概要
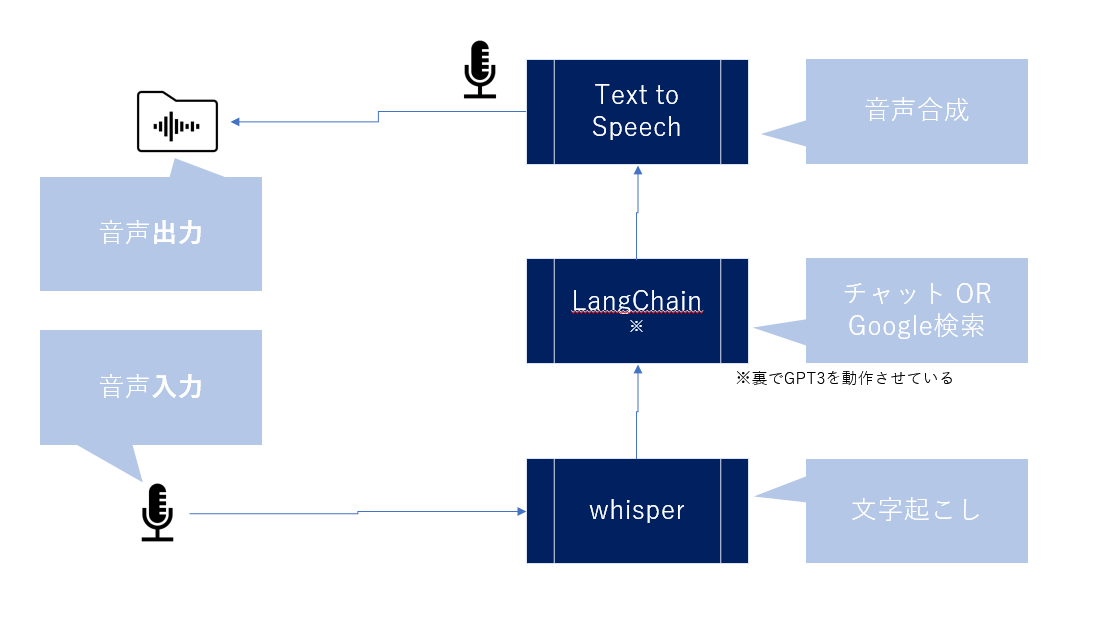
この画像にあるように、マイクで話しかけて、AIに回答を考えてもらい、その結果を音声として出力する、というものを作成しました。ロボットと対話できます。
全てGoogleColabの環境でできます。
こちらの方の記事内容をオマージュさせていただいてます。
環境
利用するライブラリ
主に4つ使ってます。
gTTS # ← GoogleTextToSpeechという音声合成のためのライブラリです
whisper
langchain
openai
ライブラリの入れ方
全てpipで入れることができます。
pip install gTTS
pip install git+https://github.com/openai/whisper.git # whisperをいれる
pip install langchain
pip install openai
whisperのモデルダウンロード
OpenAI側で学習モデルを用意してくれているので、それをDLします。
import whisper
model = whisper.load_model("large")
モデルは最大の"large"をDLしているので、それなりに時間がかかります。
ローカルPCマイク音声入力を可能にする
ローカルPCマイクにしゃべりかけた内容をColab側へ入力しなくてはいけません。そのためのコードが次です。
import glob
import librosa
import IPython
import MeCab
import unidic
import pandas as pd
import alkana
import re
import os
from IPython.display import Audio
%cd /content/voicevox_core
# ローカルPCマイクでの録音設定
from IPython.display import Javascript
from google.colab import output
from base64 import b64decode
RECORD = """
const sleep = time => new Promise(resolve => setTimeout(resolve, time))
const b2text = blob => new Promise(resolve => {
const reader = new FileReader()
reader.onloadend = e => resolve(e.srcElement.result)
reader.readAsDataURL(blob)
})
var record = time => new Promise(async resolve => {
stream = await navigator.mediaDevices.getUserMedia({ audio: true })
recorder = new MediaRecorder(stream)
chunks = []
recorder.ondataavailable = e => chunks.push(e.data)
recorder.start()
await sleep(time)
recorder.onstop = async ()=>{
blob = new Blob(chunks)
text = await b2text(blob)
resolve(text)
}
recorder.stop()
})
"""
def record(sec, filename='audio.wav'):
display(Javascript(RECORD))
s = output.eval_js('record(%d)' % (sec * 1000))
b = b64decode(s.split(',')[1])
with open(filename, 'wb+') as f:
f.write(b)
audiofile = "audio.wav"
second = 6 #@param {type:"number"}
print(f"Speak to your microphone {second} sec...")
record(second, audiofile)
print("Done!")
今回は6秒だけ録音する設定にしていますが、もっと長く(短く)することもできます。
文字起こしの結果を確認したい場合は次のコードを実行します。
result = model.transcribe("audio.wav", verbose=False, language="ja")
textised_sentence = result["text"]
print(textised_sentence)
実行結果はこちら。

「今日のトレンドニュースを教えてください」とマイクに向かってしゃべりかけたので、正確に文字起こしできていることを確認できます。
(筆者の感覚ですが、こういった文字起こしって精度があまりよくなく、ちゃんと文字起こしできないと思っているのですが、Whisperは正確だなと思いました。)
音声で確認したい方はこちらのコードを実行してみてください。
# 入力した音声の確認
Audio("audio.wav")
次の画像のように、再生できるようなインターフェースが表示されるので、再生ボタンを押すと、マイクに話しかけた内容が録音されているはずです。
APIの設定
各種APIの取得方法については、次のページが参考になるかと思います。
- OpenAIのAPIキー:https://auto-worker.com/blog/?p=6988
- Googleカスタム検索の検索エンジンID:https://movabletype.net/sitesearch/manual/getgsearchid.html
- Googleカスタム検索のAPIキー:https://qiita.com/zak_y/items/42ca0f1ea14f7046108c
os.environ["OPENAI_API_KEY"] = "OpenAIのAPIキー"
os.environ["GOOGLE_CSE_ID"] = "Googleカスタム検索の検索エンジンID"
os.environ["GOOGLE_API_KEY"] = "Googleカスタム検索のAPIキー"
LangChainのパッケージインポート
# パッケージのインポート
# langchain関連のパッケージインポート
# エージェント系のライブラリインポート
from langchain.agents import load_tools
from langchain.agents import initialize_agent
# OpenAI
from langchain.llms import OpenAI
# 会話用のメモリ
from langchain import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferMemory # 要約しながら会話をするとき
from langchain.chains.conversation.memory import ConversationalBufferWindowMemory # ある時点までの過去の会話を記憶しながら会話をするとき
# ChatGPTっぽく使うためにはプロンプトが必要なので
from langchain.agents import ZeroShotAgent
from langchain.agents import AgentExecutor
from langchain.chains import LLMChain
会話エンジンの定義
ここでこの音声対話ロボットのエンジンとなる会話エンジンパートの設定を行います。
コードはこちらの記事と同じですので中身を確認したい方はこちらを参考にしてください。
llm = OpenAI(temperature=0.5)
# 利用するツールの定義
# ※llm-mathは必須だから加えておく
tools = load_tools(["google-search", "llm-math"],
llm = llm)
# 公式に記載されているChatGPTっぽく会話をさせるためのテンプレのプロンプトを一部改変
# 基本的に全文テンプレを引っ張ってきているが、
# "You have access to the following tools:"のところだけ、追加した箇所。
# プロンプトの生成&定義
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools:"""
suffix = """Begin!"
{chat_history}
Question: {input}
{agent_scratchpad}
"""
prompt = ZeroShotAgent.create_prompt(tools,
prefix = prefix,
suffix = suffix,
input_variables = ["input", "chat_history", "agent_scratchpad"])
# LLM Chainの定義
llm_chain = LLMChain(llm = llm,
prompt = prompt)
# エージェントのインスタンス化
agent = ZeroShotAgent(llm_chain = llm_chain,
tools = tools,
verbose = True)
# メモリの定義
memory = ConversationBufferMemory(memory_key="chat_history")
# 定義したエージェントやツール、メモリを使って、エージェントのチェーンを生成
agent_chain = AgentExecutor.from_agent_and_tools(agent = agent,
tools = tools,
verbose = True,
memory = memory
)
ロボット側の回答内容の確認
さきほど設定した会話エンジンに、マイクから入力して文字起こしした内容を渡しているので、その回答結果を確認してみましょう。
answer = agent_chain.run(input = textised_sentence)
実行結果はこちら。

今日のトレンドを検索することを思考して、とるべきアクションとしてGoogle Searchを選択し、GoogleSearchではインプットとして「今日のトレンドニュース」と入力している様子が見て取れます。
LangChainを使うことのメリットは、AI側の思考をトレースできるので、仮に間違いがあったとしてもどこで間違えているのか確認しやすい点は大きなメリットだと思います。
最終的な答えだけを見たい場合は、次のコードを実行すればよいです。
print(answer)
実行結果はこちら。

うーん。欲しかった情報とは少し違った回答が返ってきてしまいました。しかし、今日のトレンドを探そうとしてくれたんだな、というのはなんとなく伝わってくる回答なので、このあたりはご愛敬ということで大目に見てあげましょう。
ちなみに、この回答はややランダムに返ってきます。GPT3側でランダム性が組み込まれているのか、リアルタイムに膨大なデータを学習している結果、推論結果である文字列にばらつきが生じているのか、いずれかが要因だと思いますが、正確なところは不明です。どなたかがご存じであればコメントで教えていただけると助かります。
音声合成のための設定
上でAI側の回答内容をテキストデータとして用意できているので、それを音声合成させます。
テキストデータが用意できていれば、VOICEVOXやその他音声合成サービスなどで音声合成すればよいですが、せっかくここまでPythonで作ってきたので、全部Pythonで実行させる形にしたいですよね。
ということで、Google Text to Speechを使って音声合成します。
# 音声発話のためのライブラリ
from gtts import gTTS
# テキストデータから音声ファイル(wavファイル)を作成する
def GenerateWavFile(text_to_say = "こんにちは", language = "ja"):
gtts_object = gTTS(text = text_to_say,
lang = language,
slow = False)
gtts_object.save("output.wav")
"text_to_say"という文字列データを音声合成し、"output.wav"というファイルを生成&保存させています。
音声合成結果の確認
上の関数(GenerateWavFile)を実行することで、音声データが生成&保存されているので、これを再生させてみます。
# 音声の確認
Audio("output.wav")
実行結果はこちらです。

14秒の音声データとなったようです。やや機械音声感がありますが、問題なく音声合成できていると思います。
最後にインプットとアウトプットの確認
最後に「文字お越し」結果と「会話エンジンで生成したテキストデータ」を確認してみましょう。
print("質問:" + textised_sentence)
print("="*100)
print("回答:" + answer)
実行結果はこちら。

まとめと感想
- 今回はLangChainを会話エンジンとして、音声対話ロボットを作成してみました。期待していた回答は得られなかったものの、対話自体は成立していると思います。
- 音声合成にはGoogleTexttoSpeechを使い、そこそこ自然な発話ができています。
- 音声合成については、もっと自然な音声合成ソフトなどもあるので、それらを使うことでもっと自然にすることができると思います。
- Whisperを使って文字起こしする形にしていましたが、制限としていったんwavファイル化したものでないと文字起こしできないので、これが音声ストリームも扱えるようになれば、AlexaやSiri、GoogleAssistantのような音声対話ロボットを自作できるようになると思います。(文字起こしの精度を犠牲にすればGoogleのSpeechToTextというライブラリで音声ストリーミングのリアルタイム文字起こしできますが、いかんせん精度が低すぎるので「。。。」やり方はこちらで解説しています。)