概要
さくらサーバにおいて、UTF-8に対応したWEBブラウザに
Mecabで形態素解析した結果を出力する。
プログラミング言語は、python2.7を使って解説します。
Mecabの出力結果をWEB上に出力する際の参考になれば幸いです。
Mecab本体のインストール、および、MecabのPythonからの呼び出しは、
前回の記事を参照してください。
さくら共有サーバーにmecabをインストールしてpythonから呼び出してみる
http://qiita.com/Jshirius/items/3a067486e2a693544c32
文字コードは、UTF-8を使っています。
Mecabの文字コードは、デフォルト「euc-jp」になっており、UTF-8で結果を出力するのハマった。
よって、メモを残しておく。
前提条件
前提条件
この記事では、以下のディレクトリをWebのRootとします。
/home/orehome/www/test
プログラムを置く場所
/home/orehome/www/test/cgi-bin
ソースファイルのファイル名
mecab_sample.py
内容
(1)ソースコードを書く
以下のようなソースコードを書きます。
# !/usr/bin/env python
# coding: UTF-8
import MeCab
# 辞書ファイルの場所をフルパスで指定します(相対パスだと何故か読み込みに失敗した)
userdic_path="-d /home/orehome/local/lib/mecab/dic/ipadic"
t = MeCab.Tagger("-Ochasen " + userdic_path)
text = u'すもももももももものうち'
# utf8へ変換
encoded_text = text.encode('utf-8')
meData = t.parse(encoded_text )
# 改行コードを<br>に変換
meData = meData.replace("\n","<br>")
html_body="""
<html><body>
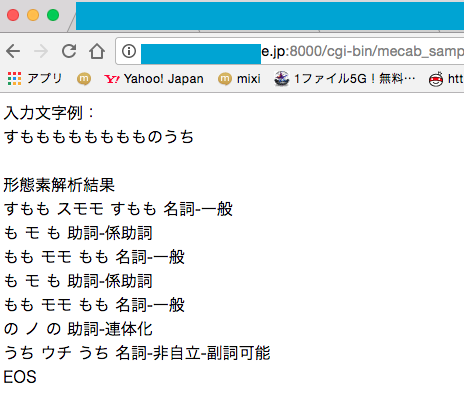
入力文字例:<br>%s
<br><br>
形態素解析結果<br>
%s
</body></html>"""
print "Content-type: text/html\n"
# 以下のmetaタグがないと、Cromeで文字化けが発生する
print "<meta charset=utf-8 />"
print html_body % (encoded_text,meData)
作成したソースコードは、サーバの任意の位置に置いてください。
ただし、ソースコードはcgiで動くため、cgi-binディレクトリ以下においてください。
この例では、以下の場所にファイルを置きます。
/home/orehome/www/test/cgi-bin/mecab_sample.py
(2)アクセス権限を実行可能に変更する
アクセス権限を実行可能にする。
これを忘れて、WEBページにアクセスしたら、ブラウザは、
真っ白になって解決に1時間も要しました・・・。
chmod 755 mecab_sample.py
(3)pythonのWEBサーバを起動する
「cgi-bin」の一つ上の階層に移動して以下のコマンドを入力してサーバを動かします。
この記事の場合は、/home/orehome/www/testに移動して以下のコマンドを入力しています。
python -m CGIHTTPServer
ログアウトしてもサーバを動いている状態にしておく方法は以下の通り
nohup python -m CGIHTTPServer &
※nohup使う方法が、本番環境で運用する場合、正しいのかわかりません。
もし知っている人がいたら教えてください!
2017年4月18日追記
本番環境で運用する場合は、以下の資料が参考になります!
さくらでシンプルなPYTHON CGIを動かしてみる(環境設定編)
http://www.mwsoft.jp/programming/python/sakura/010_010.html
(4)WEBブラウザ動作確認
私の環境は、python2.7を使っています。
ブラウザから該当のURLを叩きます。
http://domain_name:8000/cgi-bin/mecab_sample.py
ただしく動作していると以下のように表示されます。