Web のパフォーマンス継続モニタリング環境
intro
Web の健康状態を把握するためには、きちんとしたモニタリング環境を整える必要がある。
正しくメトリクスが測定できていないと、正しくボトルネックの把握ができないし、チューニングの副作用も正しく把握できない、アプリの変更の影響もわからないし、負荷対策もできない。
単にパフォーマンスチューニングだけのためではない。が、パフォーマンスチューニングには必須、という関係。
そして、メトリクスは一回適当に取っただけでは正確とは言えず、やっぱり定期的な取得が必要になる。
この辺のノウハウは、サーバサイドではかなり成熟している。
しかし、これは「リクエストtoレスポンス」部分で終わってしまうことが多々有る。
対人間で言えばクライアントとしてのブラウザがアクセスし表示するまでがパフォーマンスなので、
「レスポンス返した後は知らん」では半分しか計れていない。
本当は外部から実ブラウザでアクセスした、フロントのメトリクスも取る必要がある。
ところがこの辺はまだちょっと発展途上な感じが有る。
(Xxx Timing API シリーズの仕様策定と実装が途上なのもあるのでしかたない)
また、フロントからのメトリクスと、サーバ内部のメトリクスを一元的に管理して全体を把握したいんだけど、どうもこの辺はあまり統合された丁度良いものが、少なくとも OSS では無い気がする。(ベンダ製品を買えばあるとは思う)
OSS にしても、munin とかだとカスタマイズがちょっと限界あるし、 sensu は運用しないといけないものが少し多い、もう少し楽に・雑に・モダンに始めたい。
自分の持ってるドメインで新しく色々始めようと思い、色々探していたらタイトルの通り落ち着いた。
定期的に可視化するメリット
サーバと違って、フロントの定期的なメトリクスの収集は、まだ確立してるとは言えないと思う。
フロントのチューニングは、 devtools を開いて何回かリロードした結果でなんとなく見ている人も多いと思う。
取得のタイミングにしても、 git の push やら jenkins の deploy をフックしてメトリクスを取るという手も有るが、 Web はアプリの変更以外にもありとあらゆる要素によって、状況が変わると思っている。
要するに変えた時に一回とって終わりという感じだと、見落とされる変化が多いと思うので、とにかく定期的に取るのが良いと思っている。
両方を同時に可視化するメリット
Speed Index ががくっと落ちた、でも SlowQuery も出てないし、 CPU も余ってるし、swap も大丈夫で、Response Time も変わらない、実はアプリに変なリダイレクトが入っててそれが悪さしてた、みたいなのが grafana で一括表示されてればすぐにわかる。という感じ。
表示がもたついた時にサーバが原因なのかフロントが原因なのかをすぐにグラフから読み取れたりする。これは、どっちかだけの可視化ではできない。サーバ内だけ可視化して見えた気になってるのは全体の半分だなと、構築してみ見るとよくわかる。
SPA
sitespeed.io が測るのはいわゆる初期表示なので、 SPA 的なものはこれだけでは足らない。
その場合、測定したいポイントでクライアントにタイムスタンプを取得するコードを仕込み、それを beacon API や XHR や WebSocket で graphite に入れられる形式で送るなどが考えられる。
ただし、その場合は、それこそブラウザを selenium などで動かす必要が有る。
その辺は、もう汎用的な解があるわけじゃないし、アプリのどこを測るべきか、そのメトリクス取得コードが悪さしないかなど、色々別の問題が出てくるが、そういう拡張に対しても柔軟な構成にしているので、そこは探っていくしかない。
RUM
sitespeed.io は仮想ブラウザからのメトリクス収集なので、プロダクションにコードを仕込んでの Real User Monitoring ではない。
それをしたい場合は、sitespeed.io が収集する情報と同等のものをフロントのコードに仕込み、
やっぱり beacon API や XHR や WebSocket で graphite に送りつけることで可視化はできる。
しかし、サイトが表示されるたびにデータが飛んでくるのはさすがに多いとなれば、間引く手段について考える必要がある。
また、フロントからのコードはブラウザに入ってる拡張のバグやら、だれかが devtools 開いていたずらした結果などのノイズも飛んでくる。このノイズ対策も必要になる。
一応そういう方向にも進めるようにしてあるので、おいおい考えていきたい。
用件
ということで、今回の用件はこんな感じ。
- 大規模ではない
- できるだけ楽に構築したい。運用するべきものは減らしたい
- フロントは外からなるべくブラウザのリアルなでアクセスして、初期表示メトリクスを見たい(speed index とか)
- サーバ内部は、エージェントを一個起動するだけな感じにして、 dstat 相当が柔軟に取りたい
- フロントもサーバ内も合わせて柔軟にグラフ化がしたい
- 自分でメトリクス/グラフが適宜柔軟に追加できると嬉しい
- 有料サービ組み合わせ始めると辛いので、自分で立てて費用は抑えたい
- それなりにモダンなツール群で構成したい
- SPA, RUM はとりあえず保留
結果
- フロントメトリクス: sitespeed.io
- サーバメトリクス: diamond
- メトリクス保存: graphite
- グラフ化: grafana
docker があるものは docker で。
sitespeed.io を jenkins や cron で回す。
graphite では入れ物、グラフは grafana で。
特に追加でメトリクス送りたい場合など、 TCP で graphite に雑に送りつけて grafana でグラフに使えるので、拡張はしやすいと思う。
構築
準備
基本は graphite, grafana, sitespeed.io は docker コンテナを起動するだけ。
diamond も docker でにホスト側の /proc をマウントすればできる気がするが、その結果が本当に信用できるかよくわからなかったので、結局自分でビルドして入れた。
docker 内に格納されるデータは、ホスト側からも取得したいので、ホスト側にディレクトリを作り、 docker に共有ディレクトリとしてマウントする。
例として共有ディレクトリのベースを以下とする。
以降このパスを書く場合は、フルパスにしておいた方が良い。
$ mkdir /home/jxck/monitoring
ホストの IP は 192.0.2.0 1 だったとする。
また、セキュリティやその他構築にかかわる全ては自己責任で。
graphite
概要
graphite はデータの収集と表示が行えるツールであり、
ざっくりデータの収集(carbon)/格納(whisper)/グラフ化(webapp) の三つで構成されている。
しかし、標準的なグラフツールは今ひとつなのでデータの収集と格納部分のみ、つまりメトリクスの入れ物として使う。
sitespeed.io も diamond もここへのデータ格納は非常に簡単だし、とにかく graphite に突っ込む系のエコシステムはそれなりに揃っているて、 graphite を起点にしておけば大丈夫そうという雰囲気を感じている。
特に graphite は好きな情報を以下のフォーマットで TCP から送りつけると格納してくれる。
metric_path value timestamp\n
手軽には nc コマンドや telnet でもいける。
$ echo "my.own.metrics 100 `date +%s`" | nc 192.0.2.0 2003
このため、連携ツールも多いし、何か送りたいツールがあっても簡単に書ける。
例えば、定期的な監視だと、原因が deploy だったとき、どの deploy か分からない。その場合は、 deploy するたびに graphite にそれを送り付ければ、その情報も後述の grafana で使える。
他にも、コードの中のある部分に graphite に 1 とか適当に送るコードを書いておく。
すると、そのコードをどのくらい通ったかを簡単に可視化できる。タイムスタンプに返ればそこのベンチもなんとなく取れる。
これはクライアントでも WebSocket で中継すればできる。入れすぎると負荷になるかもしれないけど、色々雑に集められる事は、アイデア次第でうまく使えると思う。
あと、もし規模が大きくなればバックエンドを influxdb とかに置き換えたりするんだろうけど、そこまではまだ考えていない。
install
まず graphite がデータを格納する場所を作る。
これはコンテナの外に作り、それを docker にマウントする。
$ mkdir /home/jxck/monitoring/graphite
起動するコンテナのデフォルトアカウントが guest/guest なので、別途パスワードを作る。
これもホストに作り後でマウントする。
$ sudo apt-get install apache2-utils
$ htpasswd -c .htpasswd <username>
コンテナを起動する
$ docker run \
-d \ # デーモン化する
--name graphite \ # コンテナ名
-p 8080:80 \ # コンテナの 80 をホストの 8080 に
-p 2003:2003 \ # コンテナの 2003 をホストの 2003 に
--restart=always \ # 落ちたらとにかく再起動
-v /home/jxck/monitoring/graphite/:/opt/graphite/storage/whisper \ # graphite のデータをホストにマウント
-v /home/jxck/monitoring/.htpasswd:/etc/nginx/.htpasswd \ # ホストの .htpasswd をコンテナに
sitespeedio/graphite \ # イメージを実行
これで起動すれば以下のアドレスでアクセスできる。
表示されるデフォルトのグラフツールは、実際には使わないけど、ちゃんと取れてるかは確認できる。
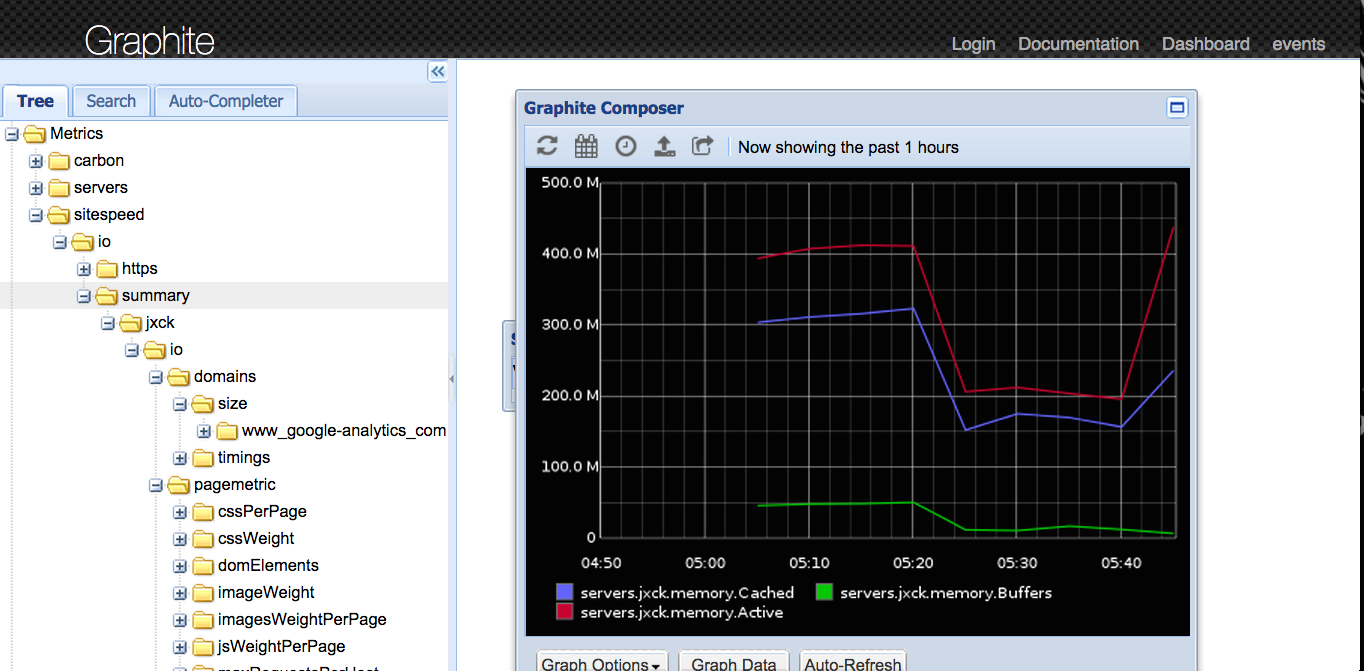
(全部の連携が終わった後の図)
grafana
概要
grafana はモダンなグラフ化ツール。
graphite をデータソースとして、そのデータをグラフ化するのに使う。
graphite だけでもグラフ化は簡単にできるが、 grafana は知識があまり無くても様々なグラフを柔軟にいい感じに作れる。
メトリクスへのクエリを GUI で簡単に作れるし、カスタマイズもしやすい。
graphite へのメトリクスを追加しても、シームレスにグラフを追加できるし、非常に良い感じ。
install
Grafna はダッシュボードのデータを生成するので、これもホスト側にディレクトリを作り docker にマウントする。
$ mkdir /home/jxck/monitoring/grafana
また、 grafana デフォルトアカウントが admin/admin だがこれは引数で変更可能なので、
以下のように起動する。
$ docker run \
-d \
-p 3000:3000 \
-v /home/jxck/monitoring/grafana:/var/lib/grafana \
-e GF_SECURITY_ADMIN_USER=admin \
-e GF_SECURITY_ADMIN_PASSWORD=password \
--name grafana \
--restart=always \
grafana/grafana
以下でアクセスできる。
grafana が起動したら、 admin > Data Source から graphite をひもづける。
上の例では graphite は host の 8080 にマップされているので、そこに作成したパスワードを用いた basic auth で http://192.0.2.0:8080 に接続する。
グラフ作成画面右下の datastore で graphite が選べるようになるので、あとはプロパティを掘って行き自分の見たいデータを見たいように表示すれば良い。
という意味では、データはとにかく手当たり次第に送っておいて、見たい奴だけ表示するみたいにしておくのでとりあえずは良いと思う。
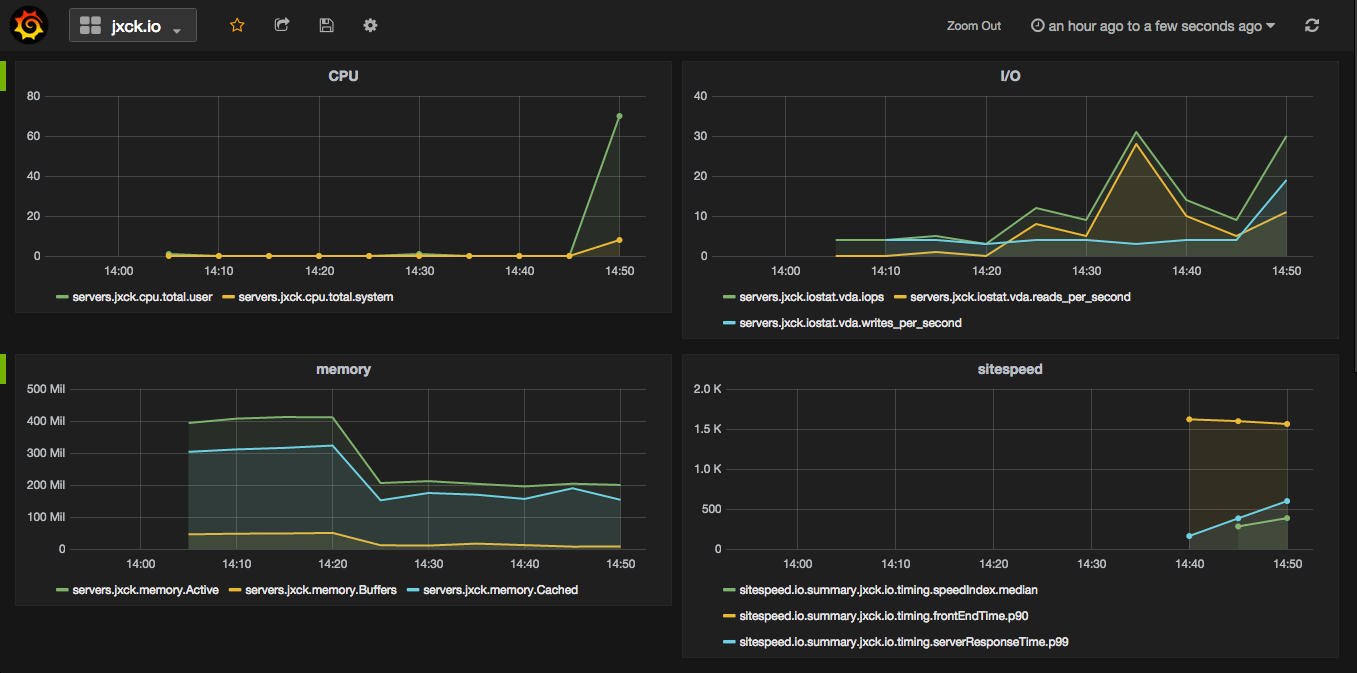
(全部の連携が終わった後の図)
sitespeed.io
概要
サイトへは ab (apache bench) 的な response time を測定するツールは多く有るが、
今の Web でブラウザとサーバが行っているインタラクションはそんなに単純なものではない。
特にレスポンスの HTML が返ったあとだけではなく、その後にそれがレンダリングされる部分もきちんと測定したい。
一番良いのは、実ブラウザでアクセスし、 devtools の timeline や、 navigation timing API で情報を抜くことになる。
sitespeed.io は chrome や firefox を Xvfb を用いたヘッドレスブラウザとして起動し、そこからアクセスした結果のメトリクスを保存できる。
ブラウザからのリアルなリクエスト/レスポンス/レンダリングなどが取れるので、かなり詳細に挙動が把握できる。
単発で実行するだけでも、以下のように HTML で結果が表示できるが、これを定期的に実行することで継続的な監視ができる。
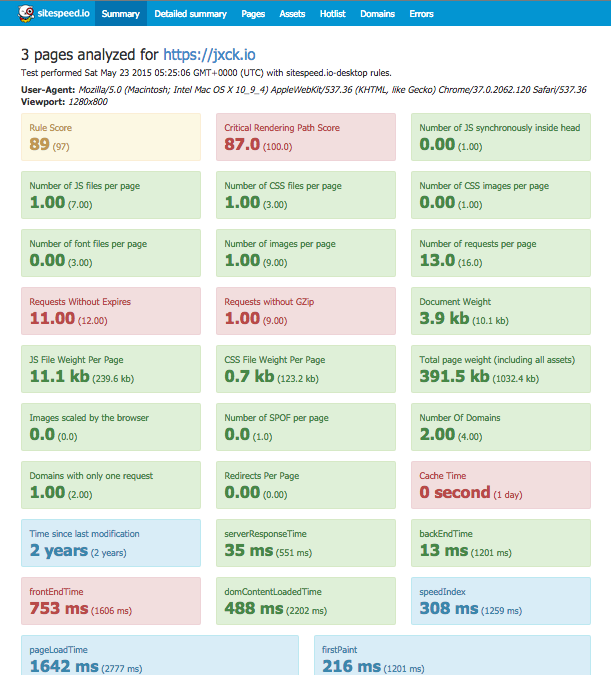
こっちにデモもある。sitespeed.io example
SpeedIndex, FirstPaint, PageLoadTime などなど、色々見えることがわかる。
HTML でなく、結果を直接 graphite に送れるオプションがあるので、今回はそれを使う。
これらの情報を時系列でみることで、過渡的な変化の発見や、チューニングの効果の確認につながる。
ちなみに、 WebPageTest のフリー API を使って連携もできるらしいが、ここはまだやってない。
また、 ab -n 10000 -c 100 的な負荷テスト向きではない。
install
まず格納場所を作る。
$ mkdir /home/jxck/monitoring/sitespeed.io
sitespeed.io も docker があるので、これを叩けば行える。
この docker はコマンドを実行するためのもので、デーモン起動はしない。
コマンドは npm でインストールできるが、 Java が無いと実行できないので、
Java 入れるのが面倒じゃなければそれで良いと思う。
コマンドが長いので一旦ファイルに書く。
// sitespeed.sh
docker run \
--privileged \ # 権限を与える
--rm \ # 実行したらコンテナを消す
-v /home/jxck/monitoring/sitespeed.io:/sitespeed.io \ # ディレクトリを共有
sitespeedio/sitespeed.io \ # コンテナ名
sitespeed.io \ # ここからはコマンド実行
-u https://jxck.io \ # ターゲット URL
-b firefox \ # ブラウザ
-n 3 \ # 回数
--connection cable \ # 回線エミュレート
--graphiteHost 192.0.2.0 \ # ここはホストを IP で指定 2003 ポートに送られる
--graphiteData summary,rules,pagemetrics,timings,timings \ # 全ての情報を graphite に送る
sitespeed.io は単発でメトリクスを取得するツールなので、これを定期実行するとグラフ化するための時系列データとなる。
最後のオプションが無いと全てのデータは送られないので、まずは全部送ってみて、いらないのを減らして行くと良いと思う。
定期実行ジョブスケジュールの基本といえば crontab や jenkins など、別に何でやっても良い。
とりあえず 15 分ごとで動かしてみたが、ブラウザから 3 リクエストくるくらいの負荷ならもっと短い間隔でも問題ないと思う。
diamond
概要
サーバ内のメトリクスは CLI なら dstat あたりが見やすいので、その中身を fluentd で収集するとかがモダンなのかと思ったら、それ相当を一個でやってくれる diamond というのが有るらしいと教えてもらったので、これを使ってみる。
@Jxck_ graphiteだとDiamondがおすすめです https://t.co/tnMVtW9urk
— Akihiro Okuno (@choplin) 2015, 5月 15
fluentd がすでに入ってるなら dstat + fluentd の方が実が楽かもしれない。
diamond は collector が非常に充実しているので、とりあえず標準で入れただけでも欲しそうなものは一通り取れた。もし追加で欲しければ collector に追加すればよさそう。
ちなみに、今回 graphite を入れた docker の Dockerfile は、 fork 元が docker-graphite-statsd なものだったため、今回作業したバージョンでは statsd で取って carbon で送る構成が自動で構築されている。が、これが収集するのは graphite の docker の中の情報なので、あまり意味が無い。そして、 Dockerfile からも statsd の設定は消されている ので、そのうち、この carbon での収集は動かなくなると思う。
install
インストールがちょっと癖があって、 python 製だけど make でパッケージをビルドしてから入れる感じ。インストールスクリプトが微妙に足りてないところがあったが wiki だったので勝手に直しておいた。
$ sudo apt-get update
$ sudo apt-get install make pbuilder python-mock python-configobj python-support cdbs devscripts
$ git clone https://github.com/python-diamond/Diamond
$ cd Diamond
$ make builddeb
$ sudo dpkg -i build/diamond_3.5.8_all.deb #(check version number properly)
config はテンプレートをコピーして以下あたりを直す。
- Graphite Server Host
- Default Pool Interval
$ sudo cp /etc/diamond/diamond.conf.example /etc/diamond/diamond.conf
$ vim /etc/diamond/diamond.conf
デーモンを起動
$ sudo service diamond start
コンフィグの設定はまだよくわからないところが多い。
とりあえず、きちんと動けば graphite には servers というメトリクスデータが溜まり始めるはず。
まとめ
diamond 以外は docker なので、割と簡単に構築ができた。
とりあえずこれで色々こまかく見る事ができるようになったし、拡張もしやすいベースができたと思うので、これでしばらくやってみたいと思う。
もう少し良い構成、とくにこの辺の問題をいい感じに解決してくれる OSS ソリューションなどあったら教えていただけると幸いです。
また、間違いなどはコメントや編集リクエストでご指摘ください。
参考サイト
- http://www.peterhedenskog.com/blog/2015/04/open-source-performance-dashboard/
- http://www.sitespeed.io/
- http://graphite.readthedocs.org/en/latest/tools.html
- http://grafana.org