本記事では、Alibaba CloudのENI(Elastic Network Interface)技術をベースにしたコンテナネットワークの基礎を紹介します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
従来のコンテナネットワークソリューション
ここでは、従来のコンテナネットワークの動作原理を紹介します。
CNIは、Cloud Native Computing Foundation (CNCF)が運営するオープンソースプロジェクトです。これは、Linuxコンテナネットワーク管理のためのプラグインを開発するための標準を開発し、主要なベンダーにソースコードライブラリを提供しています。よく知られているCNIプラグインには、CalicoやFlannelなどがあります。Calico は Flex/Bird を通じて BGP などのプロトコルを実装し、それらを分散型のインメモリデータベースに格納して大規模なレイヤ 3 ネットワークを構築し、異なるホスト上のコンテナが ARP を送信せずに異なるサブネット上のコンテナと通信できるようにします。
Flannelは、VXLANなどのトンネリング技術に基づいたコンテナオーバーレイネットワークを実装しています。Calico/FlannelなどのCNIは、コンテナネットワークを構成するためにVETHペアを使用します。VETH デバイスのペアが作成され、一方の端がコンテナにバインドされ、もう一方の端が VM にバインドされます。VMは、ネットワークプロトコルスタック(オーバーレイネットワーク)、Iptables(Calicoプラグイン)、Linux Bridgeなどの技術を介してコンテナネットワークを転送します。(コンテナネットワークがECSのブリッジを介してvSwitchに接続されている場合、VPCはECSレベルにしか到達できず、コンテナネットワークはブリッジ上のプライベートネットワークとなります)。
現在主流となっているコンテナネットワークのワークフローを下図に示しますが、マルチNICコンテナネットワークとは以下の点で異なります。
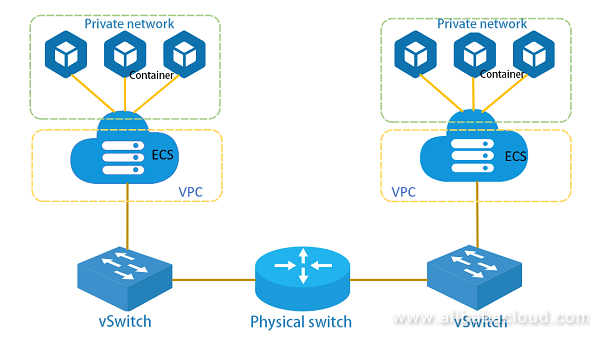
1、ホスト1上のコンテナから送信されたメッセージは、VETHを介してVM上のLinux Bridgeに送信され、Linux Bridgeはフォワーディングロジックを実行して、メッセージVM上のNICをホスト上に配置されたvSwitchに送信します。
2、ホスト2上のVMは、vSwitchから送信されたメッセージを受信し、Linux Bridgeのフォワーディングロジックを用いてVETHを介してコンテナに送信します。
ネットワークシステム全体では、VMはネットワーク構成のためにK8SなどのオーケストレーションシステムのCNIプラグインを内部的に必要とします。vSwitchはOpenflowやNetconfなどの通信プロトコルをサポートしており、これらはSDN(Software Defined Network)コントローラを介して管理・設定されます。主流のToRスイッチは、リモート設定にNetconfプロトコルを使用します。OpenflowをサポートするSDN物理スイッチも市場に出回っています。
ネットワーク全体を管理するためには、2つの異なるネットワーク制御システムが必要になります。構成が比較的複雑で、実装の仕組みなどの要因で一定のパフォーマンスのボトルネックが存在します。ホスト上のセキュリティポリシーをコンテナアプリケーションに適用出来ません。
マルチNICコンテナネットワーク
VMに動的にホットスワップ可能な複数のNIC(Network Interface Card)がある場合、これらのNICをコンテナネットワーク上で使用できるため、コンテナネットワークではLinux VETHやBridgeなどの技術を利用する必要がなくなります。同時に、ホスト上の仮想スイッチ(vSwitch)にメッセージが転送されるため、プロセスが簡素化され、ネットワークパフォーマンスが向上します。
ソリューションの概要
次の図に示すように、VMとコンテナからのトラフィックを転送するために、ホスト上でvSwitchが動作しています。vSwitchには複数の仮想NICが接続されています。コンテナがVM上で起動されると、仮想NICはホスト上でコンテナが配置されているVMに動的にバインドされ、その後、VM内でNICはコンテナが配置されているネットワークネームスペースにバインドされ、コンテナ内のネットワークトラフィックをNICを介してホスト上に配置されているvSwitchに直接送信することができます(つまり、コンテナのネットワークはvSwitchに直接接続することができます)。
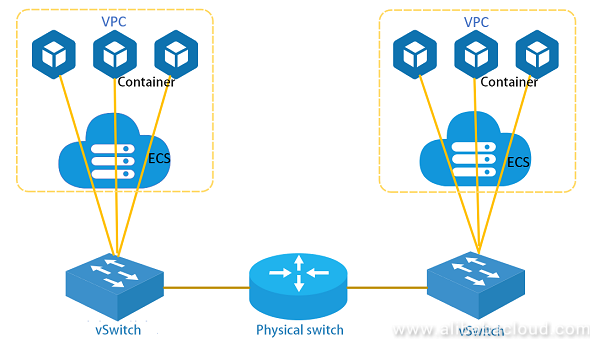
ACL、QoS、Session などのルールが vSwitch で適用され、トラフィックを転送します。ホスト 1 の VM 上で動作しているコンテナがホスト 2 の VM 上で動作しているコンテナにアクセスする場合、トラフィックは一般的に以下のプロセスを経ます。
1、ネットワークメッセージがコンテナコアのネットワークプロトコルスタックを通過します。ルートが照会された後、メッセージは eth0 NIC を介して送信されます。
2、ホスト上のvSwitchは、仮想ポートを介してコンテナからのメッセージを受信し、vSwitchのフォワーディングロジックを実行して、物理ネットワークポートを介してトップオブラック(ToR)スイッチにパケットを送信します。コンテナまたはVMネットワークに仮想プライベートクラウド(VPC)が確立されている場合、メッセージはVXLANなどのトンネリング技術を使用してカプセル化する必要があります。
3、ToRスイッチはルートを問い合わせ、ホスト2の物理ポートに接続してメッセージを転送します。
4、ホスト2のvSwitchは物理ポートのメッセージを受信し、転送ロジックを介してコンテナに接続する仮想ポートに送信します。
5、相手側から送られてきたメッセージをコンテナ内のプロトコルスタックeth0が受信し、コンテナ内のネットワークプロトコルスタックで処理します。
ソリューションの特徴
VM上でコンテナを稼働させる従来のソリューションと比較して、高いパフォーマンスと管理のしやすさ、強力なアイソレーションが特徴です。
VPCへの直接接続
マルチNICソリューションでは、コンテナがVPCネットワークプレーンに直接アクセスできるため、各コンテナはEIP、SLB、Anti-DoS Pro、セキュリティグループ、HAVIP、NAT、ユーザールーティングなどのVPCネットワーク機能をフルに提供することができます。
Cross-VPC
マルチNICソリューションを介してVPCのネットワークプレーンに直接アクセスするコンテナは、ピア機能などのVPCの一部の高度な機能を利用することができます。また、クラウド製品へのアクセスにはCross-VPC ENIを利用することができ、異なるVPC内の複数のNICをコンテナに割り当てることができます。これにより、複数のVPCをまたいでコンテナを利用することができます。
ハイパフォーマンスを実現
マルチNICソリューションでは、コンテナ内のネットワークトラフィックは、VM上のIptables/Bridgeを経由して転送される必要はなく、ホスト上にあるvSwitchに直接転送されます。これにより、VM上のデータメッセージ転送ロジックが不要となり、データコピー処理が簡素化されるため、コンテナネットワークのパフォーマンスが大幅に向上します。次の表は、1回のテストでの異なるソリューションの基本性能データを示しています。
| Single-thread (Mbps) | Single-thread (pps) | Multi-thread (pps) | TBase test 1 KB (QPS) | |
|---|---|---|---|---|
| Linux Bridge | 32.867 | 295,980 | 2,341,669 | 363,300 |
| Multi-NIC solution | 51.389 | 469,865 | 3,851,922 | 470,900 |
| Performance improvement | 56.35% | 58.7% | 64.49% | 29.6% |
強力な分離
従来のブリッジソリューションでは、すべてのコンテナインスタンスが同じ大きなレイヤ2ネットワーク上にあるため、ブロードキャスト、マルチキャスト、未知のユニキャストが氾濫してしまうという問題がありました。マルチNICソリューションが提供する直接接続機能とECSネットワークが提供するACLやセキュリティグループ機能により、セキュリティの分離を効果的に確保することができます。コンテナの管理画面上でもコンテナネットワークのトラフィックを見ることができません。セキュリティルールはVMレベルではなくコンテナレベルで適用されます。
簡単な管理
管理システムがコンテナを VM にディスパッチすると、制御システムは VM が配置されているホスト上の vSwitch 上に NIC を作成し、ホットスワップで VM に NIC を挿入し、VM 上のコンテナネットワークネームスペースに NIC を設定します。vSwitchのトラフィック転送ルールを設定し、xGW上でHaVIPを設定することで、外部アプリケーションやクライアントはコンテナが提供するサービスにアクセスすることができます。
また、マルチNICソリューションは、コンテナの移行を容易にします。同じホストに移行した別のVMを例にとると、K8SのKubeletモジュールはアプリケーションを移行した後、CNIプラグインによるネットワークの再設定、コンテナIPとVIPの管理、コンテナアプリケーションへのアクセス方法の設定を行います。全体のプロセスは複雑ですが、NICソリューションを使えば簡単にできます。コンテナがVMにディスパッチされた後、古いコンテナにバインドされているNICを古いVMから外し、新しいコンテナがあるVMに挿入します。そして、NICはVM上のコンテナネットワークネームスペースにバインドされます。新しいコンテナは、これ以上ネットワークを再設定する必要がなく、通常通り通信することができます。
DPDKサポート
その優れた性能上の優位性から、DPDKが普及し、DPDKをベースにしたアプリケーションがどんどん開発されています。従来のコンテナネットワークでは、ネットワークデバイスとしてVETHを使用していますが、現在はDPDKのPDKドライバを直接使用することができないため、DPDKベースのアプリケーションをコンテナ内で直接使用することはできません。マルチNICソリューションでは、コンテナは一般的な E1000 または virtio_net デバイスである ECS ネットワークデバイスを使用します。どちらのデバイスにもPMDドライバが搭載されており、コンテナはこのデバイスを使用してDPDKベースのアプリケーションを直接実行することができるため、コンテナ内のアプリケーションのネットワークパフォーマンスが向上します。
VM マルチNIC
物理ホストのクロスドメインを有効にするには、物理マシンに複数のNICを挿入する必要があります。PCIスロットの制限とコストのため、物理マシンに2つ以上のNICを配置することは稀です。ハードウェアデバイスの電源を多かれ少なかれオンまたはオフにすると、システム全体にパルスが追加され、マシンの安定性に影響を与え、デバイスのホットスワップが制限されます。一般的なホットスワップデバイスはUSBデバイスです。PCIデバイスのホットスワップは、2つの列挙の必要性と電力効果のため、近年まで制限的なサポートを受けていませんでした。
仮想環境では、仮想NICの低コストと柔軟性により、VMの可用性が大幅に向上します。ユーザーは必要に応じてNICを動的に割り当てたり、解放したりすることができ、VMの正常な動作に影響を与えることなく、VMへのNICのプラグインやプラグの抜き差しを動的に行うことができます。libvirt/qemu が仮想デバイスをシミュレートする方法には、物理ホストでは実現できない以下の利点があります。
リソースの制限
システムにメモリなどの十分なリソースがあれば、複数のNICをシミュレートして同じVMに割り当てることができ、1つのVMに64枚、あるいは128枚のNICをインストールすることも可能です。ソフトウェアでシミュレートされたNICは、物理的なハードウェア環境のものに比べて、はるかに少ないコストで実現できます。また、マルチキューやメインストリームハードウェアのアンインストール機能もサポートしており、システムの柔軟性が向上しています。
ダイナミックホットスワップ
VM上のNICはソフトウェアによってシミュレートされます。そのため、NICが必要な場合には、NICをシミュレートするためにソフトウェアによっていくつかの基本的なリソースが割り当てられます。ホットスワップフレームワークにより、libvirt/qemu を実行中の VM に簡単にバインドすることができ、VM は NIC を使ってネットワークメッセージを送信することができます。NIC が不要になったら、VM を停止させることなく、libvirt/qemu インターフェイスコールで NIC を "unplugged" することができます。NIC に割り当てられたリソースは破棄され、NIC に割り当てられたメモリはリサイクルされ、中断は回復します。
コンテナネットワークの実装
ここでは、VMのマルチNICを利用してコンテナネットワーク通信をステップごとに実装する方法を説明します。
1、Alibaba CloudコンソールでVMインスタンスを作成し、インスタンス作成時に複数のNICを選択します。すると、VM上に複数のNICが表示されます。
2、VM上にコンテナアプリケーションをデプロイします。
~# docker run -itd --net none ubuntu:16.04
注:Docker起動時にコンテナのネットワークタイプをnoneに指定します。
3、VM にログオンし、NIC の 1 つをコンテナの名前空間にバインドします。次の例では、新しく動的に挿入されたNICはeth2で、コンテナのネットワークネームスペースは2017です(明確にするために、docker inspectで見たPIDをネットワークネームスペースとして使用しています)。
~# mkdir /var/run/netns
~# ln -sf /proc/2017/ns/net /var/run/netns/2017
~# ip link set dev eth2 netns 2017
~# ip netns exec 2017 ip link set eth2 name eth0
~# ip netns exec 2017 ip link set eth0 up
~# ip netns exec 2017 dhclient eth0
注: リリースバージョンによっては、ユーザーが手動で接続を作成してコンテナのネットワークネームスペースを「作成」する必要がない場合があります。eth2 をコンテナのネットワークネームスペースにバインドした後、eth0 に名前を変更します。
4、VM とコンテナ内の NIC 構成ステータスを表示します。
VM 上に NIC がまだ存在するかどうかを確認します。
~# ifconfig -a
コンテナ内に新しく設定されたNICがあるかどうかを確認します。
/# ifcofig -a
VMからeth2が削除され、コンテナに適用されたことがわかります。
5、手順1から4を繰り返して、別のVMとコンテナを起動します。
6、sockperfなどのツールを使ってパフォーマンスのテストや比較を行います。
$ cat server.sh
# !/bin/bash
for i in $(seq 1 $1)
do
sockperf server --port 123`printf "%02d" $i` &
Done
$ sh server.sh 10
$ cat client.sh
# !/bin/bash
for i in $(seq 1 $1)
do
sockperf tp -i 192.168.2.35 --pps max --port 123`printf "%02d" $i` -t 300 &
done
$ sh client 10
Antの金融ユースケース
Tier-Base (TBase) は Redis に似た分散型 KV データベースです。C++で書かれており、ほとんどすべてのRedisデータ構造をサポートしています。また、バックエンドとしてRocksDBをサポートしています。TBaseはAnt Financialで広く利用されています。ここでは、本ソリューションのTBaseビジネステストについて紹介します。
従来のLinuxブリッジテスト
テスト環境
サーバー:16C60G×1(ハーフA8)
クライアント:4C8G×8
TBaseサーバーの導入:7G×7インスタンス
TBaseクライアントの展開:8 x (16スレッド+1クライアント) => 128スレッド+8クライアント
試験報告書
| Operation | Packet size | Clients | NIC | load1 | CPU | QPS | AVG rt | 99th rt |
|---|---|---|---|---|---|---|---|---|
| set | 1 KB | 8 | 424 MB | 7.15 | 44% | 363,300 | 0.39 ms | < 1 ms |
| get | 1 KB | 8 | 421 MB | 7.06 | 45% | 357,000 | 0.39 ms | < 1 ms |
| set | 64 KB | 1 | 1,884 MB | 2.3 | 17% | 29,000 | 0.55 ms | < 5 ms |
| set | 128 KB | 1 | 2,252 MB | 2.53 | 18% | 18,200 | 0.87 ms | < 6 ms |
| set | 256 KB | 1 | 2,804 MB | 2.36 | 20% | 11,100 | 1.43 ms | < 5 ms |
| set | 512 KB | 1 | 3,104 MB | 2.61 | 20% | 6,000 | 2.62 ms | < 10 ms |
ENI マルチNICテスト
テスト環境
サーバー:16C60G×1(ハーフA8)
クライアント:4C8G×8
TBaseサーバーの導入:7G×7インスタンス
TBaseクライアントの展開:16 x (16スレッド+1クライアント) => 256スレッド+16クライアント
試験報告書
| Operation | Packet size | Clients | NIC | load1 | CPU | QPS | AVG rt | 99th rt |
|---|---|---|---|---|---|---|---|---|
| set/get | 1 KB | 16 | 570 MB | 6.97 | 45% | 470,900 | 0.30 ms | < 1 ms |
テストの結論
ENIのマルチNICソリューションをベースに、ブリッジソリューションと比較して、全体的なパフォーマンスが向上し、遅延が大幅に短縮されています(QPSが30%向上し、平均遅延が23%短縮されています)。16C60Gのサーバーを使用し、QPSが470,900程度だとします。この場合、平均rtは0.30ms、99番目のrtは1ms以下となります。CPUの45%、29%、18%、2%がそれぞれユーザ、sys、si、stで消費されています。Linux Bridgeと比較して、multi-NCソリューションの特徴は、siによるCPU消費量が大幅に少ないことです。カーネルキュー分散により、st の CPU 消費量を複数の異なるコアに分散させることで、処理リソースの使用量をよりバランスよくすることができます。
VPCルートテーブルであるFlannel/Canalのソリューションでは、帯域幅とスループットの大幅な損失はありません。遅延はホストに対して0.1ms程度になります。QPSのテストにはNginxを使用しており、ページが小さい場合は10%程度の損失となります。ENIソリューションでは、ホストとの相対的な帯域幅とスループットの大幅な損失はなく、遅延はホスト上よりもわずかに低くなります。アプリケーションテストでは、PODがiptablesの対象になっていないため、ホストネットワーク上よりも10%程度パフォーマンスが向上しています。デフォルトのFlannel VXLANでは、帯域幅とスループットの損失が5%程度、Nginxスモールページテストの最大QPSでは、ホストとの相対的な性能低下が30%程度となっています。
概要
本稿では、VMのマルチNICホットスワップに基づくコンテナネットワークソリューションを紹介しました。VM用のNICを動的にホットスワップしてコンテナに適用し、コンテナネットワークのデータメッセージの送受信を行い、VM上で動作する仮想ソフトウェアスイッチを介してネットワークメッセージを転送することで、コンテナネットワークの管理・制御システムの複雑さを大幅に軽減し、ネットワークパフォーマンスを向上させ、コンテナネットワークのセキュリティを強化しています。
Alibaba Cloud Elastic Network Interface(ENI)は、VPC内のECSインスタンスに接続できる仮想ネットワークインターフェースです。ENIを利用することで、高可用性のクラスタを構築し、低コストでフェイルオーバーを実装し、洗練されたネットワーク管理を実現することができます。ENI機能はすべてのリージョンで利用可能です。ENIの詳細については、以下のページを参照してください。
1、機能と紹介:https://www.alibabacloud.com/help/doc-detail/58496.htm
2、ユーザーガイド: https://www.alibabacloud.com/help/doc-detail/58503.htm
3、開発者ガイド:https://www.alibabacloud.com/help/doc-detail/25485.htm
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ