先日、XLNetと呼ばれるNLPモデルに関する論文がarXivにアップロードされました。
https://arxiv.org/abs/1906.08237
XLNetは、その巨大さもさる事ながら、性能においても18個のベンチマークでSOTAを記録し、対BERTにおいてはすべてのタスクで上回るという驚異的な記録を残しています。
このモデルを一言でいうならば、
双方向TransformerであるBERTのアプローチを拡張し、自己回帰モデルによる学習を可能にしたNLPモデル。
といった感じです。
ではさっそく中身をみてましょう。
前提知識
-
自己回帰
AR(自己回帰)モデルはテキスト中単語の同時確率分布に従って計算します。
この場合、モデルの解釈する文脈の方向は、前向き ${\prod_{t=1}^{T}};{p(x_t|\boldsymbol{x}_{<t})}$、もしくは後ろ向き ${\prod_{t=T}^{1}};{p(x_t|\boldsymbol{x}_{>t})}$ です。
近年のNLPモデル(e.g. Seq2Seq, GPT)はこの形式でしたが、文脈理解が単方向に制限されているためパフォーマンスに限界がありました。
* **DAE**
DAE(Denoising Auto Encoder)は確率分布を直接推定する代わりに、一部が壊れたデータから元のデータを再構成します。この方式では双方向の文脈を利用できるため、性能が上がりました(e.g. BERT)。 * **BERTについて**

BERTは双方向Transformerであり、カンニングができてしまうためARで学習はできません。
そのためランダムに抜かれたいくつかの単語を、残りの文脈から予測する問題設定にしています。 欠損させる方法は入力系列の15%について、
① 80% [MASK]トークンに置換
② 10% ランダムに置換
③ 10% 置き換えない
という処理を行います。
Transformerとは?
この時点で、何度か"Transformer"という言葉が出てきましたが、簡潔に言えばTransformerとは注意機構(Attention)を備えたNNモデルのことです。
XLNerやBERTもTransformerを多段に重ねたシンプルな構造をしているため、AttentionひいてはTransformerを理解していれば、それほど難しいものではありません。
Attentionが何なるかを知りたい人には、Ryobotさんによる論文解説 Attention Is All You Need (Transformer)やイラストによる説明が素晴らしいThe Illustrated Transformerなどがオススメです。
課題:[MASK]トークン使用の問題点
既存のモデル(e.g. ELMo, GPT)においては双方向文脈を用いることはできませんでした。
というのも自己回帰モデルに双方向的な文脈を読み取らせることは、モデル構造的に困難だからです。
例えばGPTでは後ろの単語にマスクをかけることで、前から順番に単語を予測するという学習をさせます。これが双方向の文脈利用となると、単語を順番に予測させるタスクでは本質的にカンニング(その時点で見てはいけない単語をみてしまうこと)が避けられません。
過去から未来の単語を予測するという一方通行的なタスクにおいて、双方向の文脈利用はただのチートになってしまいます。
ELMoは一見すると双方向の文脈を活用しているかのように思えます。しかし実際には、2つのモデルにforwardとbackwardそれぞれの文脈を使って学習させ、embeddingされた表現を結合して使っています。
これはDeepに双方向の文脈を活用しながら学習するアプローチではなく、どちらかといえばshallowな方法です。
これらのモデルの後発であるBERTでは、既存のモデルとは異なり文章自体にマスクをかけ、穴埋め問題のようにマスクされた単語を予測させるタスクで学習させることでこの問題を解決しました。(このようなモデルをMasked Language Modelといいます)
この方式はとても有力で、精度もかなり向上しました。
ただ、BERTにもいくつかの欠点があります。
入力テキストに対するマスキングによる学習は、BERTを当時のSOTAに引き上げましたが、その学習方法の不自然さが負の側面として残る形となりました。それは以下の2点です。
① [MASK]トークンはfine-tuningの時は用いないためpre-trainingとfine-tuningの学習に差異が生じる。
② [MASK]のせいで言語の同時確率分布のモデル化が不可能
詳しくみてみると、
①はfine-tuningでは生じない人工的な[MASK]トークンをpre-trainingで用いることは両者の剥離を生じさせ、性能的な問題になるのではないかと言っています。だとするとBERTのfine-tuningが一時間程度で済んでいた理由が気になります
②は、BERTとARモデルとの差異の直接的な原因になっています。以下の式を見てください。
{\mathop{\mathrm{max}}_{\theta}}\;\;\mathrm{log}\,{p_\theta}\;(\bar{\boldsymbol{x}}\,|\,\hat{\boldsymbol{x}})\approx\sum_{t=1}^{T}{m_t\,\mathrm{log}\,{p_\theta(x_t\,|\,\hat{\boldsymbol{x}}})}=\sum_{t=1}^{T}{m_t\,\mathrm{log}\frac{\mathrm{exp}(H_{\theta}(\hat{\boldsymbol{x}})_{t}^{\textsf{T}}e(x_t))}{\sum_{x^\prime}{\mathrm{exp}(H_{\theta}(\hat{\boldsymbol{x}})_{t}^{\textsf{T}}e(x^\prime))}}}
(ここで$\boldsymbol{x}$は長さ$,T,$である元の文章、$\hat{\boldsymbol{x}}$は欠損ありの文章、$\bar{\boldsymbol{x}}$は文中の全マスクトークン、$\boldsymbol{m}$はマスクの位置($m_t=1$は$x_t$がマスクされていることを指す)、$\theta$はモデル(Transformer)のパラメータ、$H_{\theta}({\boldsymbol{x}})$は隠れ層のベクトル表示)
自己回帰モデルでは確率の連鎖律に則りモデルを最適化していましたが、一方BERTでは上式でみるようにそれぞれの[MASK]トークンが独立に再構成されるものと仮定しています。
このような独立性は自己回帰モデルと相容れるものではありません。式中の"$\approx$"はそういう意味でBERTが自己回帰モデルのいわゆる劣化的な近似版であることを言っています。
本論文では、この[MASK]トークンを取り払い、自己回帰による学習を行うモデルを構成することに焦点をあてています。
手法
提案手法のメイン
-
Permutations
ForwardかBackwardに限定されていた文脈の方向をとりうるすべての順列に変更。
これより、それぞれの単語の位置は他の全位置の単語における文脈情報を活用すると期待されます。
Permutations(順列並び替え)によるARモデルというアイデアは以前にも試みられていた(Germain 2015, Uria 2017)ものの使用されたモデルが異なり、今回はpositional encodingによりposition-awawe(現在参照している単語が文章中のどの位置にあるか認識できる)であるモデル(XLNet)を用いています。
既存手法と違い、位置に敏感なモデルと順列並び替えを組み合わせることは双方向の文脈理解を目指すアプローチになります。
性能改善のために取り入れた手法
- Segment Recurrence Mechanismと Relative Positional Encoding Scheme (どちらもTransformer XLの実装にあります。ここでは触れませんが、詳しくはこちらの記事が参考になります。)
実装
 例として、長さ4のテキストを考えます。
これまでの単方向モデルでは、Forward(1->2->3->4)かBackward(4->3->2->1)に限られていた文脈の方向を、上図のように3->2->4->1, 2->4->3->1, 1->4->2->3など凡そすべての順列にとります。このとき、文章の並び替えは起きず、あくまでモデルが解釈する文脈方向だけを変更します(このため各学習で**モデルのパラメータを共有**できる)。
例として、長さ4のテキストを考えます。
これまでの単方向モデルでは、Forward(1->2->3->4)かBackward(4->3->2->1)に限られていた文脈の方向を、上図のように3->2->4->1, 2->4->3->1, 1->4->2->3など凡そすべての順列にとります。このとき、文章の並び替えは起きず、あくまでモデルが解釈する文脈方向だけを変更します(このため各学習で**モデルのパラメータを共有**できる)。いま$Z_T$を長さ$T$のindices$[1, 2, ..., T]$のすべての順列、$z_t$, $z_{\
\mathop{\mathrm{max}}_{\theta}\;\;\mathbb{E}{_{\boldsymbol{z\sim{\mathcal{Z}_T}}}}{\biggl[\sum_{t=1}^{T}{\mathrm{log}\,p_{\theta}(x_{z_t}\,|\;\boldsymbol{x}_{\boldsymbol{z}_{<t}})}\biggr]}
となります。例を挙げると、順列$z$として3->2->4->1を選んできたとき、$x_2$の予測には$x_3$を, また$x_4$の予測には$x_2,x_3$を, そして$x_1$に対しては$x_2,x_3,x_4$を用いることになります。
ここで、上式は同時確率分布によって表されているのでARモデルにより最適化可能であることも重要な点です。
さて、順列オーダーによって双方向の文脈からある単語を学習することが可能になりました。加えて、
- 元の文章の単語位置情報を保持すること
(Transfromerにおいては線形関数によるpositional encoding ( ref. stack overflow)により達成される) - 適切なマスク(自身を参照しない制約)を選択すること
以上2点がモデルに求められます。
順列オーダーのTransformer(提案手法)におけるposition-awareな単語推定とMask方法
順列の$t-1$番目までの要素に加え、現在の位置情報 $z_t$ を含めて予測させます。このとき、index = $z_t$の単語自身($=x_{z_t}$)を情報として含んでは行けません(カンニングになる)。
p_{\theta}(X_{z_t}=x\;|\;\boldsymbol{x}_{z_<t})={\frac{\mathrm{exp}(e(x)^\textsf{T}g_{\theta}(\boldsymbol{x}_{\boldsymbol{z_{<t}}},z_t))}{\sum_{x^\prime}{\mathrm{exp}(e(x^\prime)^\textsf{T}g_{\theta}(\boldsymbol{x}_{\boldsymbol{z_{<t}}},z_t))}}}
ところが、ここでちょっとした矛盾が生じます。
この位置$z_t$の予測にはこのように$x_{z_t}$を無視すればよいのですが、後でindex = $z_j$ ($j>t$)の位置にある単語 $x_{z_j}$の予測では、$x_{z_t}$の単語情報を用いる必要があるのです。
この矛盾を解決するため、筆者らは
以下ような2種類のAttention機構を隠れ層にしました。
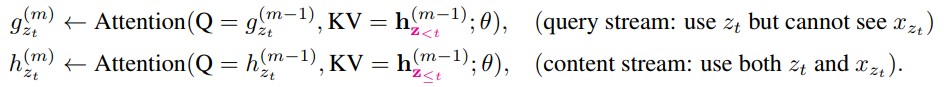
隠れ層$g_{\theta}^{(m)}$は位置 $z_t$を参照できますが単語そのもの( $x_{z_t}$)は参照できません。一方、隠れ層$h_{\theta}^{(m)}$は両方参照できます。論文ではこの$g_{\theta}^{(m)}$,$h_{\theta}^{(m)}$をそれぞれquery stream、context streamと呼んでいます。このような参照方法の違いは下図のようなAttention Masksと呼ばれる2つのマスクを使い分けることによって達成されます。
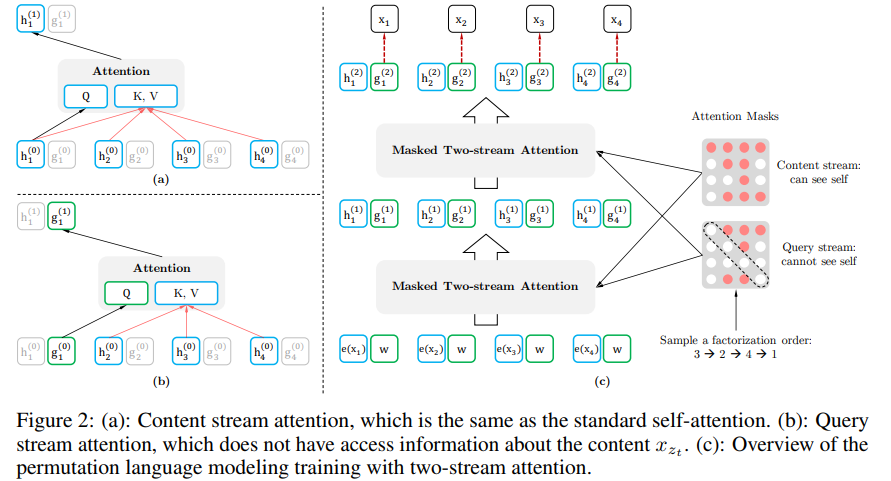
ところで、このcontext streamは標準のself-attentionそのものなので、実装レベルでは、fine-tuningの際にquery streamの方を落として学習し、出力の際にquery streamの最後の隠れ層$g_{\theta}^{(M)}$を使います。
以上がXLNetのおおよそのアルゴリズムの説明になります。
その他
-
Partial Prediction
学習の効率化のため、事前学習では(順列オーダーの)先頭から順に各要素を予測するタスクはやめて最後の数要素だけ予測させるようにしました。$K$を $|z|$のうちどのくらいを予測するかのハイパーパラメータ(e.g. $K = 6, 7$)とし、最後の $|z| / K$要素だけ予測します。 -
Relative Segment Encoding
入力として複数文をとるタスクでは(e.g 各文章:A,B, ラベル:CLS)、BERTと同じように文章を連結させます(e.g. $\rm A + B + CLS = [;A,[SEP],B,[SEP],[CLS];]$( $\rm[SEP]$は区切りを表すトークン) )。この際、Transformer XLで用いられるrelative encodingのアイデアを拡張したRelative Segment Encodingを用いました。(attention weightの計算パラメータ $s$を2つの単語$x_i$, $x_j$が同じセグメント由来かどうかで使い分ける( e.g. $s_+$ (from the same segment), $s_-$ (otherwise) )
以下では、既存モデルと比べてXLNetに具体的にどのように優位性があるのかを例として挙げてみます。
BERTとの比較
文章 = "New York is a city" で"New York"を予測する。つまり $\mathrm{maximize};;\mathrm{log},p(\mathrm{New;York;|;is;a;city})$。
するとBERTとXLNetでは目的が以下のようになります。
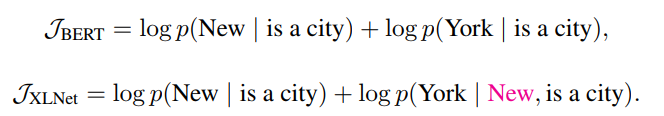
つまり、BERTではMASKされた単語同士の関係は学習できません。一方、XLNetでは$[\mathrm{;is,;a,;city,;New,; York;}]$の順列をサンプリングするため、"York"の推定に"New"の情報が使えます。
既存言語モデルとの比較 (e.g. GPT)
Question answeringで文章が"Thom Yorke is the singer of Radiohead", 質問が"Who is the singer of Radiohead"のとき、既存モデルは文章の"Thom Yorke"を"Radiohead"に結びつけて表現できません(逆はできる)。一方、XLNetは文章中の単語のすべての関係を捉えられます。
結果
NLPデータセットはよく知らないので、実験結果の表だけ載せることにします。
RACEデータセット (文章理解タスク)での性能比較
 #### SQuAD(large scaleの文章理解タスク)での性能比較
#### SQuAD(large scaleの文章理解タスク)での性能比較
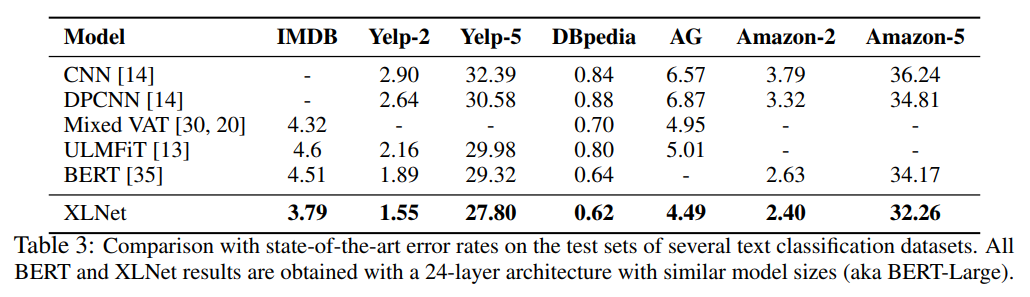
 #### テキスト分類タスクでの性能比較
#### テキスト分類タスクでの性能比較
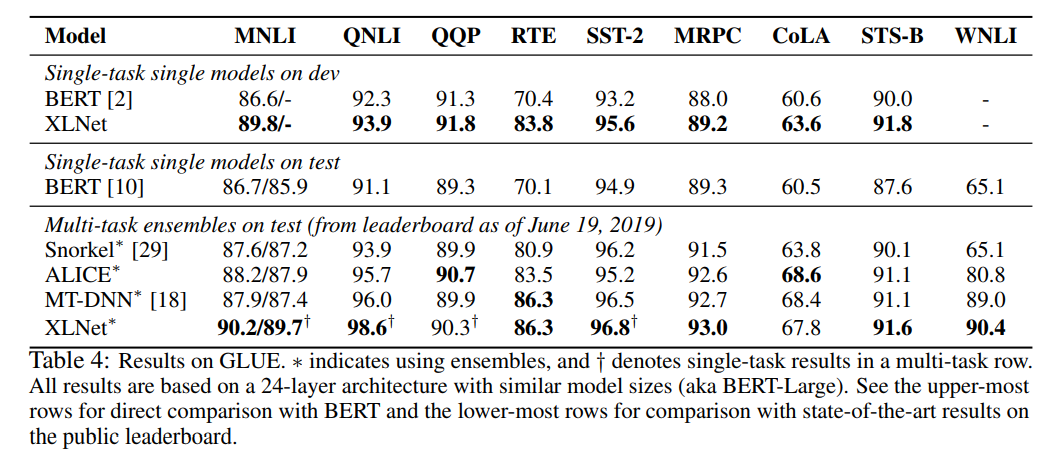
#### GLUE
最後に
今回はBERTのアプローチを拡張し、自己回帰モデルによる学習を可能にしたXLNetについて紹介しました。XLNetの学習には$60,000かかるらしい(ちなみにBERTは約$7,000)ので実装は個人でどうにかできるレベルではないですね。
画像分野に続いてNLPでもSOTAの達成には圧倒的な計算資源が必要とされる時代になった、という気がします。
紹介した論文のリンク
https://arxiv.org/abs/1906.08237 (2019/06/19投稿)
著者/所属機関
Zhilin Yang[1], Zihang Dai[1,2], Yiming Yang[1], Jaime Carbonell[1], Ruslan Salakhutdinov[1], Quoc V. Le[2] / [1] Carnegie Mellon University, [2] Google Brain