農業ITスタートアップのQuantomicsでインターンをしている鈴木海友です.
一時期,話題となったEnd-to-EndなObject DetectionであるDETRのソースコードを実行したので,概要と実行手順について解説します.
概要

皆さんはDETRをご存じだろうか? "End-to-End Object Detection with Transformers(DETR)"はObject Detectionの分野において颯爽と登場した,Facebookにより開発されたモデルである.何と言っても特徴的なのは,CNNに加えてTransformerをアーキテクチャに取り入れており,そのおかげでNMSのような既存のObject Detection特有の複雑なテクニックが不要になった点である.これ以上の詳しいアルゴリズムの説明は,既に解説記事があるため,そちらに譲らせていただく.
もっとも,最近は"MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers"というGoogleによる論文が公開されており,Segmentationベースの手法でありながら精度やアルゴリズムのシンプルさなどでは抜かれている.こちらもTransformerをベースとした手法であり,Deep Learaning界隈の発展の速さがうかがえる.そのうち解説記事が出せればと……
さて,今回は公式で公開されているgithub上のソースコードを元に,自前のGPU資源を使わずに再現を試みた.それなりに知見を得られたので,その記録を残す.
環境構築
今回は全ての実行動作をGoogle Colab上で行うため,PC上の環境構築は不要である.Googleアカウントは要求されるので,それだけ作ればよい.またデフォルトで用意されている画像ではなく,自前の画像で試したい場合はGoogle Driveが必要になってくるので,そちらも用意すること.
実行例
もっともシンプルな実行例,すなわちデフォルトで用意された画像についてのObject Detectionを行い,判定結果を表示するところまでを説明する.
実行手順
今回は以下のような手順で実行した.
- Github上のソースコードにアクセスする.
- 説明文中のstandalone Colab NotebookからGoogle Colabにアクセスする.
- Google Colabにログインする.
- "CTRL+F9"もしくは「ランタイム→全てのセルを実行」を選択する.
- Object Detectionが実行される!
超簡単!
Google Colab上のセルの説明
ちょっとだけセルについて説明させていただく.Google Colab上のセルは読み込んだ訓練済モデルを使ってデフォルトの画像についての判別を行い,その結果を画像で表示するところまでやってくれている.
DETRdemoの定義されているセルを見ればざっくりとモデルの構成がわかるので,気になるのならば見てみるといい.また最後から2番目のセルで対象となる画像の読み込みと判定を実行しているので,他の画像を試したい場合はここを書き換えていくことになる.
実行結果
デフォルトの画像で試したところ,次のような推定結果が得られた.

推定したObjectを取り囲むようなBounding Boxと,それが所属するクラスと確率がセットで表示されている.
隠れている部分のない猫や左側のリモコンなどは非常に高精度にBounding Boxを推定できている.右側のリモコンは3割以上が猫で隠れているからか,Bounding Boxが少しずれていて確率も少し低いが,それでも大きな誤差はない.さらに背景と化しているソファーについても,いまいち人間にもわかりずらいにも関わらず,しっかりと推定ができている.確率についても,人間の直感と照らし合わせても妥当のように感じる.
実行速度
せっかくなので実行速度も測ることにした.Google Colab上の最後から2番目のセルで判定を実行をしているようだ.
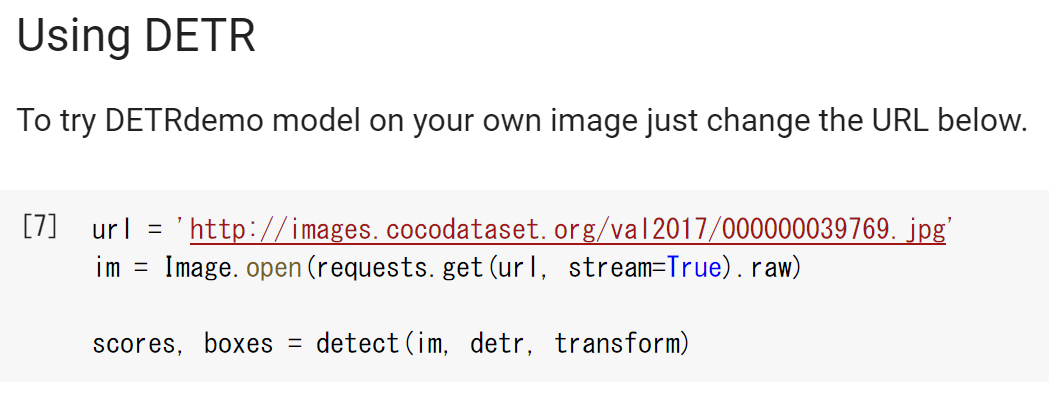
このセルを次のように書き換える.
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
im = Image.open(requests.get(url, stream=True).raw)
import time
import numpy as np
elapsed_times = []
for i in range(10):
start = time.time()
scores, boxes = detect(im, detr, transform)
elapsed_times.append(time.time()-start)
print("mean:{:.3f}, std:{:.3f}".format(np.mean(elapsed_times), np.std(elapsed_times)))
これで10回実行した平均速度および標準偏差を求めることができる.GPUを使用しないデフォルト設定だと,$3.210\pm0.022[sec]$であった.1枚を試す分には十分な時間であるが,リアルタイムで実行するには厳しい時間だ.
ちなみにGPUへの対応はデフォルトではしてないため,さらにセルの中身を書き換える必要がある.GPUで実行するためには,まず「編集→ノートブックの設定」よりハードウェアアクセラレータをNoneからGPUに変更する.次に,最後から3番目のセルにある,detect関数を次のように書き換える.
def detect(im, model, transform):
# mean-std normalize the input image (batch-size: 1)
img = transform(im).unsqueeze(0)
# demo model only support by default images with aspect ratio between 0.5 and 2
# if you want to use images with an aspect ratio outside this range
# rescale your image so that the maximum size is at most 1333 for best results
assert img.shape[-2] <= 1600 and img.shape[-1] <= 1600, 'demo model only supports images up to 1600 pixels on each side'
# propagate through the model
outputs = model.cuda()(img.cuda())
# keep only predictions with 0.7+ confidence
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1]
keep = probas.max(-1).values > 0.7
# convert boxes from [0; 1] to image scales
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep].cpu(), im.size)
return probas[keep], bboxes_scaled
最後に,これ以後のセルを順番に実行していけば,(非常に雑なやり方ではあるが)モデル実行部分をGPUで動かすことができる.また新しいセルを挿入して,次のコマンドでGPUの種類を確かめることができる.
!nvidia-smi
すると例えば次のようにGPUの種類が表示される.
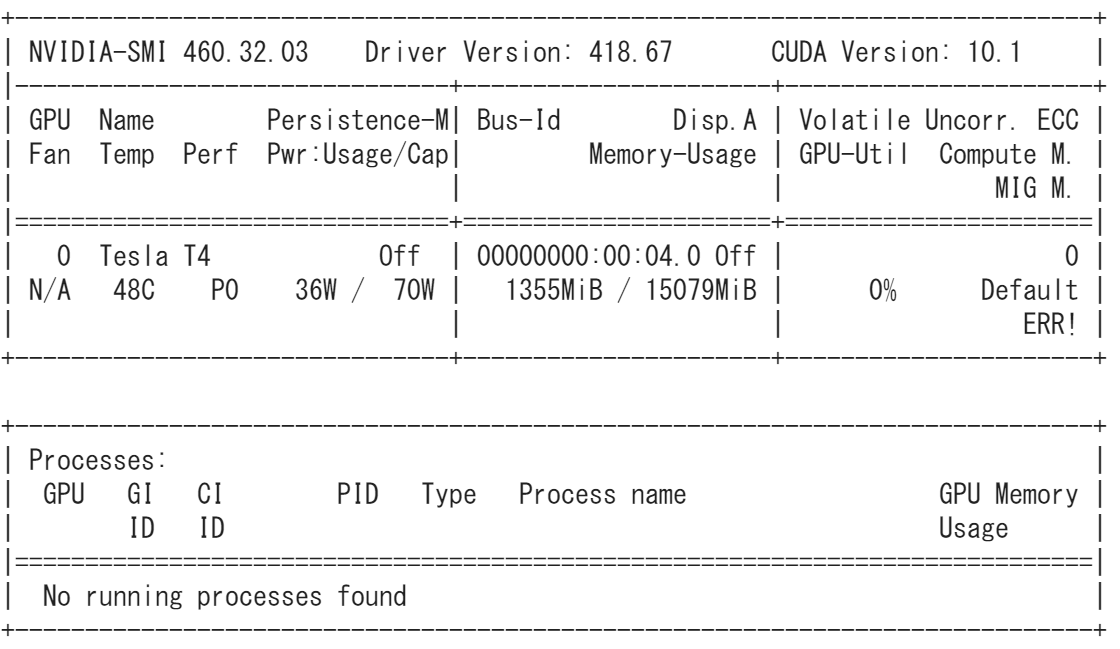
今回はTesla T4で実行したことがわかる.
肝心の実行速度であるが,上記のGPUで$0.102\pm0.015[sec]$となった.これなら10fps程度ならリアルタイムでの実行が可能である.公式によればTesla V100を使えば28fpsは出るとあるので,真面目に最適化すればもっと速くなるかもしれない.
自前の画像での実行例
以上で公式から用意された画像での実行ができた.それでは自前の画像で実行するためにはどのようにすればいいのだろうか.
実行手順
今回はGoogle Driveをマウントして実行した例を示す.まずGoogle Driveの直下にターゲットとなるファイル(今回はhogehoge.jpg)を置く.次に先ほどと同じく,最後から2番目のセルを次のように書き換えて実行する.
from google.colab import drive
drive.mount('/content/drive')
file_name = 'hogehoge.jpg'
im = Image.open('/content/drive/My Drive/{}'.format(file_name))
scores, boxes = detect(im, detr, transf
orm)
最初の実行時,"Go to this URL in a browser:<GoogleへのログインURL>"および"Enter your authorization code:"とコードを要求される.リンク先に飛ぶと,Googleアカウントへのログインを要求される.ログインするとパスコードが出てくるためコピーして,Google Colabに戻ってコードを入力すれば,Google Driveのマウントが完了する.
後は最後のセルを実行すれば,自前の画像を判定した結果を見ることができる.
実行例

訓練データにもテストデータにもない画像で試してみた.真ん中にボートが映っているが,これは波で少し隠れているにも関わらず正確にとらえている.気になるのは左側にある桟橋を"ボートである"と判断していることだ.確かに海に浮かんでいてる物体であるが,これをボートと間違える人間はいないだろう.試しに海を灰色に塗りつぶしてみた.

手前のボートについてはほぼ変わらない結果が出た.(塗り残しがあるからかもしれないが)一方で奥の桟橋についてボートと判断した信頼度が0.92から0.74へと下がった.このことから,このDETRがかなり文脈に依存することは確かなようだ.一方で海しか見ていないわけではなく,桟橋の形やテクスチャも誤った原因としてあげられそうだ.
感想
何より驚いたのは,実行するまでの手間が極端に少ない事だ.使用感を確かめるだけなら1時間もあれば十分かもしれない.(全ての実装がこれだと楽なのに……)
実際,いくつかの画像で試してみたがかなり正確に判断できているようだ.実行速度も(適当な最適化の割には)申し分なく,カタログスペックと同じだけ出せればリアルタイムでの実行も可能だろう.
一方で,桟橋をボートと判定したことは気になるところである.DETRで取り入れられているTransformerのメリットとして,一部分だけではなく全体と照らし合わせて判断できることがあげられる.しかし文脈に依存した判断をすることで"海に浮かんでいるからボート"と誤ってしまうのかもしれない.もしそうであれば,訓練データやテストデータに含まれるバイアスが考慮できていないと,Transformerは諸刃の剣になる.
まとめ
DETRの公式実装をGoogle Colab上で簡単に実行する方法を紹介させていただきました! さすがに高い精度ですが,まだまだ改善の余地はありそうですね.
元は自然言語で発展してきたTransformerがこうして画像系の分野に進出してきたのは,時代の流れを感じます.既に一切CNNを使わない画像分類モデルや,さらに新しいTransformerベースのObject Detectionモデルも登場していることもあり,目が離せません.
今後とも気になった手法や実装をご紹介していければと思います.
We’re hiring!
Quantomicsでは農業×ITの分野で一緒にデータ解析や技術開発をしてくださるサイエンティスト・エンジニアを募集しています.詳しくは弊社ウェブサイトをご覧ください.