はじめに
- 本記事では、特定領域のキャプチャを取得する方法を紹介します。
- 記事の内容は、個人の見解または確認結果であり、UiPath の公式見解ではありません。
- 画像データのデジタル化にはDU(Document Understanding)の機能をもちいています。インストールしたパッケージ:UiPath.IntelligentOCR.Activities: 6.19.3
- 製品仕様や参考画像は 24.10 バージョンのもので構成しています。
実装サンプル
本日は、次の様な単純なひらがな9文字の画像データをもちいて説明します。

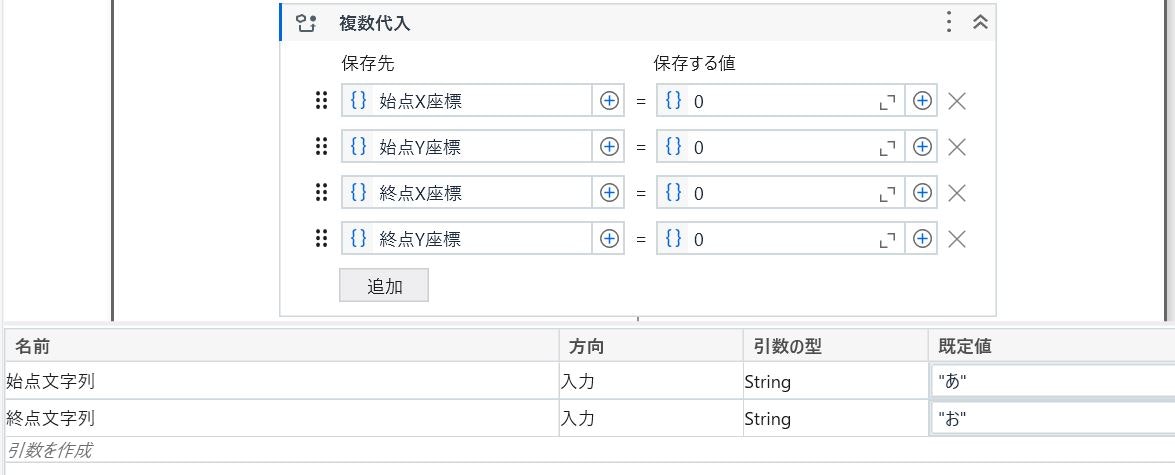
まず、座標を求めるための変数と引数の登録および変数の初期化をおこないます。
次にサンプル画像データをデジタル化します。
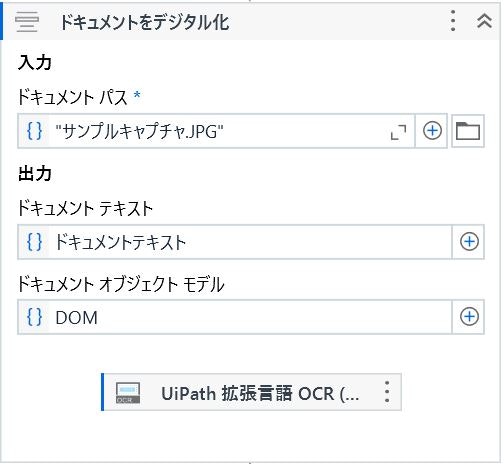
任意の領域をキャプチャするには、キャプチャしたい領域の座標情報が必要な訳ですが、
上の図の出力にある『ドキュメント オブジェクト モデル(通称:DOM)』がOCRで読み取った文字の座標情報を持っています。
このDOMは比較的複雑な構造のオブジェクトのため、次の様にして文字と座標情報を取得します。
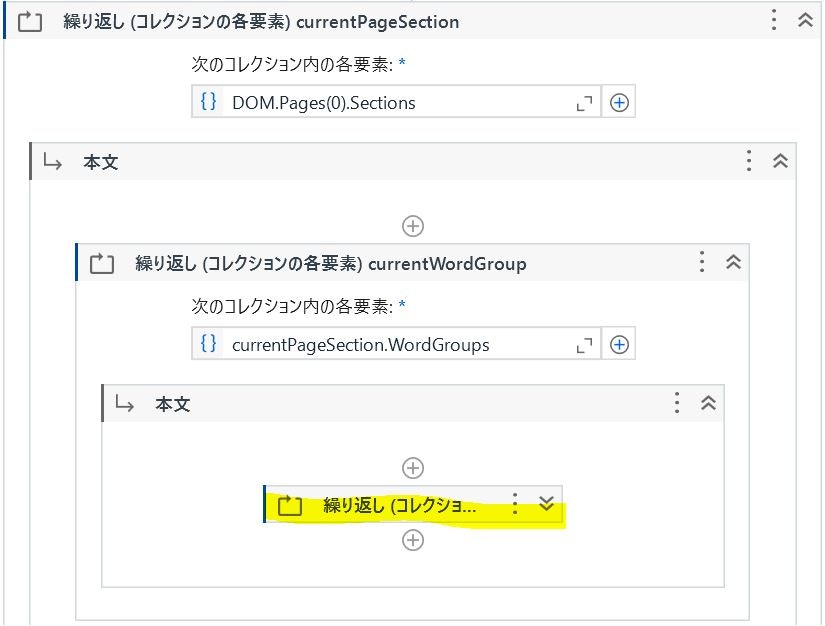
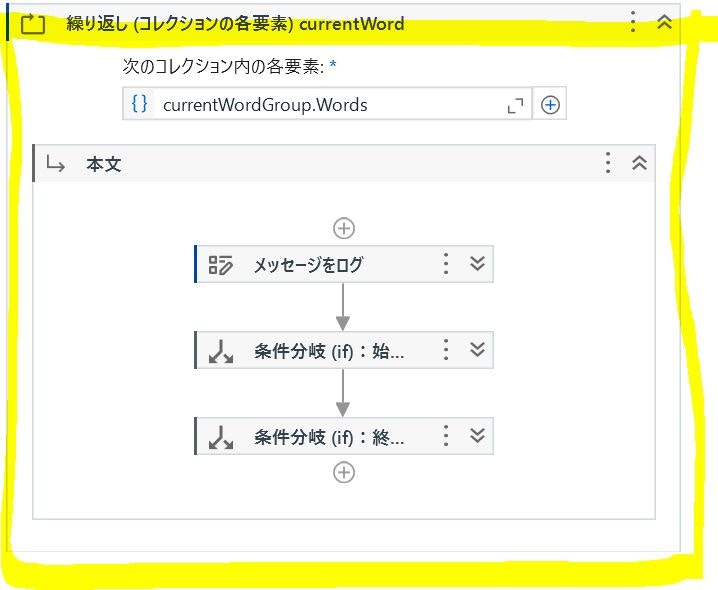
DOM.Pages(0).Sections の繰り返し
→ currentPageSection.WordGroups の繰り返し
→ currentWordGroup.Words の繰り返し
# 参考:WordGroups の中身
WordGroups=WordGroup[9]
{
WordGroup
{
IndexInText=0,
Length=1,
Type=TableCell,
Words=Word[1]
{
Word
{
Box=T:50,L:70,W:48,H:78,
IndexInText=0,
OcrConfidence=0.98999995,
Polygon=(70.00,
51.00),
(117.00,
50.00),
(118.00,
127.00),
(72.00,
128.00),
Text="あ",
TextType=Unknown,
VisualLineNumber=0
}
}
},
WordGroup
{
IndexInText=4,
Length=1,
Type=TableCell,
Words=Word[1]
{
Word
{
Box=T:57,L:294,W:44,H:69,
IndexInText=4,
OcrConfidence=0.98999995,
Polygon=(294.00,
63.00),
(325.00,
57.00),
(338.00,
122.00),
(306.00,
126.00),
Text="い",
TextType=Unknown,
VisualLineNumber=0
}
}
},
・・・省略
(始点情報の取得、設定)
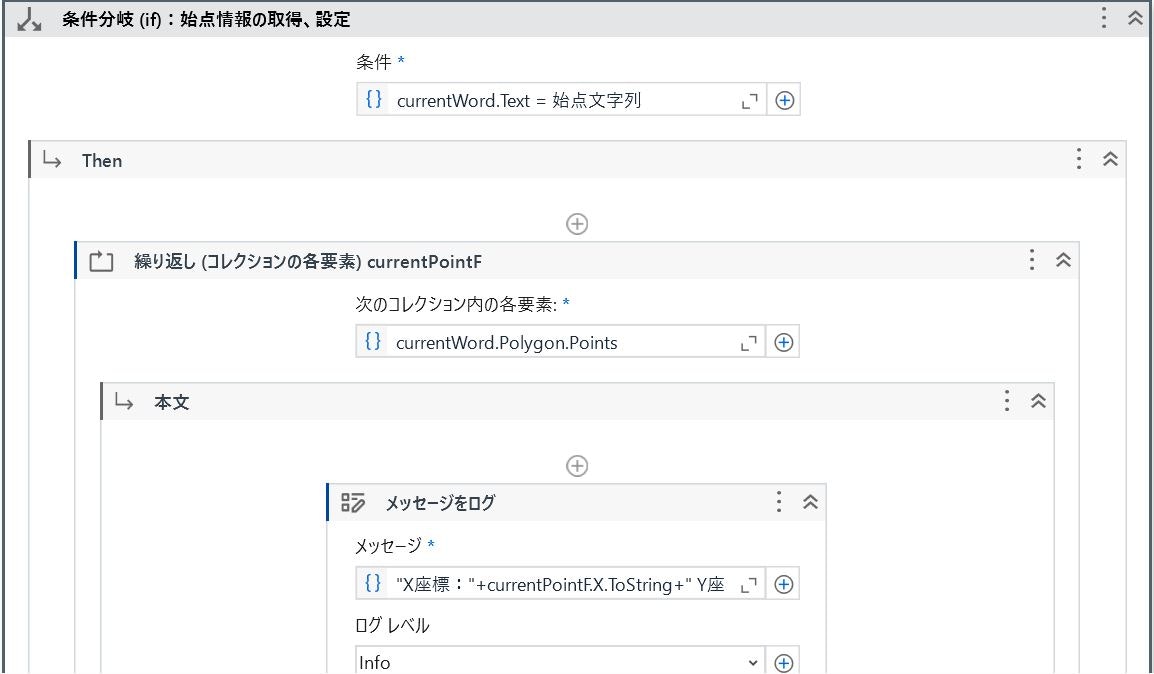
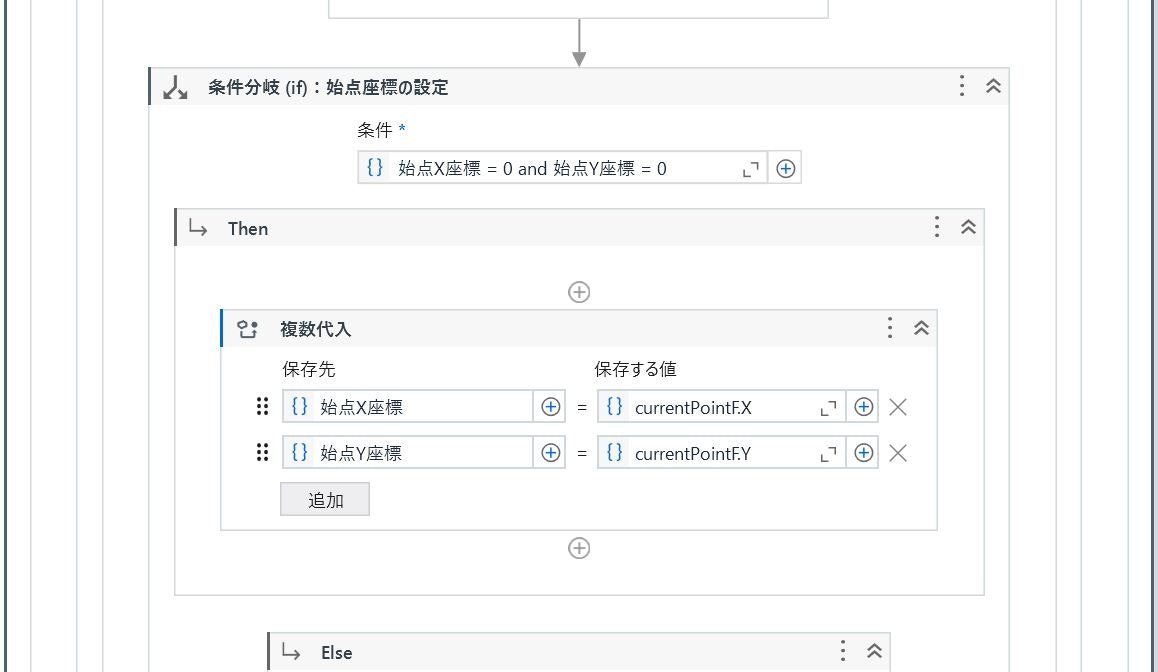
Polygon の最初のデータが領域の左上の座標なので、座標データ未取得(始点X座標 = 0 and 始点Y座標 = 0)の際に「.X」「.Y」プロパティで値を設定します。
(終点情報の取得、設定)
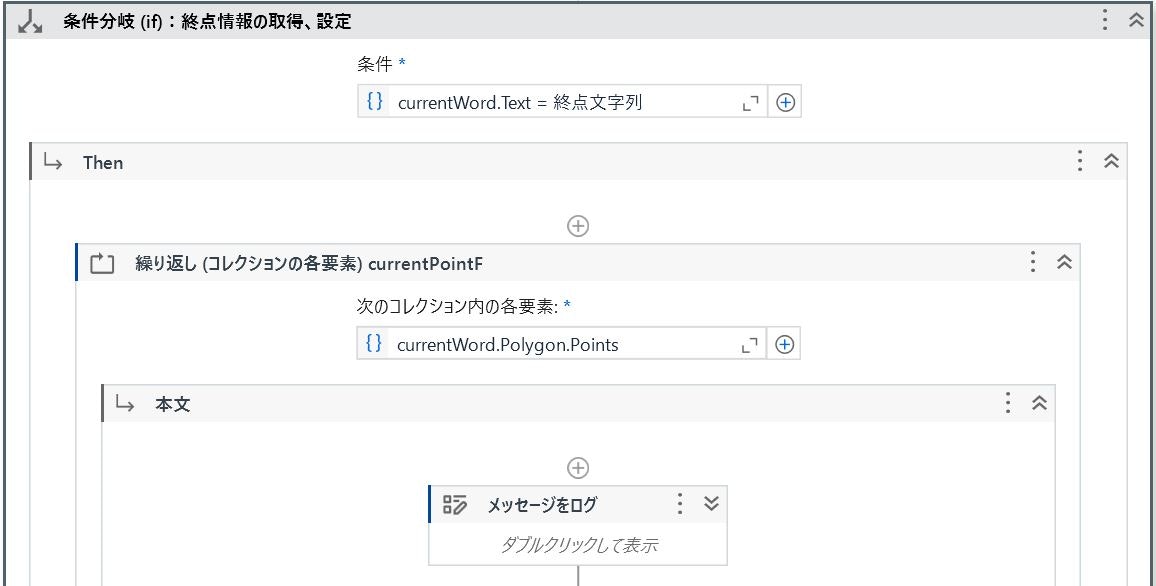
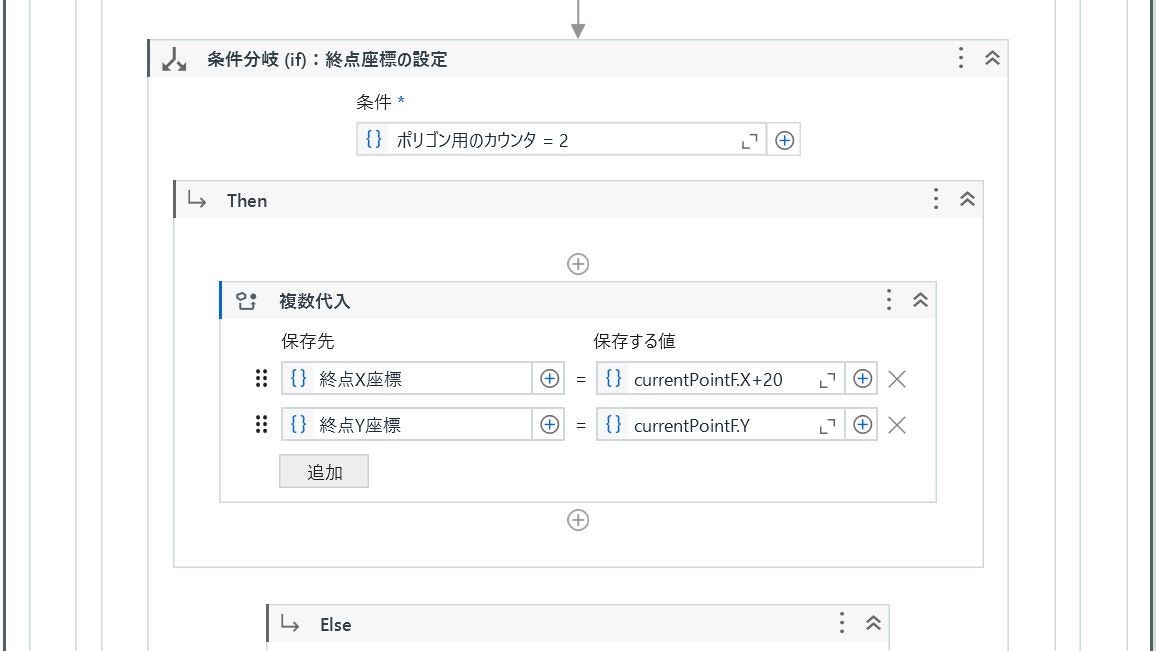
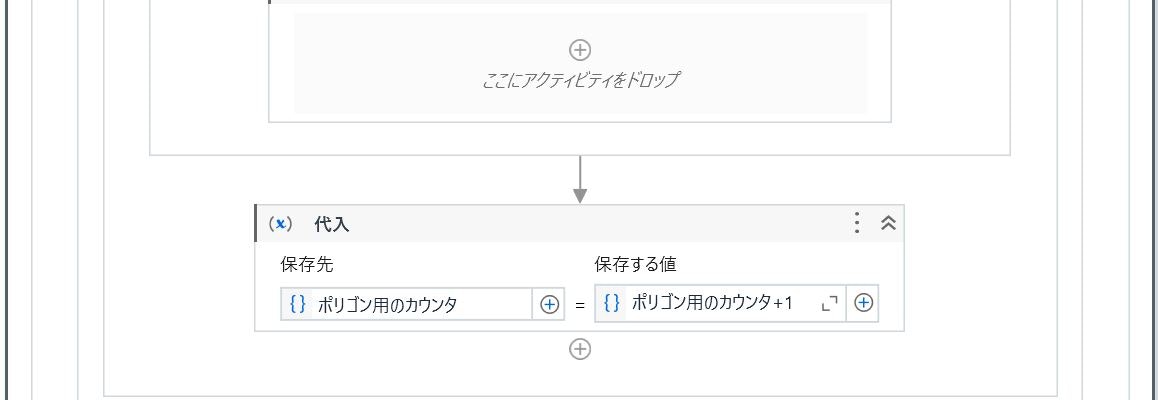
Polygon の3番目のデータが領域の右下の座標なので、カウンタを用意し3番目のデータ(カウンタは0からはじまるため値が「2」)の際に「.X」「.Y」プロパティで値を設定します。
座標情報を設定する際、気持ちピクセルを足しておきます。(上図の例ではX座標に20ピクセル足しています)
これはOCRの文字認識範囲が見た目より内側になるためです。
最後に画像データのトリミングと保存↓↓
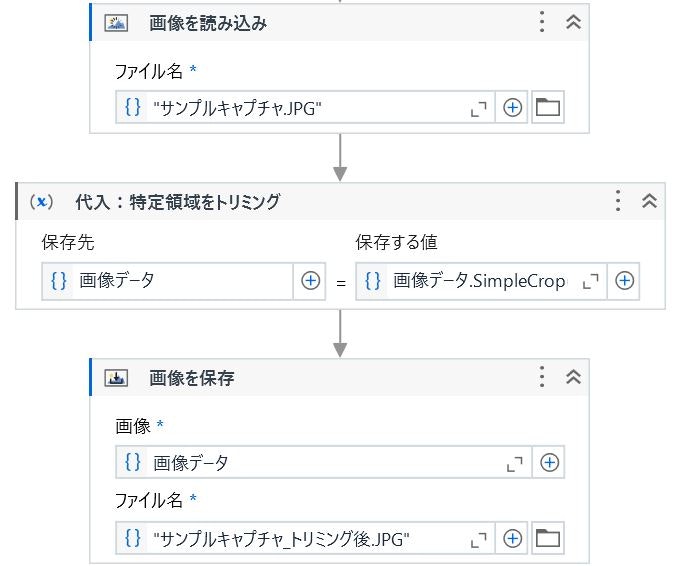
(例)代入の右辺
画像データ.SimpleCrop(New UiPath.Core.Region(New RectAngle(Cint(始点X座標),CInt(始点Y座標),CInt(終点X座標-始点X座標),CInt(終点Y座標-始点Y座標))))
※本サンプルは終点が始点より右下になる例のみしか考慮していません。
※始点と終点の値が反転するケースは、値比較の条件分岐の追加実装が必要です。
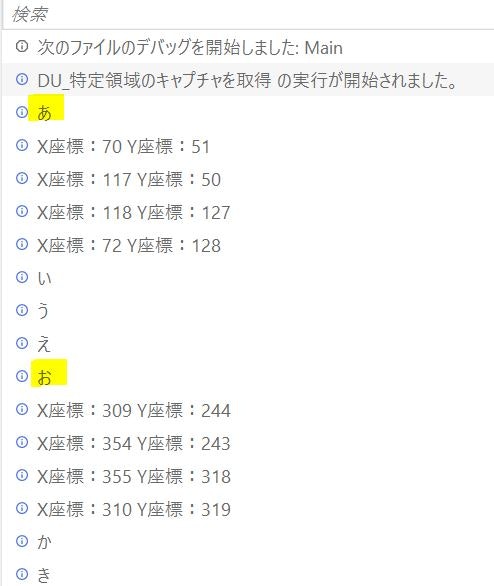
処理結果のサンプル
始点文字列:あ
終点文字列:お
(出力ログ)
(トリミング後の画像)

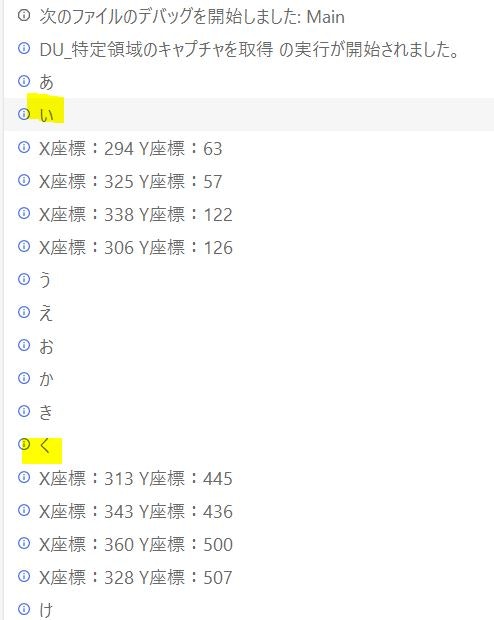
始点文字列:い
終点文字列:く
(出力ログ)
(トリミング後の画像)

さいごに
いかがでしたでしょうか。
今回は文字画像でサンプル説明しましたが、特定文字列をアンカーにイラストや表データなどを切り取ることも簡単にできそうですね☀
最後までお読みいただきありがとうございます(・ω・)ノ