>
> \end{codelisting}
ASTから原因を探す
LaTeXファイルのcodelistingブロックに該当する部分をASTから探します.図4はASTのファイルです.インデントも改行もなく,おぞましい内容ですね.
図4 JSON-formatted ASTの内容
このファイルはJSON形式なので,論理的にはツリー状に構造化されています.そこでJSON形式に従ってもう少し見やすくしましょう.以下のコマンドでASTのファイルを見やすくします.filenameの部分は見たいJSONファイルに置き換えてください.ファイルの内容が構造化されて見やすくなります(図5).
$ python3 -c "import json, pprint; pprint.pprint(json.loads(open(\"filename\").read()))"
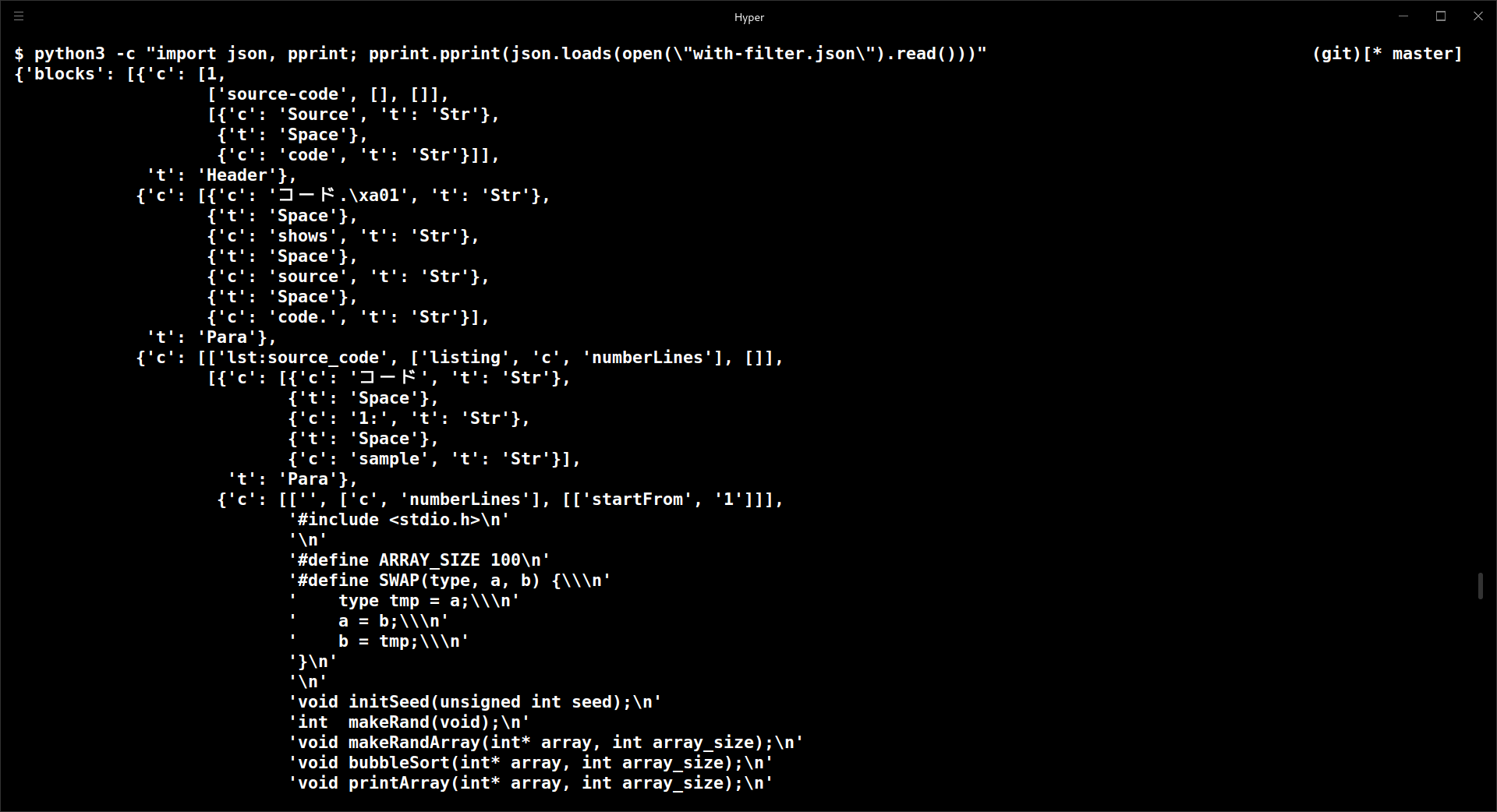
図5 見やすくなったAST
見やすくしたJSONファイルの差分を下に示します.ソースコードを含む箇所のみを抜粋しています.フィルタを使わない場合はキーcに対応する内容がソースコードとそれに関連する情報のようです.キーtに対応する内容はCodeBlockなので,まさにこのハッシュテーブルはコードブロックのためのものでしょう3.
とどのつまり,フィルタを使った場合の出力結果(下部分)をフィルタを使わない場合の出力結果(上部分)に変換する新しいフィルタを作ることで,ソースコードが突き抜けてしまう問題を解決できるでしょう.
$ diff without-filter-formatted.json with-filter-formatted.json
22,93c15,92
< {'c': [['lst:source_code',
< ['c', 'numberLines'],
< [['startFrom', '1'], ['caption', 'sample']]],
< '#include <stdio.h>\n'
< (ソースコードの内容なので省略)
< '}'],
< 't': 'CodeBlock'}],
---
> {'c': [['lst:source_code', ['listing', 'c', 'numberLines'], []],
> [{'c': [{'c': 'コード', 't': 'Str'},
> {'t': 'Space'},
> {'c': '1:', 't': 'Str'},
> {'t': 'Space'},
> {'c': 'sample', 't': 'Str'}],
> 't': 'Para'},
> {'c': [['', ['c', 'numberLines'], [['startFrom', '1']]],
> '#include <stdio.h>\n'
> (ソースコードの内容なので省略)
> '}'],
> 't': 'CodeBlock'}]],
> 't': 'Div'}],
フィルタで問題のトークンを処理する
フィルタの作り方
今回は使い慣れたPythonでフィルタを開発することとします.フィルタを作る方法はQiitaにいくつもの記事があります45.Pythonでフィルタを作る場合はpandocfiltersモジュール6を使うと楽なようです.このモジュールでページを突き抜けないPDFファイルを作ります.
前節で述べた通り,原因のASTトークンはtがDivで,かつtがCodeBlockのトークンを内包したものでした.このトークンをtがCodeBlockのトークンの内容に置き換えるフィルタを作ってみます.
作ったフィルタのコードを下に示します.たった22行で作れたのは驚きです.実行権限を付けて,早速使ってみましょう
# !/usr/bin/env python3
# -*- coding: utf-8 -*-
from pandocfilters import toJSONFilter, CodeBlock
def myfilter(key, value, format_, meta):
if key != 'Div':
return
for content in value:
if type(content[0]) != dict:
continue
for sub_content in content:
if sub_content['t'] == 'CodeBlock':
return CodeBlock(*sub_content['c'])
def main():
toJSONFilter(myfilter)
if __name__ == "__main__":
main()
フィルタを使う
作ったフィルタを使ってMarkdownファイルをPDFファイルに変換します.もちろん作ったフィルタはpandoc-crossrefの後に適用します.コマンドラインでのフィルタの適用方法を下に示します.
$ pandoc --version
pandoc 2.9.2.1
Compiled with pandoc-types 1.20, texmath 0.12.0.2, skylighting 0.8.3.4
Default user data directory: /home/kenta/.local/share/pandoc or /home/kenta/.pandoc
Copyright (C) 2006-2020 John MacFarlane
Web: https://pandoc.org
This is free software; see the source for copying conditions.
There is no warranty, not even for merchantability or fitness
for a particular purpose.
$ pandoc-crossref --version
pandoc-crossref v0.3.6.2 git commit UNKNOWN (UNKNOWN) built with Pandoc v2.9.2.1, pandoc-types v1.20 and GHC 8.8.3
$ pandoc sample.md -o sample.pdf\
--pdf-engine=lualatex\
--filter=pandoc-crossref --filter=./pandoc_remove_codelisting_filter.py
出力されたPDFファイルを図6に示します.ページをまたがってソースコードを表示できるようになりました.これで長いソースコードも安心して載せられそうです.

図6 出力したPDFファイル
まとめ
pandoc-crossrefを使った場合に,PDFファイルに記載したソースコードがページを突き抜けてしまいました.そこで本稿ではまずPandocが処理するASTから原因を調査し,それから原因を含むASTトークンを変換するフィルタを開発しました.開発したフィルタpandoc_remove_codelisting_filterを使うことで,ソースコードを複数ページにまたがって載せられるようになりました.同様の問題でお困りの方は是非お使い下さい.
また開発したフィルタはGitHubに置いておきました.pipでインストールするとフィルタをコマンドとして使えるようにしていますので,ご活用下さい.
リンク
pandoc_remove_codelisting_filter: https://github.com/Kenta11/pandoc_remove_codelisting_filter
-
pip install https://github.com/Kenta11/pandoc_remove_codelisting_filterでインストールできます!
CHANGELOG
- 5/13: Before & Afterを追加,注釈3を修正.
-
フィルタはPandocでドキュメントを変換するためのプログラムです.『原因を調査する』で詳しく述べています. ↩
-
すごい数ありますhttps://pandoc.org/ ↩
-
『ものでしょう』と述べているのは,つまり本当の仕様を知らないためです.~~このASTのドキュメントは無いようです.AST Documentation? #3262~~Haskellのデータ構造で表現した仕様がありました.Text.Pandoc.Definition ↩ ↩2
-
@takada_at, "PythonでPandocのフィルターを書く," https://qiita.com/takada-at/items/187923e57071c0aa73a7. ↩
-
@irisTa56, "Pandoc の filter として panflute を使ってみる," https://qiita.com/irisTa56/items/34c78c92b0b0e0be90a6. ↩
-
jgm, "pandocfilters," https://pypi.org/project/pandocfilters/ ↩