
[統計ソフト「JMP(ジャンプ)」によるランダムサンプリング]
この記事では、初心者の方にもわかりやすく「ランダムサンプリング」の基本を解説します。実際のやり方も紹介しますので、読み終えるころには業務で活用するイメージがきっと持てるはずです。
※今回の内容はYouTube動画でもご紹介しています。
職場で手元に大量のデータがあると、まずはざっと中身を確認して、使えるデータなら業務に役立てたいと思いますよね。
でも、データ数が膨大すぎると、すべてを確認するのは現実的ではありません。そんなとき、「データの一部を見ただけで、全体の傾向をつかめたらいいのに」と感じた経験はありませんか?
こうした場面で活躍するのが、「ランダムサンプリング」という手法です。
ランダムサンプリングとは
ランダムサンプリングとは、大量のデータ(母集団)の中から、一定数のサンプルを無作為に抽出する方法です。
製造現場の品質管理データやアンケート調査の結果のように、データ数が膨大になるとすべてを分析することは難しくなります。そこで、データの一部を無作為に取り出して分析し、全体の傾向を把握するために活用されるのがランダムサンプリングです。
ランダムサンプリングの種類
ランダムサンプリングには、いくつかの方法があります。たとえば、次のような手法が良く使われます。
- 単純ランダムサンプリング
- 層別サンプリング
- クラスターサンプリング
単純ランダムサンプリング
母集団のすべての要素から同じ確率でサンプルを選ぶ方法です。乱数などを使って無作為に選ぶため、統計的な偏りが少なくシンプルです。ただし、データ数が膨大だと時間や労力がかかる場合もあります。
層別サンプリング
母集団を性別・年齢・地域などの基準でグループ(層)に分け、それぞれのグループから無作為にサンプルを取る方法です。各グループの特性をきちんと反映できるため、より精度の高い分析が可能になります。
クラスターサンプリング
母集団をいくつかのグループ(クラスター)に分け、無作為に選んだグループの中の全てのデータを調査する方法です。たとえば、製造現場で生産ラインごとにロット(製造単位)をクラスターとし、無作為に選んだロットのすべての部品データを分析するような使い方がされます。
ランダムサンプリングの活用場面
そして、ランダムサンプリングはさまざまな業界・分野で活用されています。ここに代表的な活用例をいくつかご紹介します。
-
マーケティングリサーチ
顧客アンケートやWebサイトのA/Bテストで、無作為に抽出した一部の回答者や訪問者を対象に調査や比較を行い、パフォーマンス改善をおこないたいとき。 -
商品の品質管理
製造現場で、製造ロットの中からランダムにサンプルを選び、品質検査を行うことで、全体の品質を効率よく向上したいとき。 -
教育現場の学力調査
無作為に抽出された特定の学校の生徒を対象にテストを行うことで、全体の学力傾向を把握したいとき。 -
機械学習の学習データ選定
膨大なデータセットからデータの一部をランダムに抽出して機械学習モデルを構築したいとき。
このように、ランダムサンプリングは「元データが膨大すぎるときに、抽出されたデータから効率よく全体を把握する」ための手法として、多くの現場で役立っています。
ランダムサンプリングに最適なツールを選ぶなら?
ランダムサンプリングは、Excelなどのスプレッドシート、PythonやRといったプログラミング言語、そしてJMP(ジャンプ)のような統計ソフトを使って実行できます。
では、製造現場で得られた数十万行の品質データから、無作為に数百件だけを抽出して分析する必要があるとしたら――
皆さんなら、どのツールを使いますか?
ランダムサンプリングは、多くの場合、本格的な分析に入る前の「準備段階」で行われることが多いだけに、作業が煩雑だったりすると、余計なストレスになりかねません。
その点、JMPなら関数を使う必要もなく、ランダムサンプリングを実施するための専用メニューが用意されているので、ストレスを感じることがほとんどありません。
さらに、抽出したデータはそのままグラフで可視化でき、探索的な分析へとシームレスに移行できるのも大きな魅力です。
それでは次に、JMPの「サブセット」機能を使って、実際にランダムサンプリングをどう行うのかをご紹介します。
JMPは30年以上の歴史を持つ操作性と可視化に優れた統計ソフトです。
未体験の方は、30日間全機能を無料で試せるトライアル版があるので試してみてください(自動課金はされません)。
https://www.jmp.com/ja_jp/download-jmp-free-trial.html?utm_campaign=bl&utm_source=blog&utm_medium=JMPblog
パワフルなJMPの「サブセット」機能で得られる、データからの「気づき」
今回は、製造現場で収集された部品のスペックデータ(Excel形式・30万行)をもとに、不合格となった部品の傾向を分析していきます。
データ量が多いため、全体の合否率を反映するかたちで、無作為に300件を抽出し、不良の原因を探るというシナリオです。
それでは、さっそく始めましょう。
ヘッダのグラフで全体の傾向をざっくり確認
まずは、Excel形式のデータをJMPに読み込みます。今回使用する30万件のデータには、製品の重量・長さ・幅といったスペック情報のほか、生産ラインや検査結果といった項目も含まれています。
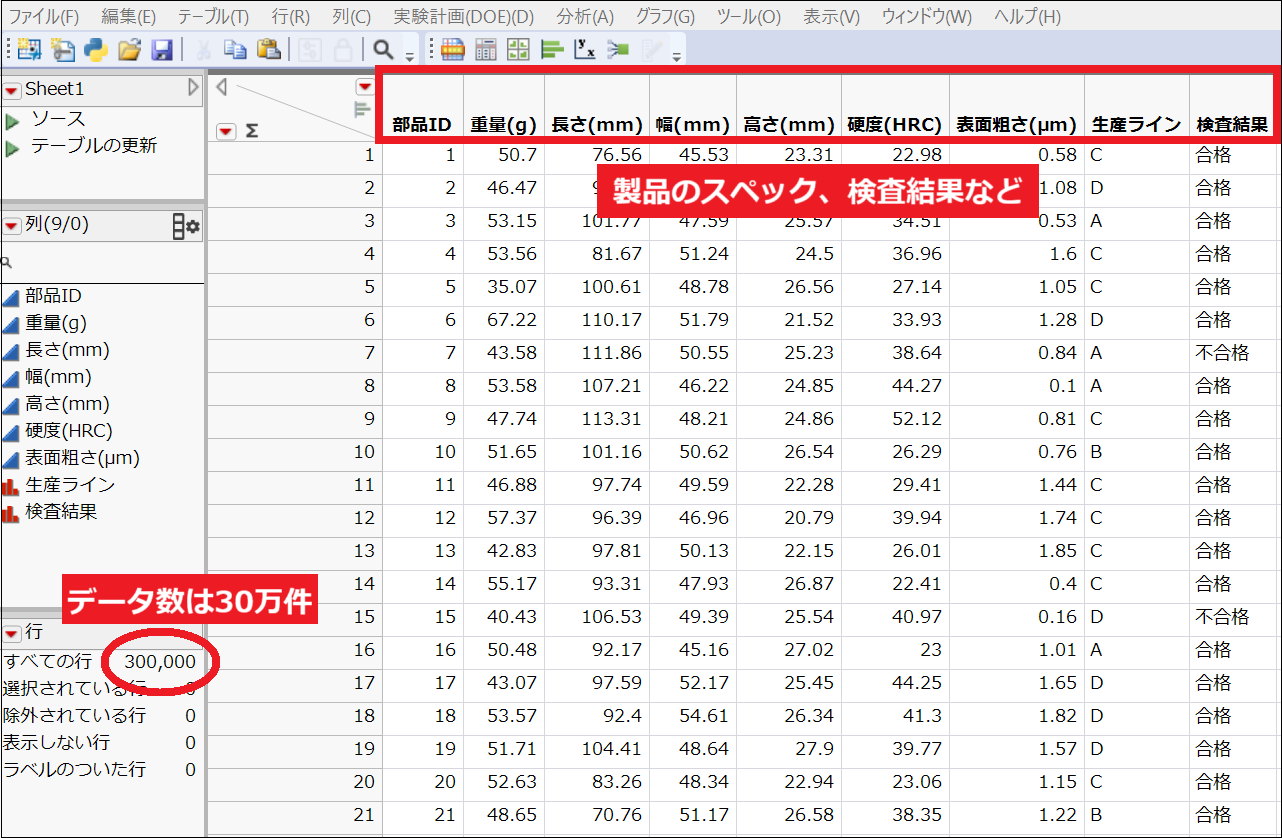
本格的な分析に入る前に、まずはデータ全体の傾向をざっくり把握しておきましょう。列名の左にあるヒストグラムのアイコンをクリックすると、簡易グラフが表示され、値の分布を視覚的に確認できます。
あらかじめデータの全体像をつかんでおくことで、この後の分析作業をよりスムーズに進めることができます。

自由自在にランダムサンプリング:JMPの「サブセット」機能
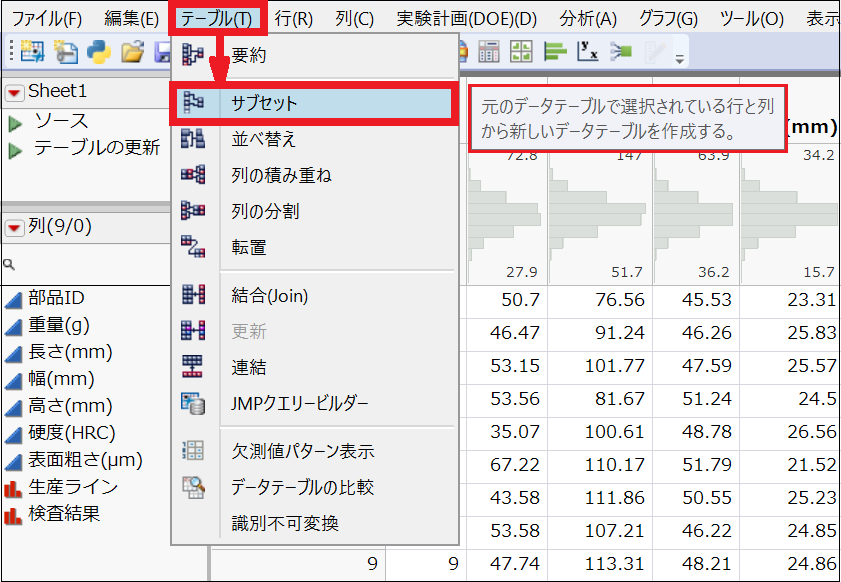
次に、30万件あるデータの中から、無作為に300件を抽出します。画面上部の「テーブル」から「サブセット」を選び、「ランダム - 標本抽出率」に「0.001(300 ÷ 300,000)」と入力します。
続いて、「層化」(元のデータの割合に比例して抽出するオプション)にチェックを入れて「検査結果」を選択し、最後に「OK」をクリックすれば、サンプリングは完了です。

抽出された300件のサブセットデータを確認すると、合格と不合格の割合が元の全データとほぼ同じであることがわかります。サンプリング後も全体の傾向がしっかり保たれていることが確認できました。

気になるポイントを深掘り!「サブセット」でデータを絞り込んで探索をもっと効果的に
ここでデータに戻ってヘッダのグラフを確認すると、不合格品では生産ラインCの製造品が多そうです。

そこで今度は、不合格品の部品データだけを抽出して検討してみます。
先ほどと同様に、「テーブル」から「サブセット」と進み、今回は「フィルタリングされた行」>「ローカルデータフィルター」>「検査結果」>「不合格」と選択して「OK」をクリックすれば、不合格品だけのデータを抽出できます。
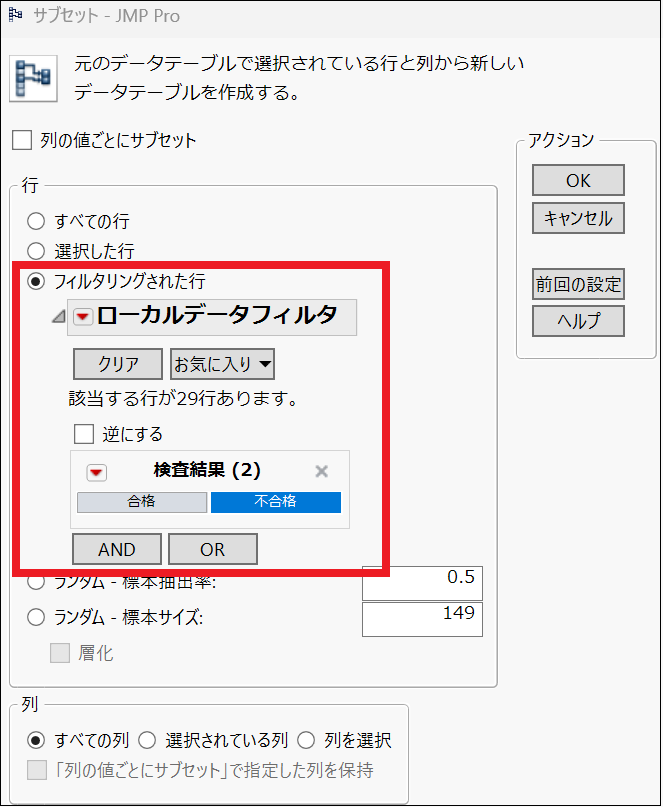
これで不合格品だけを抽出したサブセットデータが作成できました。

ヘッダ部分に表示されるグラフを見ると、不合格品の中でも生産ラインCの割合が特に高いことがわかります。ただし、現時点ではその原因までは特定できていません。
そこで、もう少しデータを探索してみましょう。
JMPの「二変量の関係」で不合格品の傾向を探索
先ほどランダムサンプリングで抽出した300件のデータのうち、不合格品だけをさらに詳しく分析してみましょう。
まず、画面上の「分析」から「二変量の関係」と進みます。「X, 説明変数」に「生産ライン」を入れ、「Y, 目的変数」に「重量」から「表面粗さ」までを入力して「OK」を押します。
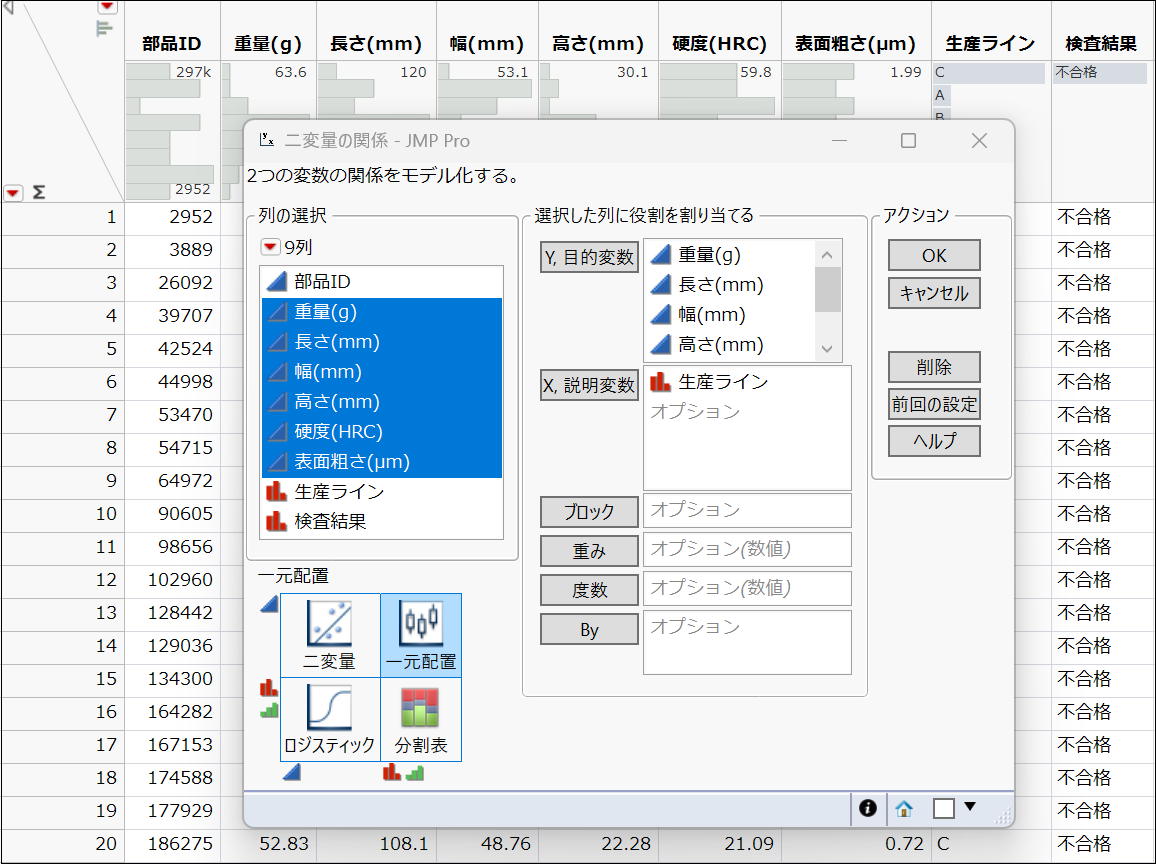
すると、幾つかの一元配置分散分析のグラフが表示されました。ここでは重量のグラフに注目してみましょう。
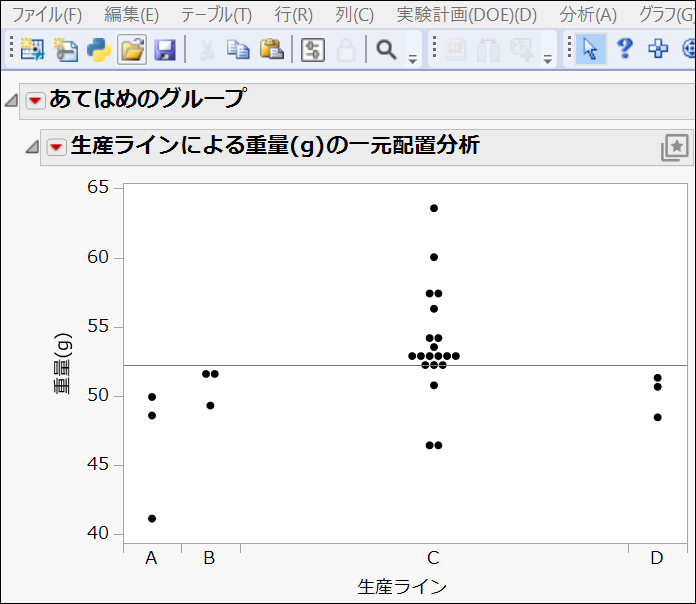
Cはおおよそ52gよりも上にデータ点が集中しているように見えます。このことから、「生産ラインCでは、重量が52gを超えると不合格になりやすいのでは?」という仮説が浮かんできます。
こうした気づきが、まさにデータ探索の面白さです。
さらに詳しく見てみたいときは、生産ラインCかつ52g以上のデータをグラフ上で選択すると、該当するデータ行が連動してハイライトされます。
JMPではグラフとデータが連動しているので、グラフで気になった箇所があれば、すぐにデータに戻って確認できるのが便利です。

この状態で、画面上部の「テーブル」から「サブセット」と進み、今回は「選択した行」を指定してサブセットを作成します。
これで、生産ラインCで製造され、かつ重量が52g以上の製品データに絞り込んで、さらに詳しく検討できるようになりました。
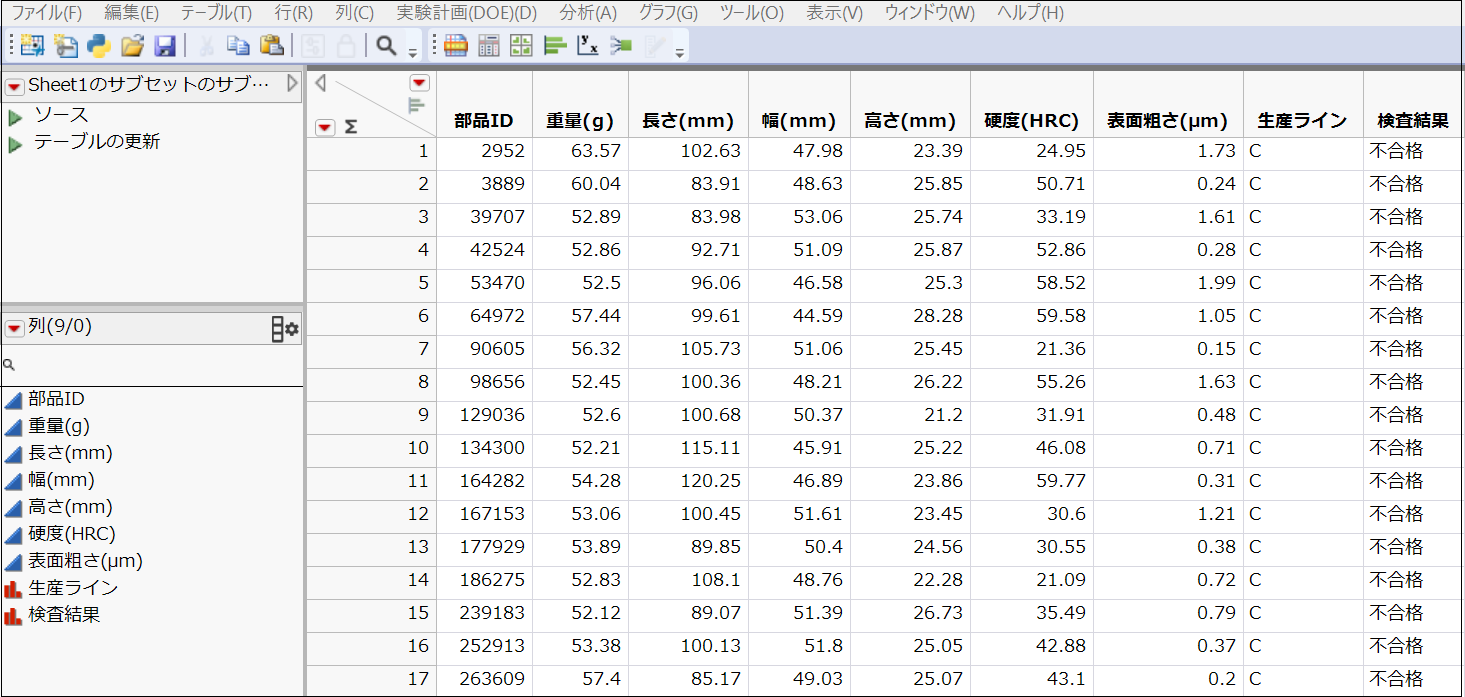
もしこのデータで不合格の原因がうまく見つからなかったとしても、JMPの「サブセット」機能を使えば、別の条件で新たなデータセットを簡単に作成して、試行錯誤を続けることができます。
まとめ
ランダムサンプリングは、スプレッドシートやプログラミング言語でも関数などを使って実行できますが、JMPなら関数を使わずに専用メニューで簡単に行えるのが特長です。
また、「抽出→可視化→分析」がスムーズにひと続きで行えるため、サンプリング後の作業も効率よく実施でき、データの中から有益な「気づき」を得やすくなります。
「分析にかける時間を短縮し、データから得られるインサイトの質を高めて、より深い理解につなげたい」
これは業務でデータ分析を担当すると誰もが願うことですが、ランダムサンプリングを行う際に、JMPの「サブセット」機能はきっと心強いパートナーになるはずです。
ぜひ記事前半でご紹介したトライアル版で試してみてください!
「サブセット」を含む、データ加工に役立つJMPのさまざまな機能については、以下の動画をご参照ください。
「データ加工に役立つ!「テーブル」メニューの各機能(動画)」
https://community.jmp.com/t5/Learn-JMP-Events/%E3%83%87%E3%83%BC%E3%82%BF%E5%8A%A0%E5%B7%A5%E3%81%AB%E5%BD%B9%E7%AB%8B%E3%81%A4-%E3%83%86%E3%83%BC%E3%83%96%E3%83%AB-%E3%83%A1%E3%83%8B%E3%83%A5%E3%83%BC%E3%81%AE%E5%90%84%E6%A9%9F%E8%83%BD-%E6%97%A5%E6%9C%AC%E8%AA%9E/ev-p/816297