今回は前回やったAutoMLをpythonのコード上から操作して学習、デプロイまでやってみたいと思います。
バージョンだったりで踏んだり蹴ったりだったので割と細かく書き残しておきます。
スクリプトだけ知りたい方は最後にまとめて書いてあるのでそちらをご確認ください。
| バージョン | |
|---|---|
| windows | 10 |
| python | Python 3.6.7 |
| pip | 21.3.1 |
| azure-cli | 2.39.0 |
※必要モジュールを再度洗いなおしたので修正しました。
これで完璧です。
インストールしたモジュールとバージョンの一覧
adal==1.2.7
applicationinsights==0.11.10
argcomplete==2.0.0
attrs==22.1.0
azure-common==1.1.28
azure-core==1.25.0
azure-graphrbac==0.61.1
azure-identity==1.7.0
azure-mgmt-authorization==2.0.0
azure-mgmt-containerregistry==10.0.0
azure-mgmt-core==1.3.2
azure-mgmt-keyvault==10.1.0
azure-mgmt-resource==21.1.0
azure-mgmt-storage==20.0.0
azure-storage-blob==12.9.0
azure-storage-queue==12.4.0
azureml-automl-core==1.44.0
azureml-automl-runtime==1.44.0.post1
azureml-core==1.44.0
azureml-dataprep==4.2.2
azureml-dataprep-native==38.0.0
azureml-dataprep-rslex==2.8.1
azureml-dataset-runtime==1.44.0
azureml-defaults==1.44.0
azureml-inference-server-http==0.7.5
azureml-interpret==1.44.0
azureml-mlflow==1.44.0
azureml-telemetry==1.44.0
azureml-train-automl==1.44.0
azureml-train-automl-client==1.44.0
azureml-train-automl-runtime==1.44.0
azureml-train-core==1.44.0
azureml-train-restclients-hyperdrive==1.44.0
azureml-training-tabular==1.44.0
backports.tempfile==1.0
backports.weakref==1.0.post1
bcrypt==4.0.0
bokeh==2.4.3
boto==2.49.0
boto3==1.20.19
botocore==1.23.19
cachetools==5.2.0
certifi==2022.6.15
cffi==1.15.1
charset-normalizer==2.1.1
click==7.1.2
cloudpickle==2.1.0
colorama==0.4.5
configparser==3.7.4
contextlib2==21.6.0
cryptography==37.0.4
Cython==0.29.14
dask==2.30.0
databricks-cli==0.17.3
dataclasses==0.6
dill==0.3.5.1
distributed==2.30.1
distro==1.7.0
docker==5.0.3
dotnetcore2==3.1.23
entrypoints==0.4
fire==0.4.0
Flask==1.1.4
Flask-Cors==3.0.10
flatbuffers==2.0.7
fsspec==2022.7.1
fusepy==3.0.1
gensim==3.8.3
gitdb==4.0.9
GitPython==3.1.27
google-api-core==2.8.2
google-auth==2.11.0
googleapis-common-protos==1.56.4
HeapDict==1.0.1
humanfriendly==10.0
idna==3.3
importlib-metadata==4.12.0
importlib-resources==5.9.0
inference-schema==1.4.2.1
install==1.3.5
interpret-community==0.26.0
interpret-core==0.2.7
isodate==0.6.1
itsdangerous==1.1.0
jeepney==0.8.0
Jinja2==2.11.2
jmespath==0.10.0
joblib==0.14.1
json-logging-py==0.2
jsonpickle==2.2.0
jsonschema==4.14.0
keras2onnx==1.6.0
knack==0.9.0
lightgbm==3.2.1
llvmlite==0.38.1
locket==1.0.0
MarkupSafe==2.0.1
ml-wrappers==0.2.0
mlflow-skinny==1.28.0
msal==1.18.0
msal-extensions==0.3.1
msgpack==1.0.4
msrest==0.7.1
msrestazure==0.6.4
ndg-httpsclient==0.5.1
nimbusml==1.8.0
numba==0.55.2
numpy==1.21.6
oauthlib==3.2.0
onnx==1.12.0
onnxconverter-common==1.6.0
onnxmltools==1.4.1
onnxruntime==1.11.1
opencensus==0.11.0
opencensus-context==0.1.3
opencensus-ext-azure==1.1.7
packaging==21.3
pandas==1.1.5
paramiko==2.11.0
partd==1.3.0
pathspec==0.9.0
patsy==0.5.2
Pillow==9.2.0
pkginfo==1.8.3
pkgutil_resolve_name==1.3.10
pmdarima==1.7.1
portalocker==2.5.1
protobuf==3.20.1
psutil==5.8.0
pyarrow==6.0.0
pyasn1==0.4.8
pyasn1-modules==0.2.8
pycparser==2.21
Pygments==2.13.0
PyJWT==2.4.0
PyNaCl==1.5.0
pyOpenSSL==22.0.0
pyparsing==3.0.9
pyreadline==2.1
pyrsistent==0.18.1
PySocks==1.7.1
python-dateutil==2.8.2
pytz==2022.2.1
pywin32==227
PyYAML==6.0
requests==2.28.1
requests-oauthlib==1.3.1
rsa==4.9
s3transfer==0.5.2
scikit-learn==0.22.2.post1
scipy==1.5.3
SecretStorage==3.3.3
shap==0.39.0
six==1.16.0
skl2onnx==1.4.9
sklearn-pandas==1.7.0
slicer==0.0.7
smart-open==1.9.0
smmap==5.0.0
sortedcontainers==2.4.0
sqlparse==0.4.2
statsmodels==0.11.1
tabulate==0.8.10
tblib==1.7.0
termcolor==1.1.0
toolz==0.12.0
tornado==6.2
tqdm==4.64.0
typing_extensions==4.3.0
urllib3==1.26.9
waitress==2.1.2
websocket-client==1.4.0
Werkzeug==1.0.1
wrapt==1.12.1
zict==2.2.0
zipp==3.8.1
モジュールのインストール
azureのモジュールをインストールしていきますが、その前に準備が必要です。
まずRustのコンパイラが必要です。こちらからインストールしましょう。
pipは最新版にしましょう。私はこれのせいでエラーはいてました。
これでこけてるときはopensslがどうのこうのというエラーが出てきました。
python -m pip install --upgrade pip
準備ができたらazureのモジュールと必要モジュールをインストールします。
これにはめちゃくちゃ時間がかかっていたので、時間に余裕があるときにやっておくことをお勧めします。
20分以上はかかったと思います。
pip install pandas
pip install pip install azureml-core
pip install azureml-automl-core
pip install azureml-train-automl
ワークスペースへの接続
それではAutoMLを操作していきましょう。
まずは利用するワークスペースに接続します。
ディレクトリ配下にconfig.jsonがある場合は
ws = Workspace.from_config()
ない場合は、
ws = Workspace.get(name="ワークスペース名",
subscription_id='サブスクリプションID',
resource_group='リソースグループ名')
とすることで接続ができます。
クラスタの登録
続いて学習時に利用するクラスタを用意します。
今回はすでに作成されているクラスタを持ってきます。
cluster_name = "クラスター名"
cluster = ComputeTarget(workspace=ws, name=cluster_name)
データの準備
次に学習に用いるデータをデータストアに登録します。
学習データはTabularという型に変換することで利用ができるようです。
今回のデータはlocalに用意したタイタニックの生存予測データを用いたいと思います。
dataset = pd.read_csv("./tmp/titanic.csv")
datastore_name = 'データストア名'
datastore = Datastore.get(ws, datastore_name)
datastore_paths = [(datastore, '登録先のパス(コンテナ名は入れなくていい)')]
titanic_dataset = Dataset.Tabular.from_delimited_files(path=datastore_paths)
これで学習に用いるデータの準備ができました。
AutoMLの設定
続いてAutoMLの設定をしていきます。
まずは実際のコードを確認しましょう。
automl_classifier=AutoMLConfig(
task='classification',
iterations=5,
primary_metric='AUC_weighted',
compute_target=cluster,
experiment_timeout_minutes=60,
blocked_models=['XGBoostClassifier'],
training_data=titanic_dataset,
test_size=0.3,
label_column_name="Survived",
n_cross_validations=2)
パラメータについては今回利用しているものについてのみ説明していきます。
task: 学習の種類を決めます。今回は分類になるのでclassificationを選択しています。ほかにはregression(回帰)、forecasting(時系列)があります。
iterations: 実行するパラメータとアルゴリズムの組の数を設定します。指定しない場合は1000回実行されるようです。今回は5個だけやってみます。
primary_metric: 何を基準にしてモデルを選択していくかの設定です。設定できる項目についてはこちらに記載されています。今回はAUCを使いましょう。
compute_target: 学習を実行するクラスターの指定です。先ほど取得したクラスターを設定しています。
experiment_timeout_minutes:実験終了までにかかる最大時間を設定します。リファレンスではexperiment_timeout_hoursになっていますが、自分が利用したバージョンではこのようになっていました。分単位で設定します。今回は60分にしました。
blocked_models: 実行しないアルゴリズムを設定できます。ここに設定することで学習から省くことができるので相性の悪いものは除くことができます。
training_data: 学習データを選択します。先ほど登録したデータを設定します。
test_size: 学習データのうちテストに使うデータの割合を設定できます。設定しない場合はモデルの作成終了後にテストを行わず、テスト結果を確認できません。今回は30%をテストに利用します。
label_column_name: 予測対象を指定します。今回はSurvivedです。
n_cross_validations: 検証データを指定しなかった場合に実行する交差検証の回数です。今回は2回にしました。
AutoMLの実行
これでAutoMLの実行設定ができたので実行してみましょう。
experiment_name = '実験名'
experiment = Experiment(ws, experiment_name)
run = experiment.submit(automl_classifier)
print(run)
こちらでAutoMLを実行することができます。
Submitting remote run.
Run(Experiment: 実験名,
Id: AutoML_idxxxxxxxxxxxxxxxx,
Type: automl,
Status: NotStarted)
このように実行結果が返ってきます。
ポータルを見に行くと実行が始まってることが分かります。
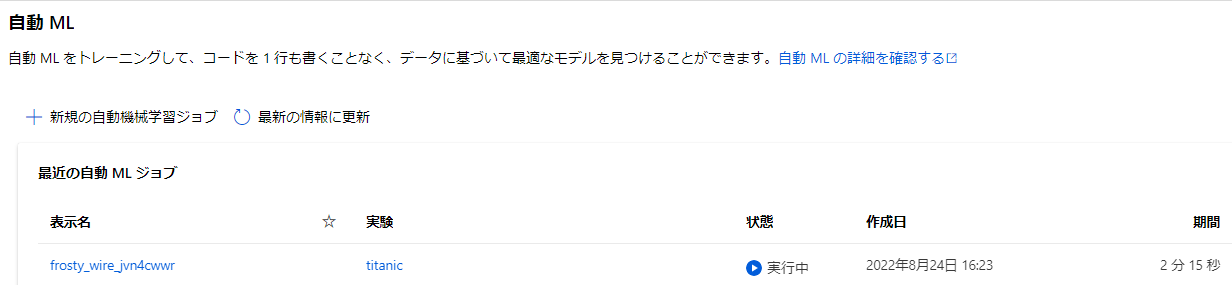
コード上から実行状況を確認してみましょう。
from azureml.core.experiment import Experiment
from azureml.core import Workspace, Run
ws = Workspace.from_config()
experiment_name = '実験名'
experiment = Experiment(ws, experiment_name)
print(Run(experiment, "実行ID").get_status())
実行IDは先ほど出力されたIDの値になります。
返ってくる値の種類は結構あるのでこちらのリファレンスから確認するといいと思います。
ちなみにIDだけが欲しい場合は実行時に返ってきたrunに対してrun.idのようにすることで取得できます。
モデルのメトリックの取得
実行の終了が確認できたら結果を見ていきたいと思います。
まずは複数作成されたモデルから最も良かった結果を取得していきます。
ws = Workspace.from_config()
experiment = ws.experiments['実験名']
automl_run = AutoMLRun(experiment, run_id = '実行ID')
best_model, _ = automl_run.get_output()
これで最も良いモデルを取得できました。
早速メトリックを確認してみたいと思います。
print(best_model.get_metrics())
こちらを実行するとメトリックのデータが辞書形式で取得できます。
{
"accuracy": 0.7724358974358974,
"recall_score_micro": 0.7724358974358974,
"average_precision_score_weighted": 0.8284506887541342,
"precision_score_micro": 0.7724358974358974,
"recall_score_macro": 0.7183413083509187,
"recall_score_weighted": 0.7724358974358974,
"f1_score_weighted": 0.7603185660578442,
"AUC_macro": 0.8247351436433699,
"AUC_weighted": 0.8247351436433699,
"matthews_correlation": 0.4905086221229481,
"norm_macro_recall": 0.4366826167018375,
"average_precision_score_macro": 0.8187645511149464,
"precision_score_weighted": 0.779139660615574,
"f1_score_micro": 0.7724358974358974,
"precision_score_macro": 0.7764410553514505,
"AUC_micro": 0.8520915516107824,
"weighted_accuracy": 0.8182147759145433,
"log_loss": 0.4839744119999346,
"balanced_accuracy": 0.7183413083509187,
"f1_score_macro": 0.7289771828525797,
"average_precision_score_micro": 0.8235973014969669,
"accuracy_table": "aml://artifactId/ExperimentRun/dcid.実験ID_番号/accuracy_table",
"confusion_matrix": "aml://artifactId/ExperimentRun/dcid.実験ID_番号/confusion_matrix"
}
このように帰ってきました。この中から必要な情報を取得して評価に利用することができますね。
テスト結果の取得
今回はテストデータを分割して設定しているので実行後にテストが行われています。
そのテスト結果を確認してみたいと思います。
testexe = best_model.get_children(tags={"mlflow.source.name" : "model_test.py"})
rundata = list(testexe)[0]
rundata.download_file("predictions/predictions.csv")
print(pd.read_csv("predictions.csv"))
まず最適なモデルから子実行を取り出します。
子実行のうちテストの実行のみ取得したいのでタグを利用してフィルターします。
取得したデータからパスを指定してファイルをダウンロードし、実行結果を確認することができます。
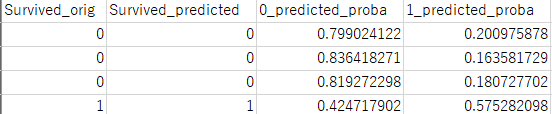
こちらが実行結果の一部です。
Survived_predictedが予測結果、0_predicted_probaと1_predicted_probaがそれぞ0と1の確率になります。
これで実行結果を確認することができました。
モデルの登録
さて、いいモデルが作れたのでデプロイしてAPIとして利用していきたいですね。
デプロイする前にまずはこのモデルを登録する必要があります。
ws = Workspace.from_config()
experiment = ws.experiments['実験名']
automl_run = AutoMLRun(experiment, run_id='実行ID')
best_run = automl_run.get_best_child()
model = automl_run.register_model(model_name="モデル名", description="説明")
ワークスペースから特定の実験を取得し、実行内容を取得します。
そこから最も良かった子実行を取得し、それをモデルとして登録します。
こちらを実行したらポータルのモデルの項目を確認してみましょう。
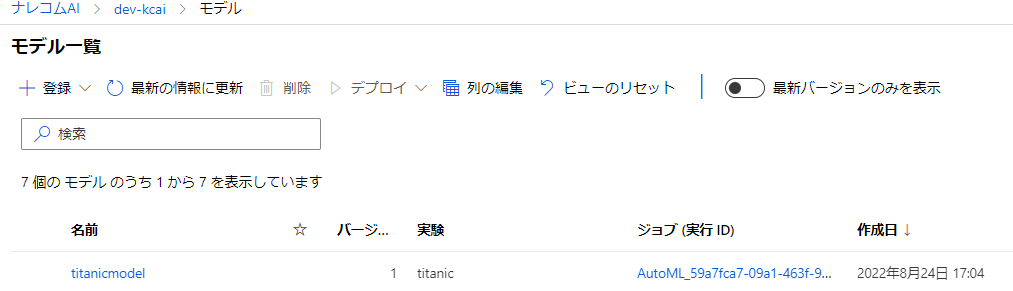
このように登録できていれば成功です。
モデルのデプロイ
登録したモデルをデプロイしていきます。
今回行うのはポータル上ではwebサービスに配置となっているデプロイ方法になります。
ws = Workspace.from_config()
model = ws.models['モデル名']
inference_config = InferenceConfig(entry_script="src/score.py")
deployment_config = AciWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "サービス名", [model], inference_config, deployment_config)
まず、ワークスペースから登録したモデルを取得します。
その後、デプロイ時、リクエスト取得時に実行する内容を書いたスクリプトファイルを登録します。
デプロイするスペックを指定し、デプロイを開始します。
スクリプトファイルについても確認しておきましょう。
def init():
global model
model_path = Model.get_model_path('モデル名')
model = joblib.load(model_path)
def run(raw_data):
df = pd.read_csv(io.StringIO(json.loads(raw_data)['data']))
predictions = model.predict(df)
df["Survived"] = predictions
return df.to_csv(index=False)
initにはデプロイ時にモデルを登録するスクリプトが書かれています。
runにはリクエスト時に実行されるスクリプトが書かれています。
runの中を少し見てみましょう。
まずリクエスト時に送られてくるbodyが引数に入ります。
データをjson.loadsで辞書型に戻し、その中からkeyがdataのデータを取得します。
今回はこれがcsv形式のテキストであると想定しています。
なのでそのcsvテキストデータをpandasを使ってDataFrame形式に変更します。
その後predictに対してDataFrameを投げることで予測結果を取得することができます。
predictの返り値は予測結果のみのlistになっているので、わかりやすい様に予測時に投げたデータに追記し、そのデータを返すようにしました。
それではこちらを実行してみましょう。
ディレクトリの構造やファイル名によってはsrc/score.pyの部分を変更する必要がある点に注意してください。
またdeployにはそこそこ時間がかかります。
今回は約10分かかりました。
デプロイができたかポータルで確認してみましょう。
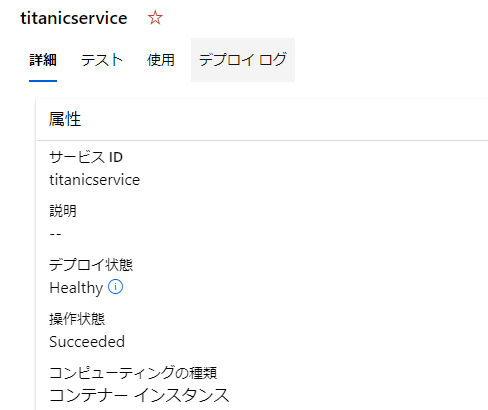
デプロイ状態がちゃんとHealthyになっていますね。
この状態であればテストすることが可能です。
デプロイしたモデルを使ってみる
それでは実際に利用してみましょう。
ポータル上からテストすることも可能ですが、今回はpythonから実際にAPIをたたいてみたいと思います。
import urllib.request
import json
import os
import ssl
import pandas as pd
def allowSelfSignedHttps(allowed):
# bypass the server certificate verification on client side
if allowed and not os.environ.get('PYTHONHTTPSVERIFY', '') and getattr(ssl, '_create_unverified_context', None):
ssl._create_default_https_context = ssl._create_unverified_context
allowSelfSignedHttps(True)
df = pd.read_csv("./tmp/titanic.csv")
data = {
"data": df.to_csv(index=False)
}
body = str.encode(json.dumps(data))
url = '自分のURL'
api_key = ''
headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key)}
req = urllib.request.Request(url, body, headers)
try:
response = urllib.request.urlopen(req)
result = response.read()
print(result)
except urllib.error.HTTPError as error:
print("The request failed with status code: " + str(error.code))
print(error.info())
print(error.read().decode("utf8", 'ignore'))
コードのほとんどはポータルの使用タブに記載されてるものとおんなじです。
今回テストに利用するデータにはSurvivedの項目がないものを利用します。
このようなデータですね。
スクリプト内の変えている部分についてのみ見てみましょう。
まずcsvデータをpandasを用いて読み取ります。
その後辞書の形でdataの中にcsvのテキストデータを入れ込んでます。
それをjson.dumbsを用いて文字列にし、エンコードします。
そのデータをリクエストに投げるという形ですね。
実際に実行してみましょう。
b'"PassengerId,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Survived\\n1,3,\\"Braund, Mr. Owen Harris\\",male,22.0,1,0,A/5 21171,7.25,0\\n3,3,\\"Heikkinen, Miss. Laina\\",female,26.0,0,0,STON/O2. 3101282,7.925,1\\n5,3,\\"Allen, Mr. William Henry\\",male,35.0,0,0,373450,8.05,0\\n7,1,\\"McCarthy, Mr. Timothy J\\",male,54.0,0,0,17463,51.8625,0\\n"'
このように帰ってきました。
返ってきた内容をそのままprintしているので見ずらいですが、Survivedという項目が追加されており、その項目に予測結果の値が入っていることが分かりますね。
まとめ
今回はpythonからAutoMLでの学習、評価、デプロイ、利用を行ってみました。
pythonからも一通りの実行ができたので、サービスに組み込んだり自動でモデルの更新がしていけそうですね。
最後に今回利用したスクリプトをファイルごとに載せて終わりにします。
利用スクリプト
import pandas as pd
from azureml.train.automl import AutoMLConfig
from azureml.core.experiment import Experiment
from azureml.core import Workspace, Datastore, Dataset
from azureml.core.compute import ComputeTarget
ws = Workspace.from_config()
# 使用するクラスターの準備
cluster_name = "クラスター名"
cluster = ComputeTarget(workspace=ws, name=cluster_name)
# データの登録
dataset = pd.read_csv("ファイルパス")
datastore = Datastore.get(ws, "データストア名")
datastore_paths = [(datastore, '登録先ファイルパス')]
titanic_dataset = Dataset.Tabular.from_delimited_files(path=datastore_paths)
# AutoMLの実行準備
automl_classifier=AutoMLConfig(
task='classification',
iterations=5,
compute_target=cluster,
primary_metric='AUC_weighted',
experiment_timeout_minutes=60,
blocked_models=['XGBoostClassifier'],
training_data=titanic_dataset,
test_size=0.3,
label_column_name="Survived",
n_cross_validations=2)
# AutoMLの実行
experiment = Experiment(ws, '実験名')
run = experiment.submit(automl_classifier)
print(run)
from azureml.core.experiment import Experiment
from azureml.core import Workspace, Run
ws = Workspace.from_config()
# AutoMLの実行
experiment = Experiment(ws, '実験名')
print(Run(experiment, "実行ID").get_status())
import pandas as pd
from azureml.core import Workspace
from azureml.train.automl.run import AutoMLRun
ws = Workspace.from_config()
experiment = ws.experiments['実験名']
automl_run = AutoMLRun(experiment, run_id = '実行ID')
# テスト結果の取得
best_model, _ = automl_run.get_output()
print(best_model.get_metrics())
testexe = best_model.get_children(tags={"mlflow.source.name" : "model_test.py"})
rundata = list(testexe)[0]
rundata.download_file("predictions/predictions.csv")
print(pd.read_csv("predictions.csv"))
from azureml.core import Workspace
from azureml.train.automl.run import AutoMLRun
ws = Workspace.from_config()
experiment = ws.experiments['実験名']
automl_run = AutoMLRun(experiment, run_id='実行ID')
best_run = automl_run.get_best_child()
model = automl_run.register_model(model_name="モデル名", description = "説明文")
from azureml.core import Workspace
from azureml.core.model import Model
from azureml.core.webservice import AciWebservice
from azureml.core.model import InferenceConfig
ws = Workspace.from_config()
model = ws.models['モデル名']
inference_config = InferenceConfig(entry_script="src/score.py")
deployment_config = AciWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "サービス名", [model], inference_config, deployment_config)
import urllib.request
import json
import os
import ssl
import pandas as pd
def allowSelfSignedHttps(allowed):
# bypass the server certificate verification on client side
if allowed and not os.environ.get('PYTHONHTTPSVERIFY', '') and getattr(ssl, '_create_unverified_context', None):
ssl._create_default_https_context = ssl._create_unverified_context
allowSelfSignedHttps(True)
df = pd.read_csv("./tmp/titanic.csv")
data = {
"data": df.to_csv(index=False)
}
body = str.encode(json.dumps(data))
url = '自分の'
api_key = ''
headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key)}
req = urllib.request.Request(url, body, headers)
try:
response = urllib.request.urlopen(req)
result = response.read()
print(result)
except urllib.error.HTTPError as error:
print("The request failed with status code: " + str(error.code))
print(error.info())
print(error.read().decode("utf8", 'ignore'))