概要
ML-Agentのサンプルモデルの学習方法と動かし方についてまとめた記事です。大まかな流れだけのメモだと思ってください。Anacondaやpipなど使用します。これらの設定方法は各自行ってください。細かい環境などは前回の記事を参考にしてください。
環境
- macOS Catalina 10.15.5
- Anaconda 4.8.3
- python 3.8.3
- pip 20.1.1
3DBallモデル
今回はML-Agentsのサンプル内にある3DBallというモデルを使用し、学習方法などを説明していきます。3DBallはボックスの上に乗っているボールを落とさないようにするモデルのことです。
前回の記事の続きです。
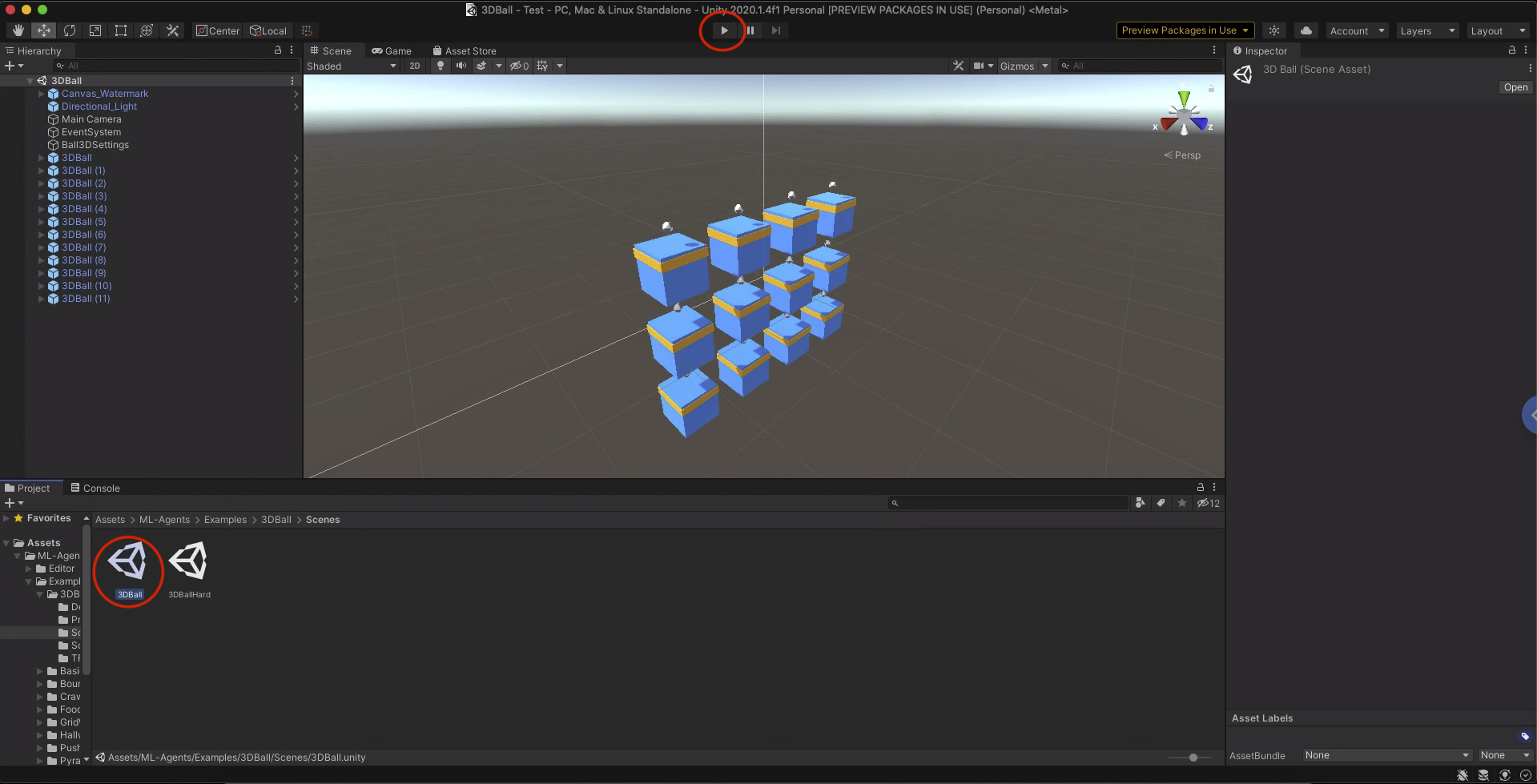
左下の Assets/ML-Agents/Examples/3DBall/Scenes を開き、赤い印をつけたモデルをダブルクリックします。下の画像のようになると思います。
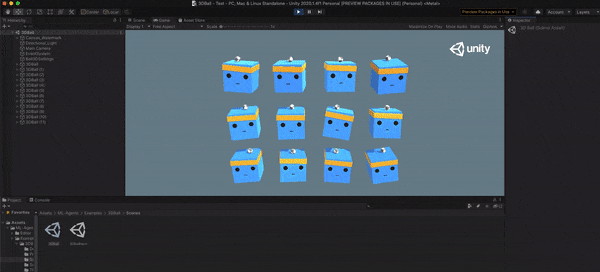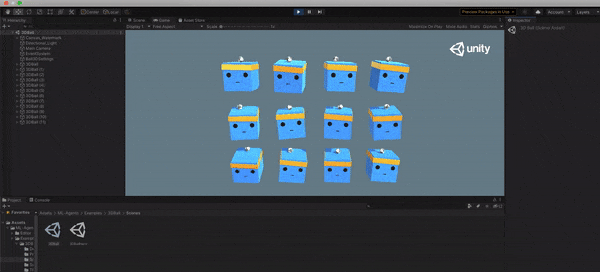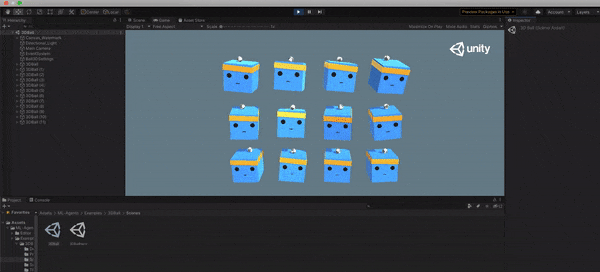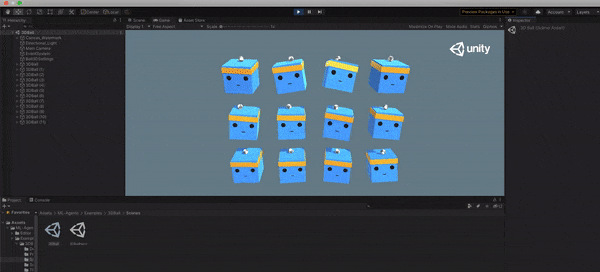
赤く印つけた再生ボタンを押すと下の画像のようになります。サンプルのモデルはすでに学習済みなので、ボールを落とさないように動いていることが確認できます。
次からモデルの学習方法について説明していきます。
学習する環境を整える
まずはじめにモデルを学習させるAnacondaの仮想環境を作成します。
ML-Agentsではpython 3.6.1 以降が必要です。今回はpython 3.8.3 を使用します。
$ conda create -n mlagents python=3.8.3 anaconda
$ conda activate mlagents
次にpythonパッケージの ml-agents、 ml-agents-env をインストールします。
前回ダウンロードした ml-agents-release_6 に移動して以下のコマンドを実行します。
cd ml-agents-envs
pip3 install -e ./
cd ..
cd ml-agents
pip3 install -e ./
cd ..
これでモデルを学習させる環境が整いました。
モデルを学習させる
次に3DBallを学習させていきます。
やることは以下の3つです。
- ハイパーパラメータを設定する。
- Anacondaの仮想環境でプログラムを実行する。
- unityのモデルを実行する。
ハイパーパラメータを設定する
ml-agents-release_6/config で学習アルゴリズムやパラメータを設定します。
ppo、sacというフォルダがあります。それぞれ強化学習のアルゴリズムになります。
- PPO : Proximal Policy Optimization
- SAC : Soft Actor-Critic
とりあえずppoを使用します。このファイル内にppoのパラメータを設定するYAMLファイルがあります。YAMLファイルを作成することでハイパーパラメータを自由に設定することができます。3DBallのパラメータはすでに3DBall.yamlに設定されているのでそのまま使用します。
Anacondaの仮想環境でプログラムを実行する
学習させるpythonスクリプトを実行します。さっき作成した仮想環境で ml-agents-release_6/ml-agents に移動し以下のコマンドを実行してください。
mlagents-learn ../config/ppo/3DBall.yaml --run-id=3DBall --train
--run-id はなんでもいいです。実行すると次の画像のようにunityのロゴが出てきます。
unityのモデルを実行する
次にunity上でモデルを実行します。実行ボタンを押すだけでいいです。学習が進むと以下の画像のようになります。
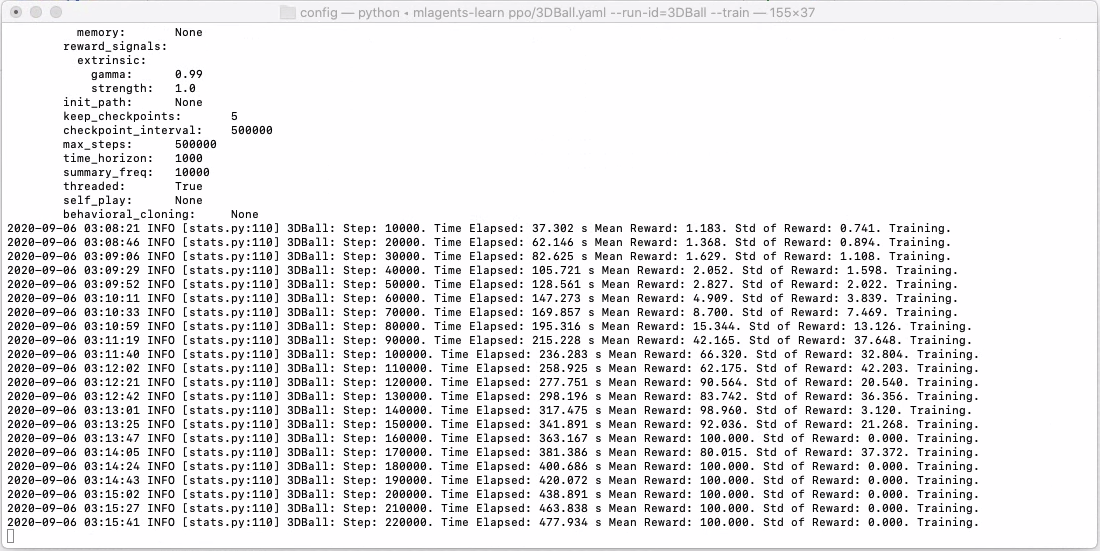
「Mean Reward」は平均報酬です。3DBallは最大値が100になっています。16万ステップあたりから最大になっていることがわかります。「Std of ReWard」は報酬の標準偏差です。小さくなるほど良いです。20万ステップあたりで学習仕切れていることがわかります。
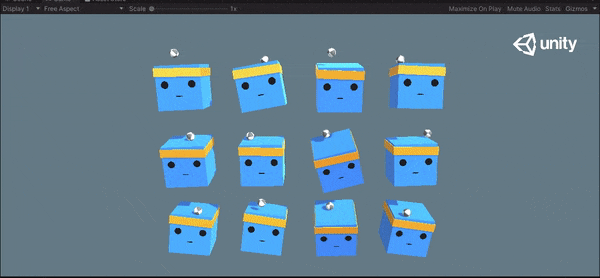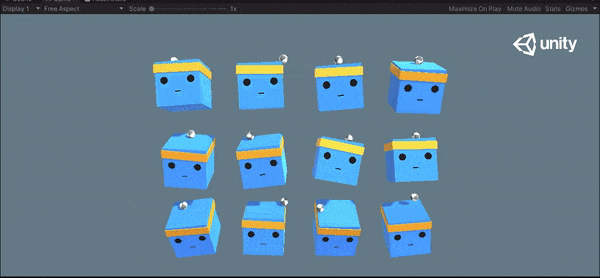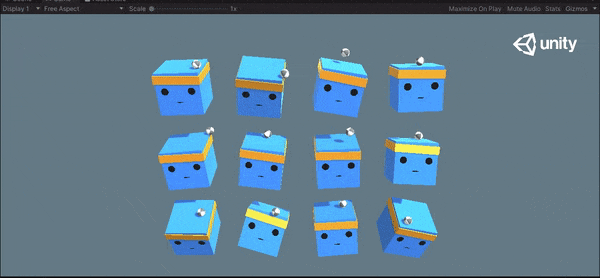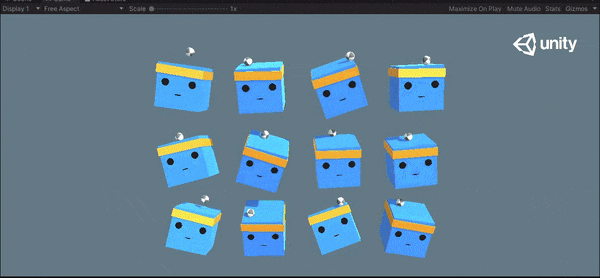
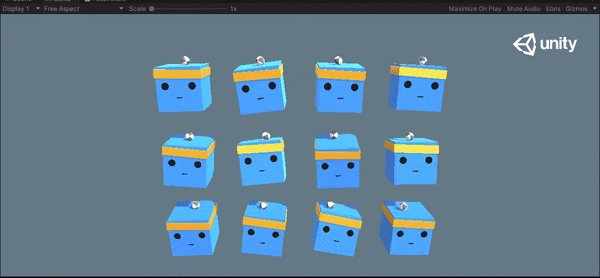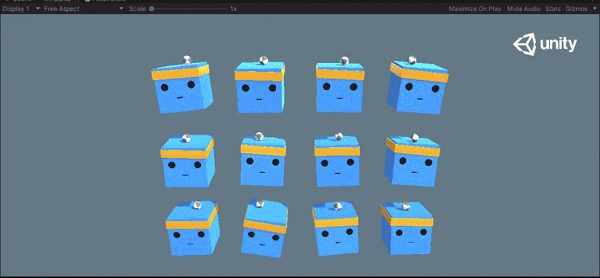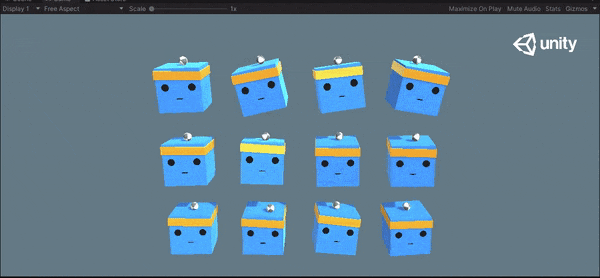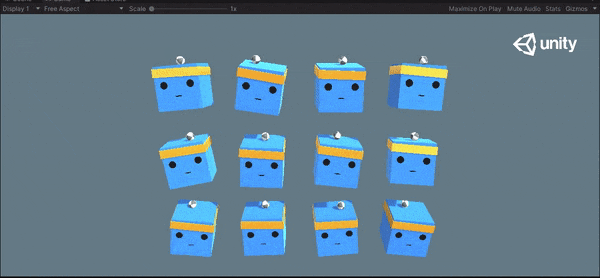
1万ステップと15万ステップの挙動を以下に示します。ボールを落とさないように学習できていることがわかります。
1万ステップ
15万ステップ
学習後のモデル
学習したモデルは ml-agents/results にさっき指定した --run-id の名前のフォルダができています。そのフォルダの中の 3DBall.nn が学習済みのモデルになります。新しく学習したモデルを使用する場合はunityの Assets/ML-Agents/Example/3DBall/TFModels に 3DBall.nn を追加し、Agent の Behavior Parameters の Model で 3DBall.nn を選択してください。
まとめ
ML-Agentsのサンプルモデルの動かし方について記事を書きました。ML-Agentsでの学習方法は基本的にこの流れになります。間違っていることがあるかもしれないので参考程度にしてください。また公式にドキュメントがあります。
次回はカートポールのモデルを作成し、学習させる記事を書きたいと思います。