はじめに
Node-REDでNLC(IBM Watson Natural Language Classifier)のチャットボットが作りたかったのですが、前提として学習させなければならないので、共通課題として、学習のさせ方と分類についてを、切り出して投稿しておきます。
前提
- IBM IDを持っていて、Bluemixにログインができる状態。
- BluemixでNode-REDを作成していて、アクセスできる状態。まだの場合:Bluemixでnode-redを立ち上げる
- NLCの仕組みを理解していることが望ましいですが、していなくても問題ありません。
NLCの作成
IBM Bluemixにログインし、カタログからNatural Language Classifierを選択します。
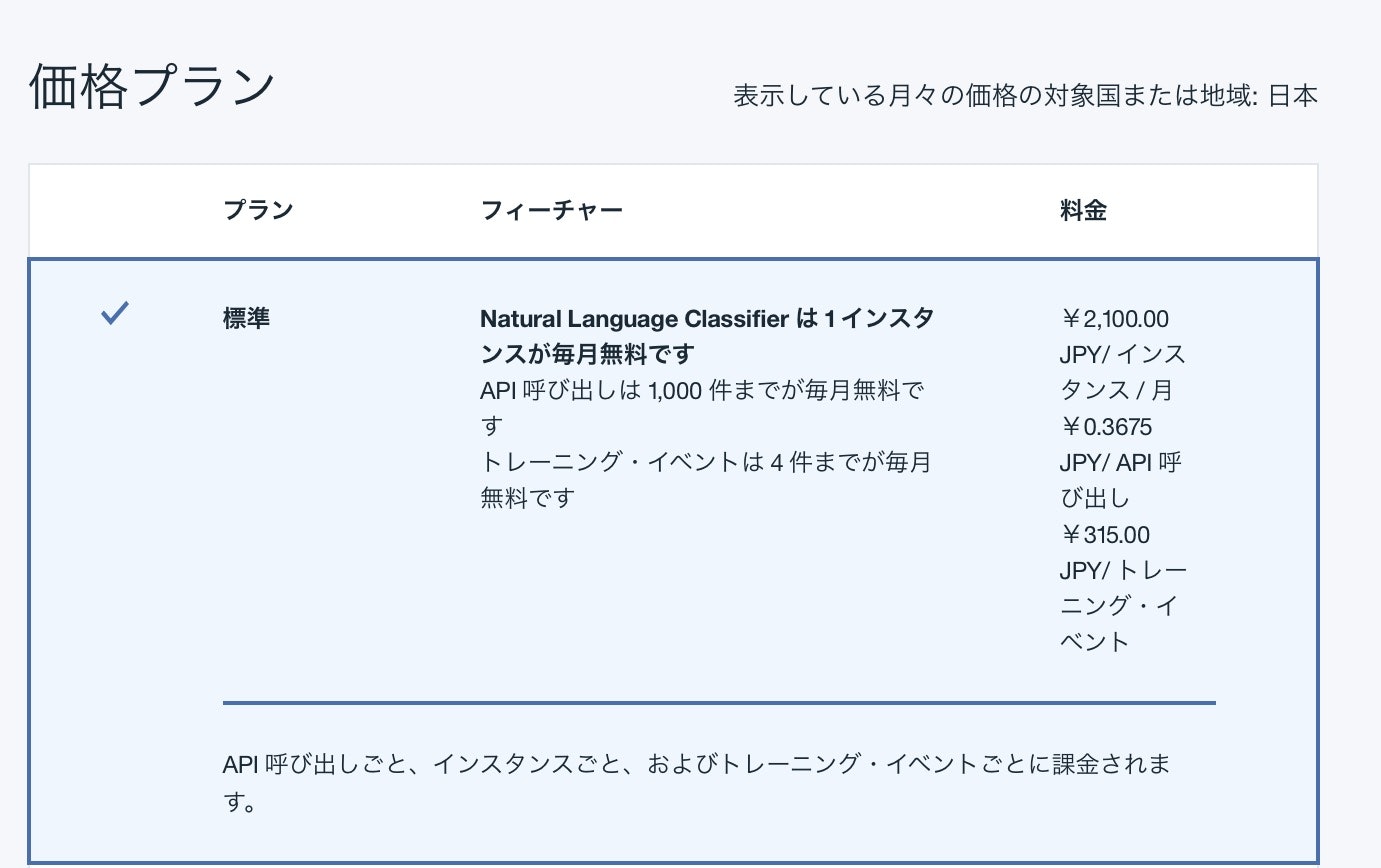
価格プランを見ると、1インスタンス、4トレーニング、1000呼び出しまでが無料とあります。今回は1度試してみる程度ですので、無料枠でおさまる計算ですね(投稿時点。最新は公式でご確認ください)。なおサービス名は何でもよいのですが、自分はあとからわかるような名前で入力して、作成するようにしてください。
サービスのバインド
Bluemix Consoleより作成済のNode-REDを開き、『接続』から『既存に接続』を選択し、先ほど作成したNLCを指定します。
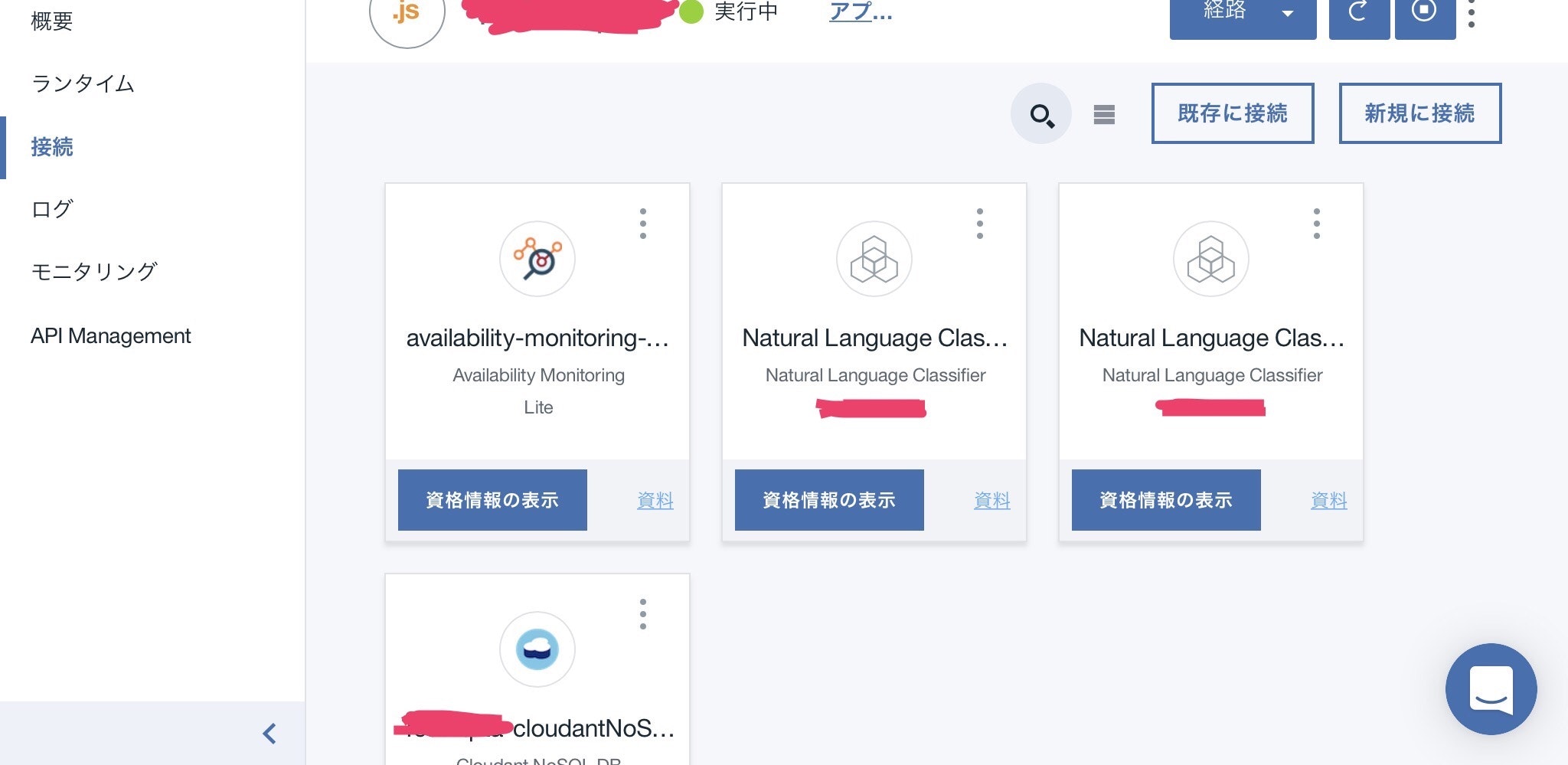
前項『NLCの作成』をせずここで『新規に接続』しても同じ結果になります。
Node-REDの開発
Training
さっそくNode-REDのパレットよりNLCを見つけて、配置します。

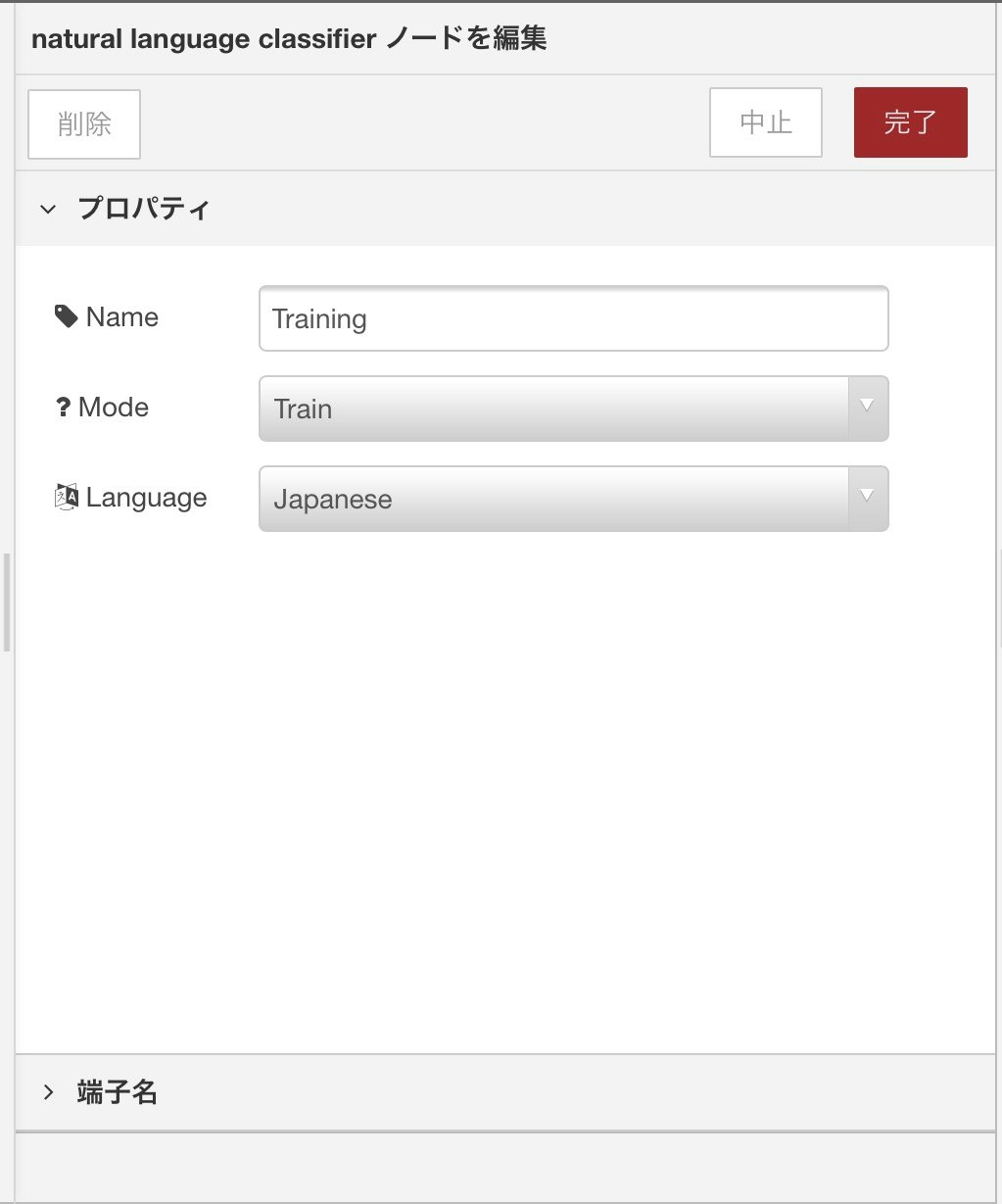
ダブルクリックで開き、ModeをTrain、LanguageをJapaneseとしておきます。名前は何でもいいです。バインドされているので、これでNLCの呼び出しが可能です。ちなみに複数バインドされていた場合、新しい方に接続されるようです(仕様未確認)。
次に、学習するデータを用意します。機械学習における教師データとか呼ばれるものですね。公式文書を見ると、学習データはcsvをUTF-8で用意し、1カラム目にTextを、2カラム目にClassを記載し、カンマで分割しなさいとあります。用意されているNode-REDのノードでは、以下のように投入すれば学習されますので、最後の3つだけ意識しておいてください。ここではテーマを携帯ショップのチャットボットとしてさらりと済ませてしまいますが、やり始めると深いところですので、機会を見つけて別の記事で紹介したいと思います。
こんにちは,挨拶
こんばんは,挨拶
はじめまして,挨拶
よろしく,挨拶
どうも,挨拶
新規契約したい,新規契約
携帯電話がほしい,新規契約
契約したい,新規契約
乗り換えがしたい,MNP
番号を継続したい,MNP
MNPがしたい,MNP
解約したい,解約
携帯をやめたい,解約
契約解除したい,解約
我ながら、例えの悪いテーマです。これを、今回はTemplateノードに仕込んで学習させてみます。パレットからTemplateをドラッグしてドロップ、開いて上のテキストをテンプレートに貼り付けます。

完了を押して戻ると、以下のように名前が適用されています。

これだけではNode-REDは、いつ動いていいかわからないので、トリガーをInjectノードで教えてあげます。timestamp??気にしないでください。今回は学習データ投げるきっかけとしてのみ動作しますので、中身は無関係です。さらに学習をしたあとにできる分類器(NLCの実体)の情報が必要になるので、Debugノードを配置してから、トリガーをキックします。
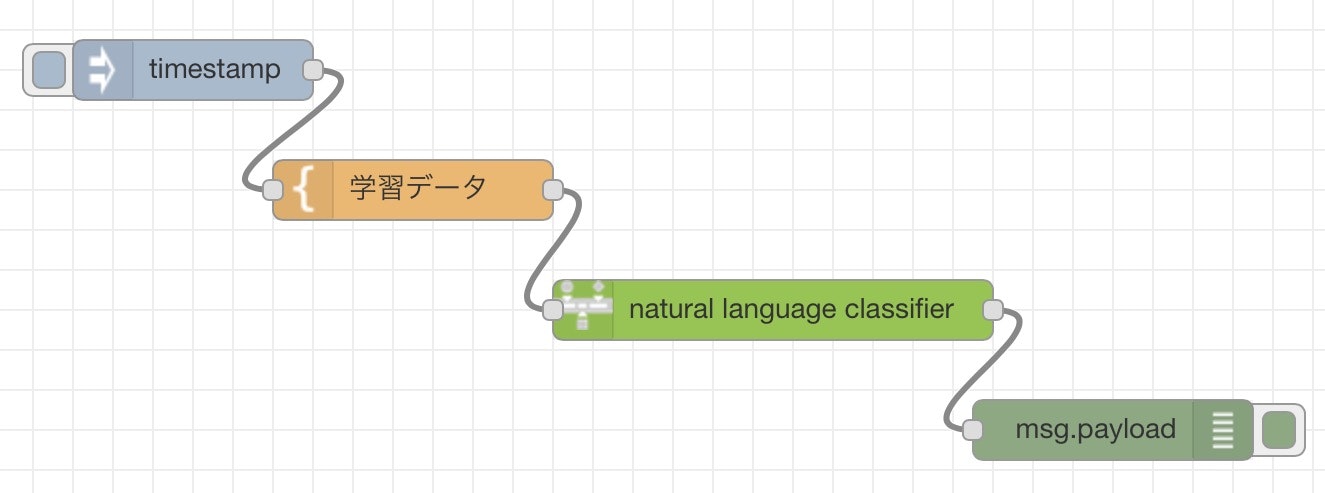
『デプロイ』したあとに、timestampの左側にあるボタンを押してみてください。下記のメッセージが出ると思います。※これは冒頭の価格プランで見た『トレーニング・イベント』にあたります。むやみに押さないよう注意してください!

同時に、デバッグタブには下記のようなメッセージが表示されますので、内容を控えておいてください。

トレーニングは数分から数十分待たされますので、その間に他のノードを開発してしまいます。せっかくなのでトレーニングのノードは残し、コメントをつけておきましょう。

Classify
NLCとはその名の通り、自然言語の分類サービスです。この『Classify』が分類であり、学習済のNLCを呼び出し、分類することになります。準備するのはTraining同様、パレットに用意されたNLCのノードです。先ほど、Trainingの際にDebugノードに吐き出された"classifier_id"を入力し、完了を押してください。

Training同様に、InputとOutputを作っていきます。通常、アプリケーションとしてはUIとしてWeb画面やメッセージングアプリとの接続をしてやる必要がありますが、長くなるので割愛し、InjectとDebugノードを使って済ませます。LINEやSlackなどのアプリと接続したい方は、下部の記事を参考に、結合していただければと思います。

ここで、Injectノードは先ほどとは違い、分類したいテキストそのものを送信する必要がありますので、開いて『ペイロード』に分類したいテキストを記載します。

完了を押してノードを接続、デプロイしたあとに『こんにちは』の左にあるボタンを押してみましょう。

先ほどと同じようにメッセージが、画面上とデバッグタブに表示されたと思います。

msg.payload.top_classが『挨拶』ですね。『こんにちは』は学習データにそのものが存在したので、msg.payload.classes[0].confidenceより、NLCの確信度(confidence)が1(100%)で返却されていることがわかります。学習データそのものであくても1が返ることもありますが、いずれにせよ学習データと非常に近いものだと理解してください。
Answerとの紐付け
Injectより日本語を入力すると、Classifyしてくれるところまでできました。次に、分類されたClassに対応する回答を紐づけるノードを追加していきます。一般的にはDBサービスを使うことになりますが、今回は簡易に、Switchノードで実現します。
Switchノードを開いて、下記のように設定します。先ほどデバッグタブで確認した通り、msg.payload.top_classに『最も確からしい分類結果』が格納されていることがわかりましたので、ここの値によって、処理を変更するというルールにします。otheriseは発生しない想定ですが、一応書いておきます。また複数の条件を満たすことはありませんので、『最初に合致した条件で終了』としておきます。

このSwitchノードを配置すると、以下のように分岐ができます。

さらに分岐した先にChangeノードを配置し、回答を紐付けてみます。以下は『挨拶』に分岐された先に接続するノードです。これを例に、5つのChangeノードを配置してください。

このようになったら完了です。

再度こんにちはの左にあるボタンを押してみます。Classと紐付けた回答が格納されていることがわかります。

こんにちはだけじゃ面白くないので、Inputを『解約したいんだけど』に変更してみましょう。Injectノードのペイロードに文字を入れ、完了 → デプロイをし、ボタンを押します。

解約の分類に適応した回答が返されました。

ちなみにConfidenceは0.98とのこと。『解約したい』が学習データに存在したので、さすがに間違えなかったようです。

LINE@との接続
今回は手抜きでInput/Outputを、それぞれInject/Debugノードで実装しましたが、チャットボットの場合UIの開発が必要になります。下記を参照するとLINE@での接続ができますので、よかったら結合してみてください。
Watson ConversationでLINEのチャットボットを作ってみる(前編)
Watson ConversationでLINEのチャットボットを作ってみる(後編)
おわりに
NLCの使い方ということでざっと書いてきましたが、学習データの作り方やチャットボットにおけるテーマやスコープの切り方にはあまり触れられませんでした。各々重要な点ですので、どこかであらためて触れたいと考えています。