データ解析のための統計モデリング入門 - 岩波書店
のRのコードをJuliaで実装してみました。
ちなみにPython版はこちらが参考になります。
pythonで「データ解析のための統計モデリング入門」1 確率分布と統計モデリングの最尤推定
ひとまず実装ができたので,コードだけ公開します。
本の内容,コードの詳細な解説は後日追記します。
実行環境
- juliaのdockerイメージ
- vscode
- vscodeのJulia拡張機能
- vscodeのJupyter拡張機能
環境構築はこちらを参照。
Dockerイメージを使って JuliaでHello,worldする
使用したモジュール
using Pkg
Pkg.add("StatsBase")
Pkg.add("Distributions")
Pkg.add("DataFrames")
Pkg.add("Gadfly")
データセットの作成と概要
データセットの作成
using DataFrames
data = [
2,2,4,6,4,5,2,3,1,2,
0,4,3,3,3,3,4,2,7,2,
4,3,3,3,4,3,7,5,3,1,
7,6,4,6,5,2,4,7,2,2,
6,2,4,5,4,5,1,3,2,3
]
df_data = DataFrame(x=data)
要約統計量の確認
using StatsBase
summarystats(df_data.x)
>>
Summary Stats:
Length: 50
Missing Count: 0
Mean: 3.560000
Minimum: 0.000000
1st Quartile: 2.000000
Median: 3.000000
3rd Quartile: 4.750000
Maximum: 7.000000
# (不偏)標準偏差の確認
std(df_data.x)
>> 1.7280400600042787
# (不偏)分散の確認
var(df_data.x)
>> 2.9861224489795912
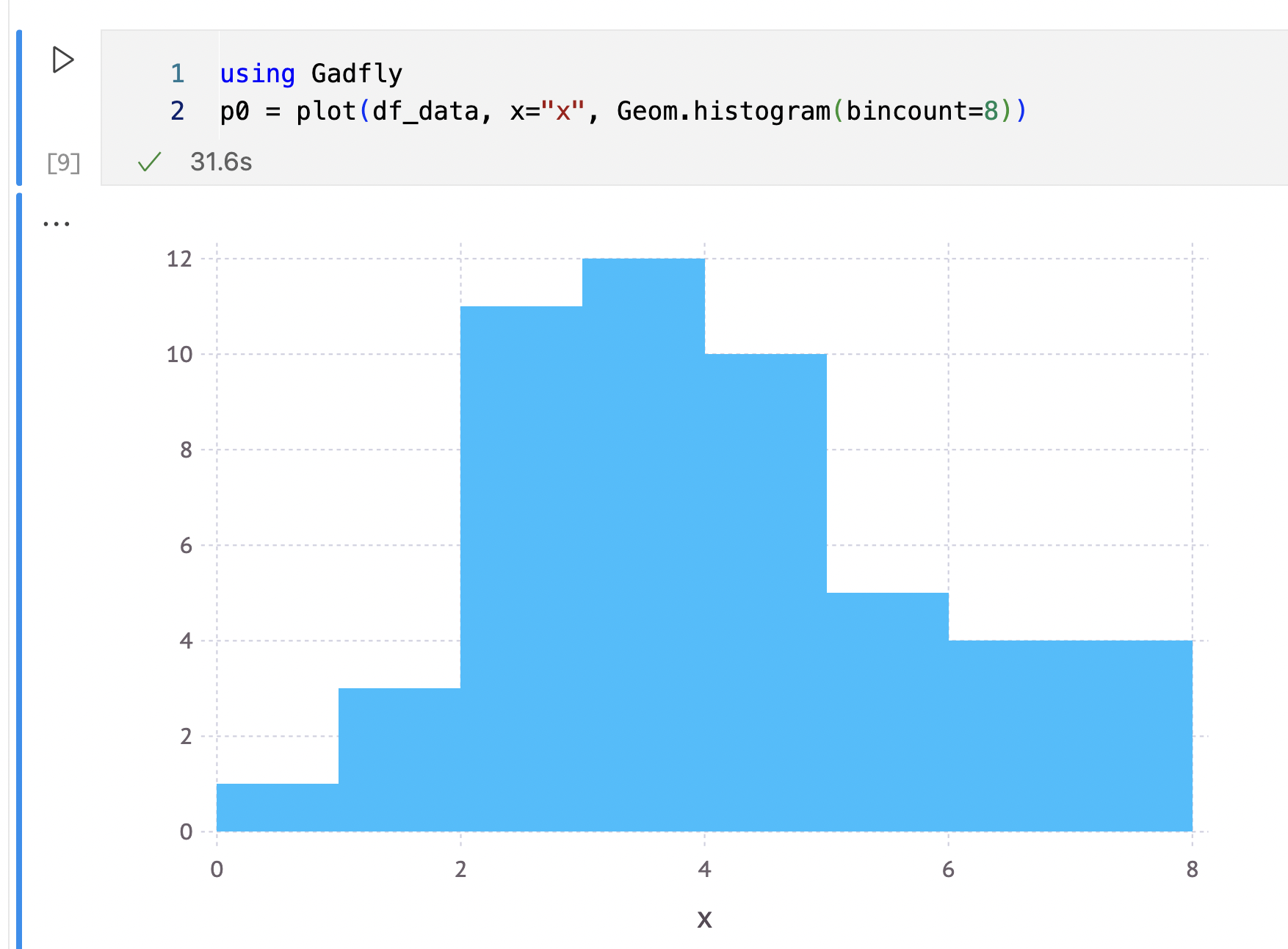
ヒストグラムの描写
using Gadfly
p0 = plot(df_data, x="x", Geom.histogram(bincount=8))
ポアソン分布
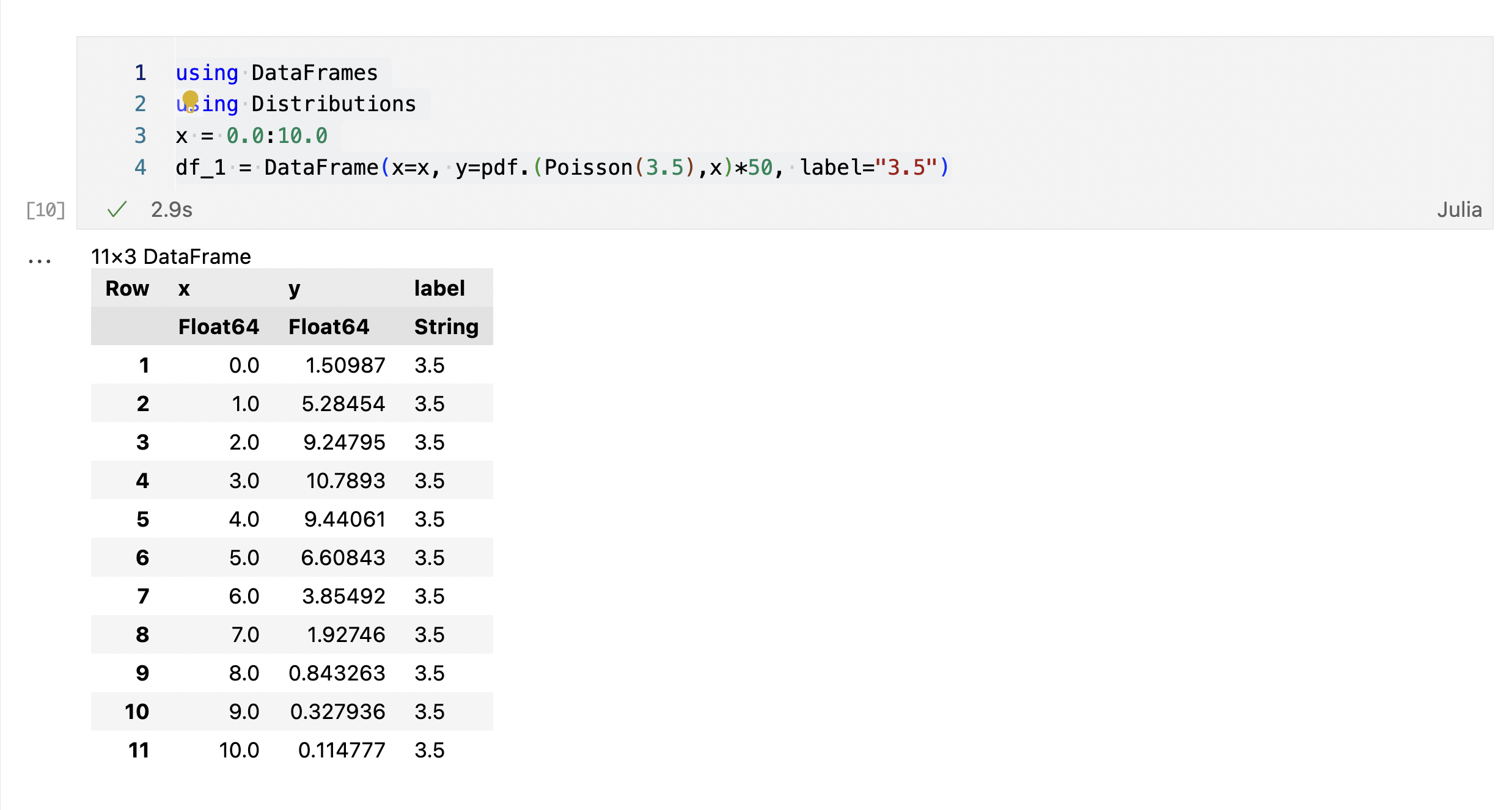
ポアソン分布の生成
using DataFrames
using Distributions
x = 0.0:10.0
df_1 = DataFrame(x=x, y=pdf.(Poisson(3.5),x)*50, label="3.5")
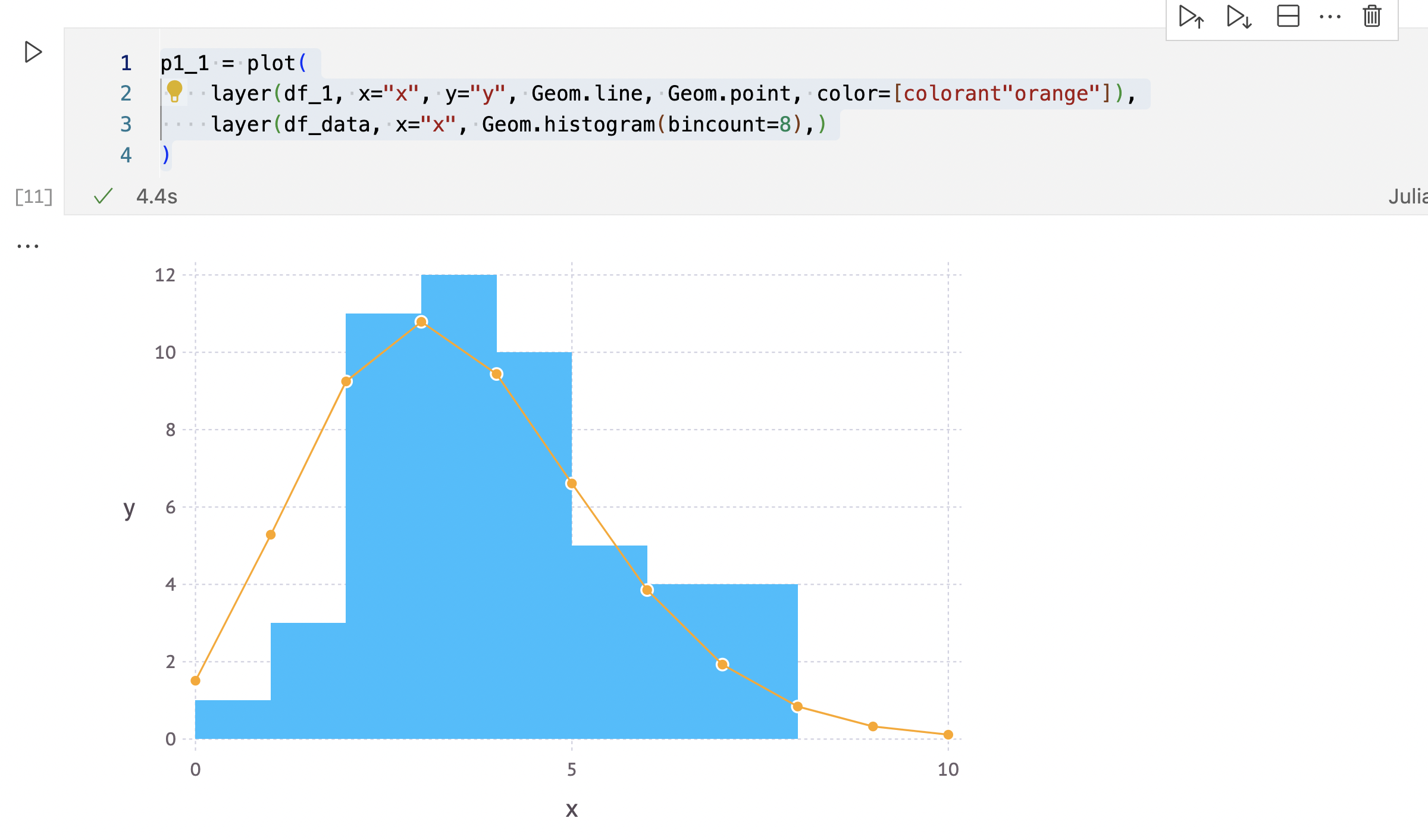
ポアソン分布とヒストグラムを重ねる
p1_1 = plot(
layer(df_1, x="x", y="y", Geom.line, Geom.point, color=[colorant"orange"]),
layer(df_data, x="x", Geom.histogram(bincount=8),)
)
色々なパラメータのポアソン分布を描く
# 3つのポアソン分布の生成
using DataFrames
using Distributions
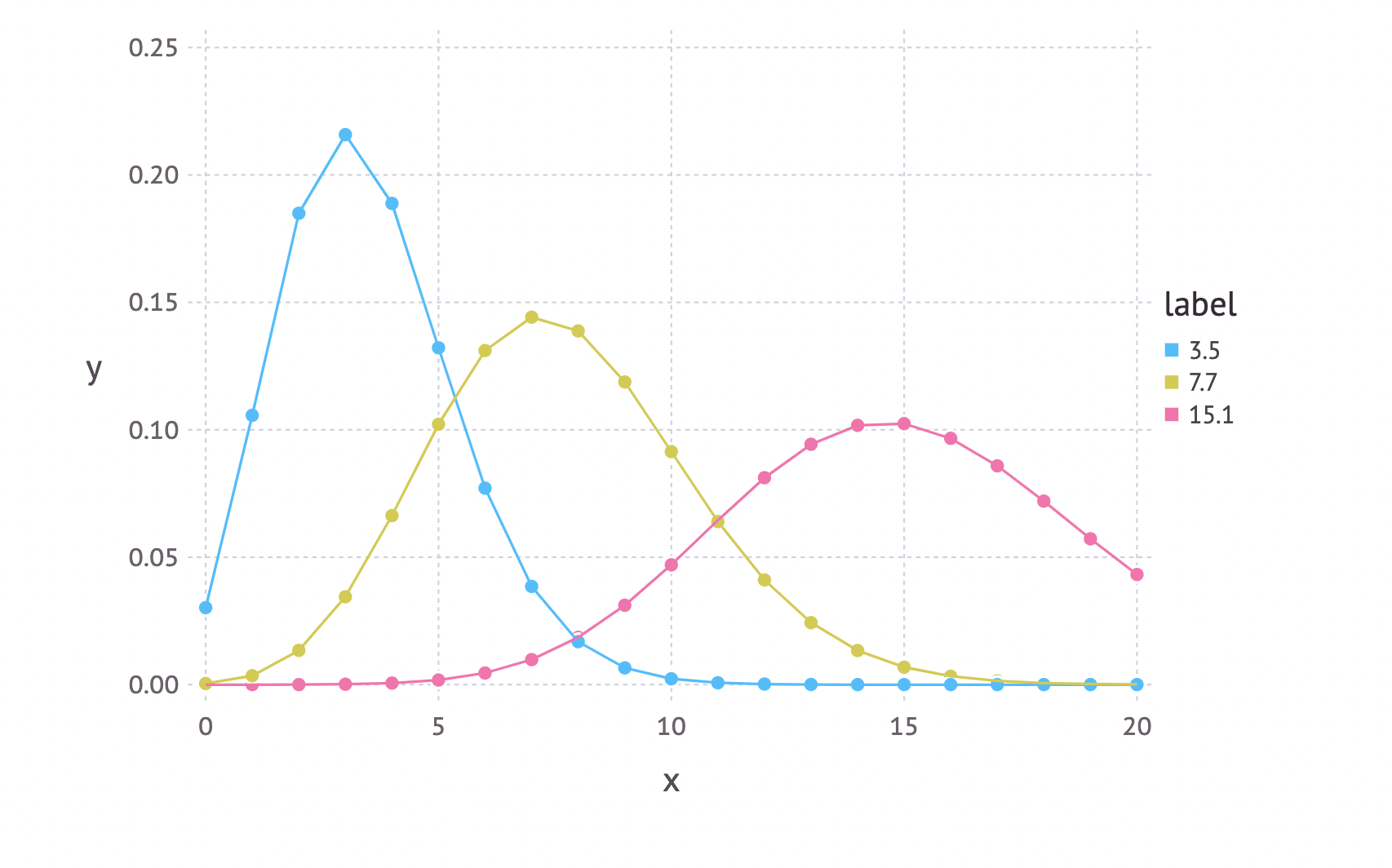
x = 0.0:20.0
df_1 = DataFrame(x=x, y=pdf.(Poisson(3.5),x), label="3.5")
df_2 = DataFrame(x=x, y=pdf.(Poisson(7.7),x), label="7.7")
df_3 = DataFrame(x=x, y=pdf.(Poisson(15.1),x), label="15.1")
# 3つのポアソン分布の描写
using Gadfly
df = vcat(df_1, df_2, df_3)
p = plot(df,x="x", y="y", color="label", Geom.line, Geom.point)
ポアソン分布の最尤推定
# 対数尤度関数の作成
function poisson_log_likelihood(data, λ)
df_poisson = DataFrame(x=data,y=pdf.(Poisson(λ),data), label=string(λ))
df_logL = DataFrame(x=data, y=log.(pdf.(Poisson(λ),data)))
likelihood = sum(df_logL.y)
return df_poisson, likelihood
end
# λ=2.0の時の対数尤度を算出してみる
df, logL = poisson_log_likelihood(data, 2.0)
println(logL)
>> -121.88118178691752
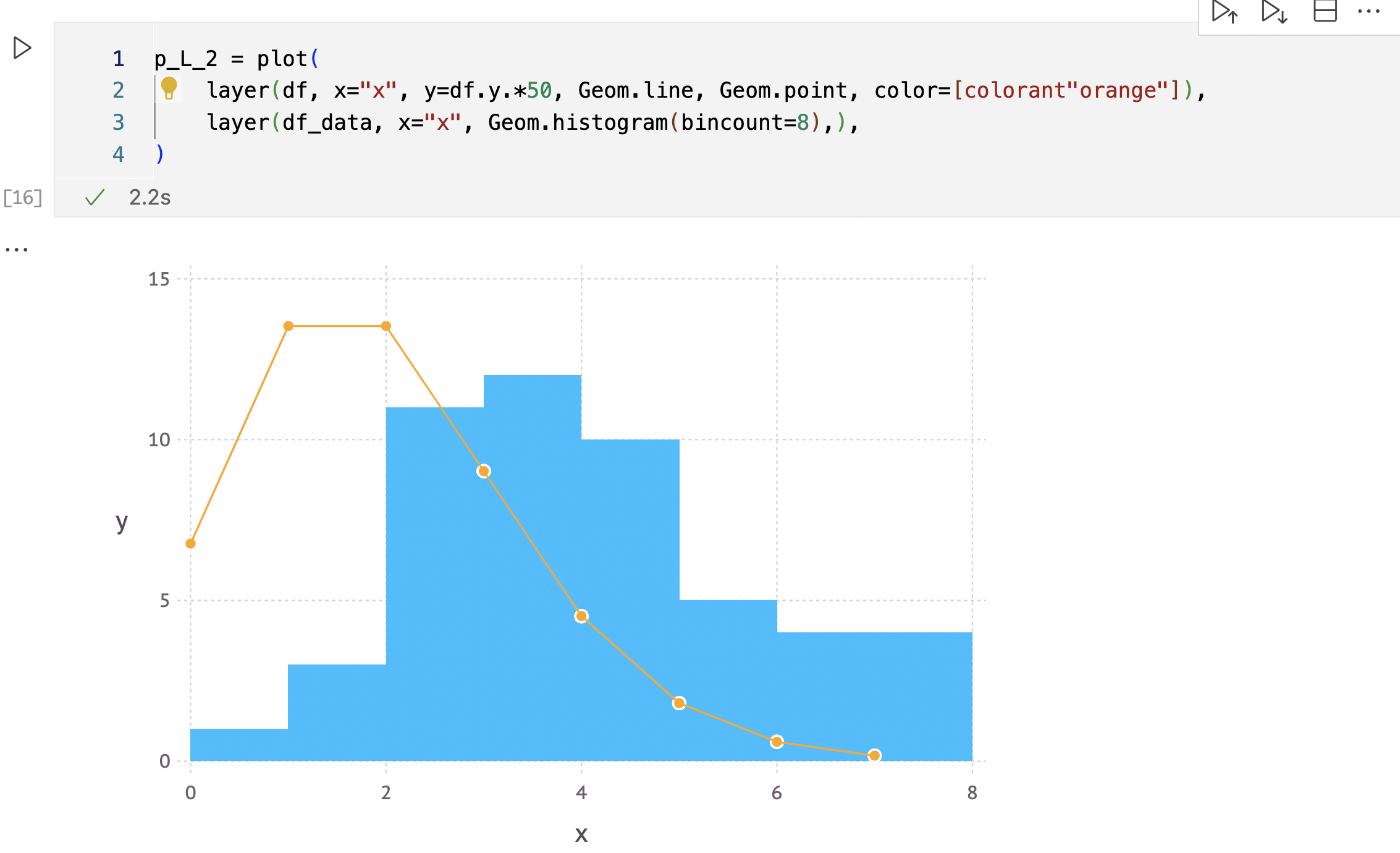
# λ=2.0の時のポアソン分布とヒストグラムを重ね合わせて描写してみる
df, logL = poisson_log_likelihood(data, 2.0)
p_l_2 = plot(
layer(df, x="x", y=df.y.*50, Geom.line, Geom.point, color=[colorant"orange"]),
layer(df_data, x="x", Geom.histogram(bincount=8),),
)
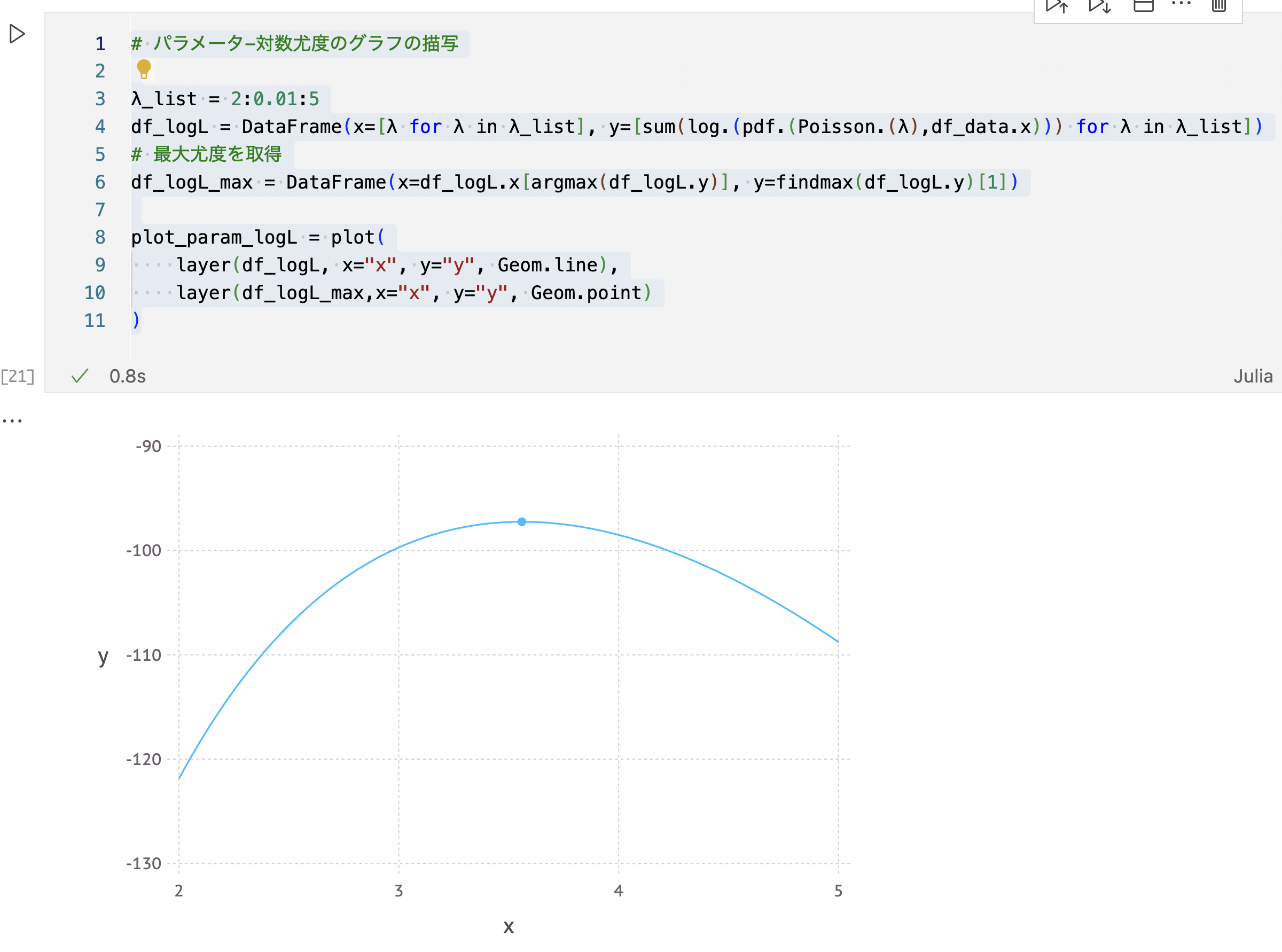
# パラメータ-対数尤度のグラフの描写
λ_list = 2:0.01:5
df_logL = DataFrame(x=[λ for λ in λ_list], y=[sum(log.(pdf.(Poisson.(λ),df_data.x))) for λ in λ_list])
# 最大尤度を取得
df_logL_max = DataFrame(x=df_logL.x[argmax(df_logL.y)], y=findmax(df_logL.y)[1])
plot_param_logL = plot(
layer(df_logL, x="x", y="y", Geom.line),
layer(df_logL_max,x="x", y="y", Geom.point)
)