はじめに
こんにちは!
ビジネスエンジニアリング株式会社の髙橋と申します!
本記事は、
ビジネスエンジニアリング株式会社 Advent Calendar 2025
12日目の記事となります。
社会人3年目のエンジニアで、2025年12月1日~5日にラスベガスで開催された「AWS re:Invent 2025」というイベントに参加してきました!
(イベントの雰囲気や体験記は11日目の記事で紹介しています)
数あるセッションの中で、特に「アーキテクチャの考え方が変わった」と感じたワークショップ「Build a web-scale application with purpose-built databases & analytics (DAT405)」での学びを共有します。
ワークショップについて
このワークショップは、AWS公式のハンズオン形式のセッションで、実際にEコマース書店アプリケーションを構築しながら、複数のデータベースを組み合わせる設計パターンを学べる内容になっています。
ワークショップカタログ:
Build a web-scale application with purpose-built databases & analytics
本記事では、このワークショップで扱った技術的な内容を日本語で要約し、特に「なぜそのデータベースを選んだのか?」という選定理由に焦点を当てて解説します。
このワークショップの題材は「Eコマース書店アプリケーション」なのですが、なんとこのアプリ、裏側で5種類ものデータベースを使い分けています。
「RDB一本でなんでもやる」のではなく、データの性質やアクセスパターンに合わせて最適なDBを選ぶ「Polyglot Persistence(ポリグロット・パーシステンス)」の実装パターンが非常に勉強になったので、「なぜそこでそのDBを選んだのか?」という選定理由に焦点を当てて解説します。
Polyglot Persistenceとは?
複数の異なる種類のデータベース技術を組み合わせて使用するアーキテクチャパターンのこと。
各データベースの強みを活かし、弱みを補完することで、システム全体の性能と柔軟性を最大化します。
作成したアプリケーションの構成
今回構築した「AWS Bookstore Demo App」のアーキテクチャは以下の通りです。
- フロントエンド: React (S3 + CloudFront)
- バックエンド: API Gateway + Lambda
- データベース: DynamoDB, Neptune, ElastiCache, OpenSearch, Aurora
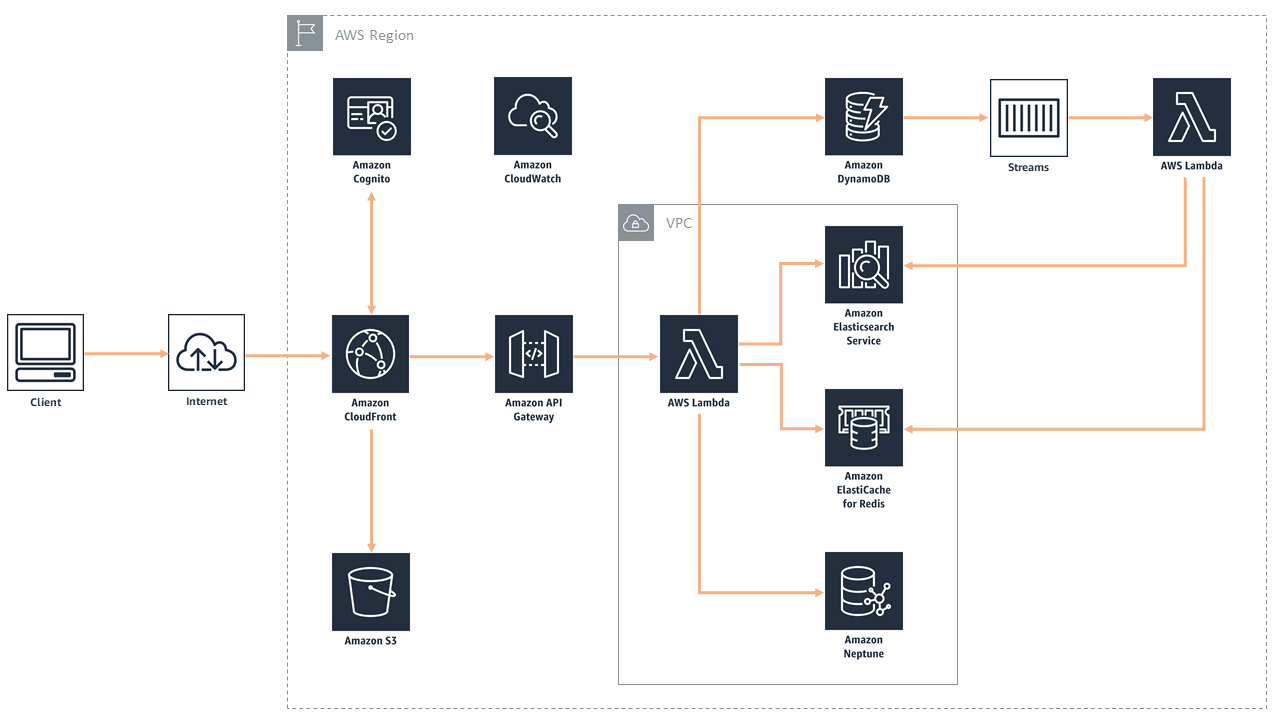
※図には記載がありませんが、注文処理フローには Amazon Aurora が組み込まれています。
フロントエンドからAPI Gateway経由でLambdaが呼ばれ、Lambdaが各機能に特化したデータベースを叩くという構成です。API Gateway、Lambda、DynamoDB、Neptune、ElastiCache、OpenSearchといったサーバーレスサービスを中心に、注文処理にはマネージドRDBのAurora PostgreSQLを組み合わせています。
(出典: aws-samples/aws-bookstore-demo-app)
では、なぜ5つもDBが必要だったのでしょうか?機能ごとに見ていきます。
データベース選定早見表
各機能に対してどのデータベースを選んだのか、一覧で確認できます。
| 機能 | 採用DB | 選定理由 |
|---|---|---|
| 商品カタログ | DynamoDB | ID指定の高速取得 |
| レコメンデーション | Neptune | つながりの探索 |
| ベストセラーランキング | ElastiCache | リアルタイム集計 |
| 全文検索 | OpenSearch | あいまい検索 |
| 注文処理 | Aurora | トランザクション管理 |
1. 商品カタログ:Amazon DynamoDB
書籍のタイトル、著者、価格などの詳細情報を表示する機能です。
💡 なぜDynamoDB(キー・バリュー型)なのか?
ここでのアクセスパターンは、「商品ID(bookId)を指定して、その本の情報を取得する(GetItem)」という非常にシンプルなものです。
選定理由:
- 単純なKey-Valueの読み書きにおいて、データ量がどれだけ増えてもミリ秒単位の安定した低レイテンシを実現するため
- RDBのような複雑な結合は不要であり、スキーマレスな柔軟性もメリットになります
2. レコメンデーション:Amazon Neptune
「あなたの友達が購入した本」や「この本を買った人はこんな本も買っています」といった推奨機能です。
💡 なぜNeptune(グラフDB)なのか?
ここで扱いたいのは、ユーザー間の「友人関係(friendOf)」や、ユーザーと商品の「購入関係(purchased)」といった「つながり」です。
選定理由:
- RDBで「友達の友達が買った本」を探そうとすると、中間テーブルを何度もJOIN(結合)する必要があり、データ量が増えるとクエリが急速に重くなります
- グラフデータベースであれば、ノード間のエッジを辿る(Traverse)だけで済むため、結合なしで高速に探索できます
実装コード例(Gremlinクエリ):
// ユーザー(userId)の友達が購入した本を集計してトップ10を返す
g.V(userId)
.out('friendOf') // 友達を辿る
.out('purchased') // 購入した本を辿る
.groupCount() // 集計
.order(local).by(values, desc)
.limit(10)
3. ベストセラーランキング:Amazon ElastiCache for Redis
売上の多い書籍トップ20をリアルタイムに近い速度で表示する機能です。
💡 なぜElastiCache(インメモリDB)なのか?
ランキングは頻繁にアクセスされるコンテンツですが、毎回データベース全体を集計するのは非効率です。
選定理由:
- ディスクI/Oを伴わないメモリ上での処理により、圧倒的な速度が出せます
- Redisの「ソート済みセット(Sorted Set)」というデータ構造を使えば、スコア(販売数)に基づく順位付けを自動で維持してくれるため、アプリケーション側で並び替え処理を書く必要がありません
実装コード例(Redisコマンド):
# bestsellersキーからスコアの高い順に20件取得
ZRANGE bestsellers 0 19 REV WITHSCORES
※ ZRANGE ... REV 構文はRedis 6.2.0以降で使用可能です。それ以前のバージョンでは ZREVRANGE bestsellers 0 19 WITHSCORES を使用してください。
詳細はRedis ZRANGEコマンド公式ドキュメントを参照。
4. 全文検索:Amazon OpenSearch Service
タイトル、著者、カテゴリなどのキーワードで書籍を検索する機能です。
💡 なぜOpenSearch(検索エンジン)なのか?
DynamoDBも検索はできますが、「完全一致」や「前方一致」など単純なものに限られます。
選定理由:
- ユーザーは「あいまいな記憶」で検索したり、著者名とタイトルを混ぜて検索したりします
- DynamoDBのようなキーバリュー型のNoSQLデータベースでは実装が難しい「あいまい検索(Fuzzy Search)」や、複数フィールドにまたがる関連度順の検索を実現するには、専用の検索エンジンが最適です
補足: OpenSearchは厳密には「データベース」ではなく「検索エンジン」ですが、データを保存・検索する役割を担うため、本記事ではデータストアの一種として扱っています。
実装コード例(検索クエリ):
{
"query": {
"multi_match": {
"query": "入力されたキーワード",
"fields": ["name", "author", "category"] // 複数項目を横断検索
}
}
}
5. 注文処理:Amazon Aurora PostgreSQL
カートに入れた商品の購入を確定し、注文履歴を管理する機能です。
💡 なぜここだけAurora(RDB)なのか?
カタログや検索にはNoSQLを使いましたが、注文処理は「お金」に関わる業務です。
選定理由:
- 在庫の引き落としと決済処理など、複数のデータ更新を「すべて成功するか、すべて失敗するか」で管理するトランザクション管理(ACID特性)が不可欠だからです
- 注文(Order)と注文明細(Order Items)のような、厳格な構造化データのリレーション管理には、やはりRDBが最も適しています
まとめ:万能なDBを探すのをやめよう
今回のワークショップを通じて学んだのは、「万能なデータベースを探すのではなく、アクセスパターンに合わせてDBを使い分ける」というアプローチの重要性です。
- 単純なID検索なら DynamoDB
- つながりの探索なら Neptune
- ランキングなら ElastiCache
- あいまい検索なら OpenSearch
- 堅牢なトランザクションなら Aurora
一見、構成が複雑に見えるかもしれませんが、各DBの手前にLambdaがいることで、アプリケーション(フロントエンド)からは裏側のDB構成を意識せずにAPIを叩くだけで済むようになっています。この「接着剤」としてのサーバーレスの使い方も非常に参考になりました。
本記事で紹介したアプリケーションのソースコードは、AWS公式のGitHubで公開されています。興味のある方はぜひ覗いてみてください。
参考リンク
- ワークショップカタログ: Build a web-scale application with purpose-built databases & analytics
- ワークショップで使用したアプリケーションのソースコード: aws-samples/aws-bookstore-demo-app
- NoSQLデータベースサービスの公式ページ: Amazon DynamoDB
- グラフデータベースサービスの公式ページ: Amazon Neptune
- インメモリデータストアサービスの公式ページ: Amazon ElastiCache
- 検索エンジンサービスの公式ページ: Amazon OpenSearch Service
- リレーショナルデータベースサービスの公式ページ: Amazon Aurora
- AWSのデータベースサービス一覧: Purpose-Built Databases on AWS
- Redis ZRANGEコマンドの公式ドキュメント: ZRANGE | Redis