文字の規格に関して改訂の議論が始まっているので、現在技術的な問題を残していそうな文字のリストを出して欲しいというボールを投げられましたので簡単にまとめてみました。なおどのレベルにどういう形で投げるべき問題なのかはこちらでは細かな分類はしていません。ざっくりとしたリストとして見ていただければと思います。
「ダーシ」の問題
主にDTPデータからの電子化での問題です。私の把握している限りで、DTP等のデータで「ダーシ」として使われている文字は以下のものがあります。
- U+2014(EM DASH)
- U+2015(HORIZONTAL BAR)
- U+FE31(PRESENTATION FORM FOR VERTICAL EM DASH)
- U+2500(罫線素片)
このうち、U+2014が本来の符号位置としての「ダーシ」ですが、フォントによって縦書きで中央に来ないケースが多くあるため、DTPではこれを嫌ってU+2015を使用しているケースが多く見られるようです。
U+FE31は中央に来るようですが、電子化に際して書き出すと自動で横棒にならず、縦棒のまま残ってしまうため別の文字に置換する必要があります。

さまざまな文字が「ダーシ」として使われている
また、ダーシは1文字幅で使うだけではなく、2文字幅の「二倍ダーシ」として使用するケースが多く見られます。二倍ダーシとして連続入力した場合、U+2014/U+2015ともに文字間に隙間ができるデザインのフォントが多く、これを避けるために本来はダーシとして使うべきでないU+2500の罫線素片を使っているケースがあるようです。これは実質的に現状フォントの指定ができない電子書籍では通常の対応となっているのではないかと思います。
DTPではU+2015を使い、縦200%の変倍をかけているケースが多く見られるようですが、これは電子化のためにそのままテキスト化すれば変倍の情報が飛んで1倍ダーシになります。このため置換処理が必要となります。さらにU+2015はJIS X 0213外の文字であり、厳密にJIS X 0213内での電子化対応を求める場合※1には何らかの文字に置換しなければならないという問題もあります。
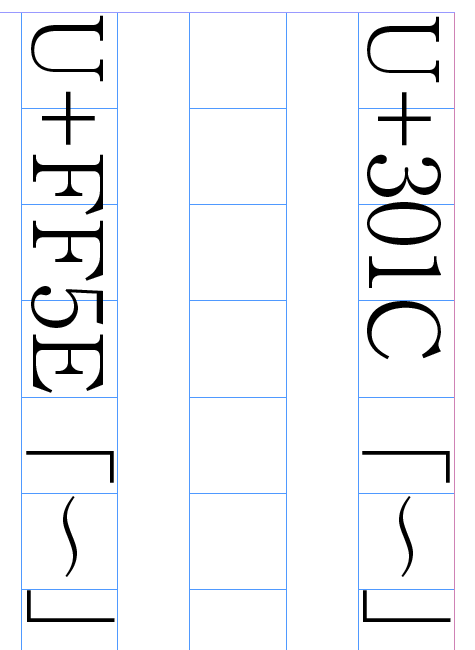
波ダッシュと全角チルダの問題
Webを含めさまざまな場面で起きている問題です。過去のさまざまな経緯により以下の文字が混用されています。
- U+301C(WAVE DASH)
- U+FF5E(FULLWIDTH TILDE)
現在多くの商用フォントではグリフで見分けがつきません。このためDTP的には問題は顕在化していませんが、U+FF5EはJIS X 0213外の文字のため、電子化では置換処理が必要になることがあります。なおこれ以外の文字混用問題も別項目で取り上げていますが、このケースはUnicodeの規格のミスなども絡んでいてだいぶ根が深いので単独で挙げておきます。参考リンク先の記述がかなり詳細ですので、この問題の概要はそちらをご覧ください。
波ダッシュと全角チルダはグリフでは見分けがつかない
和文引用符の問題
DTPデータからの電子化での問題です。U+201C/U+201Dのダブルクォートは、InDesignの機能によってダブルミニュート※2として表示させることができます。ただし、バックグラウンドで持っている文字情報はU+201C/U+201Dのままなので、電子化に際してテキスト化するとグリフが変わってしまいます。このため置換処理が必要となります。U+301D/U+301Fのダブルミニュートをそのまま使えばこの問題はクリアできますが、これはInDesignの禁則文字に入っていない文字のため、InDesignで禁則文字のカスタマイズが必要となります。

InDesingからテキスト化するとグリフが変わってしまう
和文中の欧文引用符の問題
DTPデータからの電子化での問題です。和文組版では通常、和文中の欧文であっても引用符にU+0022を使わず、U+201C/U+201Dをダブルクォートとして使うケースが多く見られます。同様に、アポストロフィとしてU+2019を使い、U+0027を使わないことも慣例となっているようです。
これはU+0022/U+0027の字形が「間抜け引用符」などと呼ばれてデザイン的に嫌われたために起きたものですが、U+201C/U+201D/U+2019はUnicode上では全角幅/半角幅で異なるコードポイントを与えられてはいないため、テキストとして書き出した際に不自然なアキが引用符の前後に入るケースがあります。このため、電子化に際してはU+0022/U+0027に適宜置換して対応したりします。これはまた、Kindleが縦組み時にU+201C/U+201Dを強制的にU+301D/U+301Fのグリフで表示してしまうことへの対応策でもあります※3。

Kindleでは縦組みでのダブルクォートはダブルミニュートとして表示される
グリフで見分けが付かないが使うべきでない文字の混用問題
Webを含めさまざまな場面で起きている問題です。よく見られるのが「康熙部首」としてUnicodeに収録されている文字(U+2F00〜U+2FD5)を、通常の漢字と混用しているケースや、キリル文字の「А」「В」「С」「Е」「О」「Р」などを通常のアルファベットの文字と混用しているケースです。また、漢字の「二」とカタカナの「ニ」の混用も時々見られます。
これらはおそらくOCRの誤認識などが混入の原因と思われますが、グリフを目視で見分けて修正することが極めて困難であるため、何らかの機械的な処理で混用を防ぐことが期待されます。康熙部首などは特殊なケース以外では使用されない文字であるため、機械的な1対1の置換でかなりの場合カバーできるかと思います。

康熙部首と通常の文字は見分けがつかない
絵文字の異体字表示文字の混入問題
現在、Web等で絵文字が日常的に使われるようになってきており、それに伴って絵文字の異体字表示文字がDTPの元データや電子書籍のテキストに混入し、意図しない表示結果を引き起こすケースがあるようです。符号位置としてはU+FE00〜U+FE0Fがそれに当たります。
時計数字や丸数字などかつての機種依存文字対応の残滓
現在、時計数字や丸数字などはその多くがUnicodeに独自のコードポイントが与えられており、テキストとして扱えるようになっていますが、かつて機種依存文字として扱われた経緯があるため、現在でも例えば時計数字の「Ⅳ」をアルファベットの組み合わせの「IV」で入力する等の対応をしているケースがあります。少なくともDTPデータや電子書籍では、アクセシビリティへの正しい対応のために本来のUnicodeの文字を使うべきと思います※4。また、丸数字の外字での対応等も極力控えた方がよいと考えています。
その他問題がありそうな文字
一部の文字が電子化の際に縦組みで左右中央に来ないため、別の文字に置換したり、場合によっては外字化しているケースがあるようです。確認できている文字は以下の通りです。こういったものはフォントのグリフに依存するため、まだ同種のものがあるかもしれません。
- 「•」(U+2022/BULLET)
- 「…」(U+2026/三点リーダー)
以上になります。当然他にも問題のある文字はあるかもしれません。今なら規格側での修正の可能性もあるようですので、どんどん意見を上げましょう。
※1 電書協ガイドでは現在、使用する文字の範囲をJIS X 0213の範囲内とすることを規定している。一部のリーディングシステムが厳密にJIS X 0213内のグリフしか持たないフォントを表示フォントとして採用しているため。
※2 「ノノカギ」「チョンチョン」などと呼ばれることもある約物。
※3 Kindleのみの将来解決されうる問題であるとして許容する解釈もある。
※4 例えば音声読み上げ時に「フォー」ではなく「アイブイ」と読み上げられてしまうため、アクセシビリティ的には問題。