この記事では、Javaのログをクラウドに移行するための強力なツールを3つ紹介します。Log4J、LogBack、Producer Libです。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
ログの一元化への道
近年、ステートレスプログラミング、コンテナ、サーバレスプログラミングの登場により、ソフトウェアのデリバリやデプロイの効率が大きく向上しました。アーキテクチャの進化では、以下の2つの変化を見ることができます。
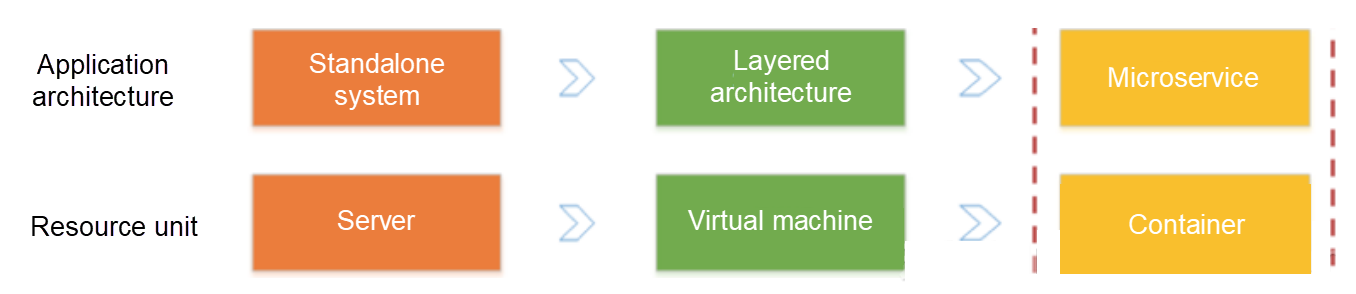
- アプリケーションアーキテクチャは、単一システムからマイクロサービスに変化しています。次に、ビジネスロジックがマイクロサービス間で呼び出しとリクエストに変化します。
- リソースの面では、従来の物理サーバがフェードアウトし、目に見えない仮想リソースへと変化しています。
前述の2つの変化は、弾性的で標準化されたアーキテクチャの裏で、運用保守(O&M)や診断の要件が複雑化していることを示しています。10年前は、サーバにログオンしてログを素早くフェッチすることができました。しかし、もはやアタッチ処理モードは存在しません。現在は、標準化されたブラックボックスに直面しています。
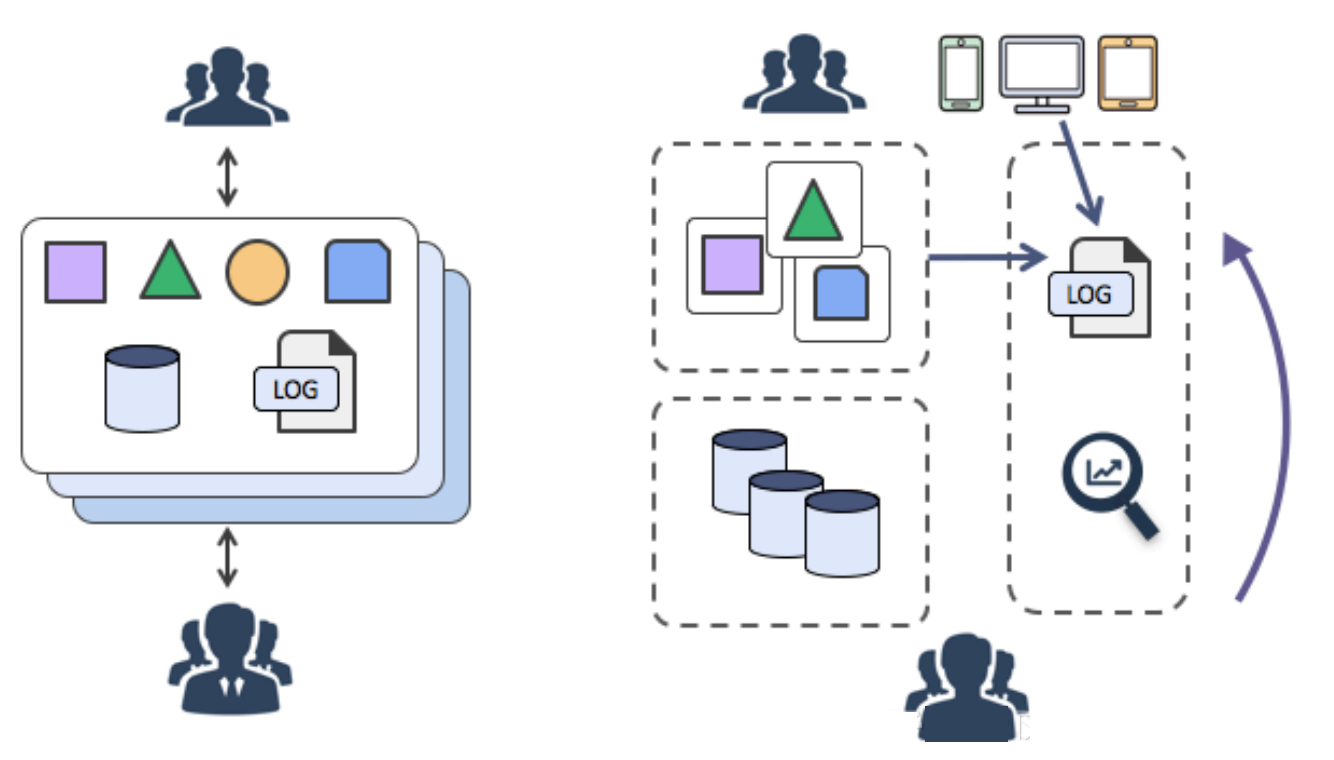
こうした変化に対応するために、DevOpsに特化した診断・分析ツールが続々と登場しています。これらには、集中監視、集中ログシステム、各種SaaSの導入、監視などが含まれます。
ログを一元化することで、先行する課題を解決することができます。これを行うには、アプリケーションがログを生成した後、ログはリアルタイム(または準リアルタイム)で中央のノードサーバに送信されます。多くの場合、Syslog、Kafka、ELK、HBaseが集中型ストレージを実行するために使用されます。
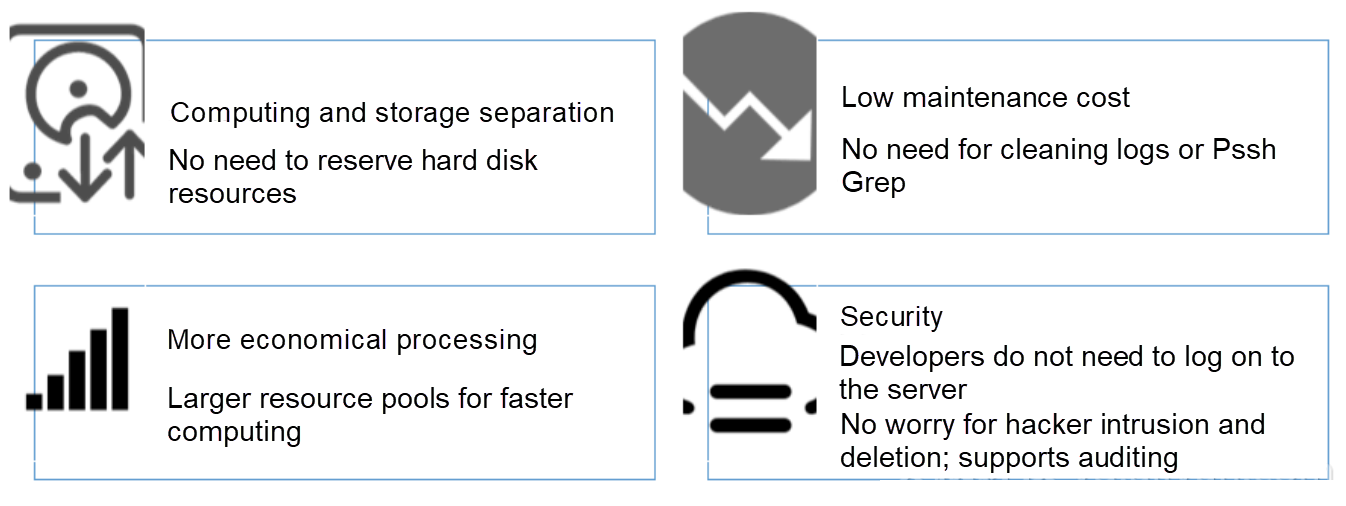
集中化の利点
- 使い勝手の良さ:Grepを使ってステートレスアプリケーションのログを照会するのは面倒です。集中型ストレージでは、前の長い処理が検索コマンドを実行することで置き換えられます。
- ストレージとコンピューティングの分離:マシンのハードウェアをカスタマイズする際に、ログのためのストレージスペースを考慮する必要がありません。
- コスト削減:集中型ログストレージでは、より多くのリソースを確保するためにロードシフトを行うことができます。
- セキュリティ:ハッカーの侵入や災害が発生した場合でも、重要なデータは証拠として保持されます。
コレクター (Javaシリーズ)
ログサービスは、サーバ、モバイル端末、組み込み機器、各種開発言語に対応した30以上のデータ収集方法と包括的なアクセスソリューションを提供しています。Java開発者にはおなじみのログフレームワークが必要です。Log4j、Log4j2、Logback Appenderです。
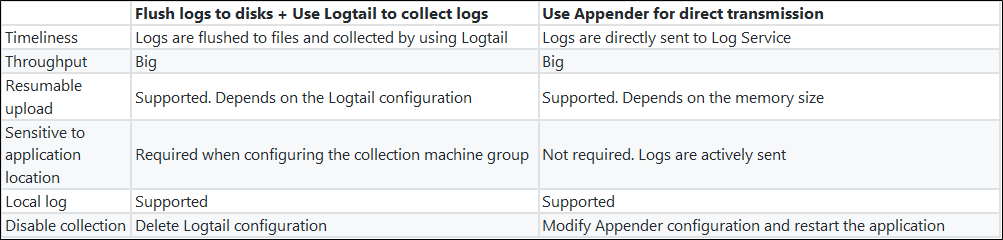
Javaアプリケーションには現在、2つの主流のログ収集ソリューションがあります。
- Javaプログラムはログをディスクにフラッシュし、Logtailをリアルタイム収集に使用します。
- Javaプログラムは、Log Serviceが提供するAppenderを直接設定します。プログラムが実行されると、ログはリアルタイムでLog Serviceに送信されます。
両者の違い:
Appenderを使用することで、Configを使用して、コードを変更することなく簡単にリアルタイムログ収集を完了させることができます。Log Serviceが提供するJavaシリーズのAppenderには、以下のようなメリットがあります。
- プログラムを変更せずにConfigの変更が有効になります。
- 非同期+ブレークポイント転送:I/Oはメインスレッドに影響を与えず、特定のネットワークやサービスの障害を許容することができます。
- 高カレンシー設計:大規模なログの書き込み要件を満たしています。
- コンテキストクエリをサポート:ログサービスの元のプロセスで、ログのコンテキスト(ログの前後にあるN個のログ)を正確に復元することをサポートします。
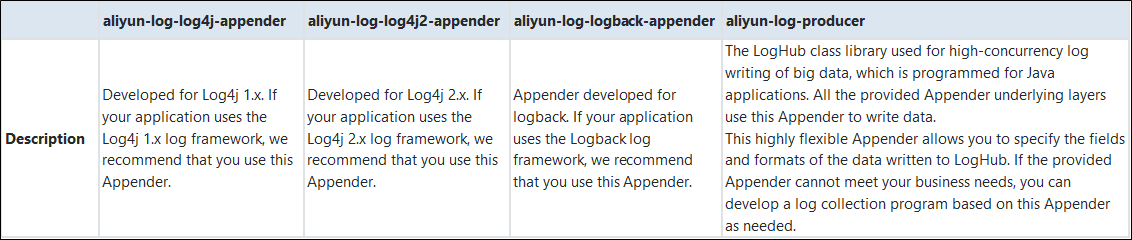
アペンダーの概要と使い方:
提供されているアペンダーは以下の通りです。基礎となるレイヤーはすべて、データを書き込むためにaliyun-log-producer-javaを使用します。
aliyun-log-log4j-appender
aliyun-log-log4j2-appender
aliyun-log-logback-appender
4つの違い:
アペンダーの統合
aliyun-log-log4j-appenderの設定手順を実行することで、Appenderを統合することができます。
設定ファイルlog4j.propertiesの内容は以下の通りです。
log4j.rootLogger=WARN,loghub
log4j.appender.loghub=com.aliyun.openservices.log.log4j.LoghubAppender
# Log Service project name (required parameter)
log4j.appender.loghub.projectName=[your project]
# Log Service LogStore name (required parameter)
log4j.appender.loghub.logstore=[your logstore]
# Log Service HTTP address (required parameter)
log4j.appender.loghub.endpoint=[your project endpoint]
# User identity (required parameter)
log4j.appender.loghub.accessKeyId=[your accesskey id]
log4j.appender.loghub.accessKey=[your accesskey]
クエリと分析
前のステップで説明したようにアペンダーを設定すると、Java アプリケーションが生成したログが自動的に Log Service に送信されます。LogSearch/Analyticsを使用して、これらのログをリアルタイムで照会・分析することができます。次のようなサンプルのログ形式を参照してください。この例で使用したログ形式:
ログオンの動作を記録するログ:
level: INFO
location: com.aliyun.log4jappendertest.Log4jAppenderBizDemo.login(Log4jAppenderBizDemo.java:38)
message: User login successfully. requestID=id4 userID=user8
thread: main
time: 2018-01-26T15:31+0000
購入行動を記録するログ:
level: INFO
location: com.aliyun.log4jappendertest.Log4jAppenderBizDemo.order(Log4jAppenderBizDemo.java:46)
message: Place an order successfully. requestID=id44 userID=user8 itemID=item3 amount=9
thread: main
time: 2018-01-26T15:31+0000
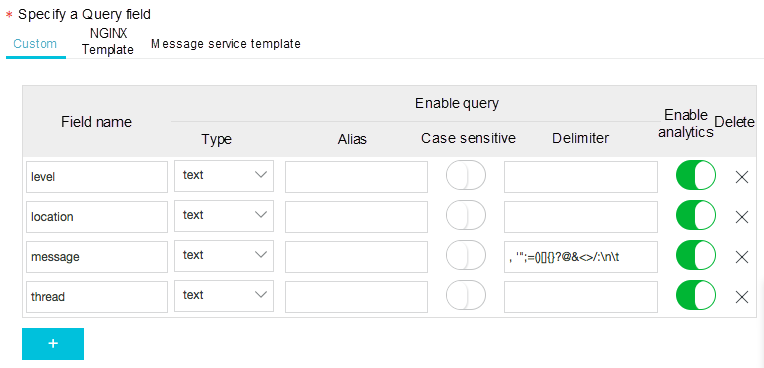
クエリ解析を有効にする
データを照会して分析する前に、照会および分析機能を有効にする必要があります。以下の手順に従って、機能を有効にしてください。
- ログサービスコンソールにログオンします。
- プロジェクト一覧ページで、プロジェクト名をクリックするか、右側の管理をクリックします。
- ログストアを選択し、ログ検索列で検索をクリックします。
- Set LogSearch and Analytics > Settings を選択します。
- 設定メニューに移動し、以下のフィールドのクエリを有効にします。
ログの分析
5つの分析例を見てみましょう。
1、過去1時間にエラーが最も多く発生した場所の上位3つを数えてください。
構文例:
level: ERROR | select location ,count(*) as count GROUP BY location ORDER BY count DESC LIMIT 3
- 過去 15 分間にログレベルごとに生成されたログの数をカウントします。
構文例:
| select level ,count(*) as count GROUP BY level ORDER BY count DESC
- ログ コンテキストを照会します。
任意のログについて、元のログ ファイルのログ コンテキスト情報を正確に再構築できます。
詳細については、コンテキスト クエリを参照してください。
- 過去 1 時間に最も頻繁にログオンしたユーザーの上位 3 人をカウントします。
構文例:
login | SELECT regexp_extract(message, 'userID=(? <userID>[a-zA-Z\d]+)', 1) AS userID, count(*) as count GROUP BY userID ORDER BY count DESC LIMIT 3
- 各ユーザーの過去 15 分間の支払い合計統計をコンパイルします。
構文例:
order | SELECT regexp_extract(message, 'userID=(? <userID>[a-zA-Z\d]+)', 1) AS userID, sum(cast(regexp_extract(message, 'amount=(? <amount>[a-zA-Z\d]+)', 1) AS double)) AS amount GROUP BY userID
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ