技術者であるDeng Qingling氏は、ビジネス開発の観点から、サーバーレスのKubernetesとその運用についての考えを述べています。
著者:アリババのテクニカルエキスパート、Deng Qinglin (Qingling)氏

この記事は、アリババの技術専門家であるDeng Qinglin(青林)氏が作成した内部文書から転載したものです。彼は、Alibaba Cloud Consoleチームから、Serverless Kubernetesの基盤となるECI R&Dチームに異動し、その後、Kubernetesの勉強を始め、ビジネス開発の観点からKubernetesの登場と運用についての考えを語ってくれました。
はじめに
2019年の後半、私は新しい職場に異動し、Kubernetesの勉強を始めました。まだまだKubernetesへの理解は不完全ですが、学んだことの一部を紹介したいと思います。この記事が、皆さんがKubernetesを使い始める際に役立つことを願っています。もし、この記事に誤りがあれば、訂正しますので、ご連絡ください。
Kubernetesを紹介する記事はたくさんありますし、Kubernetesの公式ドキュメントも非常にわかりやすいです。ここでは、ビジネス開発の観点から、Kubernetesの登場とその運用についてお話したいと思います。
序章

中国では生活水準の向上に伴い、ほぼすべての家庭に自動車が普及しています。王さんは、今後5年間で車の廃棄ビジネスが急速に発展すると予測していました。2019年、政府は新政策「使用済み自動車リサイクル管理弁法」を発表し、自動車の廃車・リサイクルの「特殊産業」の地位を撤廃し、業界を市場ベースの競争に開放することになりました。
王さんは、これはビジネスを始めるのに良い機会だと感じ、興味を持った数人のパートナーを見つけ、Taoche.comというプラットフォームを作りました。
Taoche.comは当初、オールインワンのJavaアプリケーションを物理的なサーバーに展開していました。 ビジネスの成長に伴い、サーバーが対応しきれなくなったため、64c256gのサーバーから160c1920gのモデルにアップグレードしました。コストは少しかかりましたが、アップグレードしたサーバーで必要なシステムリソースを確保できました。
しかし、1年も経つと160c1920gでは足りなくなってきました。同社では、サービスを分割して分散展開する必要があり、分散展開の過程で発生した問題を解決するために、同社はHSF、TDDL、Tair、Diamond、MetaQなどの一連のミドルウェア製品を導入しました。この困難なビジネスアーキテクチャの変革の後、彼らはオールインワンのJavaアプリケーションを複数の小さなアプリケーションに分割することに成功し、我々はIBM、Oracle、EMCのインフラから脱却しました。
分散型アーキテクチャへの移行後、王氏のチームはより多くのサーバーを管理しなければならず、サーバーのバッチ、ハードウェアの仕様、OSのバージョンなどが混乱していました。これにより、アプリケーションのランタイムやO&Mにおいて様々な問題が発生しました。
仮想マシン技術を使うことで、基盤となるさまざまなハードウェアやソフトウェアの違いを保護することができます。ハードウェアの違いはあっても、アプリケーションから見ると同じように見えるのです。当時、仮想化はパフォーマンスを大幅に低下させていました。
一方、Dockerはどうでしょうか。Dockerは、cgroupなどのLinuxのネイティブな技術をベースにしているため、パフォーマンスへの影響が少なく、根本的な違いを保護することができます。これは本当に良い選択でした。また、Dockerイメージをベースにしたサービス提供は、継続的インテグレーションや継続的デリバリ(CI/CD)を非常に容易にします。

Dockerコンテナの数が増えるにつれ、企業はDockerコンテナ間のスケジューリングとコミュニケーションという新たな課題に直面することになりました。Taoche.comはもはや小さな会社ではありませんでした。何千ものDockerコンテナを動かしていたのです。現在のビジネスを続けていけば、すぐに1万個以上のコンテナを持つことになるでしょう。
彼らは、サーバーの管理(サーバーの健康状態、空きメモリ、CPUリソースのチェックなど)を自動的に行い、CPUやメモリの必要量に応じてコンテナ化に最適なサーバーを選択できるシステムを必要としていました。また、コンテナ間の通信を制御するシステムも必要です。例えば、ある部署のコンテナが、別の部署の社内サービスコンテナにアクセスできてしまうようなことがあってはなりません。このようなシステムを「コンテナオーケストレーションシステム」と呼びます。
コンテナオーケストレーションシステム

まずTaocheは、"多数のサーバーを扱う場合、コンテナオーケストレーションシステムをどのように実装するか?"という質問に答えなければなりませんでした。
すでにオーケストレーションシステムを導入していると仮定して、サーバーの一部をオーケストレーションシステムの実行に使用し、残りのサーバーでビジネスコンテナを実行することになります。オーケストレーションシステムを稼働させるサーバーをマスターノード、ビジネスコンテナを稼働させるサーバーをワーカーノードと呼びます。
マスターノードはクラスターの管理を担当し、必要な管理インターフェースを提供する必要があります。このうち、管理者がクラスターのO&Mを行うためのインターフェースと、ワーカーノードとの間でリソースの割り当てやネットワークの管理などを行うためのインターフェースがあります。
マスターノード上で管理インターフェースを提供するコンポーネントを、我々は「kube-apiserver」と呼んでいます。一方、APIサーバとのやりとりには2つのクライアントが必要です。
- クラスタのO&M管理者には「kubextl」が提供されます。
- kubeletはワーカーノードに提供されます。
これで、クラスターのO&M管理者、マスターノード、ワーカーノードが相互にやりとりできるようになりました。O&M管理者は、kubectlを使って「Create 1,000 containers from the Taoche User Center v2.0 image」というコマンドを発行することができます。このリクエストを受け取ったマスターノードは、クラスタ内のワーカーノードのリソース情報に基づいて計算スケジューリングを行います。そして、マスターノードは、作成が必要な1,000個のコンテナに対応するワーカーノードを算出し、該当するワーカーに関連する作成要求を送信します。スケジューリングを担当するコンポーネントは「kube-scheduler」と呼ばれています。
マスターは、各ワーカー上のコンテナのリソース消費量や稼働状況をどのようにして知るのでしょうか。簡単に言うと、ワーカー上のkubeletクライアントを使って、ノードのリソースやコンテナの稼働状況を定期的に能動的に報告します。そして、マスターはこのデータを保存し、その後のスケジューリングやコンテナ管理に利用することができます。このデータを保存するには、ファイルやデータベースに書き込むことができます。また、データの一貫性や高可用性の要件を満たすことができる「etcd」というオープンソースのストレージシステムがあります。インストールも簡単で、性能も良好です。
すべてのワーカーノードとコンテナの運用データが手に入れば、それを使っていろいろなことができるようになります。前述の例では、Taoche User Center v2.0のイメージから1,000個のコンテナが作成されました。このうち5つのコンテナがワーカーノードAで稼働しているとします。ノードAが突然ハードウェア障害に遭遇して利用できなくなった場合、マスターノードは利用可能なワーカーノードのリストからノードAを削除します。次に、元々このノードで稼働していた5つのUser Center v2.0コンテナを、利用可能な他のワーカーノードに再割り当てする必要があります。これにより、システムはUser Center v2.0コンテナの数を1,000に戻すことができます。その後、コンテナが正しく通信できるように、コンテナのネットワーク通信構成を調整する必要があります。ここで、この作業に関わる一連のコンポーネントを「コントローラ」と呼びます。このコントローラには、ノードコントローラ、レプリケーションコントローラ、エンドポイントコントローラなどがあります。また、これらのコントローラを集中的に管理するランタイムコンポーネントとして「kube-controller-manager」が用意されています。
では、マスターがコンテナ間のネットワーク通信をどのように実装・管理しているかを見てみましょう。まず、各コンテナは、他のコンテナとの通信に使用される固有のIPアドレスを持つ必要があります。相互に通信する必要のあるコンテナは、異なるワーカーノード上で動作する場合があります。そのような通信には、ワーカーノード間のネットワーク通信が必要になります。そのため、各ワーカーノードは固有のIPアドレスを持つ必要があります。コンテナは、コンテナのIPアドレスを介して相互に通信し、ワーカーノードのIPアドレスを認識しないため、ワーカーノードはコンテナのIPアドレスに対するルーティング情報を提供する必要があります。そのためには、iptablesやIPVSなどの技術を利用します。コンテナIPアドレスやコンテナ数が変更された場合は、それに応じてiptablesやIPVXの設定を更新する必要があります。ワーカーノード上には、ルートフォワーディングの設定を聞き取り、調整する役割を担う特別なコンポーネントが必要です。このコンポーネントは「kube-proxy」と呼ばれます。
ここまでで、コンテナ間のネットワーク通信を解決しました。しかし、コーディングの際には、動的に変化する可能性のあるコンテナのIPアドレスではなく、ドメイン名やVIPでサービスを呼び出す必要があります。そのためには、コンテナのIPアドレスに加えて、サービスをカプセル化する必要があります。このサービスは、クラスタのVIPまたはドメイン名である可能性があり、そのためには、内部のDNS解決サービスが必要です。
すでにkubectlがあり、マスターと簡単にやりとりできますが、ウェブ管理インターフェースを追加することで、より簡単になります。また、クラスタ全体に関連するコンポーネントのコンテナリソースや運用ログを見たい場合もあります。
DNS、Web管理インターフェース、コンテナリソース情報、クラスタログなど、ユーザーエクスペリエンスを向上させることができるコンポーネントを総称して「プラグイン」と呼びます。
さて、ここまででコンテナオーケストレーションシステムの構築に成功しました。次に、本稿で紹介したコンポーネントを簡単にまとめておきます。
- マスターコンポーネント:kube-apiserver、kube-scheduler、etcd、kube-controller-manager
- ノードコンポーネント:kubelet、kube-proxy
- プラグイン: DNS、Web UI、コンテナリソースモニタリング、クラスタログ
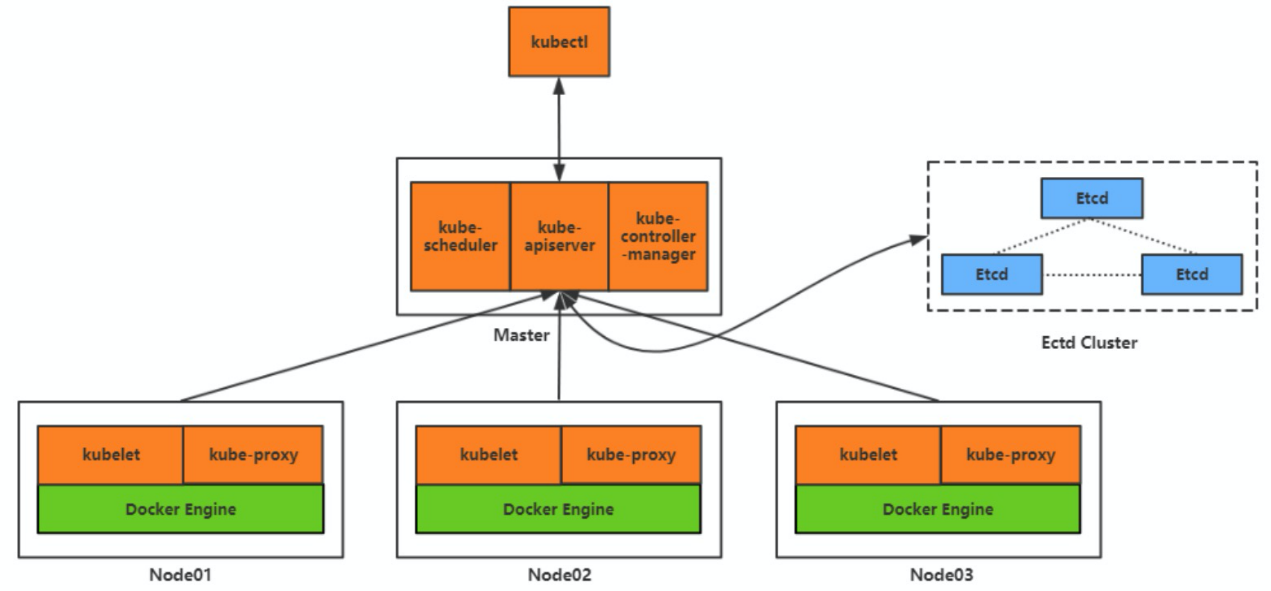
これらは、Kubernetesにおける主要なコンポーネントです。
サーバーレスのコンテナオーケストレーションシステム
Taoche社はコンテナオーケストレーションシステムの導入に成功し、満足していましたが、Taoche社の王社長(もはや単に王氏ではない)は、オーケストレーションシステムのR&DおよびO&Mコストが高すぎると考え、これらのコストを削減する方法を、そして社員がクラスターのO&M管理ではなく、事業開発に専念できるオーケストレーションシステムを探していました。王社長と同社の技術チームは、サーバーレスのコンセプトを知り、すぐに興味を持ち、サーバーレスのコンテナオーケストレーションシステムを構築できないかと考えました。
運良く、彼らはServerless Kubernetesという製品を発見しましたが、それはまた別の日の話です。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ