繧医&縺昴≧縺ェ繧オ繧、繝医′譁�ュ怜喧縺代@縺ヲ縺�※縲√≧繧上Γ繝ウ繝峨¥縺輔→縺ェ縺」縺溘%縺ィ縺ゅj縺セ縺帙s縺�? 文字化け、読めるようになってみませんか?
文字化けとは
説明要る?
文字化けとは「もじばけをよむ。」が「繧ゅ§縺ー縺代r繧医�縲�」みたいになってしまう悲劇です。一昔前のHPを見に行くと遭遇します。
コンピューターあるあるですが、データは01に変換されます。文字列も例外ではなく、「文字コード」という変換ルールを使います。世の中に様々な言語や暗号があるように、この文字コードにもさまざまな種類があります。そのため、「文字->01」のときに使った文字コードと、「01->文字」のときに使った文字コードが一致しないという事態がたびたび発生します。たとえるなら、フランス語だと思って翻訳したら実際はスワヒリ語だった、みたいな事態です。
よく目にする文字化けは「UTF-8」で01に変換されたものを、「Shift-JIS」だと思って文字列に変換してしまったケースなので、今回はこれに絞って書きます。
UTF-8とは
最近よく使われる文字コードです。あらゆる文字を表現することを目指しています。
英語を表記するのに1バイト、日本語に3バイト使います。1
この記事の中では、英語を無視し、UTF-8が常に3バイト使うものとして扱います。
例として、「やはり青春ラブコメ。」は
や: E3 82 84
は: E3 81 AF
り: E3 82 8A
青: E9 9D 92
春: E6 98 A5
ラ: E3 83 A9
ブ: E3 83 96
コ: E3 82 B3
メ: E3 83 A1
。: E3 80 82
と表記できます。
日本語など、3byteで表記されるUTF-8のビット列は、
1ビット: 1110-****
2ビット: 10**-****
3ビット: 10**-****
というルールに従っています。
まず1ビット目に注目すると、16進数表記でE*となります。
日本語に限定すると、
-
E3が「約物2」「ひらがな」「カタカナ」 -
E4~E9が「漢字」
が対応します。
漢字に関してですが、部首ごと、画数の小さな部首から順に並んでいます。
E4: 一画の部首全部、二亠、人
E5: 人、二画の部首残り、口囗土士夂夊夕大女子宀寸小尢尸屮山巛工己巾干幺广廴廾弋弓彐彡彳、心
E6: 心、三画の部首残り、水
E7: 水、四画の部首残り、五画の部首全部、竹米糸缶网羊羽
E8: 老、六角の部首残り、見角言谷豆豕豸貝赤走足身車辛辰辶
E9: 辶、残りの部首
また、2,3ビット目に注目すると、16進数表記したときの1桁目が8, 9, A, Aのどれかになることがわかります。中でも2ビット目は
-
80: 約物 -
81: ひらがな -
82: ひらがな/カタカナ -
83: カタカナ
となります。
まとめると、
- 約物:
E3 80 XX - ひらがな:
E3 81 XXorE3 82 XX - カタカナ:
E3 82 XXorE3 83 XX - 漢字:
E[4-9] XX XX
となります。ここでXXは、一桁目が8, 9, A, B、言い換えると80~BFまでが入ります。
ついでにひらがなの開始はE3 81 81、カタカナの開始はE3 81 A1、小書きの仮名(ぃ、とか)はその字の直前に入る、ということを覚えておくと、バイト列から仮名もわかります。
Shift-JISとは
昔よく使われていた文字コードです、と言いたいのですが、今でもWindowsの内部で使われている文字コードです。日本語を表現しようとした文字コードです。
英語・ハンカクカタカナを表記するのに1バイト、それ以外の日本語を表現するのに2バイト使います。
例として、「やはり青春ラブニフメ。」は
や: 82 E2
は: 82 CD
り: 82 E8
青: 90 C2
春: 8F 74
ラ: 83 89
ブ: 83 70
ニ : C6
フ : CC
メ: 83 81
。: 81 42
と表記できます。
Shift-JISのバイト列の読み方はWikipediaの図がわかりやすいです。
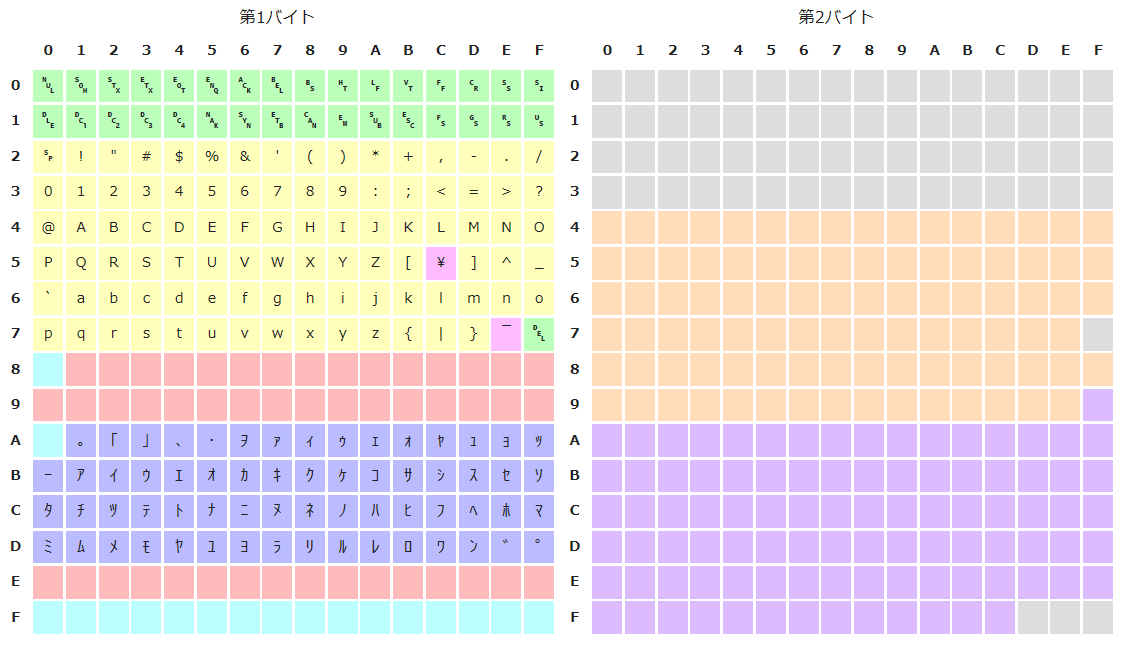

バイト列を先頭から読んでいく中で、
- 黄色か青のバイト: 1バイト目で終了
- 赤(ピンク)を認識した場合は、もう1バイト読み、終了
したがって、UTF-8でよく使われる80~BFのバイト列が、Shift-JISの1バイト目に来た場合は
- 80 : 読み込まれない
- 81-9F: 約物、全角文字、ひらがな、カタカナ、漢字
- A0 : 読み込まれない
- A1-BF: 漢字
となります。
UTF-8->Shift-JISの文字化けを読む
UTF-8だったものをShift-JISと勘違いした場合の文字化けを読むうえで、重要な点が2つあります。
- UTF-8は3バイト、Shift-JISは1~2バイト
- UTF-8はかならず、E3からはじまる
UTF-8であらわされたひらがな2文字「E3-XX-XX-E3-XX-XX」はShift-JISで
- E3-XX
- XX-E3
- XX
- XX-XX
の4通りで解釈されます。(漢字が含まれる場合はE3がE4-E9になります)
したがって、E3を含む文字を見つけることで、もともとの区切りがわかるようになります。
一つ一つ見ていきましょう。
E3からはじまるShift-JISの文字(E4-E9も)
E3-XXという形のShift-JISの文字を見ていきましょう。
まず、最重要なものから
| バイト列 | UTF-8 | Shift-JIS | 漢字の解説(ちゃんと辞書で引いてね) |
|---|---|---|---|
| E3 80 | 約物 | 縲 | 捕縛する |
| E3 81 | ひらがな | 縺 | 縺(もつ)れる。絡まりあう |
| E3 82 | ひらがな/カタカナ | 繧 | 繧繝(とびとびのグラデ、これみたいな) |
| E3 83 | カタカナ | 繝 | 錦、プリーツスカート |
文字化けといえば糸偏、しかも「縺」みたいなイメージがありますが、それは「縺」がひらがなを指し示しているからです。言い換えると
「縺〇」という並びをみるだけで、「あぁこれはひらがなだな」と判断できます。
また、E4-E9から始まるのは漢字です。すべてJIS第二水準の漢字なので、珍しい漢字が多いです。
多すぎるので部首のみ掲載します。部首の画数が6~7画のものが多い気がします。
E4: 月至臼舌舟艹
E5: 虍虫血行衣
E6: 襾見角言谷豆豕貝赤走
E7: 身車辛辶邑酉釆金
E8: 門阜隶隹雨面革韋韭音頁
E9: 風食首馬骨髟鬥鬼魚鳥
EA: 鹵鹿麦黍黒黹黽鼓鼠齒
部首としてまとまっていなかったために上から省いたものとして
E4: 隋臧艱艷
E7: 釐
E8: 靜靠竟
E9: 馥
EA: 靡黌鼾齊龕龜龠堯槇遙瑤凜熙
があります。
E3で終わるShift-JISの文字
区切り方によってはXX-E3として認識されます。この場合を見ていきましょう。
XX-E3となる文字は
80E3: 存在せず
81E3: √
82E3: ゅ
8[3-7]E3: 存在せず
8[8-F]E3: 医峨翫九後阪弱上
9[0-F]E3: 舌代偵薙斐輔悶励倥吶壹帙懊昴槭溘
[A0-BF]E3: 存在せず
となります。
E4で終わるものは膨大で、まとまりもないため割愛します。
XXのもの
XXは80-BFを示しますが、このうちA1-BFにあたるものが1バイト目に来た場合、2バイト文字でなく1バイトの半角カナとして認識されます。
A1-AF: 。「」、・ヲァィゥェォャュョッ
B0-BF: ーアイウエオカキクケコサシスセソ
したがって、半角カナのうち、タ行以降及び濁点、半濁点は文字化けの中に出現しません。
XX-XXのもの
"◆"などの記号、全角英字、ひらがな、カタカナ、第一水準漢字、第二水準漢字など、非常に大きな領域にまたがります。
実際に読む
「縺セ繧九〒縲√ざ繝溘�繧医≧縺�」を読んでみましょう。
まず、上記の内容でわかるビット列を埋めてみます。
縺: E3 81
セ : BE
繧: E3 82
九: 8B E3
〒: XX XX
縲: E3 80
√ : 81 E3
ざ: XX XX
繝: E3 83
溘: 9F E3
�: ?
繧: E3 82
医: 88 E3
≧: XX XX
縺: E3 81
�: ?
これをE3を目安に並べると、
E3 81 BE -> ま
E3 82 8B -> る
E3 XX XX -> 約物/ひらがな/カタカナ
E3 80 81 -> 、
E3 XX XX -> 約物/ひらがな/カタカナ
E3 83 9F -> ミ
E3 ? -> 約物/ひらがな/カタカナ
E3 82 88 -> よ
E3 XX XX -> 約物/ひらがな/カタカナ
E3 81 ? -> ひらがな/カタカナ
と、E*-XX-XXの形式であることがわかります。
まとめると「まる〇、〇ミ〇よ〇〇」となります。
いやまぁ、ここまで書いたあげく予測できるのはここまでですが、有名台詞なので勘で当ててみてください。
終わりに
文字ばけらった使え
参考リンク
UTF-8からSJISに文字化けすると糸偏の漢字がよく出てくる
UTF-8の対応表
Shift-JISの仕組み
Shift-JISの対応表
UTF-8の仕組み
文字化けさせるサイト
文字ばけらった