この記事について
ブラウザ操作をLambdaで自動化したいのですが、調べてみたらSeleniumを利用すればできそうです。
LambdaとSeleniumを利用して、快適なサーバレススクレイピング環境を作る手順を記載します。
事前知識
AWS Lambdaとは
サーバレスで関数(プログラム)を実行することができるAWSサービスです。
EC2などのコンピューティングリソースを使用せずに、実行したい時にプログラムを実行させることができます。
利用料金は関数の実行回数に依るため、利用料金が時間単位であるEC2などを利用する場合に比べて大幅にコストを下げることが可能です。(実行回数が多すぎる場合は、EC2よりも割高になってしまうケースもあるかもしれません)
他のAWSサービスから呼び出すことも可能であり、連携性が非常に高いです。
Seleniumとは
ブラウザ操作をプログラムで自動化することができるツール(ライブラリ)です。
ChromeやFirefoxなどの主要なブラウザは一通りサポートしています。
Seleniumの実行モードには2つのモードがあります。
| モード | 説明 |
|---|---|
| Headfulモード | Seleniumを実行した際にブラウザが実際に立ち上がるモードです。ブラウザがどのように遷移しているかといった動き確認できます。 |
| Headlessモード | バックグランドでSeleniumが実行されます。ブラウザは表示されません。そのため、何が起きているか分かりにくいというデメリットはありますが、処理が高速でありGUIがない環境でも実行することができます。 |
LambdaにてSeleniumを実行するためには、Headlessモードで実行する必要があります。
前提
- AWSアカウントにアクセスできる
- AWS CLIが利用可能
- SAM CLIが利用可能
やること
- ① LambdaにてSeleniumをHeadlessモードで実行できるようにする
- ② AWS SAMを利用したIaC (Infrastructure as Code)
- ③ ローカルでテストしやすいようにする(Headfulモード)
① LambdaにてSeleniumをHeadlessモードで実行できるようにする
LambdaのPythonスクリプトでSeleniumをHeadlessモードで実行できるようにします。
SeleniumなどのライブラリはLambdaレイヤーにする必要があるため、その作成も必要になります。
後述しますが、Selenium関連パッケージのバージョンの互換性がとてもややこしいです。
バージョンが違うと動かないので、注意しましょう。
② AWS SAMを利用したIaC (Infrastructure as Code)
Lambda関数やレイヤーをSAMでコード管理できるようにします。
コード管理しておくと他の人にも使ってもらいやすくなりますし、Gitで管理すれば変更管理などもしやすいです。
③ ローカルでテストしやすいようにする(Headfulモード)
Healessモードは動作が高速ですが、ブラウザが見えないためどのように動いているか確認しにくいです。
実際にLambdaでSeleniumを利用したプログラムを作成する際は
[1] テストして問題なく動いていることを確認
[2] Lambdaにデプロイ
という流れになるかと思います。
[1]のテストをローカルにてHeadfulモードで行うことができれば、プログラム作成の効率が高くなると思います。
注意事項
Seleniumパッケージのバージョン互換性について
本手順において以下のパッケージを利用します。
- selenium
- serverless-chrome
- chrome-driver
これらのバージョンには互換性があり、互換性がないバージョンだとLambda上で動いてくれません。そのため、利用するバージョンに十分注意する必要があります。
serveless-chromeとchrome-driverはバージョンを指定することができます。しかし、seleniumはpipでダウンロードする場合、インストールするプラットフォームに依存するパッケージがダウンロードされます。つまりLambda上で動くパッケージを入手しなくてはいけません。
Macなどで直接pipでseleniumをダウンロードしても、lambdaで動くパッケージはダウンロードされません。そのためdockerを利用して、lambdaで動くパッケージをダウンロードするという一工夫が必要になります。
手順 : ① LambdaにてSeleniumをHeadlessモードで実行できるようにする
Lambdaレイヤー作成の準備
SeleniumなどのライブラリはLambdaレイヤーにして関数から呼び出すことで利用することができます。
ここではそれらレイヤー作成の準備を行います。
ちなみにLambdaレイヤーでは以下いずれかのディレクトリ配下であれば、自動的にファイルを読み込んでくれます。
・python
・python/lib/python3.x/site-packages
※3.xは使用するpythonのバージョンです
Seleniumのダウンロード
Seleniumをダウンロードするときはpipコマンドを利用します。
その際にダウンロードされるSeleniumは、その環境で実行可能なものになります。つまりLambdaで実行するためには、Lambdaで実行可能なものをダウンロードする必要があります。
Mac環境などでダウンロードすると、Lambdaで実行することができないものがダウンロードされてしまうので、Dockerを利用してLambdaで実行可能なファイルをダウンロードします。
Lambda環境を模倣したlambci/lambdaというDockerイメージを利用します。
(このイメージですが、build-python:3.6でないとダメです。今回LambdaのランタイムはPython3.7ですが、このイメージのbuild-python:3.7を利用してしまうと互換性がなくなってしまいます。)
Dockerfileを作成します。
FROM lambci/lambda:build-python3.6
WORKDIR /work
CMD pip install --upgrade pip && \
pip install selenium -t /python/lib/python3.7/site-packages && \
zip -r selenium.zip /python/
以下を実行して、seleniumをダウンロードします。
> docker build -t selenium .
> docker run -v "${PWD}":/work selenium
selenium.zipファイルが作成されます。
❯ ls
Dockerfile selenium.zip
headless-chromiumとchromedriverのダウンロード
headless-chromiumをダウンロードします。
> mkdir -p python/bin/
> curl -SL https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-37/stable-headless-chromium-amazonlinux-2017-03.zip > headless-chromium.zip
> unzip headless-chromium.zip -d python/bin/
> rm headless-chromium.zip
続けて、chromedriverをダウンロードします。
> curl -SL https://chromedriver.storage.googleapis.com/2.37/chromedriver_linux64.zip > chromedriver.zip
> unzip chromedriver.zip -d python/bin/
> rm chromedriver.zip
ダウンロードしたパッケージをZipに圧縮します。
❯ zip -r chromedriver.zip python
❯ rm -rf python
❯ ls
Dockerfile chromedriver.zip selenium.zip
Lambdaレイヤーの作成
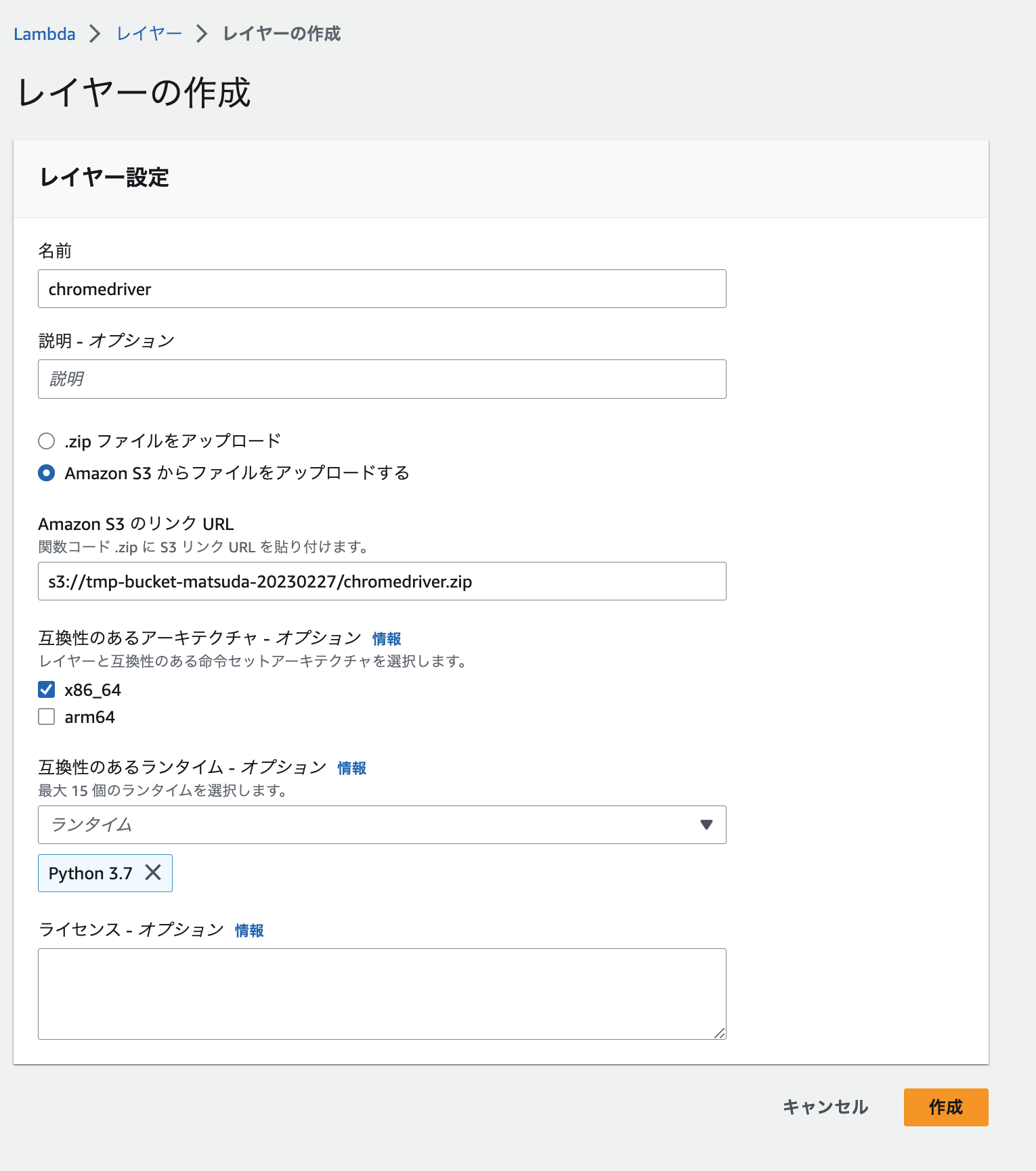
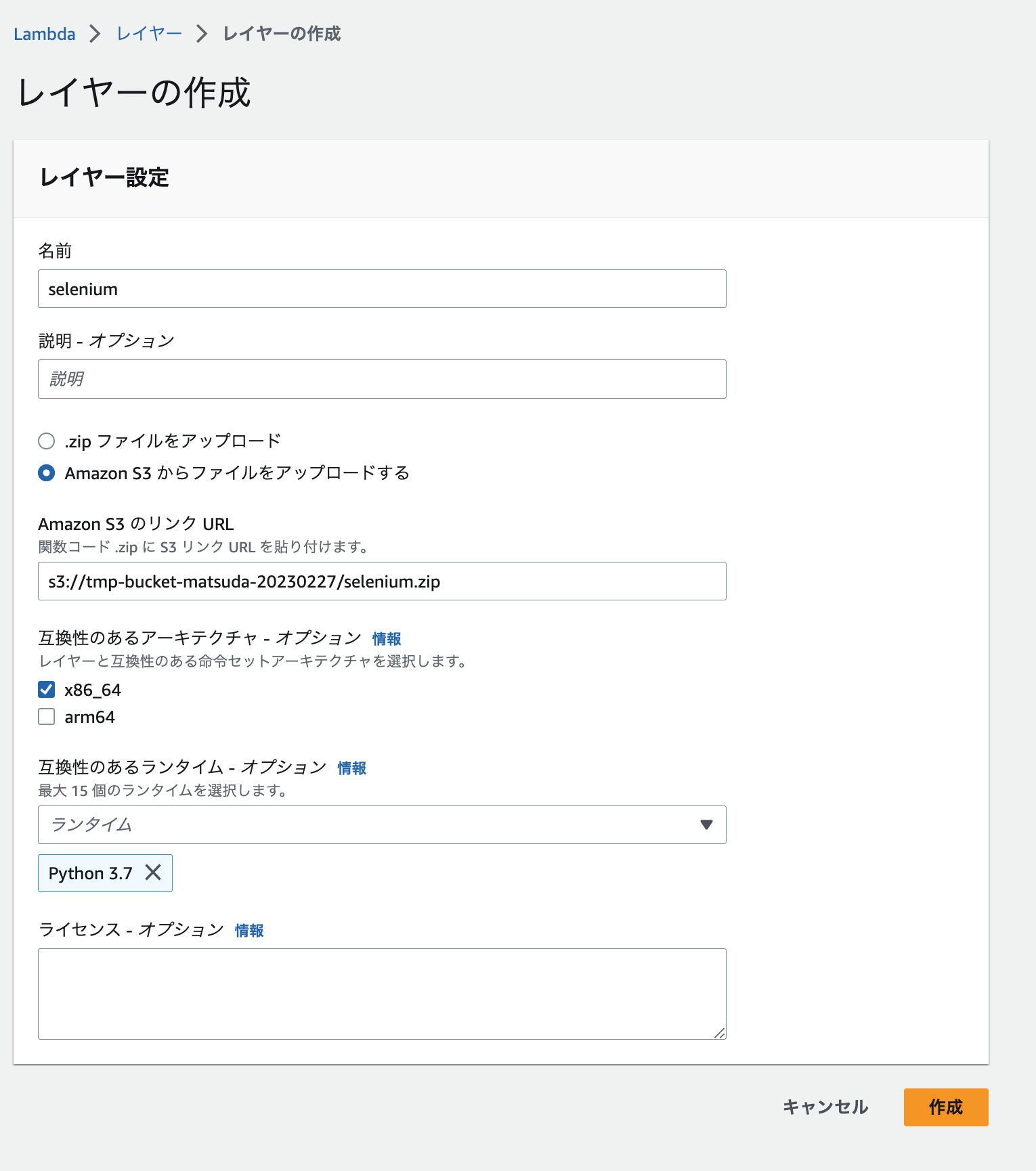
chromedriver.zipとselenium.zipはLambdaレイヤーを作成する際に利用します。Lambdaレイヤーを作成する際は直接ファイルをアップロードするより、S3から読み込ませる方が楽です。
そのため、適当なS3バケットを作成して、そこのzipファイルをアップロードします。
❯ aws s3 cp selenium.zip s3://tmp-bucket-matsuda-20230227/
❯ aws s3 cp chromedriver.zip s3://tmp-bucket-matsuda-20230227/
❯ aws s3 ls s3://tmp-bucket-matsuda-20230227/
2023-03-18 16:23:48 46335228 chromedriver.zip
2023-03-18 16:23:39 1389024 selenium.zip
S3にファイルをアップロードできたら、レイヤーを作成します。
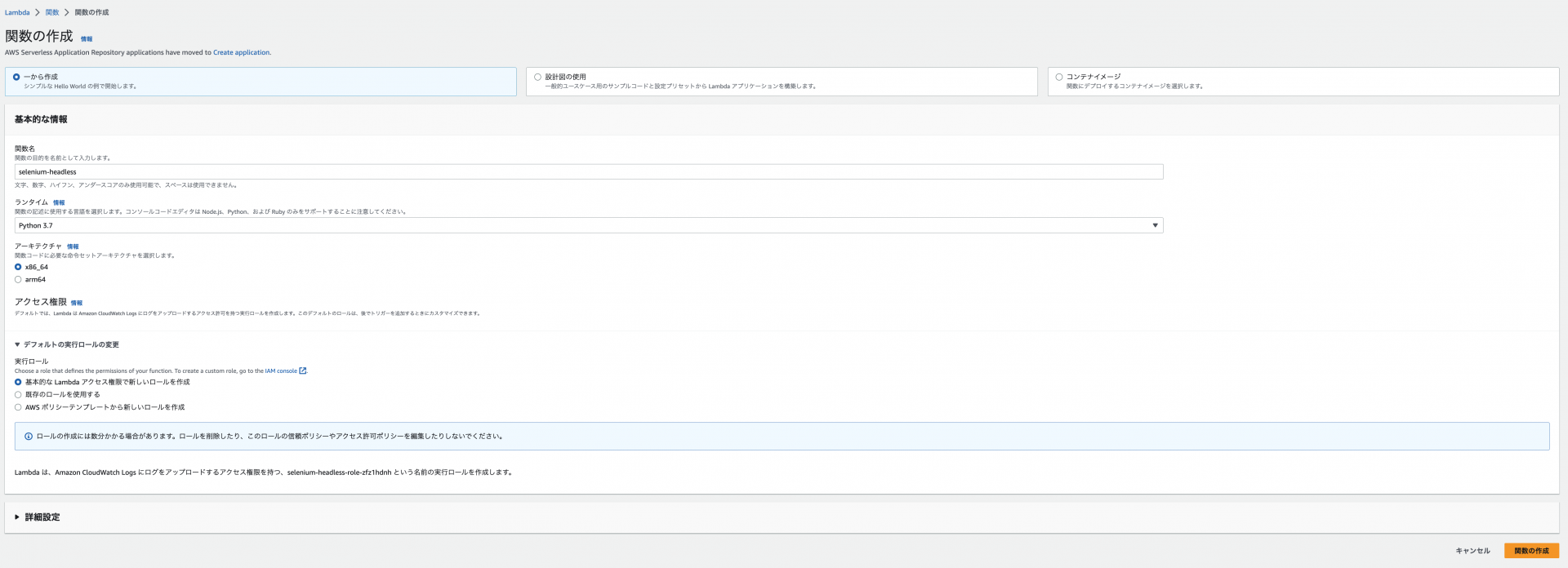
Lambda関数の作成
続いて関数を作成します。
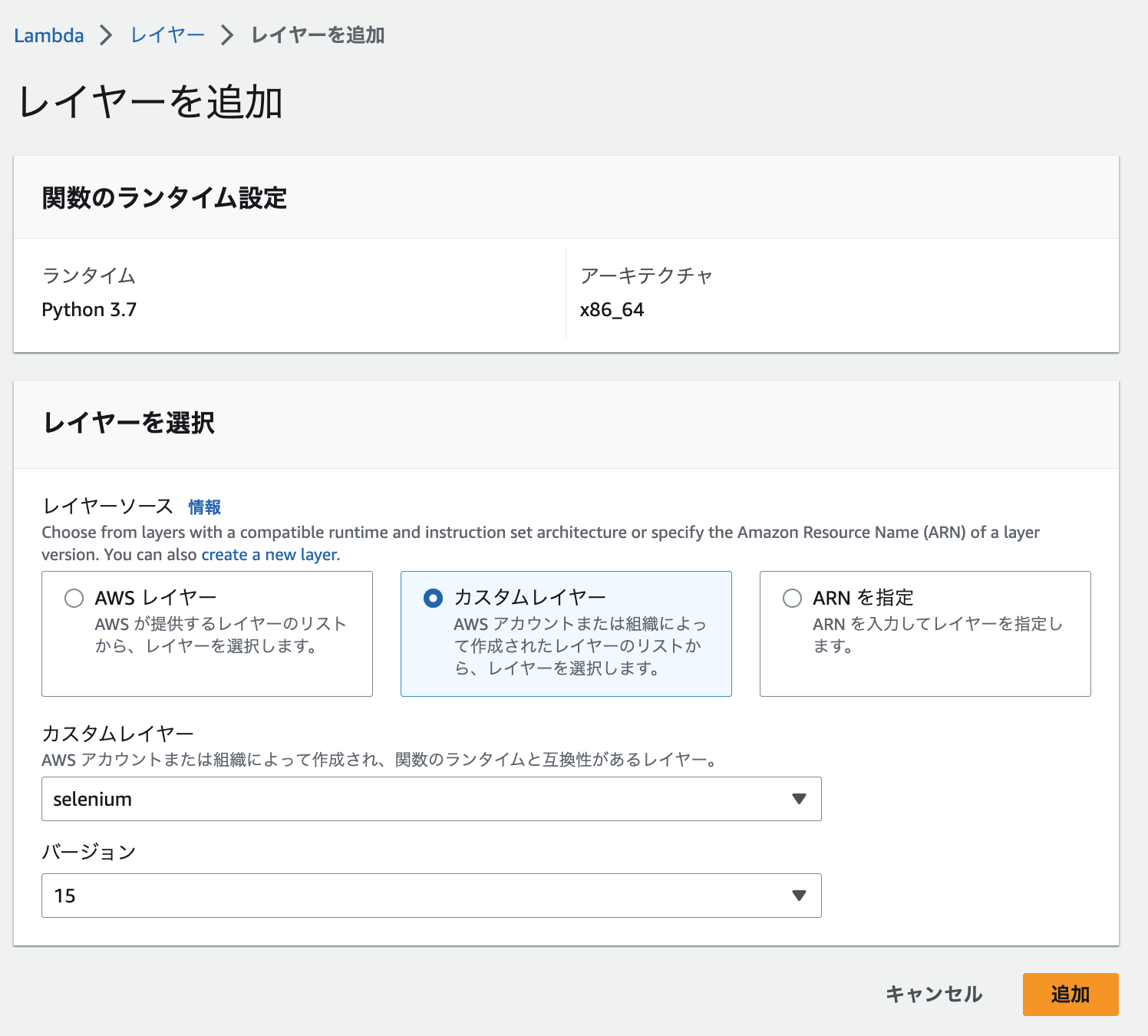
先ほど作成したレイヤー seleniumとchromedriverを追加します。
(バージョンは私が色々試している内にインクリメントされてしまったので、気にしないでください)
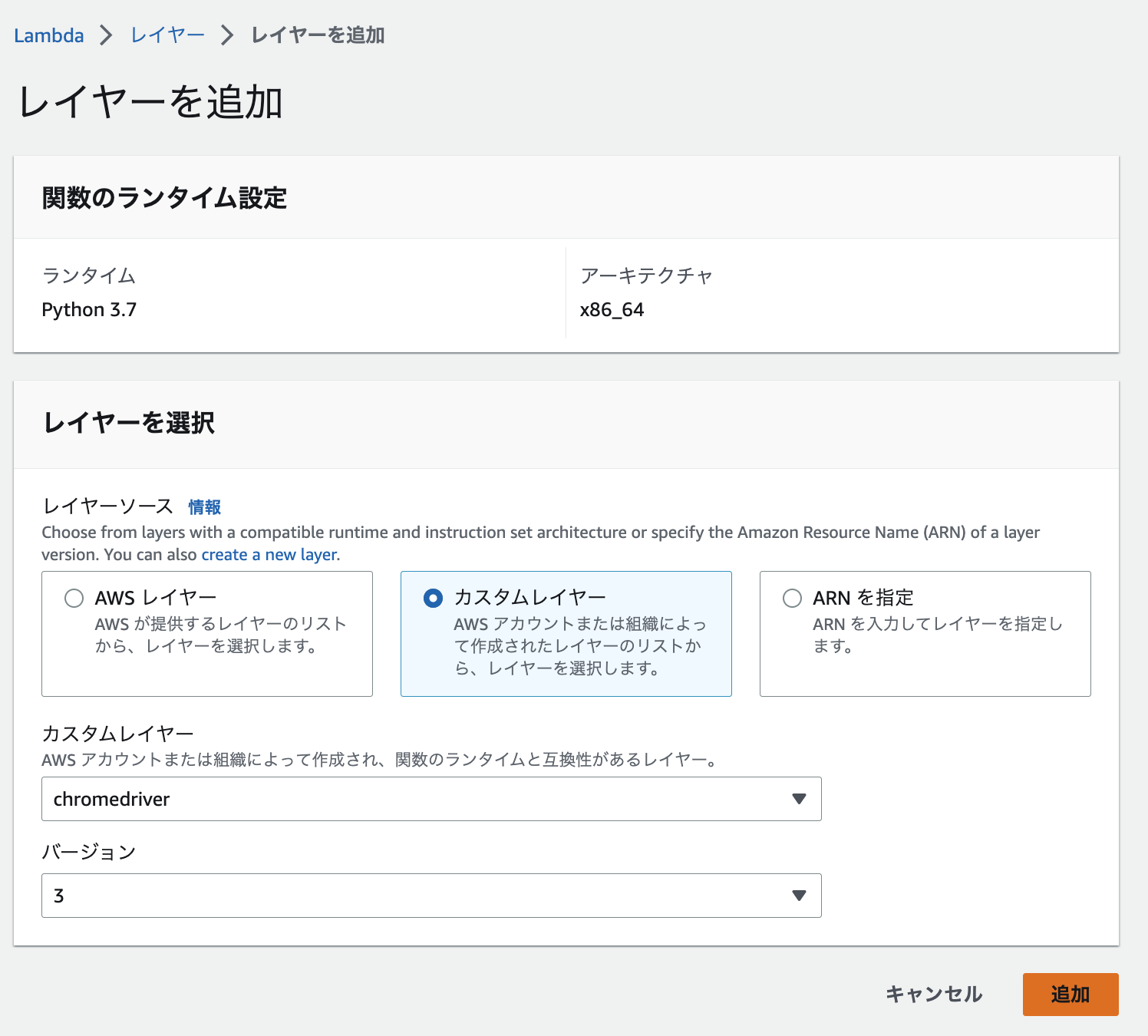
以下のコードを入力して、デプロイします。
from selenium import webdriver
def lambda_handler(event, context):
URL = "https://news.yahoo.co.jp/"
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument("--hide-scrollbars")
options.add_argument("--single-process")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--window-size=880x996")
options.add_argument("--no-sandbox")
options.add_argument("--homedir=/tmp")
options.binary_location = "/opt/python/bin/headless-chromium"
#ブラウザの定義
browser = webdriver.Chrome(
"/opt/python/bin/chromedriver",
options=options
)
browser.get(URL)
title = browser.title
browser.close()
return title
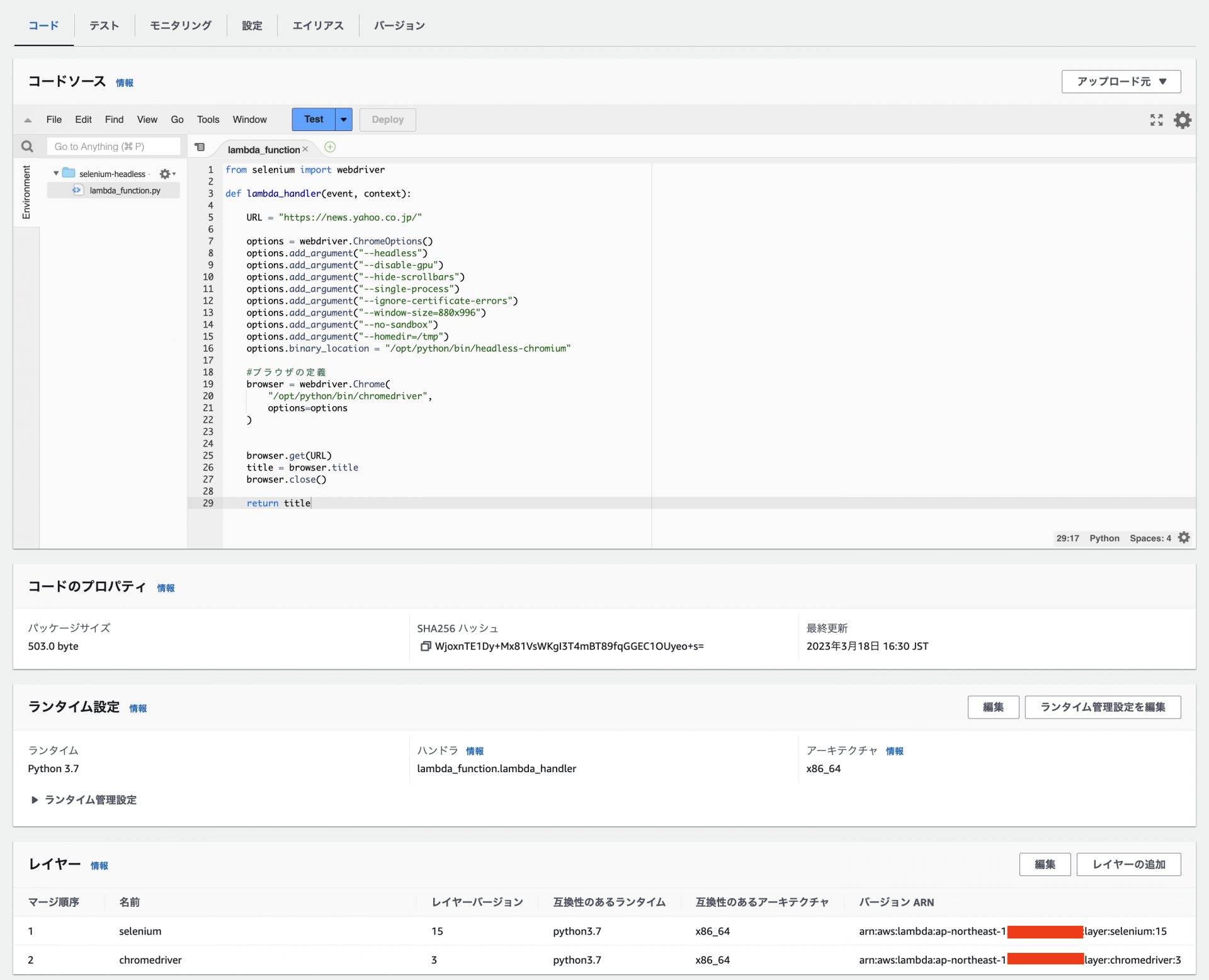
追加で以下の設定を行います。
- メモリを512MBに
- タイムアウトを5分に

動作確認
関数を実行したら、以下のようにyahooニュースのタイトルが出力されます。
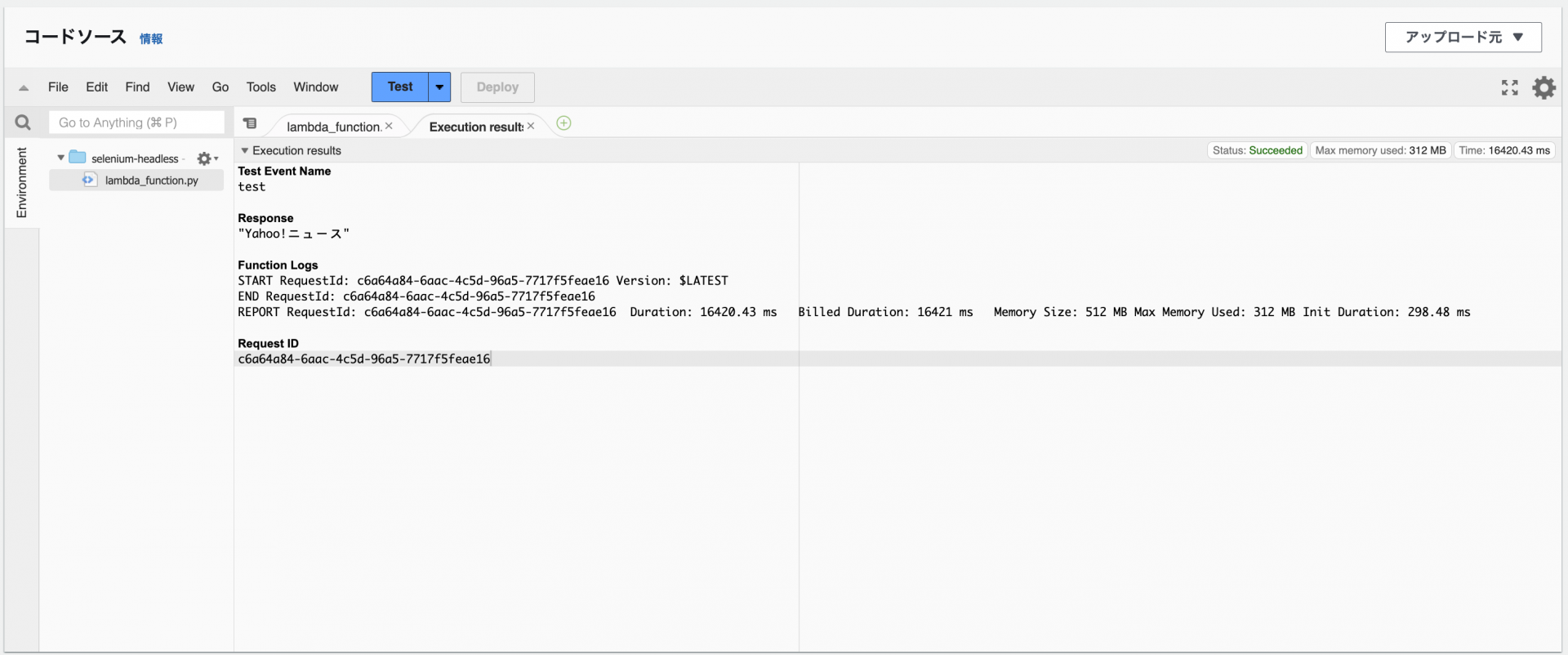
これでLambdaにてSeleniumをHeadlessモードで動かすことができるようになりました。
あとはLambdaのコードをカスタマイズすれば、好みの操作を行うことができます。
手順:② AWS SAMを利用したIaC (Infrastructure as Code)
SAMプロジェクトの作成
オプションでランタイムをpython3.7に指定します。
❯ sam init --runtime python3.7
Quick Start TemplatesのHello World Exampleを選択します。(API Gatewayなどもテンプレートに含まれてしまいますが、後ほど削除します。)
Which template source would you like to use?
1 - AWS Quick Start Templates
2 - Custom Template Location
Choice: 1
Choose an AWS Quick Start application template
1 - Hello World Example
2 - Infrastructure event management
3 - Multi-step workflow
4 - Serverless Connector Hello World Example
5 - Multi-step workflow with Connectors
Template: 1
x-rayは使いません。
Would you like to enable X-Ray tracing on the function(s) in your application? [y/N]: N
プロジェクト名は任意です。
Project name [sam-app]: selenium-headless
作成した直後のプロジェクトは以下のファイル構成になっています。
❯ tree selenium-headless
selenium-headless
├── README.md
├── __init__.py
├── events
│ └── event.json
├── hello_world
│ ├── __init__.py
│ ├── app.py
│ └── requirements.txt
├── template.yaml
└── tests
├── __init__.py
└── unit
├── __init__.py
└── test_handler.py
不要なファイルを削除します。
❯ rm -rf selenium-headless/__init__.py selenium-headless/events selenium-headless/tests selenium-headless/hello_world
❯ tree selenium-headless
selenium-headless
├── README.md
└── template.yaml
SAMプロジェクトのカスタマイズ
テンプレートファイルを以下のように修正します。
詳しくは説明しませんが、① LambdaにてSeleniumをHeadlessモードで実行できるようにするにて作成したレイヤー2つと、関数1つを定義しています。
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
selenium-headless
Sample SAM Template for selenium-headless
Globals:
Function:
Timeout: 300
Resources:
SelenumHeadlessFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: function/selenium-headless/
Handler: lambda_function.lambda_handler
Runtime: python3.7
Architectures:
- x86_64
MemorySize: 512
Layers:
- !Ref SeleniumLayer
- !Ref ChromedriverLayer
SeleniumLayer:
Type: AWS::Serverless::LayerVersion
Properties:
Description: selenium Layer
ContentUri: layer/selenium.zip
CompatibleRuntimes:
- python3.7
Metadata:
BuildMethod: python3.7
ChromedriverLayer:
Type: AWS::Serverless::LayerVersion
Properties:
Description: chrome driver Layer
ContentUri: layer/chromedriver.zip
CompatibleRuntimes:
- python3.7
Metadata:
BuildMethod: python3.7
① LambdaにてSeleniumをHeadlessモードで実行できるようにするにて作成したchromedriver.zipとselenium.zipをプロジェクトディレクトリに加えます。
❯ mkdir selenium-headless/layer
❯ mv chromedriver.zip selenium-headless/layer
❯ mv selenium.zip selenium-headless/layer
lambda関数用のディレクトリを作成します。
❯ mkdir selenium-headless/function/selenium-headless
以下のファイルを関数用のディレクトリに追加します。
from selenium import webdriver
def lambda_handler(event, context):
URL = "https://news.yahoo.co.jp/"
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument("--hide-scrollbars")
options.add_argument("--single-process")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--window-size=880x996")
options.add_argument("--no-sandbox")
options.add_argument("--homedir=/tmp")
options.binary_location = "/opt/python/bin/headless-chromium"
#ブラウザの定義
browser = webdriver.Chrome(
"/opt/python/bin/chromedriver",
options=options
)
browser.get(URL)
title = browser.title
browser.close()
return title
❯ tree selenium-headless
selenium-headless
├── function
│ └── selenium-headless
│ └── lambda_function.py
├── layer
│ ├── chromedriver.zip
│ └── selenium.zip
└── template.yaml
SAMプロジェクトのデプロイ
プロジェクトディレクトのトップでビルドを実行します。
❯ cd selenium-headless
❯ sam build
guidedオプション付きでdeployを行います。
❯ sam deploy --guided
Configuring SAM deploy
======================
Looking for config file [samconfig.toml] : Not found
Setting default arguments for 'sam deploy'
=========================================
Stack Name [sam-app]: selenium-headless
AWS Region [ap-northeast-1]: ap-northeast-1
#Shows you resources changes to be deployed and require a 'Y' to initiate deploy
Confirm changes before deploy [y/N]: y
#SAM needs permission to be able to create roles to connect to the resources in your template
Allow SAM CLI IAM role creation [Y/n]: Y
#Preserves the state of previously provisioned resources when an operation fails
Disable rollback [y/N]: N
Save arguments to configuration file [Y/n]: Y
SAM configuration file [samconfig.toml]: samconfig.toml
SAM configuration environment [default]: default
Lambda関数とレイヤーが作成されるので、動作確認を行います。
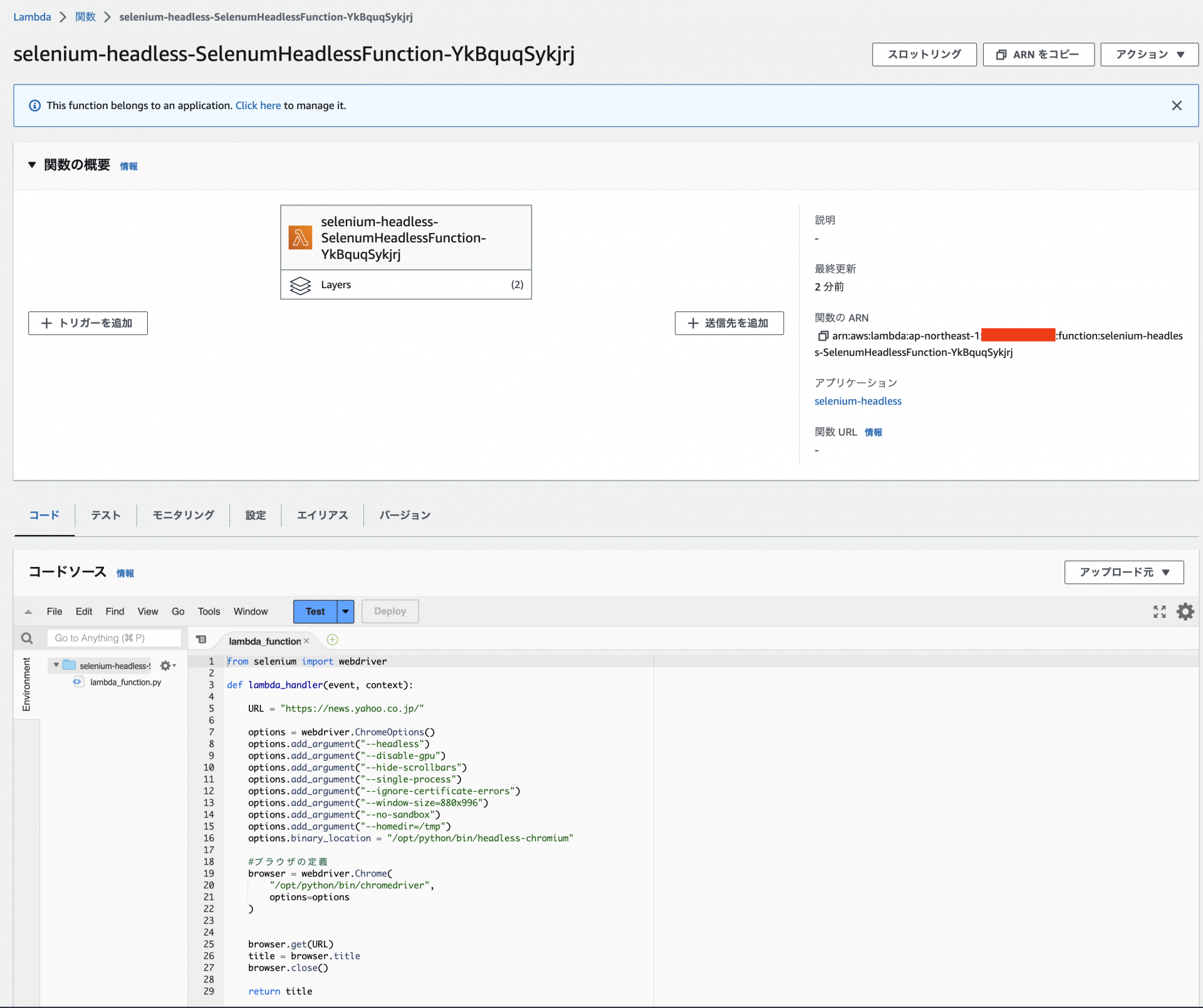
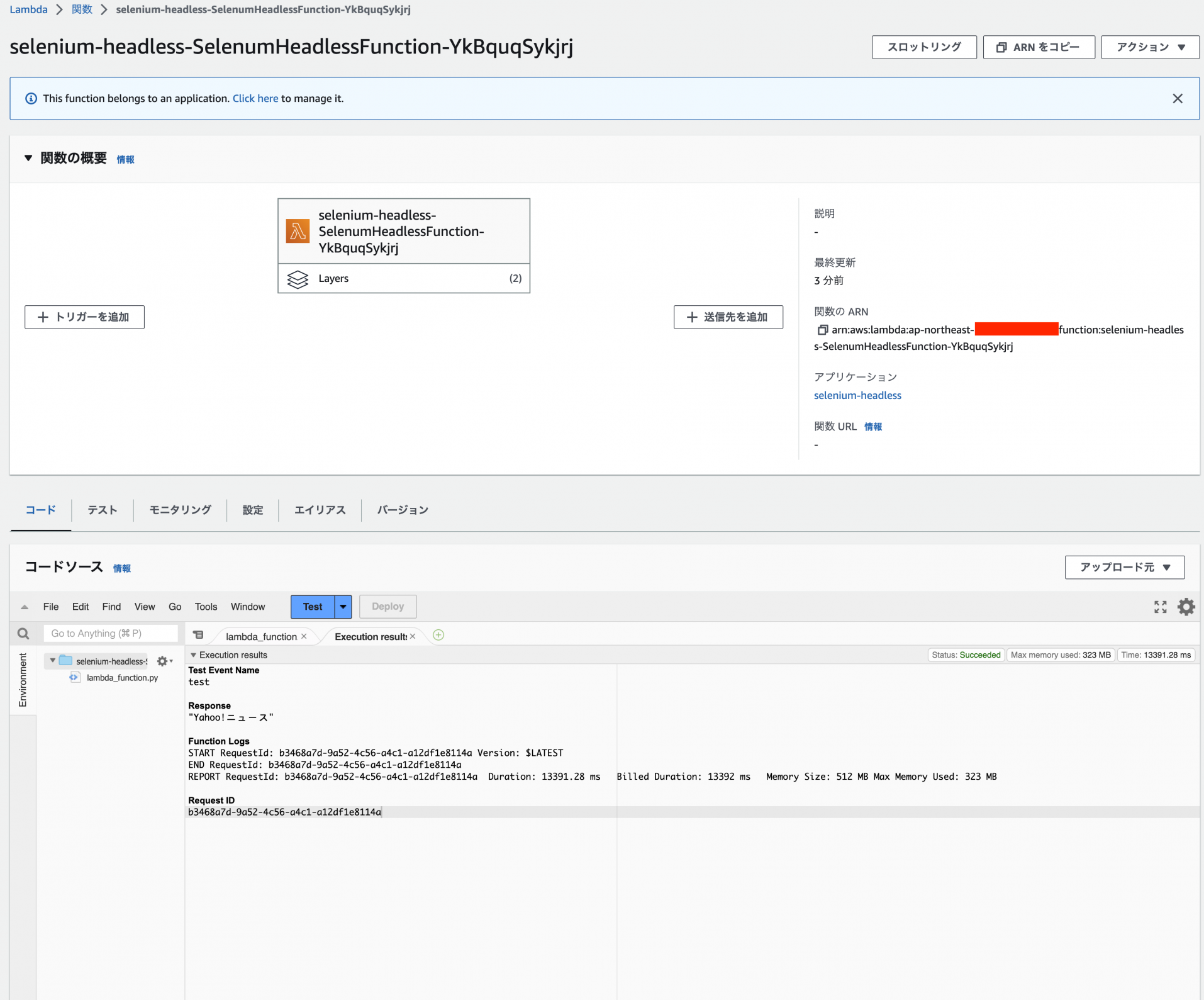
ちゃんと動いてそうですね!
手順:③ ローカルでテストしやすいようにする(Headfulモード)
仮想環境の作成
❯ python3 --version
Python 3.7.10
❯ tree
.
├── Dockerfile
├── README.md
└── selenium-headless
├── function
│ └── selenium-headless
│ └── lambda_function.py
├── layer
│ ├── chromedriver.zip
│ └── selenium.zip
├── samconfig.toml
└── template.yaml
venvで仮想環境を作成します。
❯ python3 -m venv .env
仮想環境をアクティベーションします。
❯ source .env/bin/activate
Selenium, Webdriver Managerのインストール
chrome driverとchromeのバージョンには互換性があります。
chromeのバージョンはどんどん更新されていってしまいます。そのため、それに伴ってchrome driverのバージョンもアップデートする必要があります。
手動でこのバージョン管理に対応するのは大変なので、WebDriver Managerというツールを利用します。
.env ❯ pip install selenium
.env ❯ pip install webdriver_manager
他の環境でも使えるようにrequirements.txtにパッケージ情報を保存しておきます。
.env ❯ pip freeze > requirements.txt
スクリプトの編集
スクリプトを編集します。
from selenium import webdriver
def lambda_handler(event, context, is_lambda=True):
URL = "https://news.yahoo.co.jp/"
options = webdriver.ChromeOptions()
# Lambdaから呼び出した場合
if is_lambda:
options.add_argument("--headless")
options.add_argument("--disable-gpu")
options.add_argument("--hide-scrollbars")
options.add_argument("--single-process")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--window-size=880x996")
options.add_argument("--no-sandbox")
options.add_argument("--homedir=/tmp")
options.binary_location = "/opt/python/bin/headless-chromium"
browser = webdriver.Chrome("/opt/python/bin/chromedriver", options=options)
# 直接呼び出した場合
else:
from webdriver_manager.chrome import ChromeDriverManager
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.get(URL)
title = browser.title
browser.close()
return title
if __name__ == "__main__":
result = lambda_handler(event=None, context=None, is_lambda=False)
print(result)
if分の中でライブラリ(ChromeDriverManager)をインストールするという見慣れないことをしていますが、今のところこれしか思いつかないのでご勘弁ください。
ローカルで実行
.env ❯ cd selenium-headless/function/selenium-headless
.env ❯ python lambda_function.py
Headfulモードで実行されて、yahooのタイトルが取得できればOKです。
.env ❯ python lambda_function.py
lambda_function.py:27: DeprecationWarning: executable_path has been deprecated, please pass in a Service object
browser = webdriver.Chrome(ChromeDriverManager().install())
Yahoo!ニュース
再度デプロイもしておきます。
.env ❯ sam build
.env ❯ sam deploy
Lambda上でも問題なく実行できることを確認しましょう。
成果物
以下のレポジトリにあります。
https://github.com/keiusukematsuda/selenium-headless
参考
https://qiita.com/nabehide/items/754eb7b7e9fff9a1047d
https://qiita.com/ichihara-development/items/5e61c3424b3176bc6096
https://syachiku.net/aws-lambda-python-selenium/