このチュートリアルでは、TF-IDFを用いて**NER(Named Entity Recognition)を構築することで、Pythonでの自然言語処理(NLP)**の基礎を学びます。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
前提条件
このチュートリアルはPythonバージョン3.6.5とNLTKバージョン3.3に基づいています。これらはAnacondaバージョン1.8.7に予めインストールされていますが、それが前提条件ではありません。
NLTKパッケージはパッケージマネージャを使って[インストール](https://www.nltk.org/install.html?
spm=a2c65.11461447.0.0.471a101afZjz48)することができます。---pip.
pip install nltk==3.3
インストールが完了したら、そのバージョンを確認することができます。
>>> import nltk
>>> nltk.__version__
'3.3'
このチュートリアルでは、NLTKパッケージに含まれるサンプルツイートを使用しています。ただし、これらのサンプルツイートをダウンロードする必要があります。
>>> import nltk
>>> nltk.download('twitter_samples')
[nltk_data] Downloading package twitter_samples to C:\Users\Shaumik
[nltk_data] Daityari\AppData\Roaming\nltk_data...
[nltk_data] Unzipping corpora/twitter_samples.zip.
True
データのダウンロード先は環境によって異なります。ここでの出力は、Windowsで実行した結果です。サンプルがダウンロードされたら、以下のようにしてインポートします。
>>> from nltk.corpus import twitter_samples
>>> twitter_samples.fileids()
['negative_tweets.json', 'positive_tweets.json', 'tweets.20150430-223406.json']
NLTKのtwitter_samplesでは、ネガティブとポジティブの2つの感情を持つ5000ツイートのセットと、20000ツイートのセットの3つのツイートが用意されています。このネガティブとポジティブのツイートを使って、後ほどセンチメント分析のモデルを学習します。任意のセット内のすべてのツイートを取得するには、以下のコードを使用することができます。
>>> text = twitter_samples.strings(
'tweets.20150430-223406.json')
>>> len(text)
20000
>>> text[:3]
['RT @KirkKus: Indirect cost of the UK being in the EU is estimated to be costing Britain £170 billion per year! #BetterOffOut #UKIP',
'VIDEO: Sturgeon on post-election deals http://t.co/BTJwrpbmOY',
'RT @LabourEoin: The economy was growing 3 times faster on the day David Cameron became Prime Minister than it is today.. #BBCqt http://t.co…']
興味のある方のために、Twitter APIを使って特定の期間、ユーザー、ハッシュタグのツイートを取得する方法もありますが、このチュートリアルではNLTKのサンプルツイートを中心に説明します。
次のセクションでは、統計ツールを使用する前にデータをクリーニングするプロセスを理解した上で、一般的なNLPのテクニックに移っていきます。
テキストの前処理
単語のトークン化
自然な形では、テキストデータをプログラムで分析することは困難です。そのため、テキストをトークンと呼ばれる小さな部分に変換する必要があります。トークンとは、何らかの論理的な意味を持つ連続した文字の組み合わせです。トークン化の簡単な方法は、すべての空白文字でテキストを分割することです。
NLTKにはTweet用のデフォルトのトークン化機能が用意されており、tokenizedメソッドはトークンのリストを返します。
>>> twitter_samples.tokenized('tweets.20150430-223406.json')[0]
['RT',
'@',
'KirkKus',
':',
'Indirect',
'cost',
'of',
'the',
'UK',
'being',
'in',
'the',
'EU',
'is',
'estimated',
'to',
'be',
'costing',
'Britain',
'£170',
'billion',
'per',
'year',
'!',
'#',
'BetterOffOut',
'#',
'UKIP']
ご覧のように、デフォルトのメソッドはすべての特殊文字を返します。トークン化の処理には時間がかかります。このチュートリアルの目的では、このメソッドは必要ありません。
.tokenized()メソッドはNLTKのTwitterサンプルで使用できますが、その他のテキストのトークン化にはword_tokenizeメソッドを使用することもできます。word_tokenizeを使用するには、まずpunktリソースをダウンロードしてください。
>>> nltk.download('punkt')
[nltk_data] Downloading package punkt to C:\Users\Shaumik
[nltk_data] Daityari\AppData\Roaming\nltk_data...
[nltk_data] Unzipping tokenizers\punkt.zip.
True
>>> from nltk.tokenize import word_tokenize
>>> word_tokenize(text[0])
['RT',
'@',
'KirkKus',
':',
'Indirect',
'cost',
'of',
'the',
'UK',
'being',
'in',
'the',
'EU',
'is',
'estimated',
'to',
'be',
'costing',
'Britain',
'£170',
'billion',
'per',
'year',
'!',
'#',
'BetterOffOut',
'#',
'UKIP']
単語を正規形に変換する
単語には異なる文法的な形があります。
例えば、"swim"、"swam"、"swims"、"swimming "は同じ動詞の様々な形です。分析の必要性によっては、これらすべての形を同じ定型に変換する必要があるかもしれません。このセクションでは、ステミングとレマタイズの 2 つのテクニックを探っていきます。
ステム処理は、単語から接辞を取り除く処理です。これは単純なアルゴリズムで、特定の考慮事項に基づいて単語の末尾から余分な文字を切り取るものです。ステム処理には、さまざまなアルゴリズムがあります。このチュートリアルでは、そのうちの 1 つ、ポーターステミングアルゴリズムに焦点を当ててみましょう (他のアルゴリズムには、ランカスターステミングアルゴリズムやスノーボールステミングアルゴリズムがあります)。
>>> from nltk.stem.porter import PorterStemmer
>>> stem = PorterStemmer()
>>> stem.stem('swimming')
'swim'
ここまでは順調です。もう少しやってみよう。
>>> stem.stem('swam')
'swam'
うまくいきませんでした。なぜでしょうか?
まあ、ステミングというのは、文脈を無視して単語に対して行う処理のことです。サンプルツイートでステム機能を試してみて、その変化を比較してみてください。
レンマ化は、文脈を持つ単語を正規化する処理です。WordNetLemmatizerを使用するには、追加のリソースをダウンロードする必要があります。
>>> nltk.download('wordnet')
[nltk_data] Downloading package wordnet to C:\Users\Shaumik
[nltk_data] Daityari\AppData\Roaming\nltk_data...
[nltk_data] Unzipping tokenizers\wordnet.zip.
True
ダウンロードしたら、Lemmatizerを使う準備ができました。
>>> from nltk.stem.wordnet import WordNetLemmatizer
>>> lem = WordNetLemmatizer()
>>> lem.lemmatize('swam', 'v')
'swim'
ここでの文脈は第2引数によって提供され、関数はranを動詞として扱うように指示しています! しかし、レンマ化は、速度を犠牲にして行われます。ステム処理とレマタイズ処理を比較すると、最終的には、速度と精度のトレードオフになります。
ツイートでレマタイザーを実行しているとき、単語の文脈をどのようにして知ることができますか?NLTKから別のリソースをダウンロードした後、文中の単語の相対的な位置を決定するためにタグ付けを行う必要があります。
>>> nltk.download('averaged_perceptron_tagger')
[nltk_data] Downloading package averaged_perceptron_tagger to C:\Users\Shaumik
[nltk_data] Daityari\AppData\Roaming\nltk_data...
[nltk_data] Unzipping help\averaged_perceptron_tagger.zip.
True
>>> from nltk.tag import pos_tag
>>> sample = "Your time is limited, so don't waste it living someone else's life."
>>> pos_tag(word_tokenize(sample))
[('Your', 'PRP$'),
('time', 'NN'),
('is', 'VBZ'),
('limited', 'VBN'),
(',', ','),
('so', 'IN'),
('don', 'JJ'),
(''', 'NN'),
('t', 'NN'),
('waste', 'NN'),
('it', 'PRP'),
('living', 'VBG'),
('someone', 'NN'),
('else', 'RB'),
(''', 'NNP'),
('s', 'JJ'),
('life', 'NN'),
('.', '.')]
単語ごとに、タガーは文字列を返します。タグの意味を理解するにはどうすればいいのでしょうか?
>>> nltk.download('tagsets')
[nltk_data] Downloading package tagsets to C:\Users\Shaumik
[nltk_data] Daityari\AppData\Roaming\nltk_data...
[nltk_data] Unzipping help\tagsets.zip.
True
>>> nltk.help.upenn_tagset()
単語とそのタグの一覧から、項目とその意味は次のようになります ---
- NNP 固有名詞
- NN 名詞
- VBD 動詞過去形
- VBG 動詞現在分詞
- CD 数字
- IN 前置詞
一般的に、タグがNNで始まる場合は名詞、VBで始まる場合は動詞となります。
def lemmatize_sentence(sentence):
lemmatizer = WordNetLemmatizer()
lemmatized_sentence = []
for word, tag in pos_tag(word_tokenize(sentence)):
if tag.startswith('NN'):
pos = 'n'
elif tag.startswith('VB'):
pos = 'v'
else:
pos = 'a'
lemmatized_sentence.append(lemmatizer.lemmatize(word, pos))
return lemmatized_sentence
これでレマタイザーを使う準備ができました。
>>> lemmatize_sentence(sample)
['Your',
'time',
'be',
'limit',
',',
'so',
'don',
''',
't',
'waste',
'it',
'live',
'someone',
'else',
''',
's',
'life',
'.']
ノイズ除去
文字データの処理の次のステップは「ノイズ」を除去することです。しかし、ノイズとは何でしょうか?
テキストの中で、データの処理とは無関係な部分はすべてノイズです。ノイズはデータに意味や情報を付加するものではありません。ノイズは最終的な目的に特有のものである可能性があることに注意してください。例えば、言語の中で最も一般的な単語は停止語と呼ばれています。停止語の例としては、"is"、"the"、"a "などがあります。これらの単語は、特定のユースケースで必要とされる場合を除き、一般的には言語を処理する際には無関係です。
サンプルツイートの場合は、以下の部分を削除してください。
- 分析に付加価値を与えない全てのハイパーリンク
- リプライのTwitterハンドル
- 句読点と特殊文字
上記の各項目を検索して削除するには、reというパッケージを通してPythonの正規表現ライブラリを使用します。
>>> import re
>>> sample = 'Go to https://alibabacloud.com/campaign/techshare/ for tech tutorials'
>>> re.sub('http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+#]|[!*\(\),]|'\
'(?:%[0-9a-fA-F][0-9a-fA-F]))+','', sample)
'Go to for tech tutorials'
最初にURLにマッチする部分文字列を検索します --- http:// または https:// で始まり、その後に文字、数字、特殊文字が続きます。一致するパターンがあれば、.sub() メソッドはそれを空の文字列に置き換えます。
同様に、@の言及を削除するには、同様のコードでトリックを実行します。
>>> sample = 'Go to @alibaba for techshare tutorials'
>>> re.sub('(@[A-Za-z0-9_]+)','', sample)
'Go to for techshare tutorials'
このコードでは、Twitterのハンドルを検索します。ーーー@の後に任意の数の数字、文字や_が続き、それらを削除します。次のステップでは、stringライブラリを使って句読点を削除することができます。
>>> import string
>>> string.punctuation
'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
句読点を削除するには、以下のスニペットを使用します。
>>> sample = 'Hi!!! How are you?'
>>> sample.translate(str.maketrans('', '', string.punctuation))
'Hi How are you'
このスニペットは、上記の句読点のリストに含まれる文字を検索して削除します。
最後のステップでは、ストップワードも削除する必要があります。nltkに内蔵されているストップワードのリストを使用します。nltkからstopwordsリソースをダウンロードし、.words()メソッドを使ってストップワードのリストを取得する必要があります。
>>> nltk.download('stopwords')
[nltk_data] Downloading package stopwords to C:\Users\Shaumik
[nltk_data] Daityari\AppData\Roaming\nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
True
>>> from nltk.corpus import stopwords
>>> stop_words = stopwords.words('english')
>>> len(stop_words)
179
>>> stop_words[:3]
['i', 'me', 'my']
上記のすべてのスニペットを組み合わせて、テキストからノイズを除去する関数を作ることができます。これは2つの引数をとります --- トークン化されたツイートと、オプションのストップワードのタプルです。
def remove_noise(tokens, stop_words = ()):
'''Remove @ mentions, hyperlinks, punctuation, and stop words'''
clean_tokens = []
lemmatizer = WordNetLemmatizer()
for token, tag in pos_tag(tokens):
# Remove Hyperlinks
token = re.sub('http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+#]|[!*\(\),]|'\
'(?:%[0-9a-fA-F][0-9a-fA-F]))+','', token)
# Remove twitter handles
token = re.sub("(@[A-Za-z0-9_]+)","", token)
if tag.startswith("NN"):
pos = 'n'
elif tag.startswith('VB'):
pos = 'v'
else:
pos = 'a'
# Normalize sentence
token = lemmatizer.lemmatize(token, pos)
if len(token) > 0 and token not in string.punctuation and token.lower() not in stop_words:
# Get lowercase
clean_tokens.append(token)
return clean_tokens
文を分割する前にPythonの.lower()文字列メソッドを使用することもできます。この関数は、チュートリアルの後の NER (Named Entity Recognition) で問題が発生する可能性があるため、このステップをスキップします。さらに、ツイートからRTという単語を削除することもできます。
このチュートリアルでは、ノイズを除去するという簡単な形でしか使用していません。自然言語を扱う際には、他にも多くの複雑な問題が発生する可能性があります。単語がスペースなしで結合される可能性があります("iDontLikeThis")が、特に分離されない限り、最終的には単一の単語として分析されます。さらに、「うーん」「ふーん」「ふーーん」「うんうん」などの誇張された単語も別の扱いを受けることになります。ノイズ除去のプロセスにおけるこれらの改良は、データに固有のものであり、手元のデータを慎重に分析した後でなければ行うことができません。
Twitter APIを使用している場合は、ツイートに関連するエンティティをハッシュタグ、URL、言及、メディアアイテムにグループ化して直接与えてくれるTwitterエンティティを探索してみるのもいいかもしれません。
単語密度
テキストデータの分析の最も基本的な形式は、単語の頻度を取り出すことです。1 つのツイートは単語の分布を調べるには小さすぎるので、単語の頻度の分析は 20000 個のツイートすべてに対して行われます。まず、データ内の各ツイートについて、クリーン化されたトークンのリストを作成してみましょう。
tokens_list = twitter_samples.tokenized('tweets.20150430-223406.json')
clean_tokens_list = [remove_noise(tokens, stop_words) for tokens in tokens_list]
データセットが大きく、レマタイズを必要としない場合は、上記の関数を変更して、ステム機能を含めるか、正規化を完全に避けるようにすることができます。
次に、クリーン化されたトークンのリストである clean_tokens_list から、ツイートに含まれるすべての単語のリストを作成します。
all_words = []
for tokens in clean_tokens_list:
for token in tokens:
all_words.append(token)
これでツイートのサンプルに含まれる全ての単語をコンパイルできたので、NLTKのFreqDistクラスを使って最もよく出てくる単語を調べてみましょう。.most_common()メソッドは、データの中で頻出する単語をリストアップします。
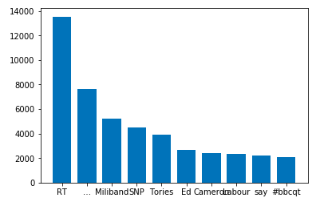
>>> freq_dist = nltk.FreqDist(all_words)
>>> freq_dist.most_common(10)
[('RT', 13539),
('…', 7663),
('Miliband', 5222),
('SNP', 4491),
('Tories', 3923),
('Ed', 2686),
('Cameron', 2419),
('Labour', 2338),
('say', 2208),
('#bbcqt', 2106)]
RTという言葉が多いのも頷けます。数年前のツイッターには、リツイートにコメントをつけるという選択肢がなかったので、非公式な方法としては、---"comment" RT @mention "original tweet "という構造に従うことになっていた。さらに、このツイートはイギリスがEU離脱を検討していた時期のもので、トップ用語には政党名や政治家名が含まれています。
次に、matplotlibを使って棒グラフに同じものをプロットすることができます。このチュートリアルではバージョン2.2.2.を使用しています。
pip install matplotlib=2.2.2
これでmatplotlibがインストールされたので、最も頻繁に使われる単語をプロットする準備ができました。
import matplotlib.pyplot as plt
items = freq_dist.most_common(10)
labels, values = zip(*items)
width = 0.75
plt.bar(labels, values, width, align='center', )
plt.show()
単語の分布を可視化するには、wordcloudパッケージを使用して単語の雲を作成することができます。
from wordcloud import WordCloud
cloud = WordCloud(max_font_size=60).generate(' '.join(all_words))
plt.figure(figsize=(16,12))
plt.imshow(cloud, interpolation='bilinear')
plt.axis('off')
plt.show()

名前付きエンティティの認識
NER(Named Entity Recognition)とは、文章から人、場所、組織などの名前のついた実体を検出する処理のことです。NLTKの本にも記載されていますが、NLTKに内蔵されている機能が認識するように訓練されている実体の種類は以下の通りです。
| Named Entity | Examples |
|---|---|
| ORGANIZATION | Georgia-Pacific Corp., WHO |
| PERSON | Eddy Bonte, President Obama |
| LOCATION | Murray River, Mount Everest |
| DATE | June, 2008-06-29 |
| TIME | two fifty a m, 1:30 p.m. |
| MONEY | 175 million Canadian Dollars,GBP 10.40 |
| PERCENT | twenty pct, 18.75 % |
| FACILITY | Washington Monument, Stonehenge |
| GPE (Geo Political Entity) | South East Asia, Midlothian |
NERの処理に入る前に、以下をダウンロードしておきましょう。
>>> nltk.download('maxent_ne_chunker')
[nltk_data] Downloading package maxent_ne_chunker to C:\Users\Shaumik
[nltk_data] Daityari\AppData\Roaming\nltk_data...
[nltk_data] Unzipping help\maxent_ne_chunker.zip.
True
>>> nltk.download('words')
[nltk_data] Downloading package words to C:\Users\Shaumik
[nltk_data] Daityari\AppData\Roaming\nltk_data...
[nltk_data] Unzipping help\words.zip.
True
テキストの中から名前付きのエンティティを見つけるには、以下のようにデータのチャンクを作成する必要があります。
from nltk import ne_chunk, pos_tag
chunked = ne_chunk(pos_tag(clean_tokens_list[15]))
ne_chunkの出力は、.draw()メソッドを使って描画したときに可視化できるnltk.Treeオブジェクトです。
chunked.draw()

画像を見ると、chunkedが文字列Sをルートノードとするツリー構造を生成していることがわかります。Sのすべての子ノードは、単語位置のペアか名前付き実体の型です。どのノードが名前付き実体を表すかは、サブツリーの根であるため、グラフの中で簡単に選ぶことができます。名前付き実体ノードの子ノードは、別の単語位置ペアです。
名前付き実体を収集するには、chunkedで生成されたツリーを辿って、ノードがnltk.tree.Tree.Treeの型を持っているかどうかを確認することができます。
from collections import defaultdict
named_entities = defaultdict(list)
for node in chunked:
# Check if node is a Tree
# If not a tree, ignore
if type(node) is nltk.tree.Tree:
# Get the type of entity
label = node.label()
entity = node[0][0]
named_entities[label].append(entity)
すべての名前の付いた実体を持つdeafultdictを作成したら、出力を検証することができます。
>>> named_entities
defaultdict(list,
{'GPE': ['Cameron'],
'ORGANIZATION': ['LONDON'],
'PERSON': ['David']})
TF-IDF
TF-IDF (term frequency - inverse document frequency) は、ある用語が文書にとってどれだけ重要かを示す統計量です。理想的には、TF-IDFリストの先頭にある用語が、テキストのトピックを決定する上で重要な役割を果たしていることが望ましい。
NLTKには文書のTF-IDFを計算するTextCollectionクラスがあります。しかし、ドキュメントにあるように、このクラスはプロトタイプなので、効率的ではないかもしれません。このチュートリアルでは、pipでインストールできるscikit-learnパッケージ(バージョン0.19.1)とnumpy(バージョン1.14.3)のTF-IDF変換器を使って作業します。
CountVectorizerはテキストを行列形式に変換し、TfidfTransformerは行列を正規化して各項のTF-IDFを生成します。
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer
import numpy as np
cv = CountVectorizer(min_df=0.005, max_df=.5, ngram_range=(1,2))
sentences = [' '.join(tokens) for tokens in clean_tokens_list]
cv.fit(sentences)
クラスを初期化する際に、min_df と max_df は、ドキュメントの最小数と最大数(ここでは文章)に存在する単語のしきい値を設定する引数です。これらは絶対数や比率で指定することができます。ドキュメントの0.5%以上、50%以上のドキュメントに含まれる単語を探しています。しきい値を通過した用語の数を確認する必要があります。
>>> len(cv.vocabulary_)
460
用語数を少なくしたい場合は、閾値を厳しくしても良いでしょう。今のところはこのまま進めても構いません。次のステップは、データの行列を作成することです。
cv_counts = cv.transform(sentences)
これにより、文の数と語彙の単語の数の次元を持つ行列が作成されます。次に、データの sparcity を計算し、行列のうちどれだけの部分がゼロではない値で埋められているかを確認することができます。
>>> 100.0 * cv_counts.nnz / (cv_counts.shape[0] * cv_counts.shape[1])
1.8398804347826088
nnz は,行列の中のゼロではない要素の数を与えます。このケースでは、1.83% の sparcity があります。次に、辞書を変換して、文書の重要度に応じて最も重要な用語を取得する必要があります。
transformed_weights = TfidfTransformer().fit_transform(cv_counts)
features = {}
for feature, weight in zip(cv.get_feature_names(),
np.asarray(transformed_weights.mean(axis=0)).ravel().tolist()):
features[feature] = weight
sorted_features = [(key, features[key])
for key in sorted(features, key=features.get, reverse=True)]
ここでは、ツイートのセットで最も重要なトップ10の用語とその重みを示しています。驚くことではありませんが、データのほとんどは政治家(miliband, cameron)と政党(ukip、labour)で埋め尽くされています。
>>> sorted_features[:10]
[('snp', 0.05178276636641074),
('miliband', 0.05100430290549024),
('ukip', 0.04243121435695297),
('tories', 0.03728900816044612),
('ed', 0.03455733071449128),
('labour', 0.033745972243756014),
('bbcqt', 0.033517709341470525),
('cameron', 0.03308571509950097),
('farage', 0.033009781157403516),
('tory', 0.03129438215249338)]
別の方法として、文書が何についてのものかを決定するためにトピックモデリングを行うこともできます。興味のある方のために、gensim パッケージを使った LDA アルゴリズムの実装を紹介します。
結論
このチュートリアルでは、Pythonでの自然言語処理の基礎を紹介し、統計分析を行う前のデータの様々な前処理の段階について説明しました。次に、一般的なNLPタスクである単語頻度、単語群、NER、TF-IDFについて説明しました。
このチュートリアルが参考になったのではないでしょうか。PythonでNLPのために他のツールを使っていますか?下のコメント欄で教えてください。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ