はじめに
これまでWatson Speech to Text (STT)の記事をいくつか書いてきました。
どうやって精度を測定するかや評価するかということをよく聞かれるので記事にすることにしました。
測定の計算式は以下の2つで、英語の場合は単語誤り率、日本語の場合は文字誤り率でよいと思います。
単語誤り率(Word Error Rate; WER)=(挿入単語数 + 置換単語数 + 削除単語数)/正解単語数
文字誤り率(Character Error Rate; CER)=(挿入語数 + 置換語数 + 削除語数)/正解語数
精度の評価については、こちらの論文によると
話し言葉の音声認識の進展―議会の会議録作成から講演・講義の字幕付与へ 河原 達也
- 人間が見て意味が分かるレベルは75%~
- 議会の議事録レベルは85%~
- アナウンサーの原稿読み上げレベル95%~
音声認識の精度は、最低限75%は目指したいし、85%あれば胸をはれる認識精度だと思います。
単語誤り率(Word Error Rate; WER)の測定ツール
英語の精度を測定する場合はこちらのオリジナルのソースコードをご参照下さい。
WER-in-python
このツールを日本語へ対応するためにMeCabで形態素解析を行なった版がこちらです。
https://github.com/kchan7/WER-CER
行毎に単語を比較するので、句点(。)読点(、)は不要なので削除して下さい。
original_file.txtは正解とする文書、target_file.txtはSTTで書き起こした文書です。
git clone https://github.com/kchan7/WER-CER.git
pip install numpy
brew install mecab
pip install mecab-python3
python wer.py original_file.txt target_file.txt
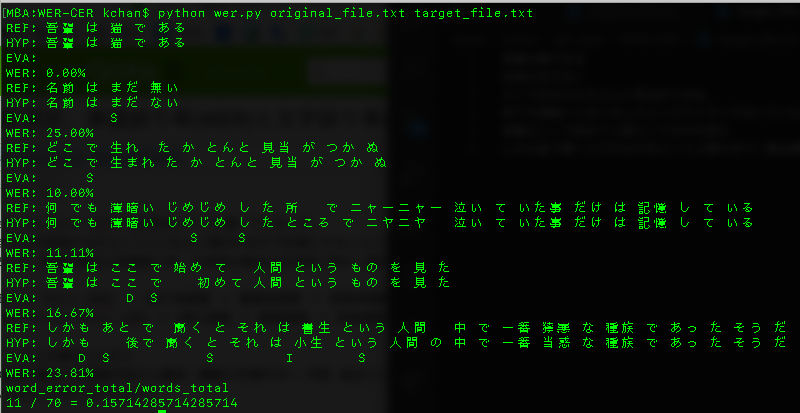
単語誤り率(WER)は0.157142857142857
単語認識率=1.0-WER(0.157142857142857)=0.842857143
単語認識率は約84%となります。
文字誤り率(Character Error Rate; CER)の測定ツール
pythonのdifflibを使って差分を計測しています
python cer.py original_file.txt target_file.txt
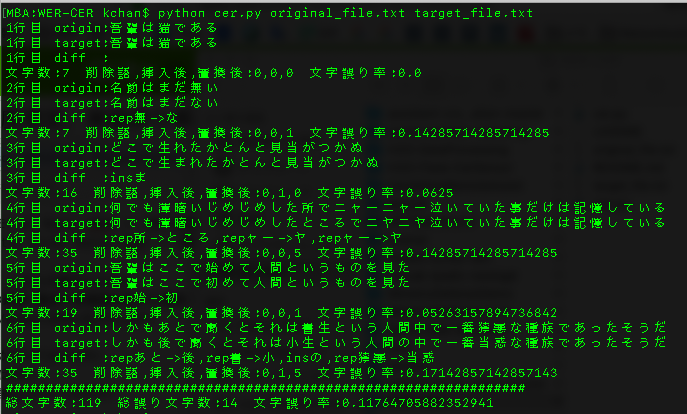
文字誤り率(CER)は0.11764705882352941
文字認識率=1.0-CER(0.11764705882352941)=0.882352941
文字認識率は約88%となります。
関連記事
Watson Speech to Text (STT) 概要編
Watson Speech to Text (STT) 基本操作curl編
Watson Speech to Text (STT) 挙動確認編