はじめに
コールセンターを新規に構築する際、Amazon Connectを使ってみようというニーズはあると思います。
しかし通話内容のテキスト化や、テキスト化した内容の利用方法については、まだよく分からない部分も多いのではないでしょうか。
例えば、COTOHAを使ったサービスとしては@azuki2iceさんの以下の記事があります。
Amazon Connectの通話をCOTOHAで音声認識させて通話テキストをSalesforceに自動登録する
Amazon Connectは他サービスでも使えるので、今回はWatsonを連携し、通話内容を文字起こしして、その内容をメールで飛ばすサービスを作ってみたいと思います。
本記事の内容を実装することで、以下の図のようなサービスが実現できます。
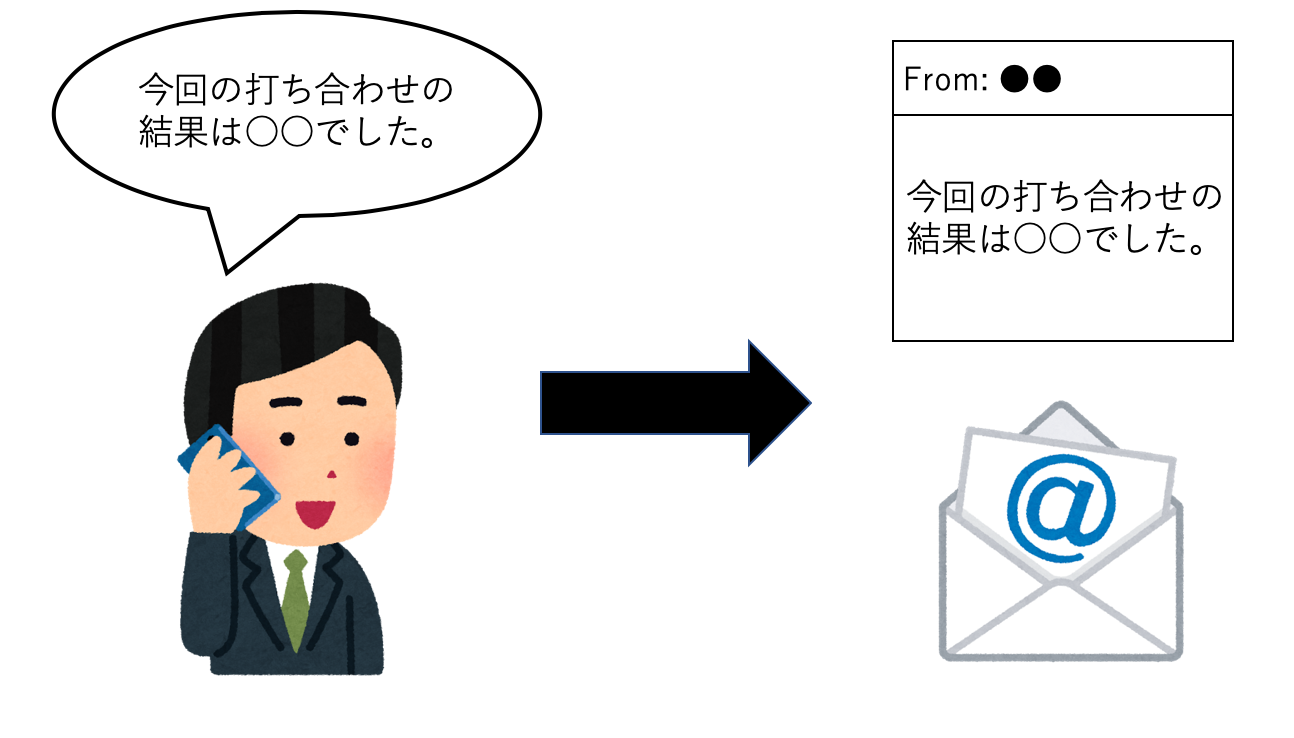
なおこのサービスは構築にあたり、@Masaakiさんにご協力いただきました。ありがとうございます。
構成
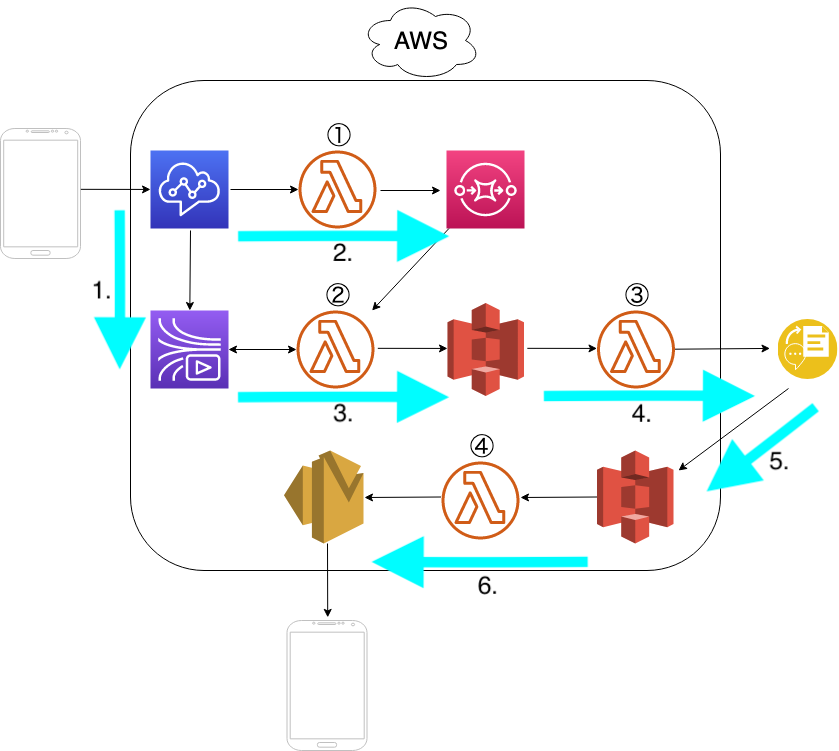
- Amazon ConnectからKinesis Video Streams(KVS)にデータを保存
- Lambda①によりAmazon ConnectからSQSにキューを保存
- SQS経由で起動されたLambda②がKVSに保存されたデータをwavに変換、S3に保存
- S3への保存をトリガーにLambda③がWatson Speech To Textを起動
- 変換されたテキストファイルをS3に保存
- S3に保存されたテキストをLambda④を用い、Amazon SES(Simple Email Service)でユーザにメール配信
Amazon Connectの設定
問い合わせフローは以下のように設定します。

- 「メディアストリーミングの開始」ブロックから「メディアストリーミングの停止」ブロックまでの通録が保存されます。
- 問い合わせフロー上で設定する必要があるLambdaは①のみです。
- 特に説明のない「プロンプトの再生」ブロックは、フローを切り分けられるよう任意のメッセージを流すよう設定しました。
- 「テキスト化」と書いてある「プロンプトの再生」は、次のように設定しています。
- 「テキスト読み上げ機能(アドホック)」を選択
- 「テキストの入力」を選択
- 「解釈する」はSSMLを選択し、テキストメッセージには以下のように記述
<speak>
<break time="10s"/>
メッセージをお預かりしました。
</speak>
Lambdaの設定
- Lambda①、②はNode.js 10.x、③、④はPython3.7で設定しています。
Lambda①
- 関数のロールにSQSを追加します。
index.js
const AWS = require("aws-sdk");
const account = process.env.account;
const name = process.env.queueName;
const region = process.env.region;
const url = 'https://sqs.'+ region +'.amazonaws.com/' + account + '/' + name;
exports.handler = async (event) => {
console.log(JSON.stringify(event));
const sqs = new AWS.SQS();
const params = {
MessageBody: JSON.stringify(event),
QueueUrl: url,
};
result = await sqs.sendMessage(params).promise();
console.log(result);
}
Lambda②
- 関数のトリガーにSQS、ロールにSQS、KVS、S3を設定します。
index.js
const AWS = require("aws-sdk");
const bucketName = process.env.bucketName;
const region = process.env.region;
const ConnectVoiceMail = require("./ConnectVoiceMail");
exports.handler = async (event) => {
console.log(JSON.stringify(event));
for(var i=0; i<event.Records.length; i++) {
const body = JSON.parse(event.Records[i].body);
const audio = body.Details.ContactData.MediaStreams.Customer.Audio;
const streamName = audio.StreamARN.split('stream/')[1].split('/')[0];
const fragmentNumber = audio.StartFragmentNumber;
const startTime = new Date(Number(audio.StartTimestamp));
console.log('streamName:' + streamName);
console.log('fragmentNumber:' + fragmentNumber);
const connectVoiceMail = new ConnectVoiceMail();
const wav = await connectVoiceMail.getWav(region, streamName, fragmentNumber);
const s3 = new AWS.S3({region:region});
const key = dateString(startTime) + '.wav';
console.log('wavFile: ' + key);
const params = {
Bucket: bucketName,
Key: key,
Body: Buffer.from(wav.buffer),
};
await s3.putObject(params).promise();
}
}
function dateString(date) {
const year = date.getFullYear();
const mon = (date.getMonth() + 1);
const day = date.getDate();
const hour = date.getHours();
const min = date.getMinutes();
const space = (n) => {
return ('0' + (n)).slice(-2)
}
let result = year + '-';
result += space(mon) + '-';
result += space(day) + '_';
result += space(hour) + ':';
result += space(min);
return result;
}
ConnectVoiceMail.js
const ebml = require('ebml');
const AWS = require("aws-sdk");
module.exports = class ConnectVoiceMail {
async getWav(region, streamName, fragmentNumber) {
const raw = await this._getMedia(region, streamName, fragmentNumber);
const wav = this._createWav(raw, 8000);
return wav;
}
async _getMedia(region, streamName, fragmentNumber) {
// Endpointの取得
const kinesisvideo = new AWS.KinesisVideo({region: region});
var params = {
APIName: "GET_MEDIA",
StreamName: streamName
};
const end = await kinesisvideo.getDataEndpoint(params).promise();
// RAWデータの取得
const kinesisvideomedia = new AWS.KinesisVideoMedia({endpoint: end.DataEndpoint, region:region});
var params = {
StartSelector: {
StartSelectorType: "FRAGMENT_NUMBER",
AfterFragmentNumber:fragmentNumber,
},
StreamName: streamName
};
const data = await kinesisvideomedia.getMedia(params).promise();
const decoder = new ebml.Decoder();
let chunks = [];
decoder.on('data', chunk => {
if(chunk[1].name == 'SimpleBlock'){
chunks.push(chunk[1].data);
}
});
decoder.write(data["Payload"]);
// chunksの結合
const margin = 4; // 各chunkの先頭4バイトを破棄する
var sumLength = 0;
chunks.forEach( chunk => {
sumLength += chunk.byteLength - margin;
})
var sample = new Uint8Array(sumLength);
var pos = 0;
chunks.forEach(chunk => {
let tmp = new Uint8Array(chunk.byteLength - margin);
for(var e = 0; e < chunk.byteLength - margin; e++){
tmp[e] = chunk[e + margin];
}
sample.set(tmp, pos);
pos += chunk.byteLength - margin;
})
return sample.buffer;
}
// WAVファイルの生成
_createWav(samples, sampleRate) {
const len = samples.byteLength;
const view = new DataView(new ArrayBuffer(44 + len));
this._writeString(view, 0, 'RIFF');
view.setUint32(4, 32 + len, true);
this._writeString(view, 8, 'WAVE');
this._writeString(view, 12, 'fmt ');
view.setUint32(16, 16, true);
view.setUint16(20, 1, true); // リニアPCM
view.setUint16(22, 1, true); // モノラル
view.setUint32(24, sampleRate, true);
view.setUint32(28, sampleRate * 2, true);
view.setUint16(32, 2, true);
view.setUint16(34, 16, true);
this._writeString(view, 36, 'data');
view.setUint32(40, len, true);
let offset = 44;
const srcView = new DataView(samples);
for (var i = 0; i < len; i+=4, offset+=4) {
view.setInt32(offset, srcView.getUint32(i));
}
return view;
}
_writeString(view, offset, string) {
for (var i = 0; i < string.length; i++) {
view.setUint8(offset + i, string.charCodeAt(i));
}
}
}
Lambda③
- 関数のロールにS3を追加します。
lambda_function.py
def lambda_handler(event, context):
bucket_name = event['Records'][0]['s3']['bucket']['name']
file_key = event['Records'][0]['s3']['object']['key']
cont_type = "audio/wav"
lang = "ja-JP_NarrowbandModel"
iam_apikey = "XXXXXXXXXXXXXXXXX"
url = "https://gateway-tok.watsonplatform.net/speech-to-text/api"
s3 = boto3.resource('s3')
local_file_name = '/tmp/'+file_key.replace('%3A', '-')
s3.Bucket(bucket_name).download_file(file_key.replace('%3A', ':'), local_file_name)
stt = SpeechToTextV1(iam_apikey=iam_apikey, url=url)
result_json = stt.recognize(audio=open(local_file_name, 'rb'), content_type=cont_type, model=lang)
# json file save
result = json.dumps(result_json.result, indent=2)
res = s3.Bucket('voice-mail-transcripted-json-file-bucket').put_object(Key=local_file_name+'.json', Body=result)
return res
Lambda④
lambda_function.py
import boto3
import json
s3 = boto3.client('s3')
dynamodb = boto3.client('dynamodb')
SRC_MAIL = "your_email_address"
DST_MAIL = "your_email_address"
REGION = "us-west-2"
DINAMO_TABLE_NAME = "your_dinamo_name"
def lock(key):
try:
dynamodb.put_item(
TableName = DINAMO_TABLE_NAME,
Item = {'filename':{'S':key},'status':{'S':'complete!'}},
Expected = {'filename':{'Exists':False}}
)
return True
except Exception as e:
return False
def unlock(key):
dynamodb.delete_item(
TableName = 'test-lambda',
Key = {
'filename': {'S': key}
}
)
def send_email(source, to, subject, body):
client = boto3.client('ses', region_name=REGION)
response = client.send_email(
Source=source,
Destination={
'ToAddresses': [
to,
]
},
Message={
'Subject': {
'Data': subject,
},
'Body': {
'Text': {
'Data': body,
},
}
}
)
return response
def lambda_handler(event, context):
bucket_name = event['Records'][0]['s3']['bucket']['name']
file_key = event['Records'][0]['s3']['object']['key']
response = s3.get_object(Bucket=bucket_name, Key=file_key)
transcripted = json.loads(response['Body'].read().decode('utf-8'))
email_content = ''
for i in range(len(transcripted['results'])):
email_content += transcripted['results'][i]["alternatives"][0]["transcript"].rstrip()
email_title = "Amazon Connectを用いたボイスメモ1"
message = json.dumps(event, indent = 4)
print(email_content)
# print(file_key)
# if(lock(file_key)):
# r = send_email(SRC_MAIL, DST_MAIL, email_title, email_content)
# else:
# print(file_key + " seems to be completed already.")
r = send_email(SRC_MAIL, DST_MAIL, email_title, email_content)
return r
おわりに
Speech To Textのサービスは色々ありますが、ポリシーなどの問題でWatsonを使うという需要は一定数あると思います。
IBM Cloudは無料枠が設定されているので、ぜひ試してみてください!