前回は、Adobe CampaignクエリーでCASE式1による集計をやってみました。
実は、やり方はひとつじゃありません。今回はちょっと違った方法に取り組んでみましょう。
誕生日が1926年12月26日以降の受信者で「昭和生まれ」「平成生まれ」「令和生まれ」それぞれの人数を数えたい。
まず、クエリー道場第5回をそのまま使います:
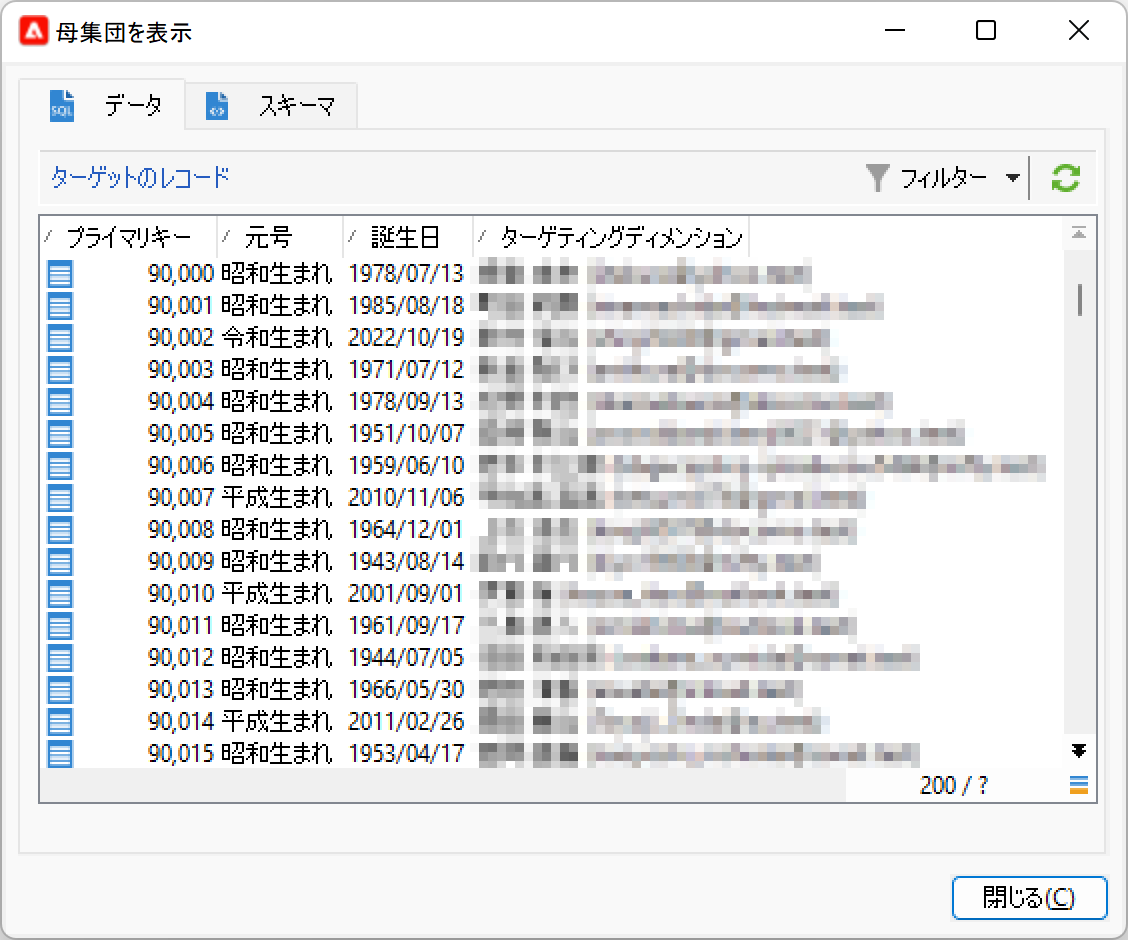
この結果を得たアクティビティにつなげて、新たな「クエリ」アクティビティを置きましょう:
ダブルクリックし、「クエリを編集...」をクリック:
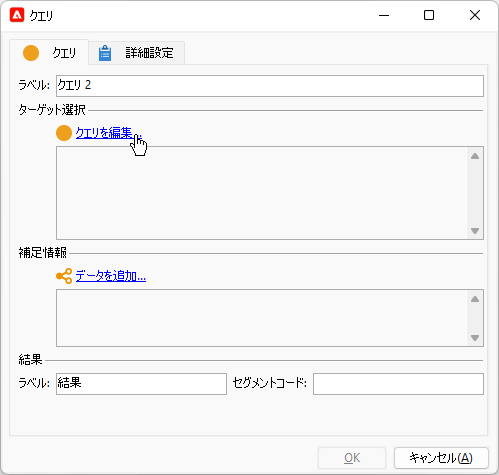
「ターゲティングとフィルタリングディメンジョン」画面で「一時スキーマ」をティックします。そしてその下の「スキーマ」でプルダウンから先行「クエリ」アクティビティを選択してください:
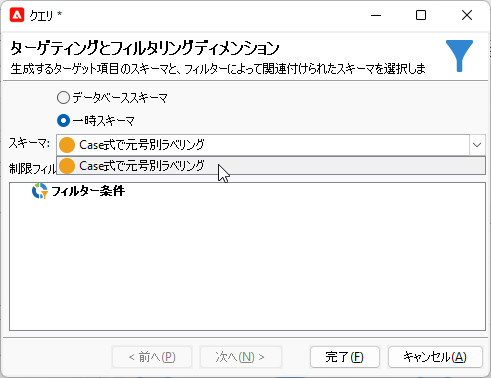
「制限フィルターのリスト」で「フィルター条件」をダブルクリック。「フィルター」画面では誕生日を1926年12月26日以降とします2:
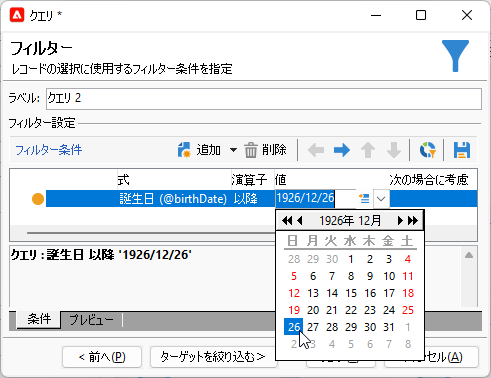
「完了」で「クエリ」画面に戻り、「データを追加...」をクリック:
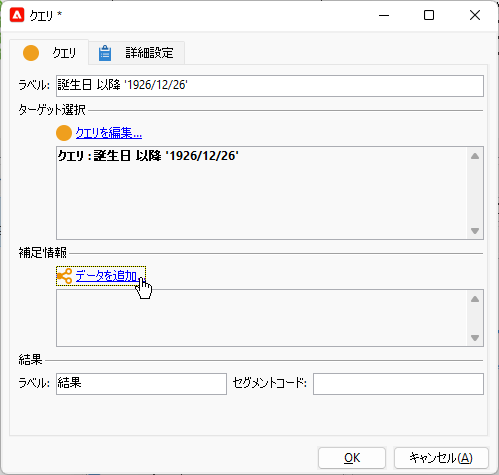
「フィルタリングディメンジョンにリンクされたデータ」>「フィルタリングディメンジョンのデータ」。この辺は過去回と同様です。
「追加するデータ」画面で「使用可能フィールド:」ペインの「元号」をダブルクリックします。すると「出力列:」に追加されるので、「グループ」のチェックボックスをチェックしてください:
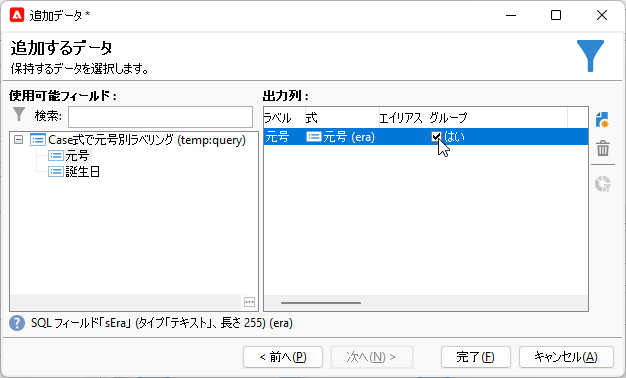
「追加」ボタンをクリック:
「式」に以下をコピペ。意味はまたのちほど:
Count(era)
「完了」で「クエリ」画面に戻り、「追加データを編集...」をクリック:
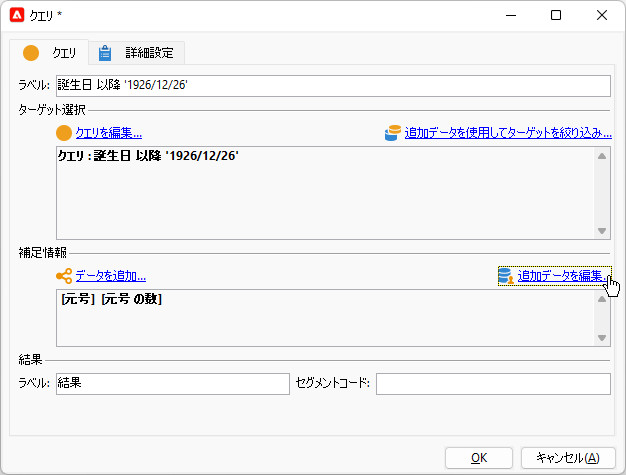
「詳細設定パラメーター...」をクリック:
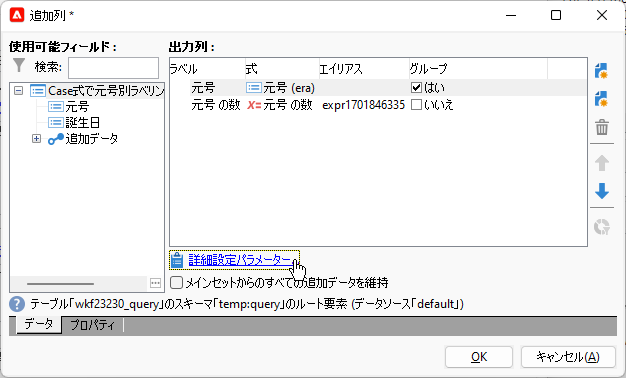
「重複行を削除 (DISTINCT)」をアンチェック、「ターゲティングディメンジョンのプライマリキーの自動追加を無効にする」をチェック3:
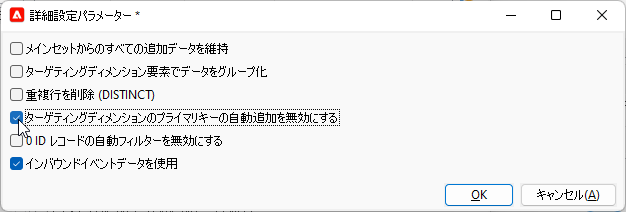
「OK」3回クリックでワークフローキャンバスに戻って「保存」、完成です。実行し「クエリ」アクティビティからの遷移矢印を右クリックして「ターゲットを表示...」:
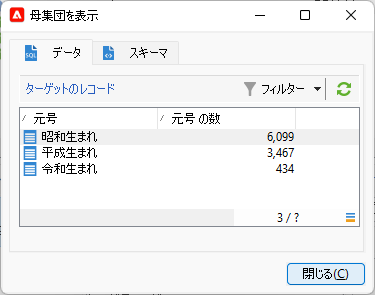
前回では集計結果を行で得る「横持ち」でしたが、今回は列に集計結果が並ぶ「縦持ち」になるのがおもしろいところです。配信など後続アクティビティの要件によって使い分けてください。
ポイントを振り返ってみます。
ここまでクエリー道場では1アクティビティ内で処理を完結させていましたが、今回はクエリーの2つ使いをやってみました。そのためターゲットディメンジョンを一時スキーマとして上流の結果を読み込んでいます:
これにより後の「詳細設定パラメーター」で「インバウンドイベントデータを使用」が自動的にチェックされていることに注意してください:
もうひとつポイントが「グループ」:
クエリー道場第3回で取り上げました。ご記憶でしょうか。
今回は元号ごとの数を集計するんでしたね。そのため「グループ」をチェックすることで元号ごとに束ねてやったというわけです。そして:
Count(era)
第2回で取り上げた集計関数Count()。また引数の「era」は第5回で元号に対して定義したエイリアスです。このエイリアス機能は見過ごされがちですがなにげに便利で、今回のようにアクティビティ間を渡ってデータを参照する場合にはとても役立ちます。
以上により、グループ化された元号カラム「era」をカウントできるので、要件の結果を得ることができました。
最後に今回作ったアクティビティのSQLを見ておきましょう:
SELECT W0.sEra, Count(W0.sEra) FROM wkf23230_30_1 W0 WHERE (W0.tsBirth >= date '1926-12-26') GROUP BY W0.sEra
Count(W0.sEra)はコピペした式に対応するSQL。元号カラムをカウントします。その対象テーブルが「wkf23230_30_1 W0」。先行するアクティビティが出力した一時テーブルで、受信者を元号でラベリングした結果が入っています。そして「GROUP BY W0.sEra」は上述の「グループ」に対応するSQL。これで元号ごとにグループ化ができるというわけですね。
Campaignのインターフェイス上で用いた式や関数がSQLに展開されていることを確認してください。
いかがでしたか。前回の別解を紹介したわけですが、過去回の復習もすることができました。忘れていた方は併せて振り返ってみてください。
ひとつの要件に対してこうして何通りものやり方ができる。Campaignの柔軟さです。それに合わせて自分の発想も柔軟にすれば、より多くの要件に適切な対応をとれるようになりますね。本稿がその助けになればうれしいです!
本稿の内容は筆者のオンプレミス型デモ環境(Adobe Campaign Classic 9359@c636bf3 PostgreSQL 14.9)上で実施した検証に基づきます。別環境における同様の動作を保証するものではありません。またデータは架空のものであり、既存の配信や実在の組織とはいっさい関係がありません。
-
CampaignのCASE式については以下記事も併せてご覧ください:
Adobe Campaignクエリー道場(5)〜CASE式はシティポップに乗せて
Adobe Campaignクエリー道場(6)〜CASE式で推し活?!
Adobe Campaignクエリー道場(7)〜CASE式で集計 ↩ -
この条件はじつは不要ですが、何らかのフィルター条件がないとエラーになるためダミー的に指定しています。 ↩
-
「ターゲティングディメンジョンのプライマリキーの自動追加を無効にする」はグループ化と集計関数に欠かせません。各レコードにキーが付いていてはグループにならないからです。過去回も併せてご覧ください:
Adobe Campaignクエリー道場(1)〜ユニークな件数
Adobe Campaignクエリー道場(2)〜重複値を探す
Adobe Campaignクエリー道場(3)〜最新日付でビバノンノン
Adobe Campaignクエリー道場(4)〜HAVING句でブラボー! ↩