はじめに
この記事ではWatson STTのLanguage model(言語モデル)をcurlで学習する手順を備忘録としてまとめました。
そもそもカスタムモデルって何それ?食えんの?という方はこちらをご覧下さい。
Watson Speech to Text (STT) 概要編
事前準備
- IBMCloudのアカウント
- STTの有償プラン(フリープランではカスタマイズができません、2019年8月執筆時点)
- curl(普通はインストールされてるよね)
- jq (macの場合
brew install jq、windows使いの方はググって下さい) - nkf (macの場合
brew install nkf、windows使いの方はググって下さい)
※筆者の環境はmacです、windows使いの方はゴメンなさい、適宜読み替えていただければ幸いです。
Language model(言語モデル)の手順とポイント
- カスタム言語モデルを新規で作成する(IDが発行される)
- IDを指定してcustom corporaの登録
- 自動で登録されたcustom wordsの候補を削除する
- IDを指定してcustom wordsの登録
いきなりですが、最重要ポイントは、ステップ3の自動で登録されたcustom wordsの候補を削除するです。
私はここでつまづき苦労しました…。
ステップ2でcustom corporaを登録するとWatsonさんがこれはOOVなという単語を自動的に選んでcustom wordsの候補に登録してくれます。しかし、この候補に禁止語句が入っている状態でtrainするとコケてしまうんですね。
私はこの事に気がつかずに悩みました…。
( Watsonさん、そんな単語をフツー選ぶ?)
とにかく、このポイントにさえ気をつけていれば、あとはcurlを叩くだけです。
さあ、やってみましょう!!
1.カスタム言語モデルを新規で作成する
ご自身の環境のエンドポイントを調べて下さい。
IBM Cloudの、どのリージョンでSTTインスタンスを作成したかということです。
STTエンドポイント一覧
今回は私が作成したTokyoでいきたいと思います。
Tokyo: https://gateway-tok.watsonplatform.net/speech-to-text/api
STTのリファレンス curl
curlメソッドであるCreate a custom language modelはこちらです
curlを実行する際にはURLを指定する必要があります。
URLのルールは、(リージョンは東京で、メソッドがCreate a custom language modelの場合)
=https://gateway-tok.watsonplatform.net/speech-to-text/api/v1/customization```
となります。
apikeyは、サービス環境情報>資格情報の表示>apikeyからコピーして下さい。

```Bash:Create_a_custom_language_model
curl -X POST -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" \
--header "Content-Type: application/json" \
--data "{\"name\": \"STT_SampleModel\", \"base_model_name\": \"ja-JP_BroadbandModel\", \"description\": \"Custom LM SampleModel\"}" \
"https://gateway-tok.watsonplatform.net/speech-to-text/api/v1/customizations" \
- nameはcustom language modelの名前
- base_model_nameはベースにするモデル名(使用できるモデルは一覧で確認可能。GET /v1/models)
- descriptionはコメント
- レスポンスは、正常終了の場合は作成されたモデルのID

今回の例でモデルのIDは、df60a30a-afd3-4c47-ad92-5c63637c7480
2.IDを指定してcustom corporaの登録
curl -X POST -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" \
--data-binary @natsumesouseki.txt \
"https://gateway-tok.watsonplatform.net/speech-to-text/api/v1/customizations/df60a30a-afd3-4c47-ad92-5c63637c7480/corpora/custom_corpus01"
- customizations/の後にモデルのIDを指定して下さい
- corpora/の後にcorpusの名前を登録して下さい
- レスポンスは、正常終了の場合は{}

登録したテキストは下記です。(リンク先の全文登録しました。下記は一部抜粋。)
https://www.aozora.gr.jp/cards/000148/files/789_14547.html
吾輩は猫である。名前はまだ無い。
どこで生れたかとんと見当がつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。吾輩はここで始めて人間というものを見た。しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。この書生というのは時々我々を捕えて煮て食うという話である。しかしその当時は何という考もなかったから別段恐しいとも思わなかった。ただ彼の掌に載せられてスーと持ち上げられた時何だかフワフワした感じがあったばかりである。掌の上で少し落ちついて書生の顔を見たのがいわゆる人間というものの見始であろう。この時妙なものだと思った感じが今でも残っている。第一毛をもって装飾されべきはずの顔がつるつるしてまるで薬缶だ。その後猫にもだいぶ逢ったがこんな片輪には一度も出会わした事がない。のみならず顔の真中があまりに突起している。そうしてその穴の中から時々ぷうぷうと煙を吹く。どうも咽せぽくて実に弱った。これが人間の飲む煙草というものである事はようやくこの頃知った。
この書生の掌の裏でしばらくはよい心持に坐っておったが、しばらくすると非常な速力で運転し始めた。書生が動くのか自分だけが動くのか分らないが無暗に眼が廻る。胸が悪くなる。到底助からないと思っていると、どさりと音がして眼から火が出た。それまでは記憶しているがあとは何の事やらいくら考え出そうとしても分らない。
3.自動で登録されたcustom wordsを削除する
ここで登録されているcustom wordsのリストを表示すると、なんと既に自動で単語が候補として登録されていることに注意です!!
curl -X GET -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" \
"https://gateway-tok.watsonplatform.net/speech-to-text/api/v1/customizations/df60a30a-afd3-4c47-ad92-5c63637c7480/words?sort=%2Balphabetical"
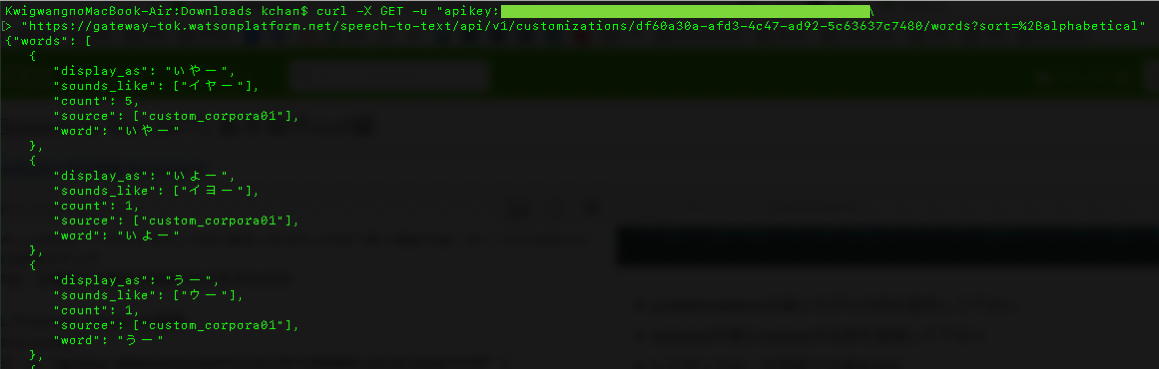
Watsonが自動的にcorpusからOOVの単語を登録しているのですが、この登録されている単語の候補がSTTの仕様を満たさない場合は後続のtrainでエラーとなります。
sounds_likeの仕様について

自動的にcustom wordsへ候補として登録されてある単語を、jqを使ってcustom_wordslist.txtへ出力しましょう。
curl -X GET -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" \
"https://gateway-tok.watsonplatform.net/speech-to-text/api/v1/customizations/df60a30a-afd3-4c47-ad92-5c63637c7480/words?sort=%2Balphabetical" | jq '.words[].word' -r > custom_wordslist.txt

custom wordsは次のステップで自分で選んだ単語を登録するとして、
custom_wordslist.txtの単語を一個一個チェックするのは面倒なので、シェルスクリプトでまとめて一旦削除しましょう。
# !/bin/bash
while read line
do
#URLエンコードの参考にした記事
#https://qiita.com/ik-fib/items/cc983ca34600c2d633d5
ENCODE=`echo ${line} | nkf -WwMQ | sed 's/=$//g' | tr = % | tr -d '\n'`
curl -X DELETE -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" "https://gateway-tok.watsonplatform.net/speech-to-text/api/v1/customizations/df60a30a-afd3-4c47-ad92-5c63637c7480/words/${ENCODE}"
done < custom_wordslist.txt
4.IDを指定してcustom wordsの登録
custom wordsのjsonファイルのフォーマットは下記です。
- wordはURLに登録される名前です。アルファベットなら指定する際にURLエンコードする必要がなくなります。
- sounds_likeは必ずカタカナで登録します、このカタカナが仕様を満たす音節でなければなりません。
- display_asは表示される文字で、漢字やひらがなやカタカナやアルファベットです。
{"words":
[
{"word": "吾輩", "sounds_like": ["ワガハイ"], "display_as": "吾輩"},
{"word": "獰悪", "sounds_like": ["ドウアク"], "display_as": "獰悪"},
{"word": "薬缶", "sounds_like": ["ヤカン"], "display_as": "薬缶"},
{"word": "片輪", "sounds_like": ["カタワ"], "display_as": "片輪"},
{"word": "煙草", "sounds_like": ["タバコ"], "display_as": "煙草"}
]
}
curl -X POST -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" \
--header "Content-Type: application/json" \
--data @sampleformat_words.json \
"https://gateway-tok.watsonplatform.net/speech-to-text/api/v1/customizations/df60a30a-afd3-4c47-ad92-5c63637c7480/words"
- 正常レスポンスは{}

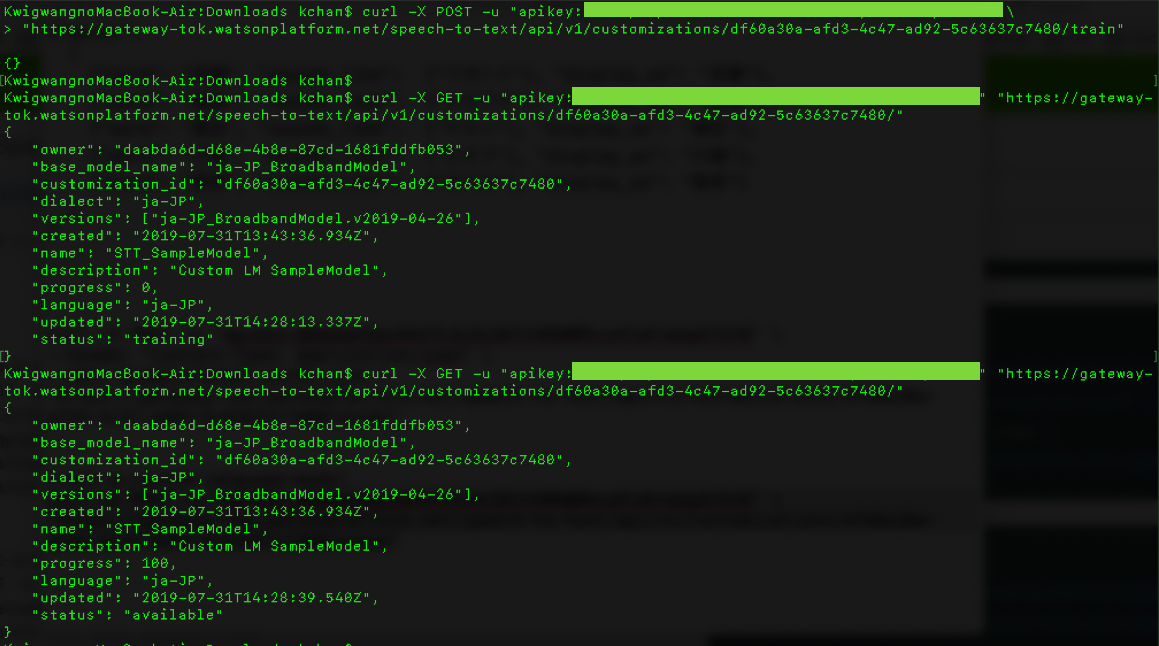
モデルの状態を確認するメソッドです。
curl -X GET -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" \
"https://gateway-tok.watsonplatform.net/speech-to-text/api/v1/customizations/df60a30a-afd3-4c47-ad92-5c63637c7480/"
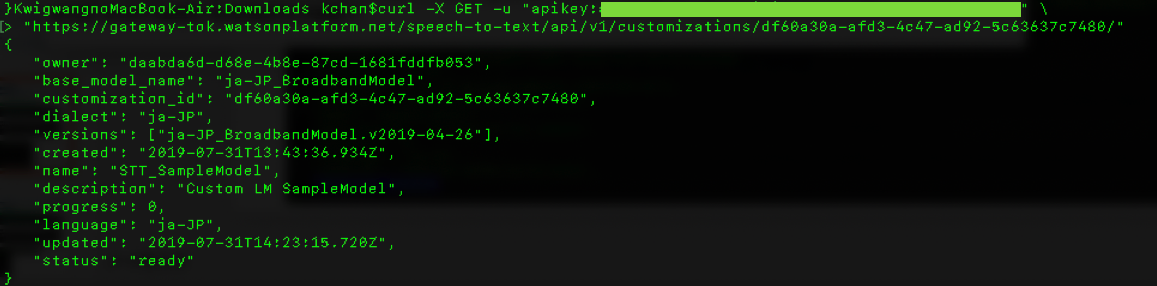
- statusがreadyなら学習データの取り込みが完了してtrainが実行できる状態です
デプロイしてある学習データを取り込んでtrainするためのメソッドです。
curl -X POST -u "apikey:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" \
"https://gateway-tok.watsonplatform.net/speech-to-text/api/v1/customizations/df60a30a-afd3-4c47-ad92-5c63637c7480/train"
- trainを実行するとstatusがtrainingとなり、完了するとavailableとなります。
関連記事
Watson Speech to Text (STT) 概要編
Watson Speech to Text (STT) 挙動確認編
音声認識の精度測定、単語誤り率(WER)と文字誤り率(CER)