はじめに
どうもこんにちは。ヤフー株式会社のkunishouです。気づけば2022年も残り3週間、皆様いかがお過ごしでしょうか?
今年の機械学習のトレンドと言えば、海外のAI企業から次々とオープンソースのAIが発表されたことが非常に印象的でした。画像生成分野ではStability AI社の「Stable Diffusion」、音声認識分野ではOpenAI社の「Whisper」などが発表されました。発表されたこれらのAIは非常に高機能であるにも関わらず、オープンソースのAIとして、自由に利用することができます。
今回、 クリスマスも近いということなのでこれらの高機能なAIを活用して何か面白い物を作ることはできないか と考え、物理的に言葉を投げかけると返事が返ってくるような音声対話ロボットを作ってみることにしました( クリスマスにしゃべる相手がいないからというわけでは決してありません )。
目次
1.対話ロボットの構成
2.使用するオープンソースAIについて
3.WhisperとVOICEVOXを用いた簡易ボイスチェンジャー
4.BERTのファインチューニング
5.Whisper、BERT、VOICEVOXを用いた対話ロボット
6.作ってみた感想と課題
7.対話ロボットの展望
9.おわりに
参考文献/記事
1.対話ロボットの構成
対話ロボットの全体像としては以下の図のようになります。先述の通り、今年はオープンソースで使用できる高機能なAIが多数発表されました。その中でも今回は、音声認識モデルのWhisperを対話ロボットの音声入力部分に用いたいと思います。また、音声出力部分については合成音声生成モデルのVOICEVOXを、質疑応答タスクのやり取りにはBERTを用い、対話ロボットの実行環境としてはクラウド上でGPUが利用できるGoogle Colabを用いたいと思います。以降では、今回用いるWhisper、VOICEVOX、BERTの概要についてそれぞれ説明し、その後、実装の話をしていきます。
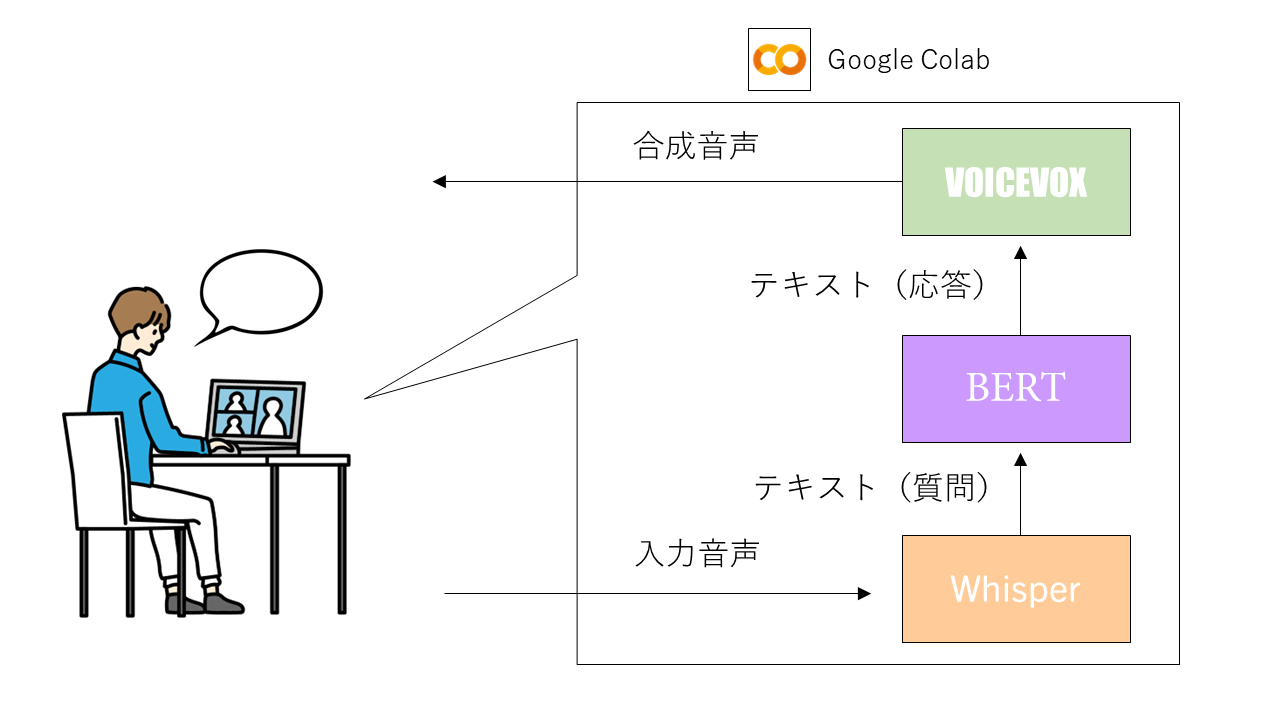
2.使用するAIモデルについて
Whisper
Whisperは、WEBから収集された680,000時間分の多言語教師データにてトレーニングされた音声認識モデルです。大規模で多様なデータセットをトレーニングに用いることでアクセント、バックグラウンドノイズ、専門用語に対する高いロバスト性を実現しています。モデルのアーキテクチャはシンプルで下図のようにEncoder/DecoderからなるTransformerの構成になっています。以下のような特徴/機能があります。
- Transcribe ... 入力した音声を文字に起こす機能
- Translation ... 入力した音声を英語に翻訳して文字に起こす機能
- 多言語対応 ... 約140の様々な言語に対応
- 5種類のモデルが存在 ... モデルサイズがlarge、medium、small、base、tinyの5種類あり(largeが一番精度が高い)
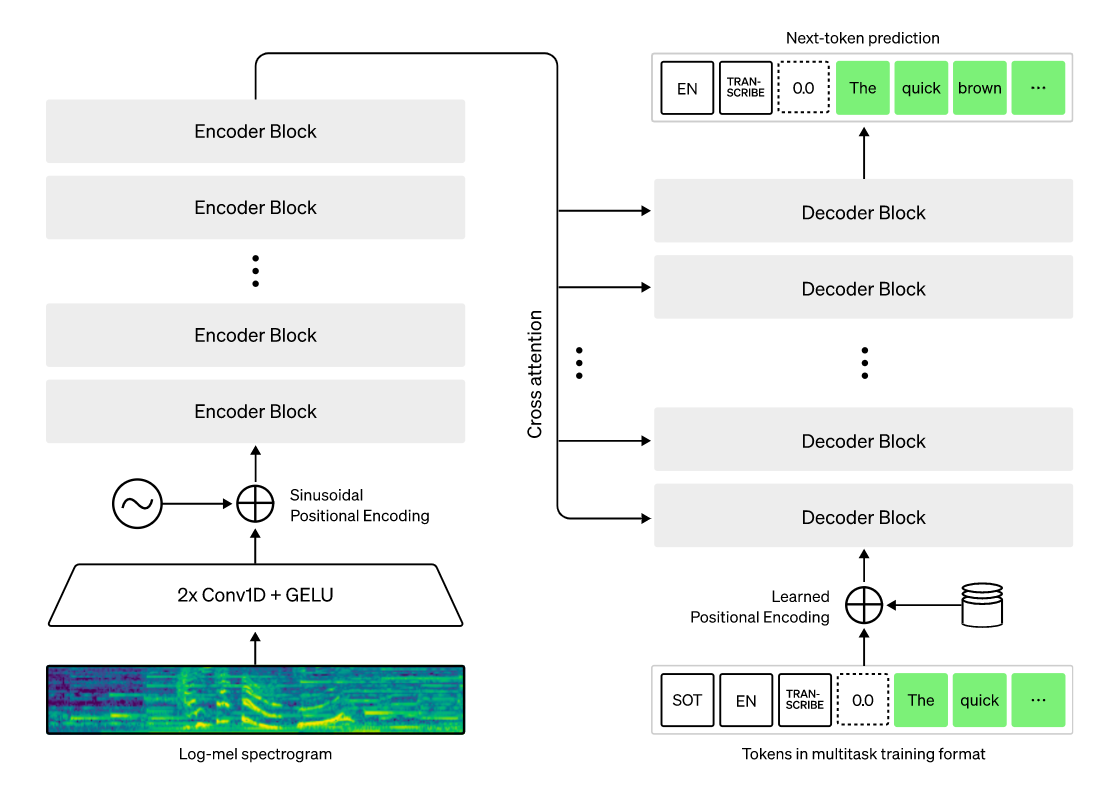
(画像引用:https://openai.com/blog/whisper/)
GitHub
使用例
使用方法は非常に簡単でパッケージをインストール後に4行のコードを記述するだけで良いです。ここでは試しにWhisperのsmallモデルを用いて、夏目漱石の小説『坊ちゃん』の冒頭を自分で音読したwavファイルを読み込ませてみました。「腰」が「星」に、「無闇」が「悩み」に、「特段」が「一段」になっていたりしますが非常に高い精度で文字起こしができています。ここではsmallモデルで文字起こしを試しましたが、largeモデルで文字起こしをすればより高い精度で文字起こしをすることができます。
# パッケージのインストール
!pip install -q git+https://github.com/openai/whisper.git
import whisper
model = whisper.load_model("small")
result = model.transcribe("sample.wav", verbose=False, language="ja")
print(result["text"])
実行結果
親譲りの無鉄砲で子供の時から 損ばかりしている
小学校にいる時 小学校の2階から飛び降りて1週間ほど星を
抜かしたことがある
なぜそんな悩みをしたと聞く人が あるかもしれぬ
一段深い理由でもない
実装コードURL
VOICEVOX
VOICEVOXは、2021年に公開されたテキスト読み上げソフトウェアで、テキストを指定することで、学習された声音声データを基に、合成音声を生成してテキストを読み上げてくれます。今回は、このVOICEVOXの機能をpython上で実行できる、voicevox_coreライブラリを利用しました。以下のような特徴/機能があります。
- 2022年12月時点でおよそ15種類もの豊富な読み上げ音声を使用可能
- 商用・非商用問わず無料で利用することが可能(ただし、クレジット表記は必要)
- 指定したテキストを読み上げる際にイントネーションの最適化が行われ、とても自然な読み上げが可能(個別にイントネーションの調整も可能)
公式ページ
GitHub
使用例
使用方法は、まず必要なパッケージをインストールし、コードの「text = 」の部分に読み上げたいテキストを記入し実行することで音声が再生されます。
# パッケージのインストール
!git clone https://github.com/VOICEVOX/voicevox_core -b 0.11.4
%cd voicevox_core
!python configure.py --use_gpu --voicevox_version 0.11.4
!pip install -r requirements.txt
!pip install -q .
!pip install -q pyopenjtalk
# パッケージのインストール
import librosa
import IPython
import sys
speacker_id = 0 # ここの番号を変えることで音声の種類を変更可能
text = "私があの有名なサンタクロースだ!"
!python example/python/run.py \
--text {text} \
--speaker_id {speacker_id} \
--f0_speaker_id 0 \
--f0_correct 0 \
--root_dir_path="./release" \
--use_gpu
# 音声再生関数
def sound():
audio_path = librosa.util.example_audio_file()
y_full, sr_full = librosa.load(f"{text}-{speacker_id}.wav")
return IPython.display.Audio(data = y_full, rate=sr_full, autoplay = True)
sound()
読み上げ結果の参考に、私が過去に作成した模擬面接アプリの動画を載せておきます(開始0:20あたりから再生すると読み上げ音声が聞けます)。こちらのアプリ内の音声はすべてVOICEVOXで作成しており、聞いていただけると一目(一耳?)瞭然ですが、非常に自然な読み上げ音声になっていることが分かると思います。
実装コードURL
BERT
BERT (Bidirectional Encoder Representations from Transformers)とは、2018年にGoogleから発表されたTranseformerと呼ばれるニューラルネットワーク構造の言語処理モデルであり、当時の様々な言語タスクにおいて最先端であったモデルの性能を大きく上回りました。以下のような特徴があります。
- 文脈を考慮した分散表現の生成が可能(word2vecでは文脈の考慮ができない)。
- 事前学習とファインチューニングの2つの学習過程があり、事前学習では汎用的な言語パターンの学習を、ファインチューニングでは特定のタスクに特化するような学習を実施
- 質疑応答、文章生成、文章分類など様々な言語タスクをこなすことが可能(対話ロボットの作成においては質疑応答タスクをBERTに行わせます)
BERTの詳細については、Yahoo! JAPAN Tech Blogの過去記事でも解説されているので興味があればご覧下さい。
なお、現在ではBERT以外にもTransformerをベースにした言語モデルが多数存在しており、一例としてRoberta、Deberta、GPT-3などがあります。
使用例
BERTの使用例については、後述の「BERTのファインチューニング」の項で説明します。
3.WhisperとVOICEVOXを用いた簡易ボイスチェンジャー
ここまでの説明でWhisper、VOICEVOX、BERTの概要が何となく理解できたかと思います。ここから対話ロボットの実装について説明していきたいところですが、ワンクッション挟んでここではまずWhisperとVOICEVOXだけを用いて簡易ボイスチェンジャーを作ってみたいと思います。ボイスチェンジャーの構成としては以下の図の通りです。
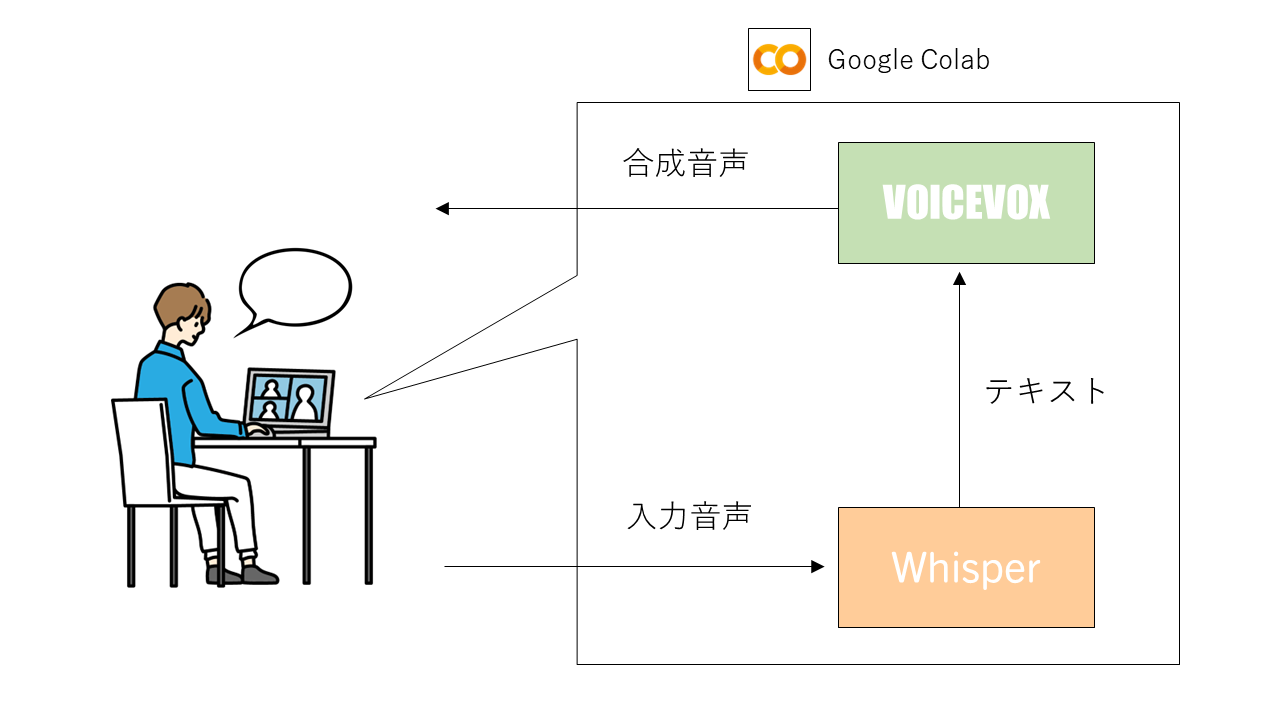
ローカルPCマイクのGoogle Colabへの入力
今回、対話ロボットはGoogle Colab(GPUが使用可能なクラウド開発環境)で実行するため、ローカルPCマイクにしゃべりかけた内容をColab側へ入力しなくてはいけません。そのためのコードは以下の通りです。
# ローカルPCマイクでの録音設定
from IPython.display import Javascript
from google.colab import output
from base64 import b64decode
RECORD = """
const sleep = time => new Promise(resolve => setTimeout(resolve, time))
const b2text = blob => new Promise(resolve => {
const reader = new FileReader()
reader.onloadend = e => resolve(e.srcElement.result)
reader.readAsDataURL(blob)
})
var record = time => new Promise(async resolve => {
stream = await navigator.mediaDevices.getUserMedia({ audio: true })
recorder = new MediaRecorder(stream)
chunks = []
recorder.ondataavailable = e => chunks.push(e.data)
recorder.start()
await sleep(time)
recorder.onstop = async ()=>{
blob = new Blob(chunks)
text = await b2text(blob)
resolve(text)
}
recorder.stop()
})
"""
def record(sec, filename='audio.wav'):
display(Javascript(RECORD))
s = output.eval_js('record(%d)' % (sec * 1000))
b = b64decode(s.split(',')[1])
with open(filename, 'wb+') as f:
f.write(b)
上記で定義したrecord関数を実行することでローカルPCマイクにしゃべりかけた内容が、Colab上に音声ファイルとして保存されます。この保存されたファイルをWhisperに読み込ませて文字起こしをします。
英単語のカナ文字への変換
Whisperで文字起こししたテキストをVOICEVOXで音声読み上げする際に、VOICEVOXでは英単語だと読み上げできないものがあります。例えば、英語の「Orange」という単語を読み上げさせようとすると「オー・アール・エー・エヌ・ジー・イー」とアルファベットを順番に読むだけになります。これを回避するために「alkana」というライブラリを用いて、英単語をカナ文字に変換する処理を加えました。
import MeCab
import unidic
import pandas as pd
import alkana
import re
import os
#半角英字判定
alphaReg = re.compile(r'^[a-zA-Z]+$')
def isalpha(s):
return alphaReg.match(s) is not None
sample_txt = result["text"]
wakati = MeCab.Tagger('-Owakati')
wakati_result = wakati.parse(sample_txt)
#print(wakati_result)
df = pd.DataFrame(wakati_result.split(" "),columns=["word"])
df = df[df["word"].str.isalpha() == True]
df["english_word"] = df["word"].apply(isalpha)
df = df[df["english_word"] == True]
df["katakana"] = df["word"].apply(alkana.get_kana)
dict_rep = dict(zip(df["word"], df["katakana"]))
for word, read in dict_rep.items():
sample_txt = sample_txt.replace(word, read)
具体的な処理としては、文字起こししたテキストをまずMecabで形態素解析し、トークンごとに英語かどうかを判定、英語判定されたトークンについてはalkanaで英単語からカナ文字に変換するように処理しています。
実装コードURL
動作デモ
このような形でこちらがしゃべった内容を合成音声の声に変換することができました。前述で実装した英語カナ変換も上手く機能しており、英単語をカナに変換して問題なく読み上げることができています。
4.BERTのファインチューニング
ここでは対話ロボット作成の準備として、BERTのファインチューニングを行います。対話ロボットを実現するために、しゃべりかけた問いに対して、回答が返ってこなくてはいけません。この質疑応答のタスクをBERTに担当させるために、日本語での質疑応答タスクについてファインチューニングを行います。ファインチューニングについても詳細に説明したいところですがとても長くなりそうなので今回ファインチューニングをするに当たり参考にしたnpakaさんの記事を紹介させていただきます。
動作確認
ファインチューニングを実施したBERTに対して質疑応答タスクを行わせてみました。
# Huggingface Transformersのインストール
!git clone https://github.com/huggingface/transformers
%cd transformers
!pip install -q .
# 日本語対応パッケージのインストール
!pip install -q fugashi[unidic-lite]
!pip install -q ipadic
# Huggingface Datasetsのインストール
!pip install -q datasets
from transformers import BertJapaneseTokenizer, AutoModelForQuestionAnswering
import torch
# 入力テキスト
context = "私の名前はサンタクロースです。 \
年齢は26歳です。 \
北海道に住んでいます。 \
昨日は東京に出かけました。 \
好きなイベントはヤフーアドベントカレンダーです。 \
好きな食べ物はケンタッキーフライドチキンです。 \
趣味はみんなにプレゼントを配ることです。 \
得意なプログラミング言語はパイソンです。 "
question_list = ["昨日はどこへ出かけましたか?",
"あなたの名前は何ですか?",
"あなたの趣味は何ですか?",
"あなたが好きなイベントは何ですか?",
"あなたが得意なプログラミング言語は何ですか?",
]
question = question_list[4]
# モデルとトークナイザーの準備
bert_model = AutoModelForQuestionAnswering.from_pretrained('/content/drive/MyDrive/talking_robot/transformers/output/') # Fine Tuningしたモデルpathを指定
tokenizer = BertJapaneseTokenizer.from_pretrained('cl-tohoku/bert-base-japanese-whole-word-masking')
# 推論の実行
inputs = tokenizer.encode_plus(question, context, add_special_tokens=True, return_tensors="pt")
input_ids = inputs["input_ids"].tolist()[0]
output = bert_model(**inputs)
answer_start = torch.argmax(output.start_logits)
answer_end = torch.argmax(output.end_logits) + 1
answer = tokenizer.convert_tokens_to_string(tokenizer.convert_ids_to_tokens(input_ids[answer_start:answer_end]))
# 結果出力
print("質問: "+question)
print(f"応答: {answer}です")
実行結果
質問: あなたが得意なプログラミング言語は何ですか?
応答: パイソンです
いかがでしょうか?このように質問をテキストで投げかけることで、contextにて付与した情報に基づき回答をしてくれるようになりました。これで対話ロボットの質疑応答エンジンが完成しました。
5.Whisper、BERT、VOICEVOXを用いた対話ロボット
ファインチューニングしたBERTも準備できたので、ここから対話ロボットを実装していきます。実は実装はとても簡単で、先ほど作成した簡易ボイスチェンジャーのWhisperとVOICEVOXの間にファインチューニングしたBERTを挿入すれば完成します(図は再掲)。
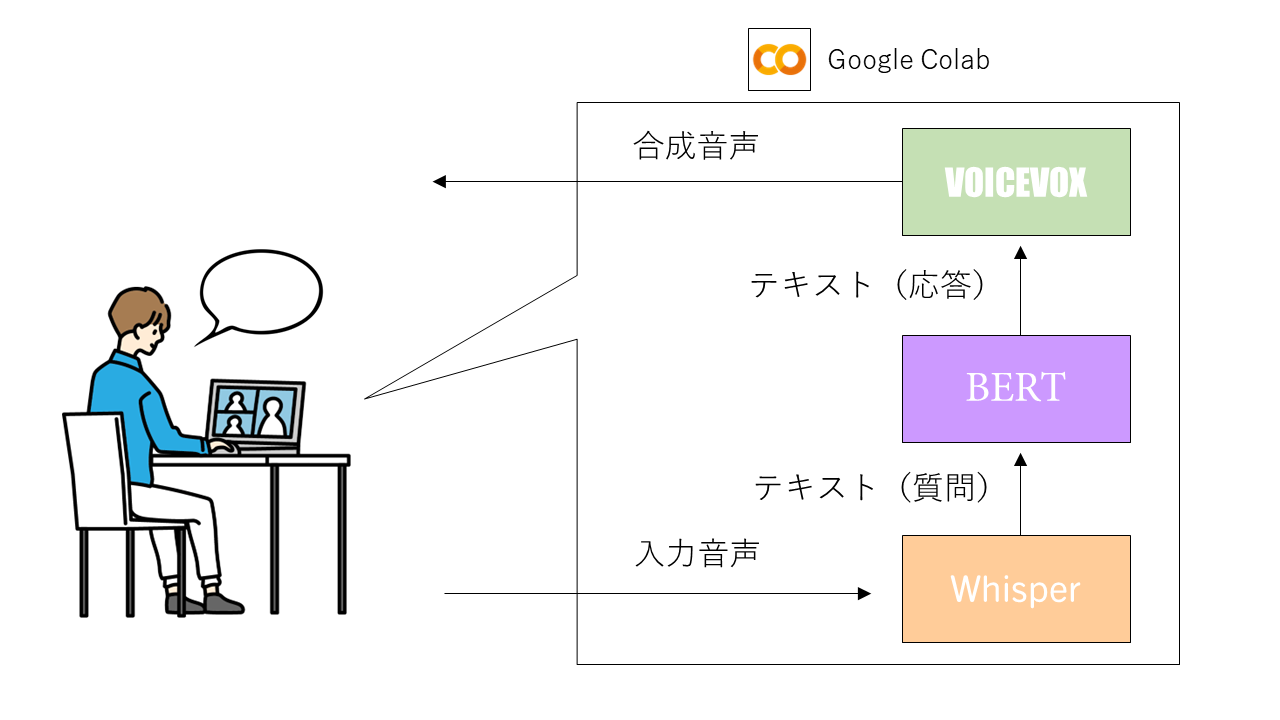
実装コードURL
動作デモ
いかがでしょうか?こちらの問いかけに対して対話ロボットが見事に返事をしてくれています。 しゃべりかけてからレスポンスがあるまでの処理時間がちょっと長いですが細かいことは気にしないで下さい。
6.作ってみた感想と課題
- 今回対話ロボットを作成しましたが、音声入力、質疑応答、音声出力までをエンド―・ツー・エンドですべてオープンソースのAIを用いて実現することでき(GPUマシンは必要ですが)、アイディアさえあればいくらでも面白いものを作ることができることを確認できました。
- 今回はcontextにあらかじめ与えた情報に対して対話ロボットが回答するまでとなりましたが、質疑応答エンジンを自前の対話エージェントや、OpenAI APIで利用できるGPT-3(有料)、rinna社のCharacter Conversation API(利用料不明)などを使えば、自由な会話ができる対話ロボットを作成することも可能だと思います。
- いくつものモデルを挟んでいるため、 しゃべりかけてから応答があるまでになかなか時間がかかることが課題だと思いました。 Whisperで使うモデルをlargeモデルとかではなく、小さめのbaseモデルを用いることでもう少しレスポンスを早くできると思います。
7.オープンソースAI、対話ロボットの展望
おまけ的な話ですが今回用いたAIや、これらを組み合わせて実装した対話ロボットをどんなことに活用できそうか勝手に妄想してみました。
・WEBニュース記事の音声読み上げサービス
私は何か作業をしているときにWEBニュース記事をラジオ感覚で聴けたらいいのに...と思うことがたまにありますが、膨大な記事をあらかじめ人に音読してもらい録音するのは現実的ではありません。今回用いた対話ロボット(特にVOICEVOXの部分)を活用すれば、WEBニュース記事のテキストをAIに読み上げさせることができ、WEBニュースラジオみたいなサービスも実現できるのではないかと思いました(ニュース媒体がWEBニュース記事をYouTube Liveで延々とAIに読み上げさせる、みたいなサービスも面白いかもしれないですね)。
・メンタルヘルスケアロボット
数年前よりは落ち着いてきましたが、まだ日本ではコロナ禍は完全収束しておらず、コロナ禍前のように人とのコミュニケーションができない状況が続いています。このような世の中なので、対話することで人のメンタルをケアするようなサービスにもニーズがあるかもしれません(AIとチャットするサービスはありますが、直接対話するサービスというのはあまり聞いたことがないです)。もし、ロボットと直接対話するようなサービスを開発するときには今回用いたオープンソースのAIも大いに役立ちそうです。
9.おわりに
本記事ではオープンソースで使用できるAIを活用して、物理的に会話することができる対話ロボットを作成しました。質疑応答エンジンとして簡易にファインチューニングしたBERTを用いましたが、この部分をより高度なモデルに差し替えることでより自由な会話のできる対話ロボットを作れると思います。
今回は、Whisper、VOICEVOX、BERTのみを用いましたが例えば、ここに画像生成AIであるStable Diffusionを加えれば、対話ロボットのアイコン画像を言葉でしゃべりかけて生成させる、といったことも可能だと思います。
アイディアさえあれば可能性は無限大ですので、是非皆さんもオープンソースのAIを用いて何かモノづくりに挑戦してみてはいかがでしょうか。
Yahoo! JAPAN Advent Calendar 2022
最後に宣伝です。今回私は参加できていないですが、私の所属している会社のアドベントカレンダーが絶賛開催中です。興味があれば是非こちらも覗いてみて下さい!
参考文献/記事
Introducing Whisper
Google Colab ではじめる VOICEVOX
Huggingface Transformers 入門 (14) - 日本語の質問応答の学習
Google Colab上で音声を録音するサンプル
クレジット
読み上げ音声 VOICEVOX:四国めたん